Download as PDF, PPTX



























![이세돌 9단 vs
알파고
이세돌 알파고
-‐ 성인 하루 권장 칼로리: ~2,500 kCal
-‐ 가정: 대국에 하루 필요한 모든 칼로리 소모
2,500
kCal *
4,184
J/kCal
~=
10M
[J]
-‐ CPU:
~100
W,
GPU:
~300 W
-‐ CPU
1,202개, GPU
176개
170,000
J/sec
*
5
hr *
3,600
sec/hr
~=
3,000M
[J]
정말 대충 계산해서 …](https://image.slidesharecdn.com/smoonalphago16-160307231450/85/slide-51-320.jpg)

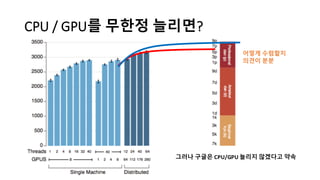






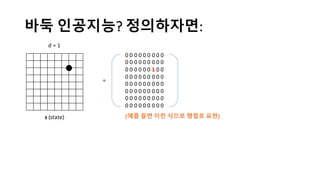
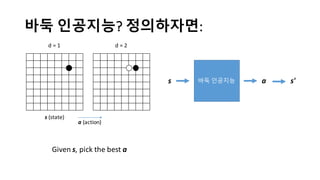
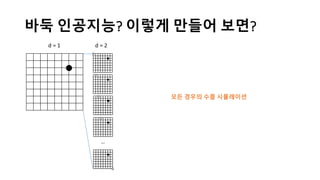
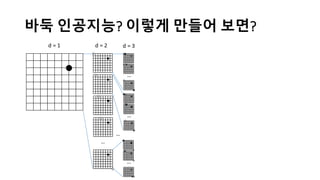
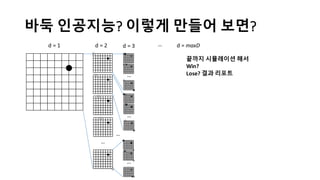
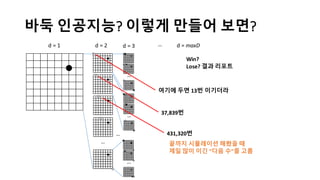
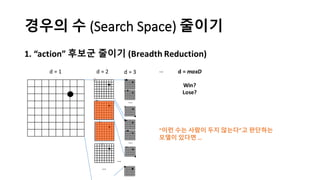
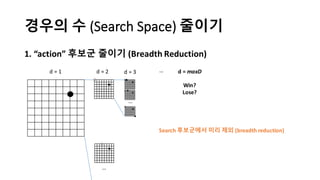
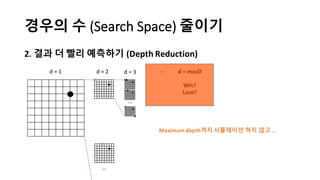
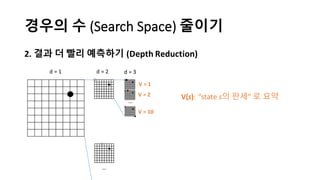
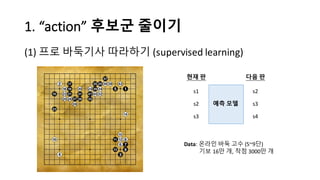
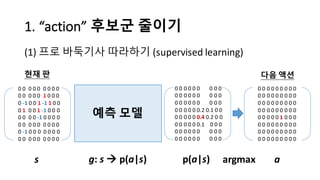
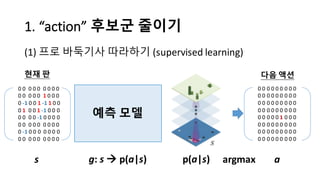
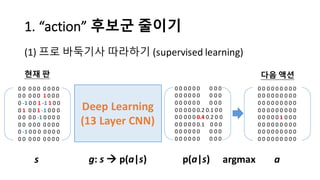
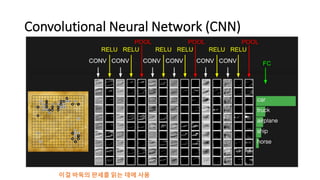
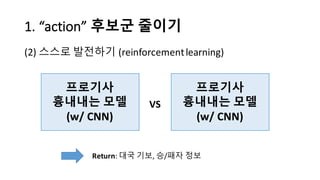
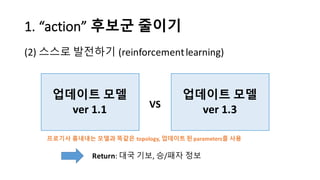
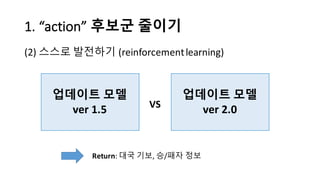
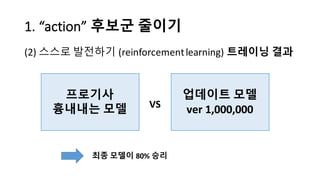
알파고의 작동 원리를 설명한 슬라이드입니다. English version: http://www.slideshare.net/ShaneSeungwhanMoon/how-alphago-works - 비전공자 분들을 위한 티저: 바둑 인공지능은 과연 어떻게 만들까요? 딥러닝 딥러닝 하는데 그게 뭘까요? 바둑 인공지능은 또 어디에 쓰일 수 있을까요? - 전공자 분들을 위한 티저: 알파고의 main components는 재밌게도 CNN (Convolutional Neural Network), 그리고 30년 전부터 유행하던 Reinforcement learning framework와 MCTS (Monte Carlo Tree Search) 정도입니다. 새로울 게 없는 재료들이지만 적절히 활용하는 방법이 신선하네요.





![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Vector-based navigation using grid-like representations in artificial ...](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi0706-180706001232-thumbnail.jpg?width=640&height=640&fit=bounds)




![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Reinforcement Learning with Deep Energy-Based Policies](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170406-170407002545-thumbnail.jpg?width=640&height=640&fit=bounds)













![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)












![[RLPR] Mastering the game of go with deep neural networks and tree search](https://cdn.slidesharecdn.com/ss_thumbnails/masteringthegameofgowithdeepneuralnetworksandtreesearch-200524142131-thumbnail.jpg?width=640&height=640&fit=bounds)





![[RLkorea] 각잡고 로봇팔 발표](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-robotarm-190303021332-thumbnail.jpg?width=640&height=640&fit=bounds)





