
Recommended
More Related Content
What's hot
What's hot (12)
Similar to Dm
Similar to Dm (20)
Recently uploaded
Recently uploaded (20)
Dm
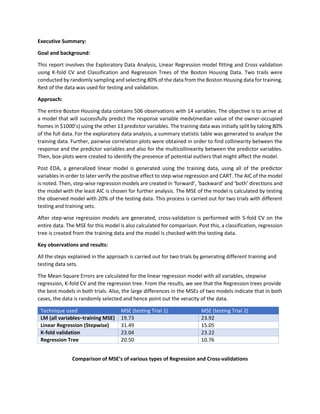
- 1. Executive Summary: Goal and background: This report involves the Exploratory Data Analysis, Linear Regression model fitting and Cross validation using K-fold CV and Classification and Regression Trees of the Boston Housing Data. Two trails were conducted by randomly sampling and selecting 80% of the data from the Boston Housing data for training. Rest of the data was used for testing and validation. Approach: The entire Boston Housing data contains 506 observations with 14 variables. The objective is to arrive at a model that will successfully predict the response variable medv(median value of the owner-occupied homes in $1000’s) using the other 13 predictor variables. The training data was initially split by taking 80% of the full data. For the exploratory data analysis, a summary statistic table was generated to analyze the training data. Further, pairwise correlation plots were obtained in order to find collinearity between the response and the predictor variables and also for the multicollinearity between the predictor variables. Then, box-plots were created to identify the presence of potential outliers that might affect the model. Post EDA, a generalized linear model is generated using the training data, using all of the predictor variables in-order to later verify the positive effect to step-wise regression and CART. The AIC of the model is noted. Then, step-wise regression models are created in ‘forward’, ‘backward’ and ‘both’ directions and the model with the least AIC is chosen for further analysis. The MSE of the model is calculated by testing the observed model with 20% of the testing data. This process is carried out for two trials with different testing and training sets. After step-wise regression models are generated, cross-validation is performed with 5-fold CV on the entire data. The MSE for this model is also calculated for comparison. Post this, a classification, regression tree is created from the training data and the model is checked with the testing data. Key observations and results: All the steps explained in the approach is carried out for two trials by generating different training and testing data sets. The Mean-Square Errors are calculated for the linear regression model with all variables, stepwise regression, K-fold CV and the regression tree. From the results, we see that the Regression trees provide the best models in both trials. Also, the large differences in the MSEs of two models indicate that in both cases, the data is randomly selected and hence point out the veracity of the data. Technique used MSE (testing Trial 1) MSE (testing Trial 2) LM (all variables–training MSE) 19.73 23.92 Linear Regression (Stepwise) 31.49 15.05 K-fold validation 23.04 23.22 Regression Tree 20.50 10.76 Comparison of MSE’s of various types of Regression and Cross-validations
- 2. Executive summary – problem2 Goal and Background: The goal of this problem is to build logistic regression, CART on a single dataset and compare the results. Approach and Results: First, a logistic regression model is built. Best model is obtained by using AIC selection criterion. To test the goodness of model by best AIC , we have performed a 5 fold validation on the full data set. The AUC and misclassification rates of k- fold validation and out of sample prediction are noted and compared. The procedure is repeated for two iterations to take account of sampling selection biases. The following are the results for two iterations: Iteration1 Iteration2 5 fold misclassification rate 0.3415372 0.3416461 Out of sample misclassification rate for AIC best model 0.3299632 0.3455882 AUC of the k-fold 0.8780538 0.8780538 AUC of AIC model on out of sample 0.8983785 0.873988 Because, 5- fold validation takes 5 random samples and summarizes the results based on these 5 samples, the estimates from 5-fold should be more reliable than the estimates given by BIC out of sample. Then, CART model is built on the data. The performance of CART and logistic regression model are compared using misclassification rate. The following are the results: Iteration1 Iteration2 Misclassification rate tree 0.2757353 0.3143382 Misclassification rate logit 0.3299632 0.3455882 Following are the classification tables of two methods: Output of tree: Predicted Truth 0 1 0 662 287 1 13 216 Output of logistic: Predicted Truth 0 1 0 559 350 1 9 130
- 3. On the basis of misclassification rate, for the two iteration CART model is better. We can also use ROC as another performance criterion. 1. Boston Housing data. Random sample a training data set that contains 80% of the original data points. (You may stay with the same data set from HW2.) (i) Start with exploratory data analysis. Repeat linear regression as in HW2. Conduct some residual diagnosis. The Original Boston dataset contains 506 records and has 14 variables. All the variables are numeric and there are no missing values in the dataset. A brief description of the variables is given below Variable Description CRIM per capita crime rate by town ZN Proportion of residential land zoned for lots over 25,000 sq.ft. INDUS proportion of non-retail business acres per town CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) NOX nitric oxides concentration (parts per 10 million) RM average number of rooms per dwelling AGE proportion of owner-occupied units built prior to 1940 DIS weighted distances to five Boston employment centers RAD index of accessibility to radial highways TAX full-value property-tax rate per $10,000 PTRATIO pupil-teacher ratio by town BLACK 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town LSTAT % lower status of the population MEDV Median value of owner-occupied homes in $1000's Table 1.1 Variable description – Boston data The Boston housing data was randomly sampled twice as follows: Dataset No. of Observations No. of Variables Training Data 404 14 Testing Data 102 14 Table 1.2 – Split of training and testing data The Training data was used to build a suitable regression model and carry out further studies We started with the Exploratory Data Analysis of the Training Data which is presented next. 1. Exploratory Data Analysis 1.1 Summary Statistics
- 4. Trial 1 Trial 2 Variable Min Max Median Mean Min Max Median Mean CRIM 0.01 73.53 0.27 3.62 0.001 73.53 0.261 3.371 ZN 0.00 100.00 0.00 11.14 0.00 100.00 0.00 11.33 INDUS 1.21 27.74 9.90 11.32 0.46 27.74 9.69 11.07 CHAS 0.00 1.00 0.00 0.07 0.00 1.00 0.00 0.07 NOX 0.39 0.87 0.54 0.56 0.39 0.87 0.54 0.56 RM 3.56 8.78 6.21 6.28 3.56 8.78 6.23 6.31 AGE 2.90 100.00 77.95 68.68 2.90 100.00 76.6 68.55 DIS 1.13 12.12 3.17 3.77 1.13 12.13 3.22 3.80 RAD 1.00 24.00 5.00 9.63 1.00 24.00 5.00 9.58 TAX 187.00 711.00 330.00 410.20 187.00 711.00 330.00 407.60 PTRATIO 12.60 22.000 19.10 18.54 12.60 22.00 19.10 18.48 BLACK 0.32 396.900 391.38 356.68 0.32 396.90 391.70 358.42 LSTAT 1.73 36.980 11.64 12.75 1.73 36.98 10.93 12.49 MEDV 5.00 50.000 20.90 22.27 5.00 50.00 21.40 22.86 Table 1.3 Summary statistics As stated above, the sample data contained 80% observations. There is one dependent variable namely MEDV and other independent variables. All the variables are numeric in nature. 1.2 Pairwise Correlation A pairwise correlation matrix was obtained as below. A lot of variables showed high correlation. This was confirmed from the correlation matrix obtained for this data sample. Few of the highly correlated values are: TRIAL 1 TRIAL 2 dis:indus = -0.710 dis:indus = -0.702 dis:age = -0.748 dis:age = -0.753 dis:nox = -0.769 dis:nox = -0.771 tax:indus = 0.706 tax:indus = 0.716 tax:rad = 0.912 tax:rad = 0.909 chas:age = 0.092 chas:age = 0.061 chas:dis = -0.095 chas:dis = -0.087 chas:nox = 0.091 chas:nox = 0.065 Table 1.4 Correlation between variables This would be taken care of when selecting the variables for the final model. 1.3 Outliers
- 5. The box plots for entire data are given below. There were many variables that had a number of outliers. The prominent ones are black, zn and crim Fig 1.1 Similar boxplots for Trail 1 and Trail 2 for training data. 2. Linear Regression Linear Regression was performed on the given set of variables. The medv was kept as the response variable and rest all the variables were treated as predictor variables to obtain a rough linear model. The relevant statistics are as follows: a) The significance factor showed indus and age to be least significant predictors (no stars only blanks) b) The R2 = 0.759 and R2 Adj = 0.751 (trial 1), R2 = 0.744 and R2 Adj = 0.736 (trial 2) showed that the rough model is a very good fit for the sample data. But this is not conclusive. c) MSE = 19.72 (trial 1), MSE = 23.89 (trial 2) d) AIC criterion = 2381.285 (trial 1), 2458.628 (trial 2) e) BIC criterion = 2441.306 (trial 1), 2518.649 (trial 2) The next step would be the Variable selection. We will use this to refine our rough model to obtain a better fit. 3. Variable Selection Two techniques were employed to select the correct variables for the regression model
- 6. a) Best Subsets Analysis – Since the number of variables were few, the best subset analysis was employed to check the most feasible subset. 14 comparisons with 2 best fits were done. The results were checked on the BIC and Adj R2 criteria. Below are the plots for the same. Similar plots were obtained for Trial 1 and Trial 2. Fig 1.2:BIC criterion Fig 1.3: Adjusted R2 criterion Both the criteria indicated towards removal of few variables for the best fit.
- 7. b) Forward and Stepwise Regression – Both forward and stepwise regression were carried out on the sample dataset. Both the techniques revealed the same model i.e. with same predictor variables. The final model obtained was: medv ~ lstat + rm + ptratio + dis + nox + chas + black + zn + rad + crim + tax The estimated coefficients are as below: Trial 1 Trial 2 (Intercept) 34.03 (Intercept) 37.51 lstat -0.53 lstat -0.53 rm 3.92 rm 3.68 ptratio -0.91 ptratio -0.95 dis -1.35 dis -1.54 nox -15.84 nox -17.75 chas 2.64 chas 3.05 black 0.01 Black 0.01 zn 0.04 zn 0.04 rad 0.27 rad 0.30 crim -0.09 crim -0.11 tax -0.01 tax -0.011 Table 1.5 Estimated coefficients for stepwise-regression The AIC value for this model was 1228.91 (trial 1) 1306.61 (trial 2) which was much smaller as compared to our previous rough model and hence hinted that this model is far better than the model with all variables The MSE is 19.73 (trial 1), 23.92 (trial 2) which is almost the same as the previous value 4. Residual diagnostics Residual diagnostics was carried out on the newly build model. The results are as given below
- 8. Fig 1.4 Residuals vs fitted The residuals showed a decent fit here. There were few outliers but a majority of data had an even spread. Fig 1.5 QQ plot Again, the QQ plot showed some evident outliers but overall the fit was good as the sample points coincided with the line.
- 9. Fig 1.6 Residuals vs leverage For most points the Cook’s distance is very less and hence it’s a good fit. The plots are similar for both trial 1 and trial 2 (ii) Test the out-of-sample performance. Using final linear model built from (i) on the 80% of original data, test with the remaining 20% testing data. (Try predict() function in R.) Report out-of-sample model MSE etc. The out-of-sample performance was measured by fitting the linear model obtained above to the 20% test dataset. The MSE for the test dataset is 31.4860 (trial 1), 15.05 (trial 2). (iii) Cross validation. Use 5-fold cross validation. (Try cv.glm() function in R on the ORIGINAL 100% data.) Does (iii) yield similar answer as (ii)? A 5-fold cross validation was applied on the entire BOSTON dataset. The MSE calculated after the cross validation was 23.0353 (trial 1), 23.85 (trial 2). This is different to the model obtained by step-wise regression. (iv) Fit a regression tree (CART) on the same data; repeat the above steps (i), (ii).
- 10. Fig 1.7 Classification tree The out-of-sample performance for the regression tree was measured using the in-sample fit. The MSE in this case is 20.504 (trial 1), 10.762 (trial 2). This is remarkably close to the value obtained with in training sample MSE using the linear regression. Thus the regression tree gives the best fitting model for the testing dataset. (v) What do you find comparing CART to the linear regression model fits from HW2? A comparison chart for the 3 methods employed on Boston data is given below Technique used MSE (testing Trial 1) MSE (testing Trial 2) Linear Regression (Stepwise) 31.49 15.05 K-fold validation 23.04 23.22 Regression Tree 20.50 10.76 Table 1.6 Comparison of MSE By applying the three different techniques we found that the Mean Square Error in prediction is least when we fit the data using Regression tree. The simple linear regression on the other hand had higher error as compared to the Tree or K-fold validation. But the above result comes with a caveat. The error may change with different random samples and the linear regression may perform better with a different sample. Hence we can say that the above results are indicative and not conclusive. However, all three techniques provide better models than generating a linear model with all variables.
- 11. 2(i) Exploratory data analysis Below plot shows the distribution of dependent variable DLRSN in the data. As can be seen number of 1’s is close to 750 and number of 0’s is ~4500 Fig 2.1.1 histogram of dependent variable DLRSN
- 12. Correlation plot for all the variables. As can be seen (R3, R8) and (R9, R10) show high correlation greater than .6 indicating a possible multi-collinearity among the independent variables. Dependent variable DLRSN is most linearly correlated to R5 and R6 as observed in the plot. Figure 2.1.2 Correlation plot for all the variables in bankruptcy data
- 13. General Linear Regression methods and comparison Below is the comparison summary of general regression methods on bankruptcy data. With AIC criteria we can observe that Log-Log method performed well out of the three models. Model Intercept R1 R2 R3 R4 R5 R6 R7 R8 R9 R10 AIC Logistic -2.56 0.207 0.584 -0.496 - 0.0817 - 0.0461 0.25 -0.47 -0.289 0.384 -1.63 2433.4 Probit -1.41 0.096 0.32 -0.258 - 0.0129 -0.024 0.0152 -0.204 -0.142 0.201 -0.896 2439.6 Log- Log -2.54 0.166 0.448 -0.387 -0.141 -0.01 0.152 -0.41 -0.257 0.31 -1.287 2455.2 Fig 2.2.3 Comparison of general linear regression models 2(ii) Logistic Regression Analysis- feature selection with step wise approach In Sample Data Model selected from step wise regression with AIC criterion is as follows DLRSN= -2.6 + 0.11*R1 + 0 .62*R2 - 0.45*R3 - 0.16*R4 + 0.26*R6 - 0.41*R7 - 0.36*R8 + 0.32*R9- 1.56*R10 AIC value = 2368.6 which is less than full model AIC of 2370 Mis classification rate using p=1/16 is .331 Mean Residual deviance 2412.2 Confusion matrix is as follows Predicted TRUE 0 1 0 2343 1388 1 52 565 Fig 2.2.1Confusion matrix on in sample training data – AIC Model
- 14. ROC Curve Fig 2.2.2 AUC curve on in sample training data – AIC model AUC = .883 Model selected from step wise regression with BIC criterion is as follows DLRSN= -2.58 + .62*R2 -0.44*R3 + 0.21*R6 -0.35*R7 -0.35*R8 + .41*R9 - 1.62*R10 BIC value = 2369.2 which is less than full model BIC of 2440 Mis classification rate using p=1/16 is .332 Mean Residual deviance 2412.2
- 15. Confusion matrix is as follows Predicted TRUE 0 1 0 2339 1392 1 50 567 Fig 2.2.3 Confusion matrix on in sample training data – BIC model Fig 2.2.4 AUC curve on in sample training data – BIC model AUC = .882
- 16. 2 (ii)Logistic Regression - testing model performance with out of sample testing data Out Sample Data Model selected from step wise regression with AIC criterion is as follows DLRSN= -2.6 + 0.11*R1 + 0 .62*R2 - 0.45*R3 - 0.16*R4 + 0.26*R6 - 0.41*R7 - 0.36*R8 + 0.32*R9- 1.56*R10 Mis classification rate using p=1/16 is .356 Confusion matrix is as follows Predicted TRUE 0 1 0 558 371 1 17 142 2.3.1 Confusion Matrix on out of sample data – AIC model
- 17. Fig 2.3.2 ROC curve on testing out sample data – AIC Model AUC = 0.859 Model selected from step wise regression with BIC criterion is as follows DLRSN= -2.58 + .62*R2 -0.44*R3 + 0.21*R6 -0.35*R7 -0.35*R8 + .41*R9 - 1.62*R10 Mis classification rate using p=1/16 is 0.361 Confusion matrix is as follows Predicted TRUE 0 1 0 553 376 1 17 142 2.3.3 Confusion matrix on testing out sample table – BIC Model Fig 2.3.4 ROC curve on testing out sample data – BIC model
- 18. AUC = .857 2(iv) Identifying optimal cut off probability based on cost function and search grid Below plot describes the variation of cost with cut off probability Fig 2.4.1 cut off probability vs cost We can observe that at cutoff probability of .10 out cost is minimal. This is close to the cut off probability of .16 we used for our misclassification table.
- 19. 2 (v) 5 fold cross validation with the model DLRSN ~ R1 + R2 + R3 + R6 + R7 + R8 + R9 + R10 on the full dataset gives the following results: Misclassification rate : 0.3415372 The initial cost from step iii is 0.3299632. k- fold validation gives more cost AUC for k-fold classification rate :0.8770093 and AUC based on part (iii) is 0.8983785. k-fold validation gives less AUC compared to single out of sample values. k- fold estimates should be more reliable because they are estimated k-times on full data Fig-2.v.a shows the ROC of k-fold 2(vi) By using asymmetric cost of 15:1 a classification tree is fitted and it is shown in Fig.2.vi.a
- 20. 2 vii) Comparing CART and logistic regression model: (i) Comparing on the basis of misclassification rate: Misclassification rate by obtained by tree is 0.2757353 whereas the misclassification rate obtained by logistic regression is 0.3299632. Hence, on the basis of misclassification rate, logistic regression is better. Output of tree: Predicted Truth 0 1 0 662 287 1 13 126 Output of logit: Predicted True 0 1 0 599 350 1 9 130 (ii) Comparing AUCs:
- 21. AUC of CART model is 0.8251 whereas AUC of logistic model is 0.8983. Hence, on the basis of AUCs , logistic regression is better 2 viii) Following is the summary of results for another run Result Iteration 1 Iteration 2 AIC of best model 2502.027 2491.085 5 fold misclassification rate 0.3415372 0.3416461 Out of sample misclassification rate for AIC best model 0.3299632 0.3455882 AUC of the k-fold 0.8780538 0.8780538 AUC of AIC model on out of sample 0.8983785 0.873988 Misclassification rate tree 0.2757353 0.3143382 Misclassification rate logit 0.3299632 0.3455882 AUC of tree 0.8251 0.8231813 AUC of logit 0.87 0.873988 The change in results of k-fold validation is negligible where as we can observe considerable variation on out of sample results. Hence, k-fold validation is more robust. On the basis of misclassification rate, CART is better model in two iterations.