Download as PDF, PPTX


















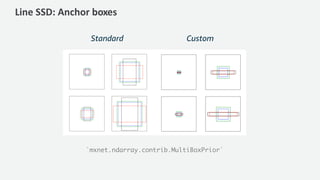

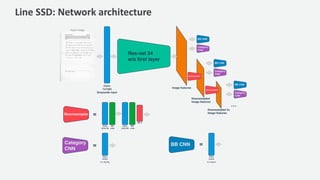







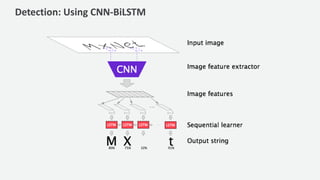




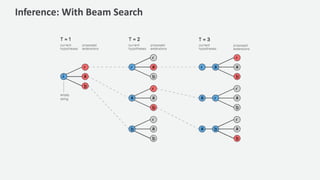

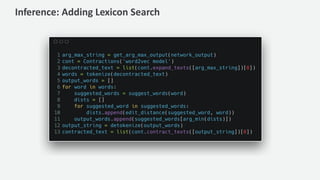




The document discusses a handwriting recognition pipeline using AWS MXNet and Gluon, focusing on optical character recognition through various methods including page and line segmentation using CNN and SSD. It elaborates on the challenges of labeling and alignment in handwriting recognition, proposing solutions like connectionist temporal classification loss and inference methods such as beam search and lexicon search. Results highlight a character error rate improvement through these techniques, emphasizing the effectiveness of the developed model.









![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[NS][Lab_Seminar_240624]Graph Neural Networks for End-to-End Information Extr...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240624stge-240624082503-16e200ab-thumbnail.jpg?width=640&height=640&fit=bounds)







































