Downloaded 19 times














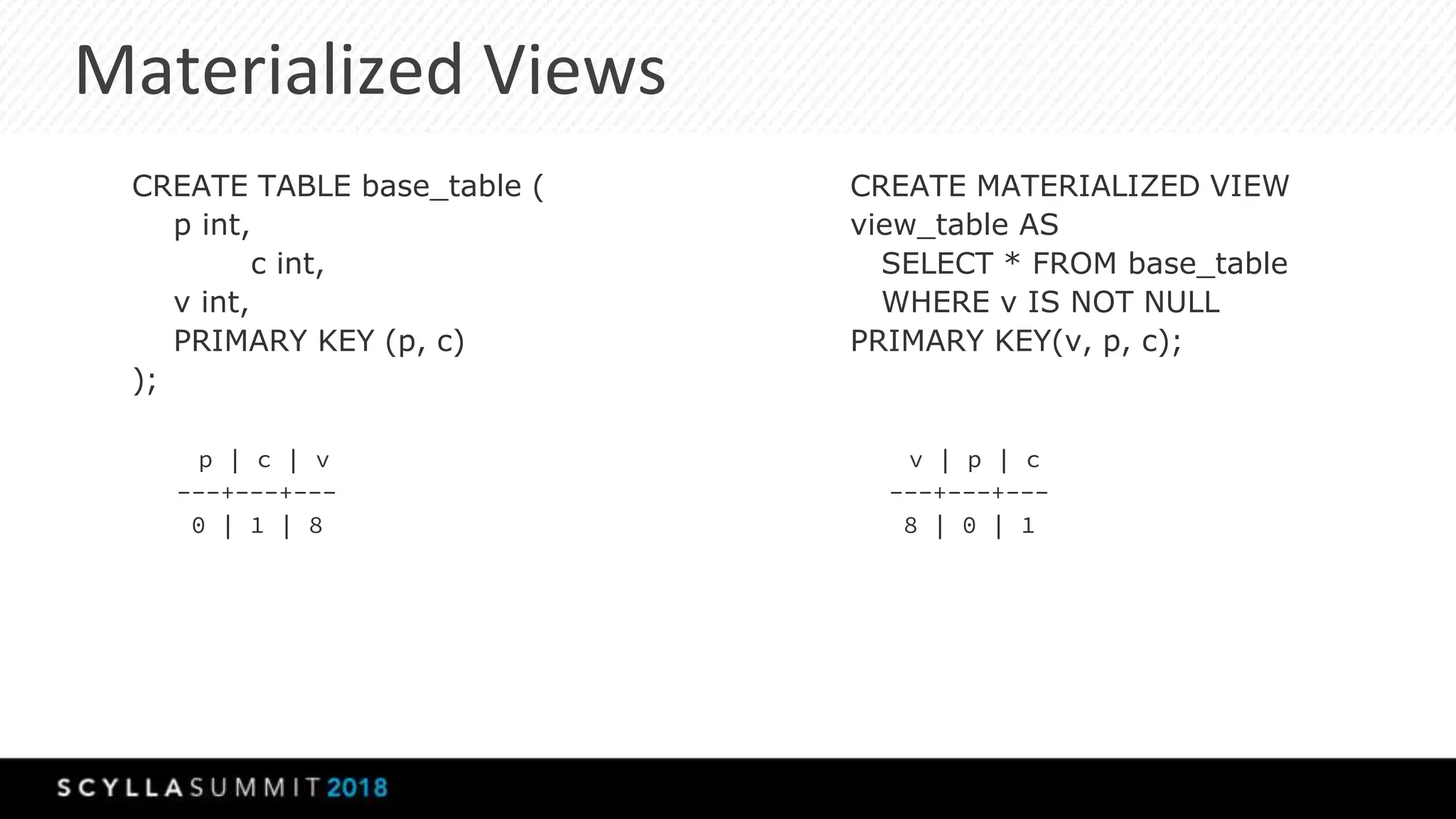




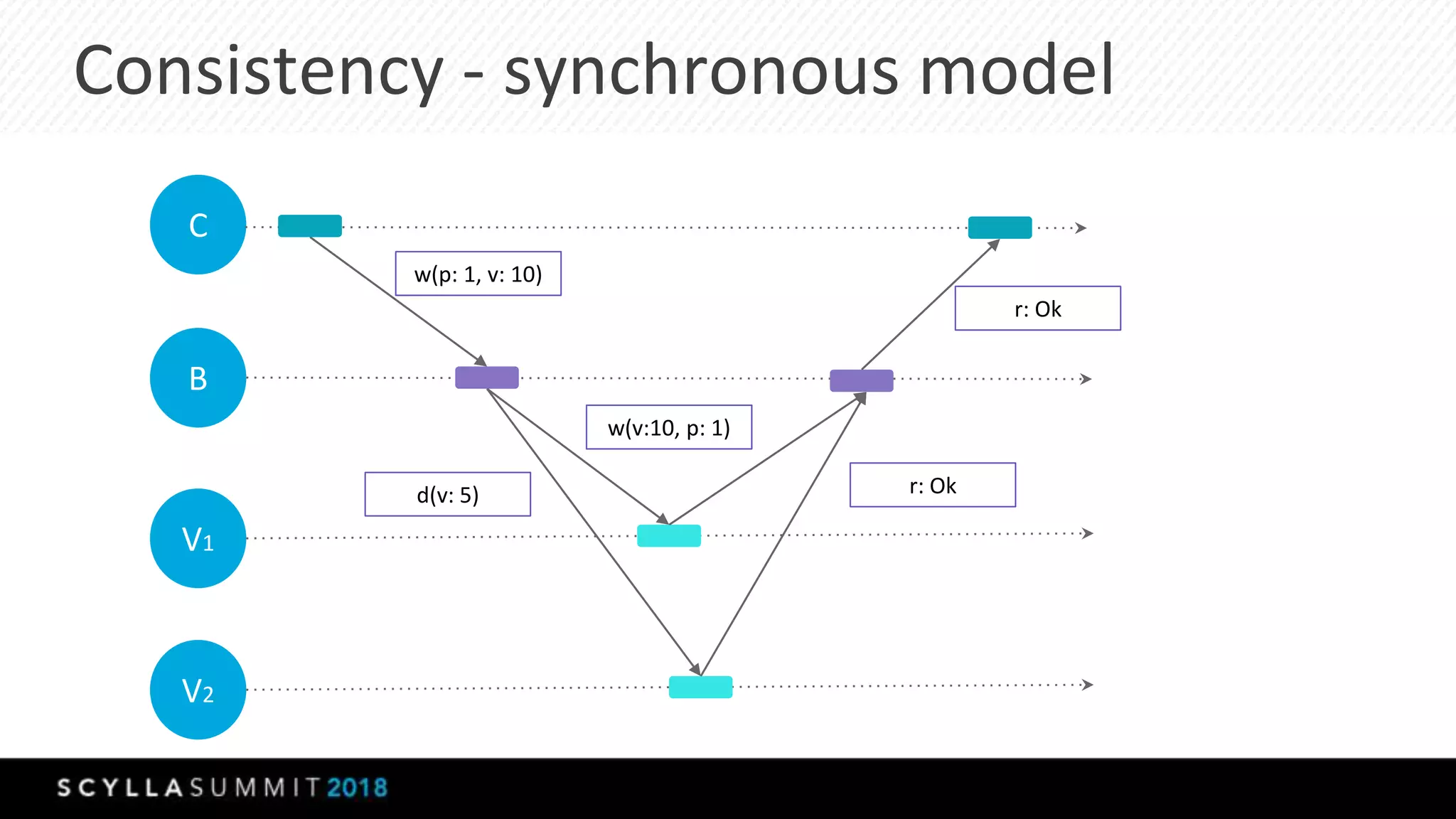
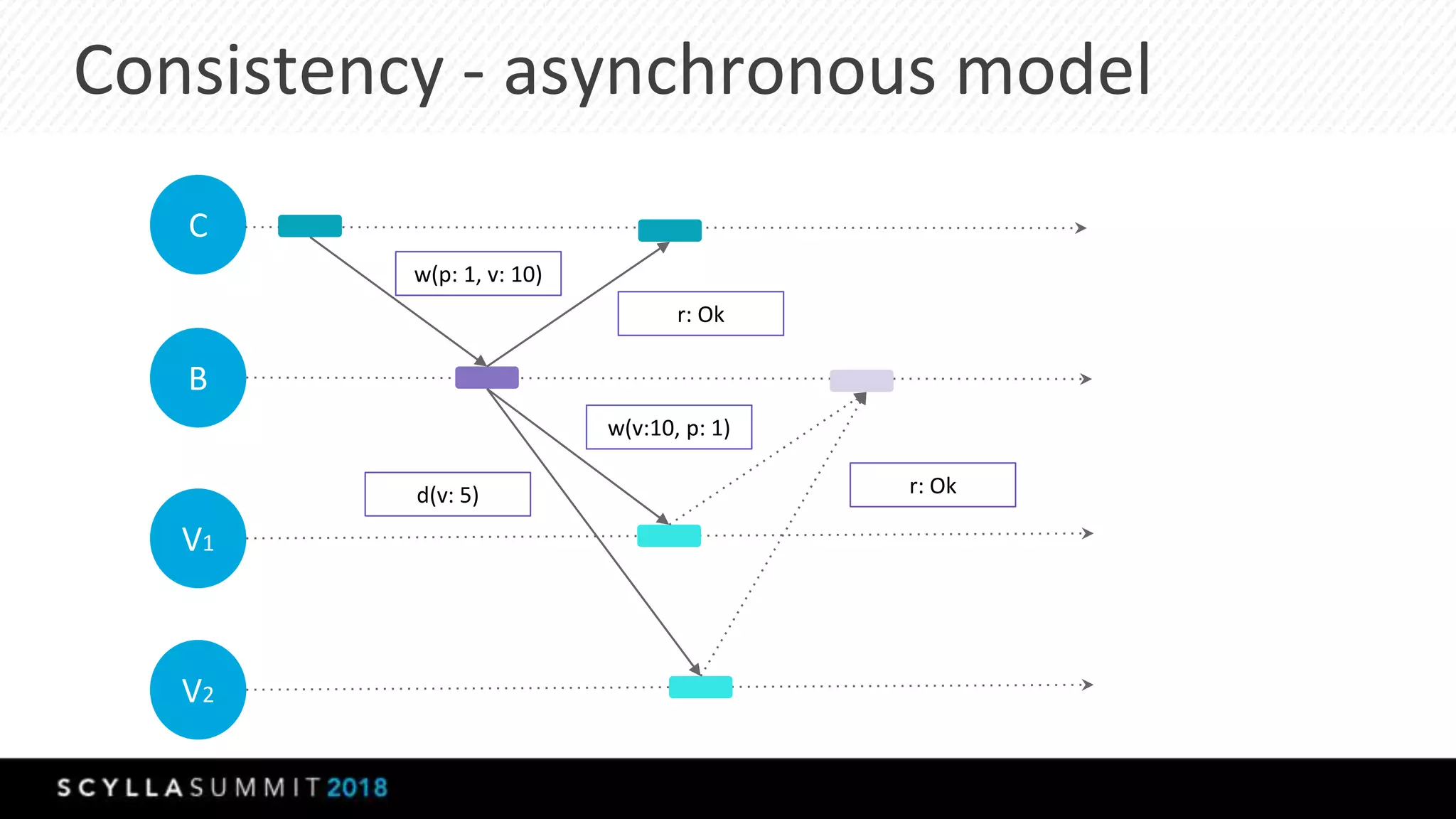
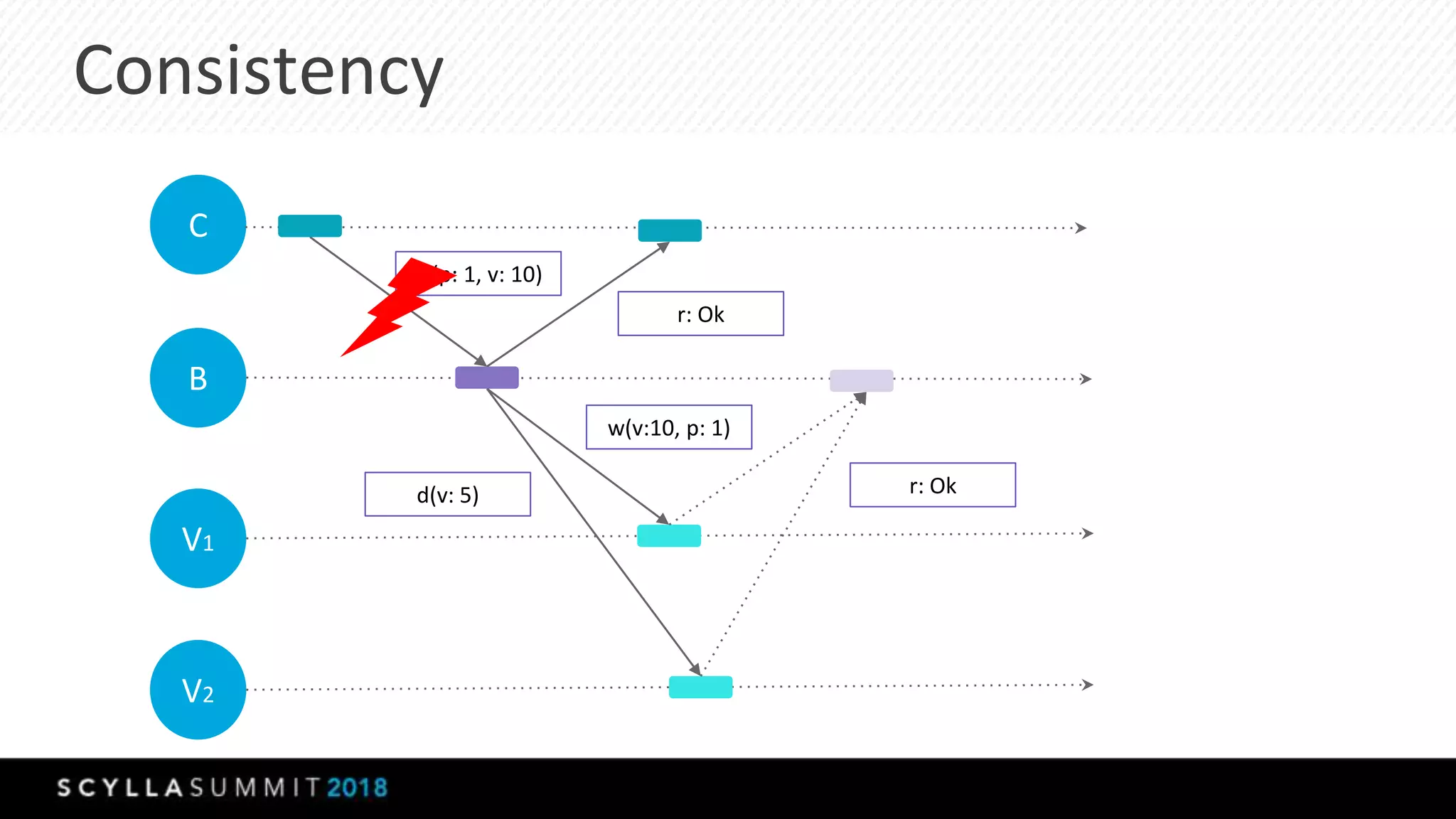
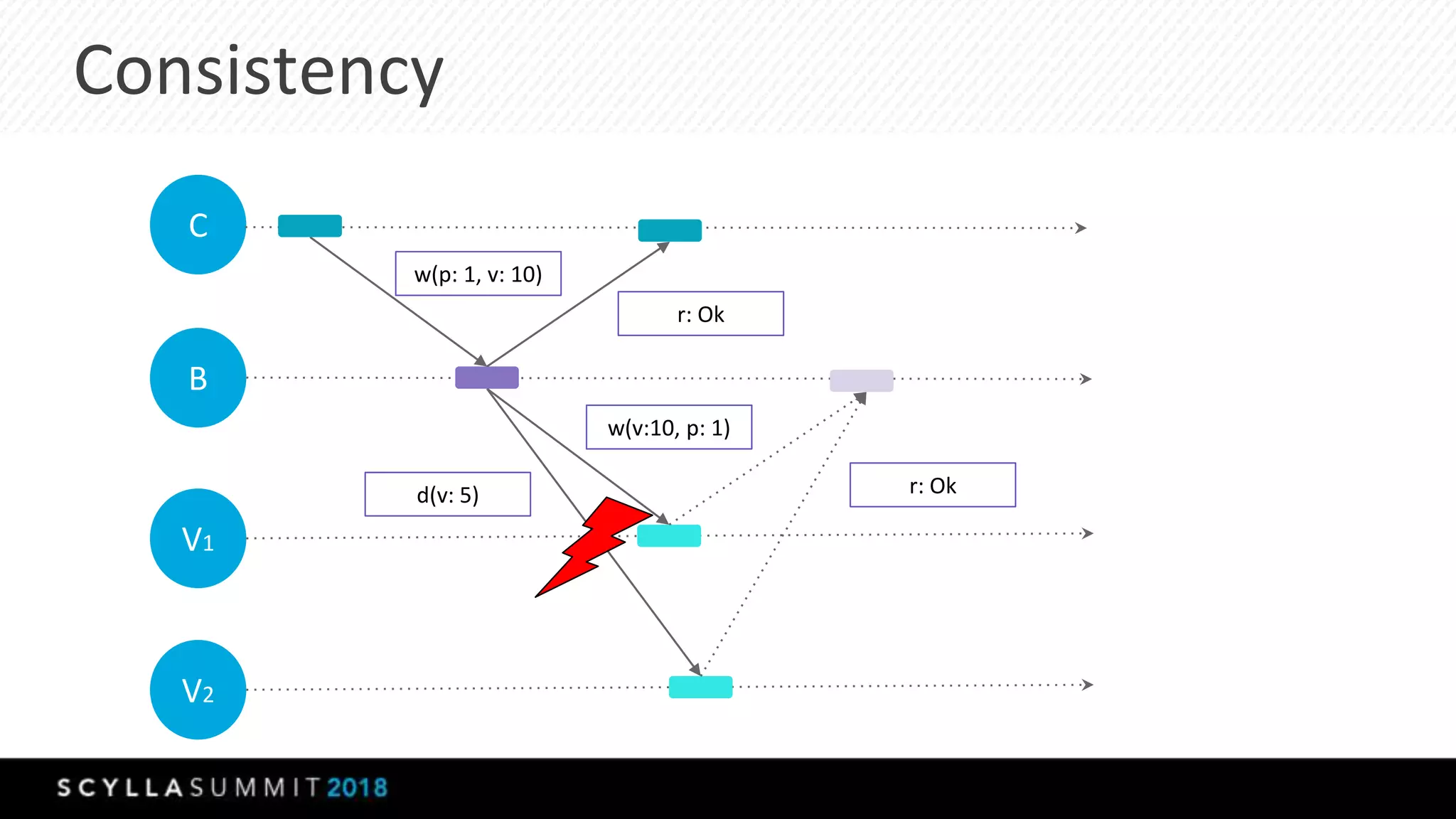
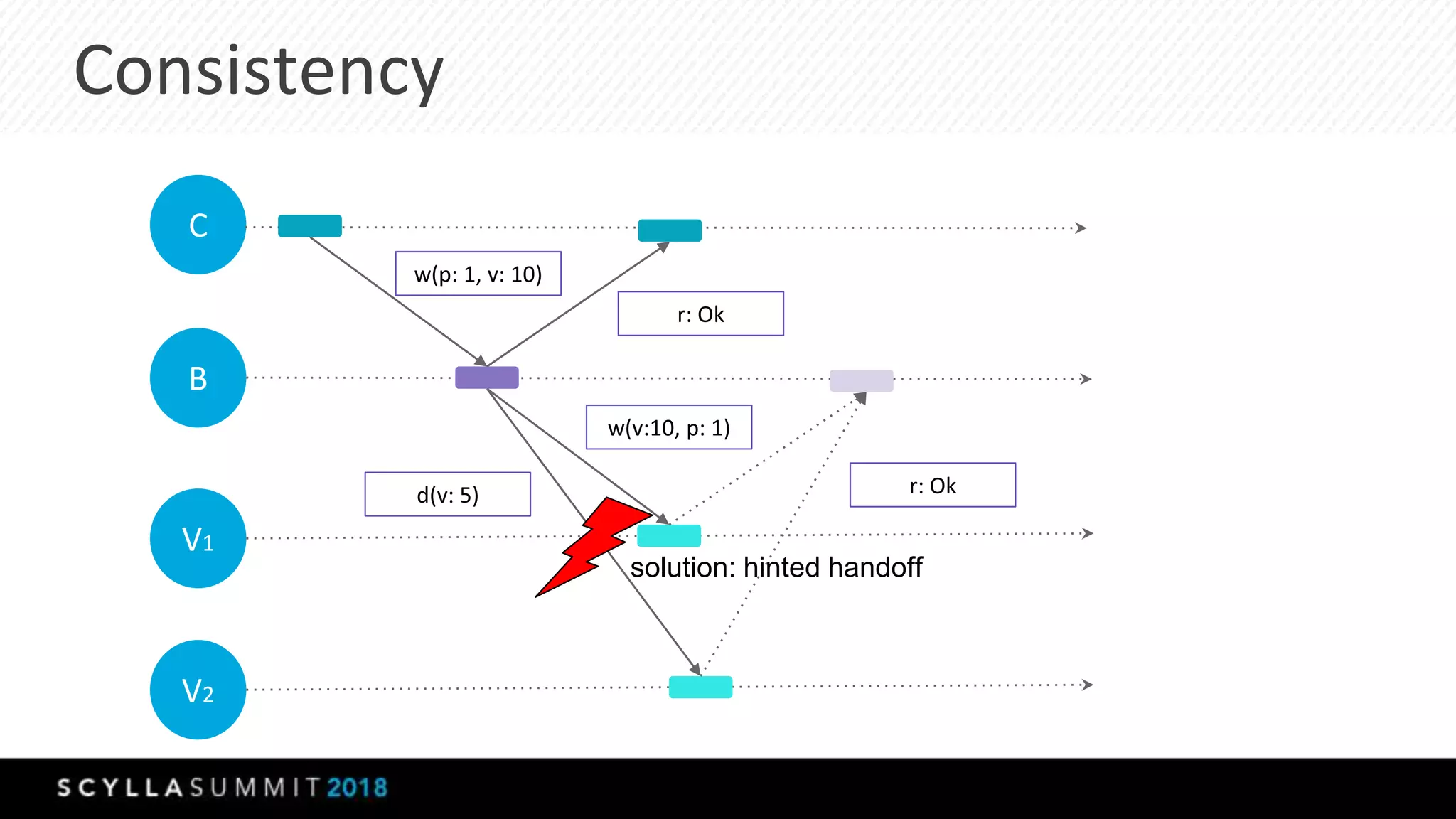










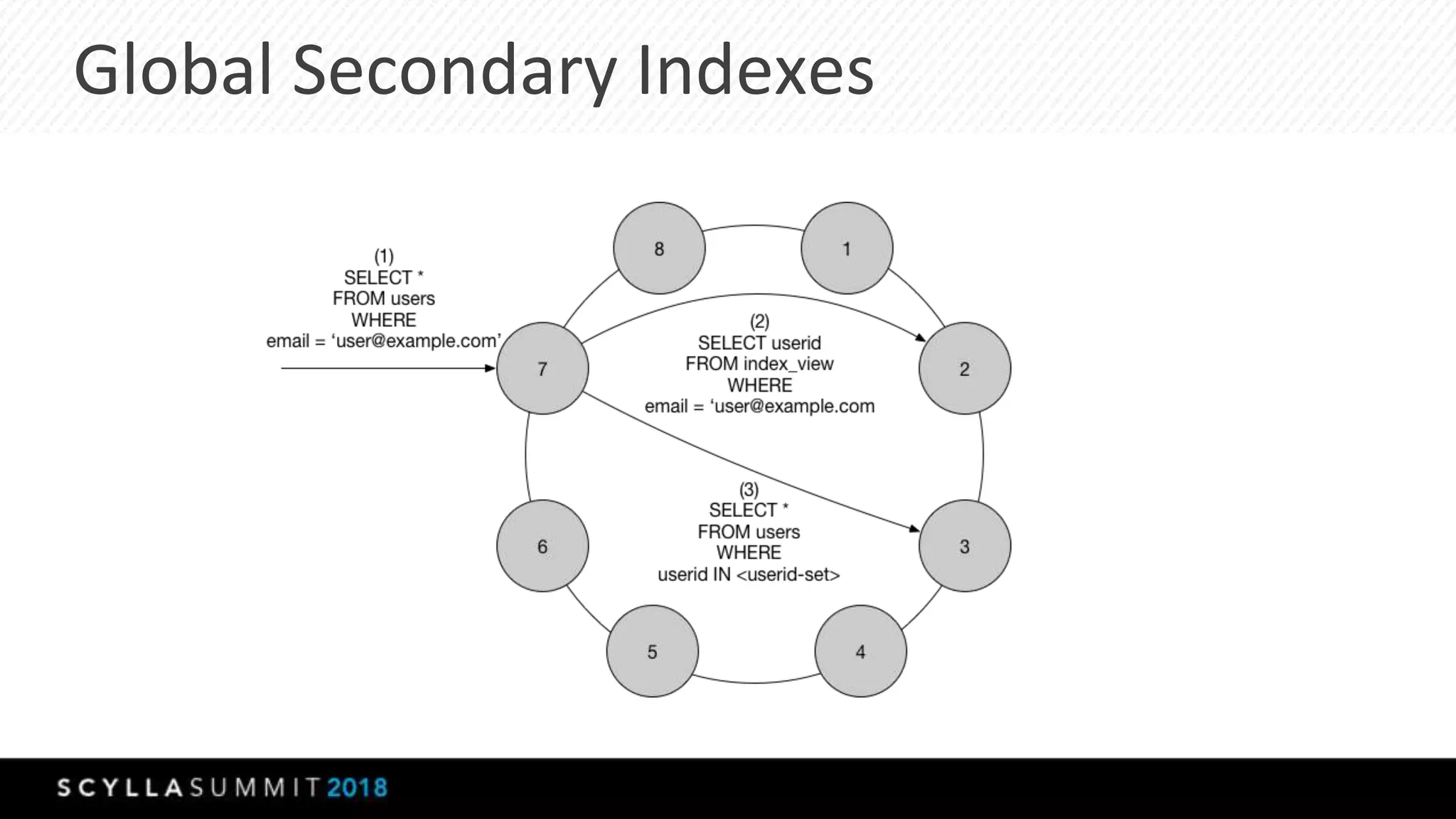


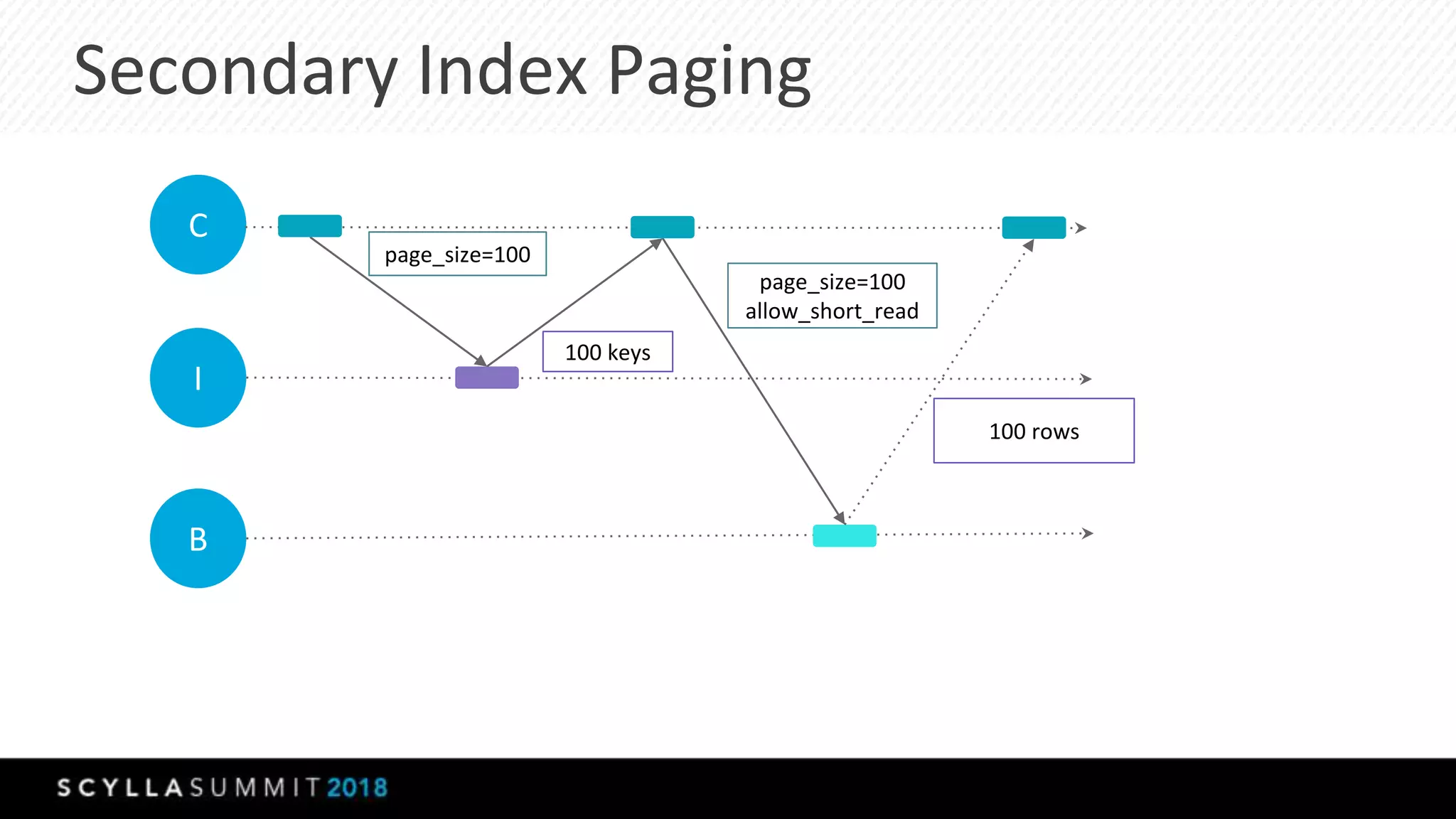
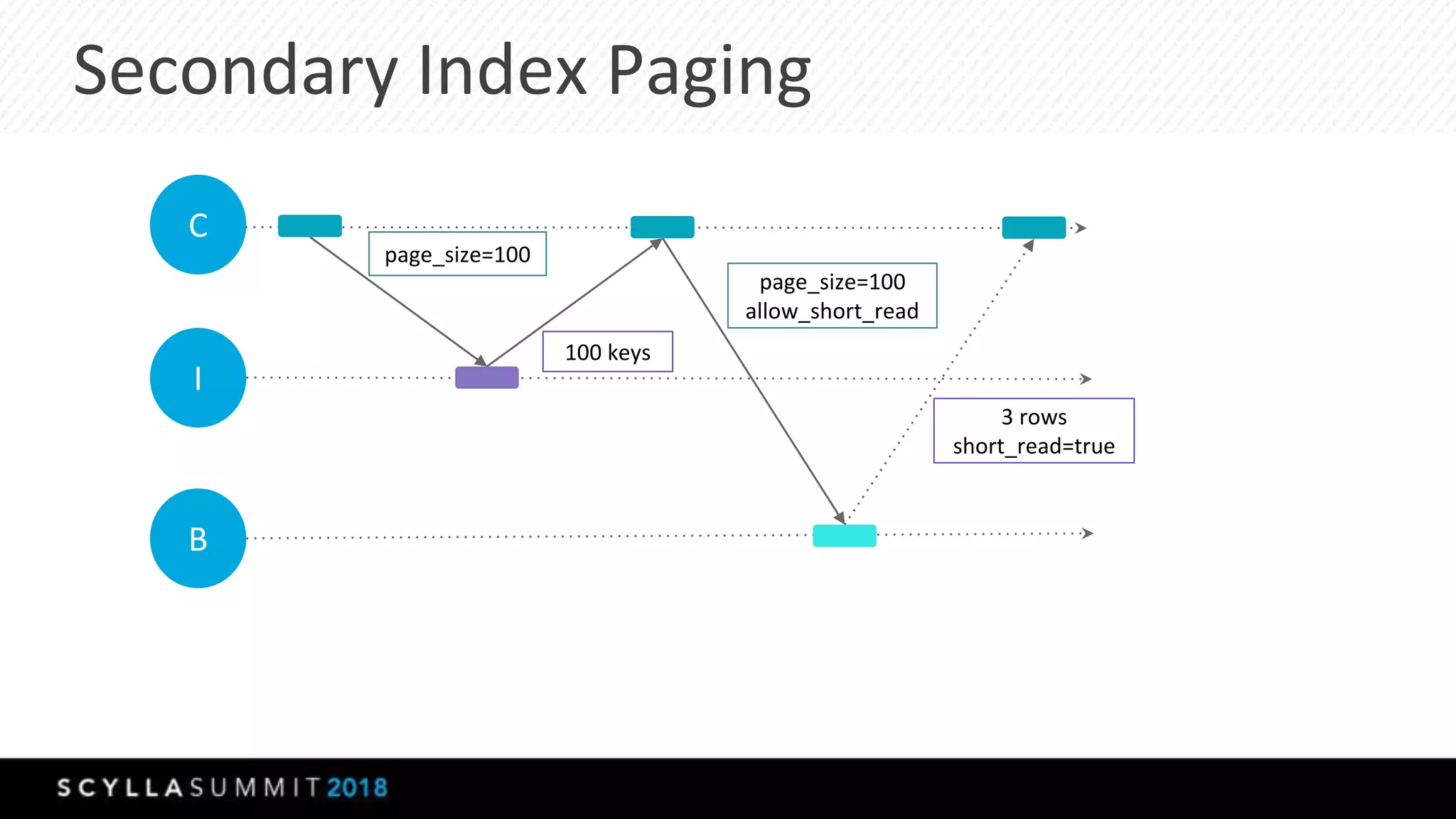





















This document summarizes a presentation about materialized views, secondary indexes, and filtering in ScyllaDB. Materialized views allow querying data by non-primary key columns through automatic denormalization. Secondary indexes provide an alternative through global indexes. Filtering queries that don't use the primary key are now supported with the ALLOW FILTERING option. The presentation covered how these features work, consistency models, and combining indexes with filtering for optimized queries. Future work includes improving materialized view repair and adding selectivity statistics.























































































