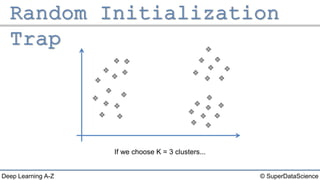
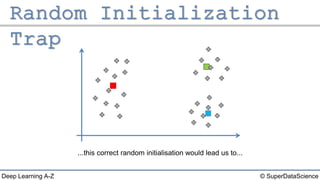
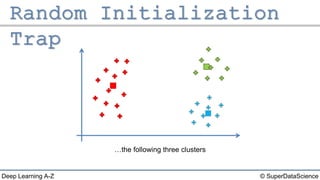
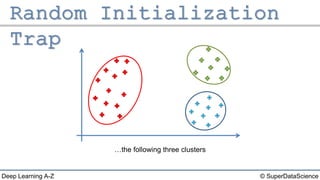
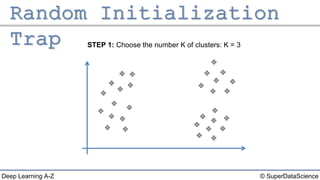
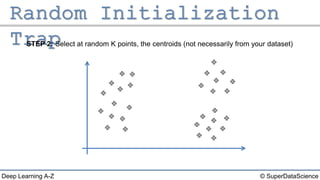
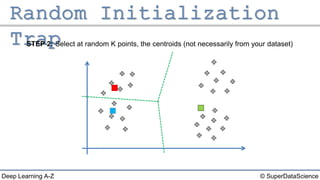
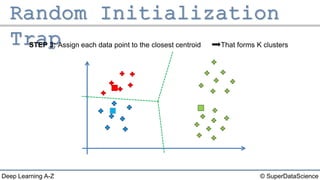
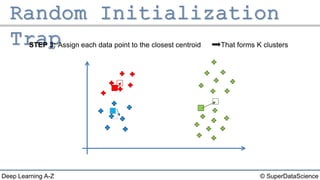
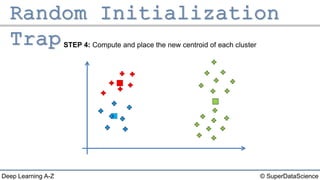
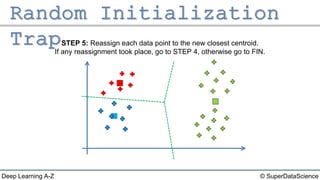
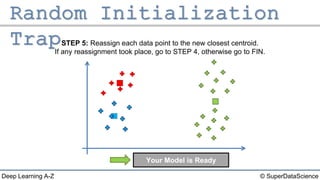
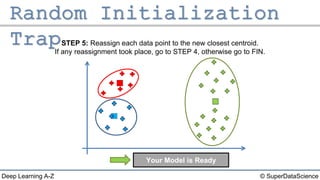
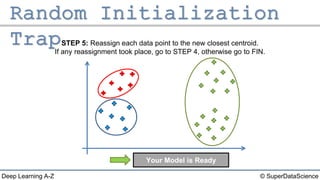
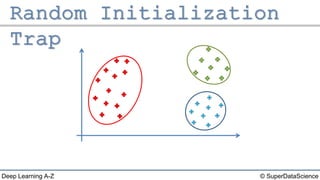
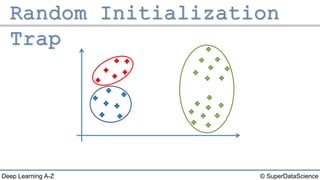
The document outlines the k-means clustering algorithm. It describes the steps of choosing the number of clusters k, randomly selecting k points as initial centroids, assigning all points to the closest centroid, recomputing the centroids, and reassigning points in an iterative process until cluster assignments stop changing. It notes that a bad initial random selection of centroids could negatively impact the resulting clusters.