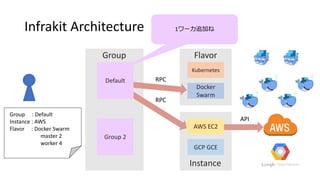
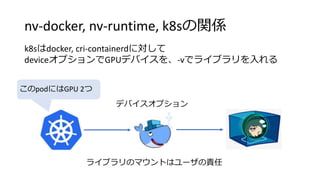
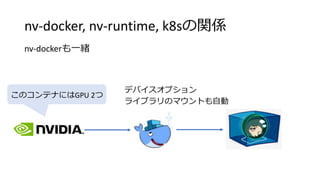
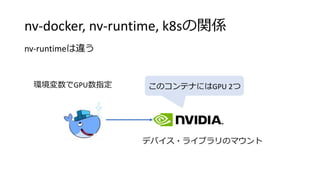
#8 This is little more details about implementation.
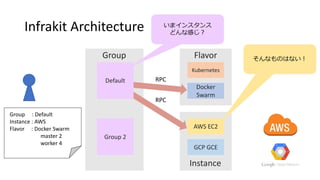
Each of plug-ins are running as go process and Infrakit discovers them through Unix socket.
And plug-ins communicate each other with rpc.
#9 Now, I will talk about the flow of using Infrakit.
First, you send a configuration of cluster to Infrakit and it will be sent to group plug-in.
In this example, Using default group plug-in, aws instance plug-in and docker swarm flavor plug-in.
And you define the desired state of your cluster.
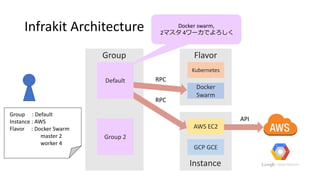
Now, it is 2 masters and 4 workers for docker swarm.
#10 Then the group plugin check the state of your cluster through flavor and instance plug-in.
now, there are no instance.
#11 The group plugin send the required number of instances to instance and flaver plug-ins with rpc.
It need to deploy 2 masters and 4 workers now.
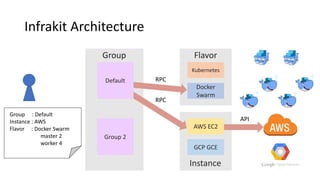
#12 And then, Instance plug-in gather information that will be needed to deploy instance from flavor plug-in and deploy instances by cloud provider’s API.
#13 Now, some failure occurred in your cluster.
One of your worker died unexpectedly.
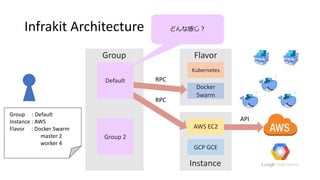
#14 Group plug-in has been polling the state of your cluster.
How many instances are running? Are all nodes healthy?
#15 So the Group plug-in can notice a node has gone down because the instance plug-in report number of only healthy nodes.
In this case, instance plugin reports 2 master and only 3 workers are running.
#16 Then, the group plug-in will request to instance and flavor plug-ins to maintain your desired state.
This is the basic behavior of provisioning and auto-healing of Infrakit.