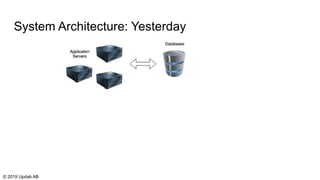
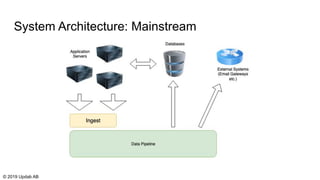
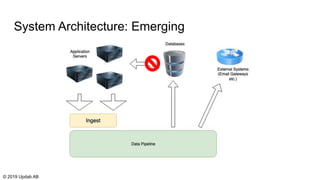
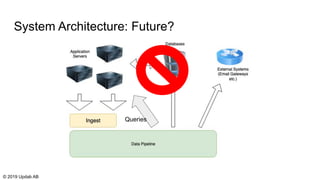
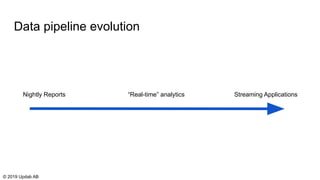
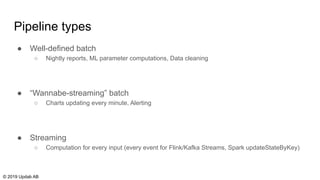
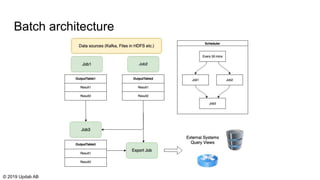
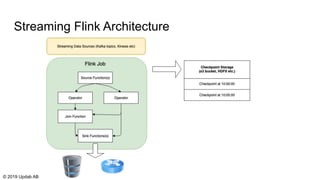
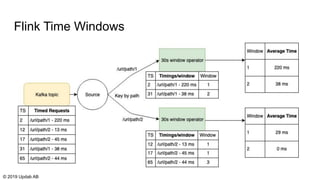
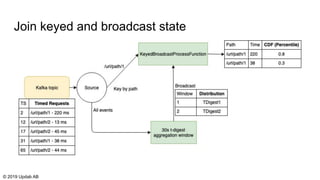
The document discusses the migration of batch ETL processes to streaming ETL using Apache Flink, detailing the advantages of streaming over batch processing including faster results, resource efficiency, and flexibility in deployment. It covers topics such as Flink's architecture, different window operators, and the importance of testing and replaying in streaming applications. Additionally, it highlights various global computations and practices to handle challenges in maintaining data integrity during replays.