Download as PDF, PPTX




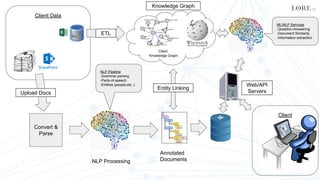









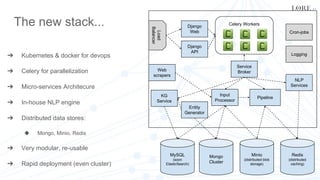






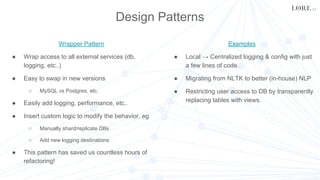






This document summarizes the development of Lore's machine learning and NLP platform using Python. It started as a monolithic Python server but evolved into a microservices architecture using Docker, Kubernetes, and Celery for parallelization. Key lessons included using DevOps tools like Docker for development and deployment, Celery to parallelize tasks, and wrapping services to improve modularity, flexibility, and performance. The platform now supports multiple products and consulting work in a scalable and maintainable way.























































































