Downloaded 41 times




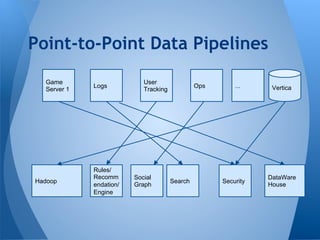
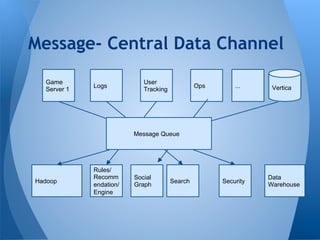

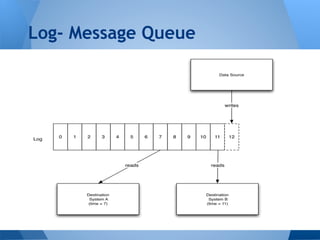
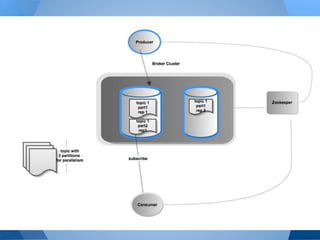

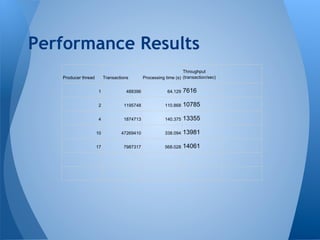













This document summarizes Kafka's performance in handling data pipelines and ETL workloads. It discusses Kafka's high-level architecture, scalability, fault tolerance, and monitoring capabilities. The document also includes results from benchmark tests showing Kafka can process over 47 million transactions in under 6 minutes with latency under 2 milliseconds. It proposes using Kafka to integrate data pipelines between various systems and services at a company.


















































































