Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masao Taketani
PPTX, PDF
2,016 views
New tf.keras
TensorFlow User Group Tokyo主催の「Recap of TensorFlow Dev Summit 2019」で発表した新しいtf.kerasについてのスライドです。
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 13 times
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PPTX
卒業研究進捗報告
by
Takuma KATANOSAKA
PDF
20090616 フレッシュマンセミナー
by
Takeo Kunishima
PDF
20080702フレッシュマンセミナー
by
Takeo Kunishima
PDF
IBIS2011 企画セッション「CV/PRで独自の進化を遂げる学習・最適化技術」 趣旨説明
by
Akisato Kimura
PDF
Curiosity driven exploration
by
Takuya Minagawa
PDF
20170211クレジットカード認識
by
Takuya Minagawa
PDF
「コンピュータビジョン勉強会@関東」紹介資料
by
Takuya Minagawa
PDF
【ECCV 2018】Zero-Shot Deep Domain Adaptation
by
cvpaper. challenge
卒業研究進捗報告
by
Takuma KATANOSAKA
20090616 フレッシュマンセミナー
by
Takeo Kunishima
20080702フレッシュマンセミナー
by
Takeo Kunishima
IBIS2011 企画セッション「CV/PRで独自の進化を遂げる学習・最適化技術」 趣旨説明
by
Akisato Kimura
Curiosity driven exploration
by
Takuya Minagawa
20170211クレジットカード認識
by
Takuya Minagawa
「コンピュータビジョン勉強会@関東」紹介資料
by
Takuya Minagawa
【ECCV 2018】Zero-Shot Deep Domain Adaptation
by
cvpaper. challenge
What's hot
PDF
Arに対する古典分子動力学シミュレーション
by
dc1394
PDF
SchracVisualizeによる波動関数の可視化
by
dc1394
PDF
水素原子に対するSchrödinger方程式の数値解法
by
dc1394
PDF
20170806 Discriminative Optimization
by
Takuya Minagawa
PDF
20160417dlibによる顔器官検出
by
Takuya Minagawa
PDF
第34回CV勉強会「コンピュテーショナルフォトグラフィ」発表資料
by
Takuya Minagawa
PDF
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
PDF
Point net
by
Fujimoto Keisuke
Arに対する古典分子動力学シミュレーション
by
dc1394
SchracVisualizeによる波動関数の可視化
by
dc1394
水素原子に対するSchrödinger方程式の数値解法
by
dc1394
20170806 Discriminative Optimization
by
Takuya Minagawa
20160417dlibによる顔器官検出
by
Takuya Minagawa
第34回CV勉強会「コンピュテーショナルフォトグラフィ」発表資料
by
Takuya Minagawa
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
Point net
by
Fujimoto Keisuke
Similar to New tf.keras
PPTX
tfug-kagoshima
by
tak9029
PPTX
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
PPTX
AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」【旧版】※新版あります
by
fukuoka.ex
PPTX
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
PPTX
葉物野菜を見極めたい!by Keras
by
Yuji Kawakami
PDF
Python初心者がKerasで画像判別をやってみた
by
KAIKenzo
PDF
第3回機械学習勉強会「色々なNNフレームワークを動かしてみよう」-Keras編-
by
Yasuyuki Sugai
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PDF
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
PDF
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
PDF
TensorFlow DevSummitを概観する
by
Y OCHI
PDF
機械学習フレームワーク横断、Chainer, Keras
by
Teppei Murakami
PDF
深層学習基礎勉強会資料
by
shinya murakawa
PPTX
Human Brain to Tensorflow in 5 Minutes
by
James Neve
PPTX
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PDF
TensorFlowで遊んでみよう!
by
Kei Hirata
PDF
2018年01月27日 Keras/TesorFlowによるディープラーニング事始め
by
aitc_jp
PDF
#経済学のための実践的データ分析 12. 機械学習とAIな経済学と最終レポート
by
Yasushi Hara
PDF
Enjoy handwritten digits recognition AI !!
by
KAIKenzo
tfug-kagoshima
by
tak9029
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」【旧版】※新版あります
by
fukuoka.ex
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
葉物野菜を見極めたい!by Keras
by
Yuji Kawakami
Python初心者がKerasで画像判別をやってみた
by
KAIKenzo
第3回機械学習勉強会「色々なNNフレームワークを動かしてみよう」-Keras編-
by
Yasuyuki Sugai
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
TensorFlowの使い方(in Japanese)
by
Toshihiko Yamakami
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
TensorFlow DevSummitを概観する
by
Y OCHI
機械学習フレームワーク横断、Chainer, Keras
by
Teppei Murakami
深層学習基礎勉強会資料
by
shinya murakawa
Human Brain to Tensorflow in 5 Minutes
by
James Neve
Deep Learning基本理論とTensorFlow
by
Tadaichiro Nakano
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
TensorFlowで遊んでみよう!
by
Kei Hirata
2018年01月27日 Keras/TesorFlowによるディープラーニング事始め
by
aitc_jp
#経済学のための実践的データ分析 12. 機械学習とAIな経済学と最終レポート
by
Yasushi Hara
Enjoy handwritten digits recognition AI !!
by
KAIKenzo
New tf.keras
1.
New tf.keras Masao Taketani
(竹谷 昌夫)
2.
自己紹介 (Self-Introduction) 名前(name):竹谷 昌夫
(Masao Taketani) 学歴(education):アメリカの大学の理工学部統計学科を卒業 (BS in Statistics) 職業(occupation):ディープラーニングエンジニア (Deep Learning Engineer) 業務では主に画像系を担当するが、業務外では自然言語処理やレコメンドも経験あり
3.
今までの tf.keras モデル構築がシンプルでPythonicな書き方ができる。ただ、小さなモデル構築用 に作られており、大規模なモデル構築用ではなかった。
4.
tf.estimator そこで、スケーラビリティを意識したAPIとしてtf.estimatorがあった。 tf.estimatorを使用すれば分散学習も容易に行える。tf.estimatorならWide & Deep Learning等のモデルもbuilt-inとして備わっており、学習や、本番環境用に デプロイすることが容易に可能。
5.
新しい tf.keras TensorFlow 2.0からは、モデルの構築に関しては今までのtf.kerasと同じ書き方 で書けるように標準化し、そこにtf.estimatorも持ってくることでtf.kerasからプ ロトタイプ作成、分散学習、そして本番環境へのデプロイまでが容易にできるよ うになった。
6.
古いtf.kerasでのモデルの書き方
7.
新しいtf.kerasでのモデルの書き方
8.
新しいtf.kerasのその他の特徴 ● 今までのtf.kerasはグラフ構造を基にし、sessionを走らせることでデータを 投入していたが、新しいtf.kerasではEager modeでデータを投入させること ができる(Define
by Run)。 ● データセットのパイプラインはnumpy配列の様に扱うことができ、デバッグ も楽になる。かつ同時にデータセットも高いパフォーマンスのためにオーバ ヘッドができるだけかからないように最適化される。
9.
Eagerモード ● Eagerモードでもグラフの利点をそのまま残している。 ● Eagerはデバッグやプロトタイプ作成を容易にさせるが、一方でTensorFlow のランタイムがパフォーマンスやスケーリングの最適化の役割を賄う。 ●
「run_eagarly」というフラグを使用することによって、明示的にeagerモー ドでモデルをステップバイステップに走らせることができる。
10.
多くのAPIをわかりやすく統合 ● optimizers、metrics、losses、layersはtf.kerasの下にそれぞれ一つのセッ トに統合され、eagerモードの使用、単独での学習か分散での学習かによら ず使用できる。 ● built-inにないものを利用したい際も、サブクラスを用いてカスタマイズする ことができる。 ●
layersにおいてはkerasのAPI仕様書に書いてあるものはすべて使用可能。
11.
RNNレイヤーの変更 今までのTensorFlowではいくつかのLSTMとGRUのバージョンがあり、cuDNNを 使用する際は実行する前に記載する必要があったが、新しいバージョンでは LSTMもGRUも一つのバージョンしかなく、CPUを使用するかGPUを使用するか は利用状況により、ランタイム時に自動で行ってくれる。
12.
tf.kerasからtf.feature_columnが使用可能 tf.feature_columnは生データをestimatorが必要なフォーマットに変換する役目 を担っていたが、TensorFlow 2.0ではtf.kerasで作られたモデルにも tf.feature_columnが使用できるようになった。
13.
tf.kerasからTensorBoardの使用 ● tf.kerasでTensorBoardを使用する際は一行で簡単に書くことができる。 ● TensorBoardでaccuracy、loss、モデルの形状等が見れる。 ●
モデルのパフォーマンスやデバイスの配置確認、学習時のボトルネックを容 易に見つけることができるようなフルプロファイリング機能を追加。
14.
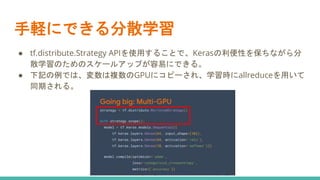
手軽にできる分散学習 ● tf.distribute.Strategy APIを使用することで、Kerasの利便性を保ちながら分 散学習のためのスケールアップが容易にできる。 ●
下記の例では、変数は複数のGPUにコピーされ、学習時にallreduceを用いて 同期される。
15.
モデルのセーブ/ロード ● 本番環境、スマホ、またはPython以外の言語で利用するために、モデルのセ ーブやロードも簡単に行える。 ● この機能はまだ実験段階(APIの詳細を調整中)だが、TF
Serving、TF Lite等に 簡単にエクスポートしたり、再学習のためにリロードできるようになってい る。
16.
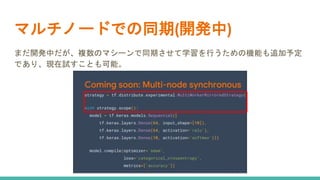
マルチノードでの同期(開発中) まだ開発中だが、複数のマシーンで同期させて学習を行うための機能も追加予定 であり、現在試すことも可能。
17.
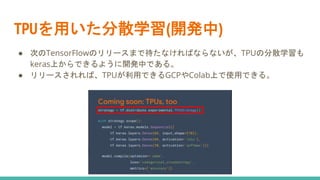
TPUを用いた分散学習(開発中) ● 次のTensorFlowのリリースまで待たなければならないが、TPUの分散学習も keras上からできるように開発中である。 ● リリースされれば、TPUが利用できるGCPやColab上で使用できる。
18.
2.0のファイナルバージョンに向けて 2.0の完成に向けて以下のスケーラビリティをtf.kerasに付け加えようとしている 。 ・tf.kerasからのParameterServerStrategyの利用 ・tf.kerasからのestimatorのモデル(Wide & Deepモデル等)利用 ・巨大なモデルを扱うためのvariable
partitioning
19.
tf.thanks!
Download