Download to read offline




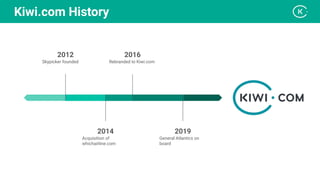
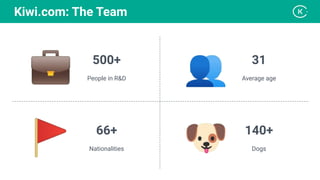


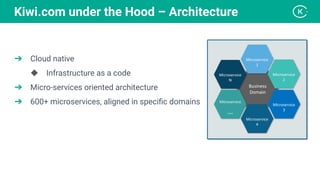

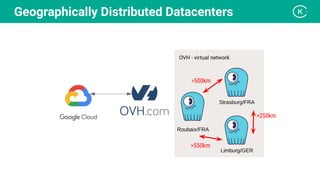
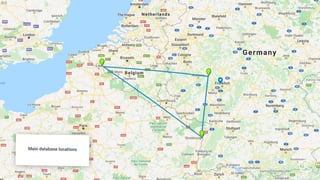





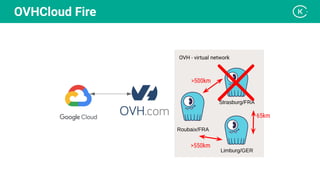

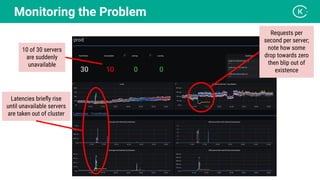











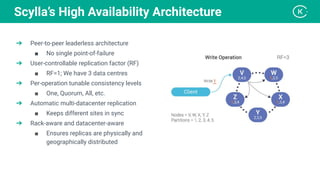
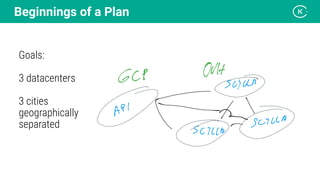



















Stanislav Komanec, VP of Engineering at Kiwi.com, discussed how the company prepared for and responded to a datacenter disaster at OVHcloud. Kiwi.com uses a distributed architecture across multiple datacenters to ensure high availability. When the OVHcloud Strasbourg datacenter caught fire in March 2021, Kiwi.com was able to quickly reroute traffic away from affected servers to avoid disruption. The presentation reviewed Kiwi.com's architecture, best practices for data resiliency, and lessons learned for improving incident response plans.






















































































