PAAS Architecture Strategy for cloud Business Intelligence Solution

The document discusses several aspects of setting up an infrastructure on AWS to support data and applications for multiple countries. Key points include: 1. The architecture would leverage multiple AWS availability zones to distribute workload and ensure high availability. Data would be partitioned by country and each availability zone would host data for a specific country/zone. 2. Backup strategies and disaster recovery plans are discussed, including regular S3 backups, RDS multi-AZ deployments, and replicating data across regions. 3. Infrastructure considerations for supporting many countries include distributing load across regions using Elastic Load Balancing, scripting the infrastructure for automation and quick deployment to new countries, and using services like Route53 and CloudFront for international domains
![with RRS, data is replicated fewer times, so the cost is less. Amazon S3 standard storage is
designed to provide 99.999999999% durability and to sustain the concurrent loss of data in two
facilities, while RRS is designed to provide 99.99% durability and to sustain the loss of data in a
single facility. Both the standard and RRS storage options are designed to be highly available, and
both are backed by Amazon S3’s Service Level Agreement. To get started using RRS and Amazon
S3, visit:http://aws.amazon.com/s3.
SQL Serverread-heavyapplication,youcandistribute the readloadacrossa fleetof synchronizedslaves.
Alternatively,youcanuse a sharding[10] algorithmthatroutesthe data where itneedstobe or youcan
use variousdatabase clusteringsolutions.
Data IntegrationComponentsShoulduse Partitioningatcountrylevel foreachavailabilityzone Code
writtenshouldreflectThispossibilitySoitcanutilize wellthe partitioneddataset
As discussedbelow:Utilize multiple AvailabilityZones:AvailabilityZonesare conceptuallylike logical
datacenters.Bydeployingyourarchitecture tomultipleavailabilityzones,youcanensure highly
availability.Utilize AmazonRDSMulti-AZdeploymentfunctionalitytoautomaticallyreplicatedatabase
updatesacrossmultiple AvailabilityZones.
DR For data hosted:
Amazon RDS Multi-AZDeployments:(ifneeded)
AmazonRDS Multi-AZdeploymentsprovide enhancedavailabilityanddurabilityforDatabase (DB)
Instances,makingthemanatural fitfor productiondatabase workloads.WhenyouprovisionaMulti-AZ
DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronouslyreplicates
the data to a standby instance in a differentAvailabilityZone (AZ).
In case of an infrastructure failure(forexample,instancehardware failure,storage failure,ornetwork
disruption),AmazonRDSperformsanautomaticfailovertothe standby,sothatyou can resume
database operationsassoonas the failoveriscomplete.Since the endpointforyourDB Instance
remainsthe same aftera failover,yourapplicationcanresume database operationwithoutthe needfor
manual administrative intervention.
http://aws.amazon.com/rds/details/multi-az/
Scaleupscale in:
Table Serverlevel clustering :TableauloadbalancedServer(workerServer)WithTableauServerhaving](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (15)
Similar to PAAS Architecture Strategy for cloud Business Intelligence Solution
Similar to PAAS Architecture Strategy for cloud Business Intelligence Solution (20)
More from Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW
More from Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW (20)
Recently uploaded
Recently uploaded (20)
PAAS Architecture Strategy for cloud Business Intelligence Solution
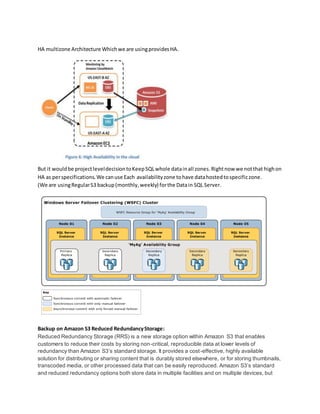
- 1. HA multizone Architecture Whichwe are usingprovidesHA. But it wouldbe projectleveldecisiontoKeepSQLwhole datainall zones.Rightnow we notthat highon HA as perspecifications.We canuse Each availabilityzone tohave datahostedtospecificzone. (We are usingRegularS3 backup(monthly,weekly) forthe Datain SQL Server. Backup on Amazon S3 Reduced RedundancyStorage: Reduced Redundancy Storage (RRS) is a new storage option within Amazon S3 that enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage. It provides a cost-effective, highly available solution for distributing or sharing content that is durably stored elsewhere, or for storing thumbnails, transcoded media, or other processed data that can be easily reproduced. Amazon S3’s standard and reduced redundancy options both store data in multiple facilities and on multiple devices, but
- 2. with RRS, data is replicated fewer times, so the cost is less. Amazon S3 standard storage is designed to provide 99.999999999% durability and to sustain the concurrent loss of data in two facilities, while RRS is designed to provide 99.99% durability and to sustain the loss of data in a single facility. Both the standard and RRS storage options are designed to be highly available, and both are backed by Amazon S3’s Service Level Agreement. To get started using RRS and Amazon S3, visit:http://aws.amazon.com/s3. SQL Serverread-heavyapplication,youcandistribute the readloadacrossa fleetof synchronizedslaves. Alternatively,youcanuse a sharding[10] algorithmthatroutesthe data where itneedstobe or youcan use variousdatabase clusteringsolutions. Data IntegrationComponentsShoulduse Partitioningatcountrylevel foreachavailabilityzone Code writtenshouldreflectThispossibilitySoitcanutilize wellthe partitioneddataset As discussedbelow:Utilize multiple AvailabilityZones:AvailabilityZonesare conceptuallylike logical datacenters.Bydeployingyourarchitecture tomultipleavailabilityzones,youcanensure highly availability.Utilize AmazonRDSMulti-AZdeploymentfunctionalitytoautomaticallyreplicatedatabase updatesacrossmultiple AvailabilityZones. DR For data hosted: Amazon RDS Multi-AZDeployments:(ifneeded) AmazonRDS Multi-AZdeploymentsprovide enhancedavailabilityanddurabilityforDatabase (DB) Instances,makingthemanatural fitfor productiondatabase workloads.WhenyouprovisionaMulti-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronouslyreplicates the data to a standby instance in a differentAvailabilityZone (AZ). In case of an infrastructure failure(forexample,instancehardware failure,storage failure,ornetwork disruption),AmazonRDSperformsanautomaticfailovertothe standby,sothatyou can resume database operationsassoonas the failoveriscomplete.Since the endpointforyourDB Instance remainsthe same aftera failover,yourapplicationcanresume database operationwithoutthe needfor manual administrative intervention. http://aws.amazon.com/rds/details/multi-az/ Scaleupscale in: Table Serverlevel clustering :TableauloadbalancedServer(workerServer)WithTableauServerhaving
- 3. a primarybackup Server. Security:UnileverCloudComputingSecurityStandard.(QuestionsraisedwithnecessaryStakeholderson UnileversecurityComplaince.AboutNIPS,HIPS,Firewalls,WAF,AV,VPN). (These compliance isalreadysharewithGeorge andadocumentisalreadypostedonSharedsite). APPENDIXB:IaaS TECHNICALREQUIREMENTS. B.3 FIREWALLING B.4 SYSTEM & EVENTMANAGEMENT B.5 LOG MANAGEMENT B.6 PROXYSERVICE B.7 ANTI-MALWARE B.8 WEB APPLICATIONFIREWALLING B.9 HIPS B.10 OS CONFIGURATION B.11 OS & PATCH COMPLIANCE B.12 DATABASECONFIGURATION B.13 PATCHING B.14 VULNERABILITYTESTING B.15 ENCRYPTIONDURING TRANSFER
- 4. B.16 SYSTEMS HOSTING CONFIDENTIAL DATA B.17 SYSTEMS HOSTING RESTRICTED DATA B.18 KEY MANAGEMENT SYSTEM B.19 FORENSICS B.20 NON-WEBBASED APPLICATIONS Data design:DependingonModel differencesbetweenEachcountry: Two sectionsof Code will exist:GenericDataIntegrationcode Countryspecificintegrationcode. But The Rulesdrivingthose will be externalizedasdiscussedinPOC.Whichmeansthe afile will have rule specifictoeachcountry.Andthat wouldbe loadedprogrammaticallyeitherByDIof by JavaUI. As Normal BPMsystemWorks.Droolsishighlyconfigurable byJava.A classcan be formed. Data IntegrationComponentsShoulduse Partitioningatcountrylevel foreachavailabilityzone Code writtenshouldreflectThispossibilitySoitcanutilize wellthe partitioneddataset Backup: Factor deciding Backup Strategy: How many hours a day do applications have to access the database? If there is a predictable off-peak period, we recommend that you schedule full database backups for that period. How frequently are changes and updates likely to occur? If changes are frequent, consider the following: o Under the simple recovery model, consider scheduling differential backups between full database backups. A differential backup captures only the changes since the last full database backup. o Under the full recovery model, you should schedule frequent log backups. Scheduling differential backups between full backups can reduce restore time by reducing the number of log backups you have to restore after restoring the data. Are changes likely to occur in only a small part of the database or in a large part of the database? For a large database in which changes are concentrated in a part of the files or filegroups, partial backups and or file backups can be useful. For more information, seePartial Backups and Full File Backups. How much disk space will a full database backup require? For more information, see "Estimating the Size of a Full Database Backup," later in this topic. Changesin Architecture in architecture To reflectmultiple countries. Intra-RegionDataTransfer:Servershouldserve requestbyfromgeographical proximity. Serversshouldbe insame availabilityzonefromwhere service requestarrived.
- 5. DistributedInfrastructure: Distribute Workloadbetweenmultiple availabilityzones betterDRandload balancing workload distributed geographically. How Can This happen:(See Diagram belowFor Two CountriesUS and Canada) AmazonElasticloadbalancerWoulddistribute loadtoEachCountryspecificsubnets. ThismeansEach countrywill have itsownsubnetonitsavailabilityzone andSQLServerwill be on AlwaysOninfrastructure. SQL ServerOnAlwaysOn:
- 6. BeanStalkService forharmonizer Instance Type Upfrontreserved,partial upfrontreversed vsOnDemand.(AsUtilizationof instanceswouldbe round the Time and Whole yearitwouldCostsavingto keepitpartial Upfrontreserve). Disaster Recovery: Usingthe forkliftmigrationstrategy,the teamwas able tomove mostof the components –AppServer and RulesEngine applicationonWindowsserverinstancesinEC2.Scripts runperiodicallyandtake snapshotsof EBS volumeseveryday.AMIsof everyinstance type were createdandwere configured such that instancescanbe stoppedandrestartedeasily.Datawasreplicatedfromthe ClaimsDBevery hour to the cloudusingbidirectional transactional replication.The teamcreatedadditional scriptsto monitorthe healthof the systemandapplicationavailability,andtonotifyon-call systemadministrators incase of anysuspiciousbehaviorinordertobringup the entire applicationinthe cloudwithinafew minutes(cloud-baseddisasterrecoverysolution).
- 7. Scriptable Infrastructure: APIDriveninfrastructure WouldhelpinautomatingAcrossdifferentregions. ThiswouldaddTo maintainabilityandScalingtonew countriestoreflectnew requirements.Forsome of the testingneeds . AWSCloud Formation:Create and maintainAWSinfrastructure describedependencies, runtime parametersrequiredtorunapplications. deployandupdate atemplate anditsassociatedcollectionof resources(calledastack) byusingthe AWS ManagementConsole,AWSCommandLine Interface,or APIs.CloudFormationisavailable atnoadditional charge,andyoupayonlyfor the AWS resources neededtorunyour applications. AutoScaling:Web applicationof SaamaFluidAnalytics. Whenwillthisbe useful? For scalingSFA basedWebapplications: AutoScalingcan alsoautomaticallyincrease the numberof AmazonEC2 instancesduringdemandspikes to maintainperformance anddecrease capacityduringlullstoreduce costs.AutoScalingiswell suited bothto applicationsthathave stable demandpatternsorthatexperience hourly,daily,orweekly variabilityinusage. Typical Example fromBatchprocessingapplications. EfficientDevelopment/deploymentLife cycle. We have 90 Countriestocoverinnext2 years.Average 4country permonth.We wouldhave to create efficientQuickdeployable infrastructure ForwhichWe needsystemswhere we canpromote like Staging instancestoproduction. SFA managementVMwouldbe perfectfitforthat (since ithasSFA Management+ AndDI Jobscan be put there + SFTPserverConfigured) itwill startmimickingProductioninstance.Simulatedrunand SanitationTestcan be done here.Thenitcan be quicklyclonedtoproduction. Same is possible forTableauServerforall tableauReports. CloudenforcesLoose CouplingTo utilize resourcesbetterway on Each Layer (Web/App/DBLayer):
- 8. The keyis to buildcomponentsthatdonothave tightdependenciesoneachother,sothatif one componentwere todie (fail),sleep(notrespond) orremainbusy(slow torespond) forsome reason,the othercomponentsinthe systemare builtsoas to continue toworkas if no failure ishappening How can we leverage. For Each Availabilitygroup. Capacity planningfor Each Servers will dependsonapplicationsrunning On Server. For TableauServerForexample We needtoknow Workloadontableau serverwhichwill drive the hardware capacity(CPU,RAM,Space requirements) requirement. For TableauAdminThere are reportsusingwhichH/Winfrarequirementcanbe monitored. Tableau Server Capacity Analysis View Analysis Server Activity A dashboard view showing recentactivity on the server User Activity A view describing user activity, including sign-in time,hostname,and idle time View Performance History A view describing server activity broken down by view Background Tasks A view showing completed and pending task details Space Usage A dashboard view showing the space used bypublished workbooks and data sources
- 9. Customized Views A dashboard view showing utilization ofcustomized views ServerActivity: Performance History
- 10. Space Used StatisticsbyUser andProject The ServerStatisticshave tobe collected oneachServerundersimulatedruntoplanforthe Capacityfor Each serverfor whichEach HarmonizerandTableauteamhave to do separate Capacityplanning. Internationalization: Route53 Service todomainnamescanbe usedforinternationalizationhereislinkprovidedHow todo it?This can usedto create DistributedDNSentries. http://docs.aws.amazon.com/Route53/latest/DeveloperGuide/registrar.html#domain-register Additional Points: - factors considered for capacity planning of servers for each hardware component? Concurrent Users, Load (already Questions are there in List) - infrastructure placement (on cloud) viz-a-viz distributed Unilever infrastructure Geographic proximity Data Centre by cloud regions defined Availability Zones.(Discussed above in detail) - Level of hardware utilization monitoring we need to have in place for different hardware components AWS CloudFront Service Reports define parameters to be analyzed Over AWS infrastructure. - How the data should be organized for multiple countries Architecture is detailed above - Software compatibility and extensibility for multi-country and multi-language expansion CloufrontService :ForTracking usage of each service andSystemwithinAWSenvironment. Reportsof cloudfront can utilizedtrackusage.