Downloaded 27 times

![Adjective
Expected, especially on the basis
of previous or known behavior
Predictable
[pri-dik-tuh-buh l]
@everydaykanban
USUALLY
________!](https://image.slidesharecdn.com/predictability-webinar-170629155922/75/Predictability-No-Magic-Required-LeanKit-Webinar-June-2017-2-2048.jpg)



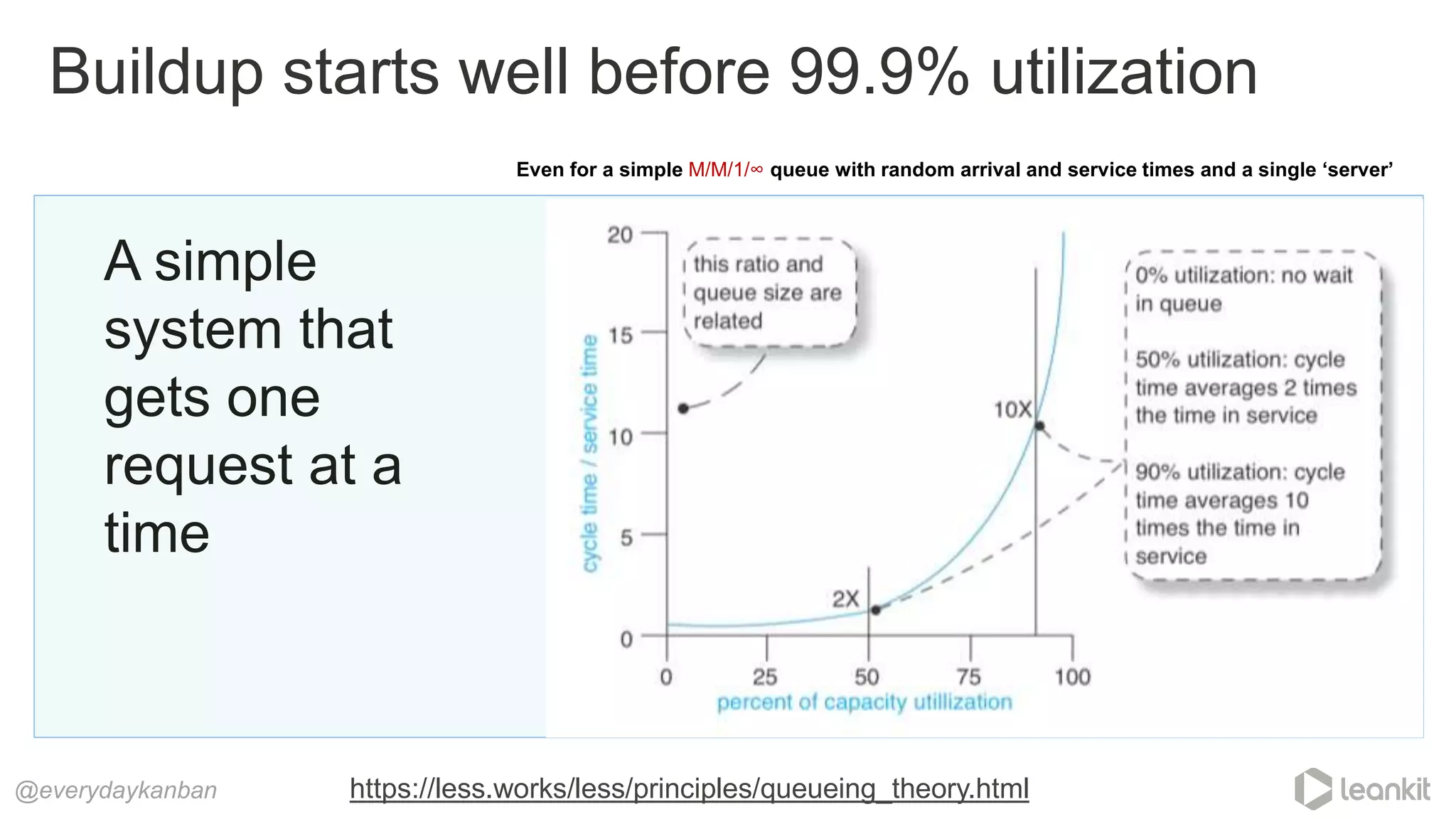
![Request size Utilization Cycle Time
Single item
requests
50% 2x Time in service
90% 10x Time in service
Big Batch
requests
50% 5x Time in Service
90% 22x Time in Service
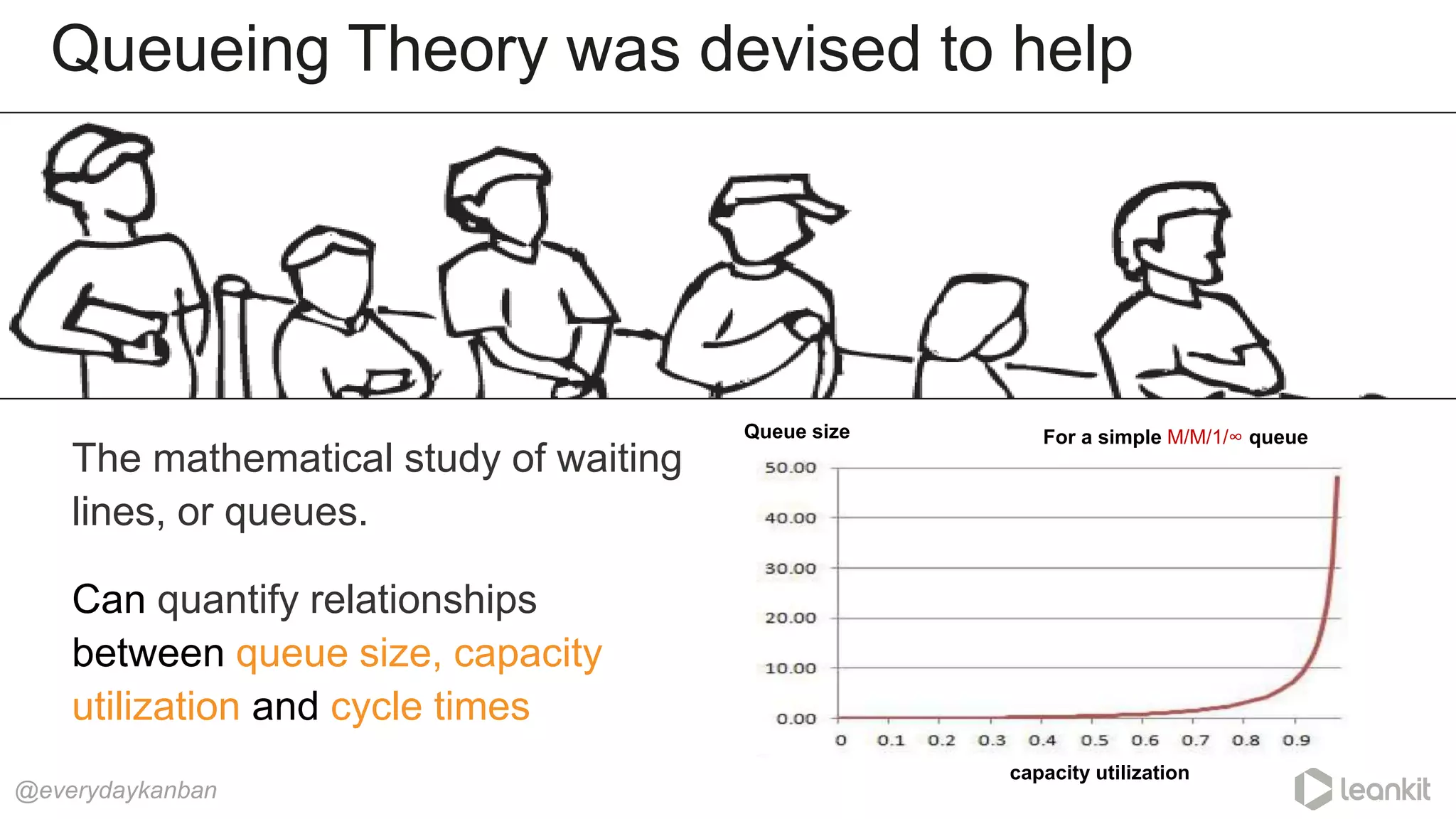
What about queues that aren’t so simple?
@everydaykanban https://less.works/less/principles/queueing_theory.html
Big Batches with random arrivals and service times: M[x]/M/1/∞ queue](https://image.slidesharecdn.com/predictability-webinar-170629155922/75/Predictability-No-Magic-Required-LeanKit-Webinar-June-2017-13-2048.jpg)

![“100% of developers
[that I surveyed] measured
cycle time.
2% measured queues.”
@everydaykanban
Donald Reinertsen
The Principles of Product Development Flow (2009)](https://image.slidesharecdn.com/predictability-webinar-170629155922/75/Predictability-No-Magic-Required-LeanKit-Webinar-June-2017-16-2048.jpg)
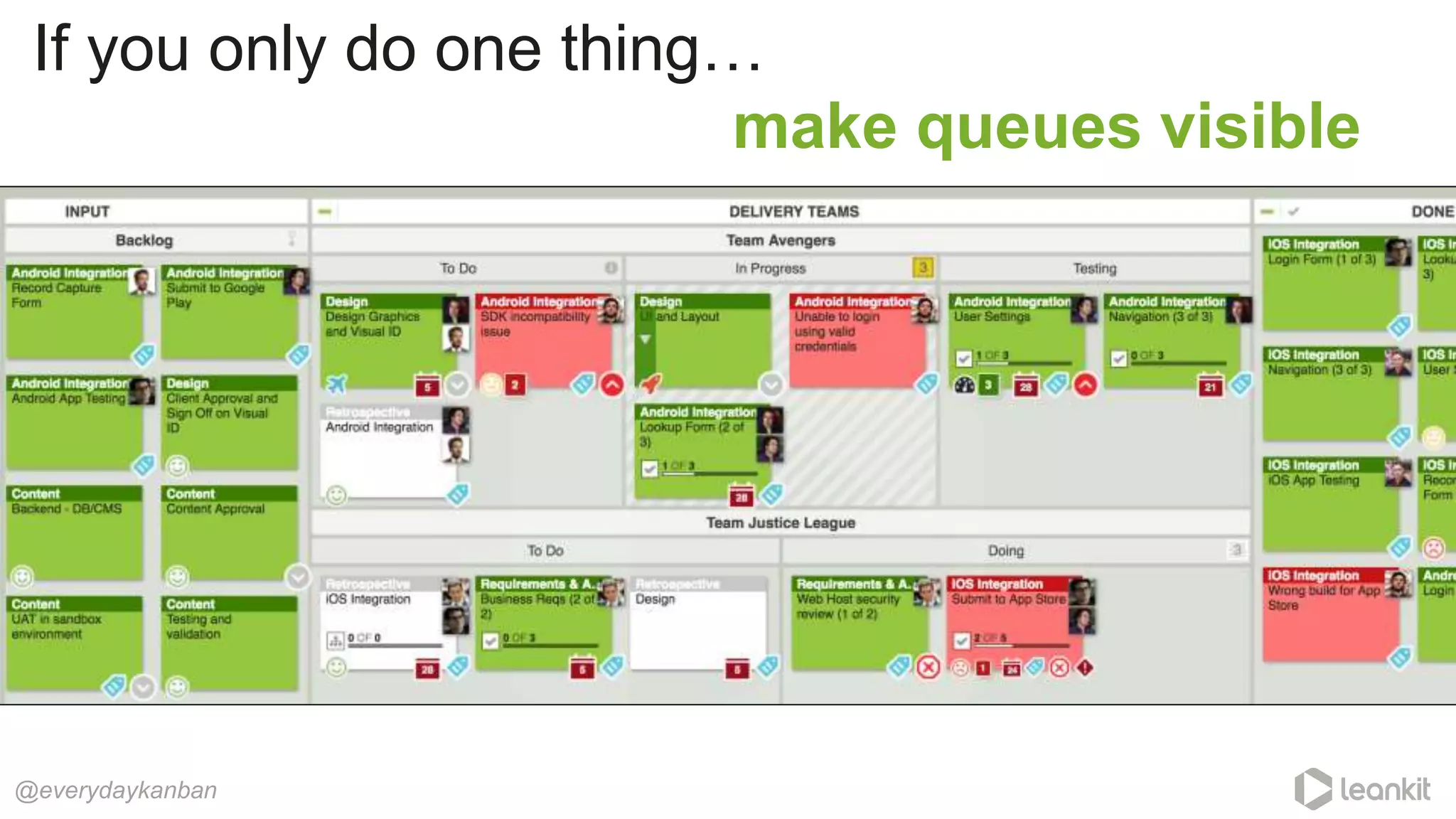





![“Business units that embraced
[process/queue management] reduced their
average [product] development times by 30%
to 50%.”
@everydaykanban
OnPoint - HBR.org
Getting the most out of your product development process (2003)](https://image.slidesharecdn.com/predictability-webinar-170629155922/75/Predictability-No-Magic-Required-LeanKit-Webinar-June-2017-24-2048.jpg)

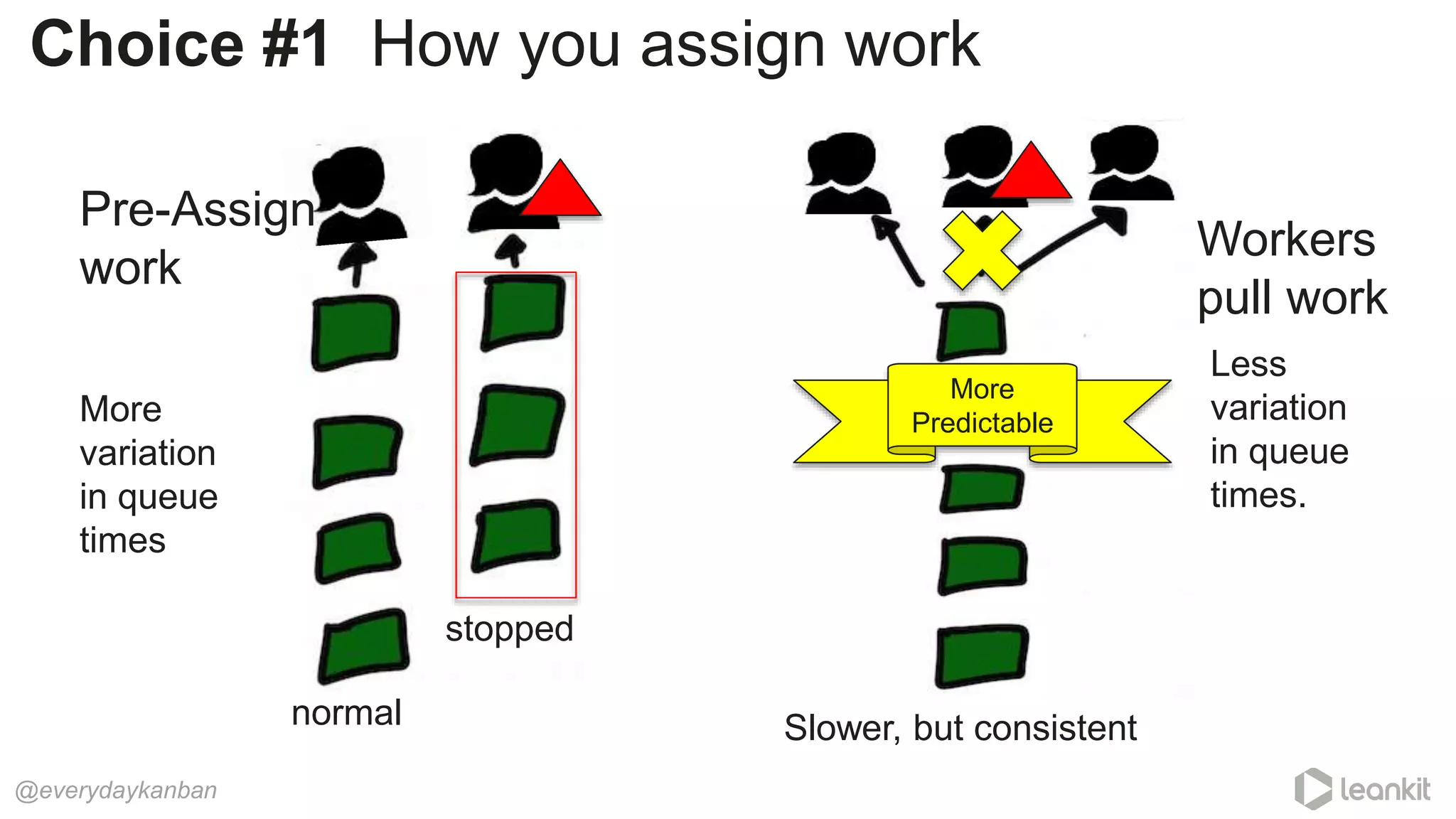
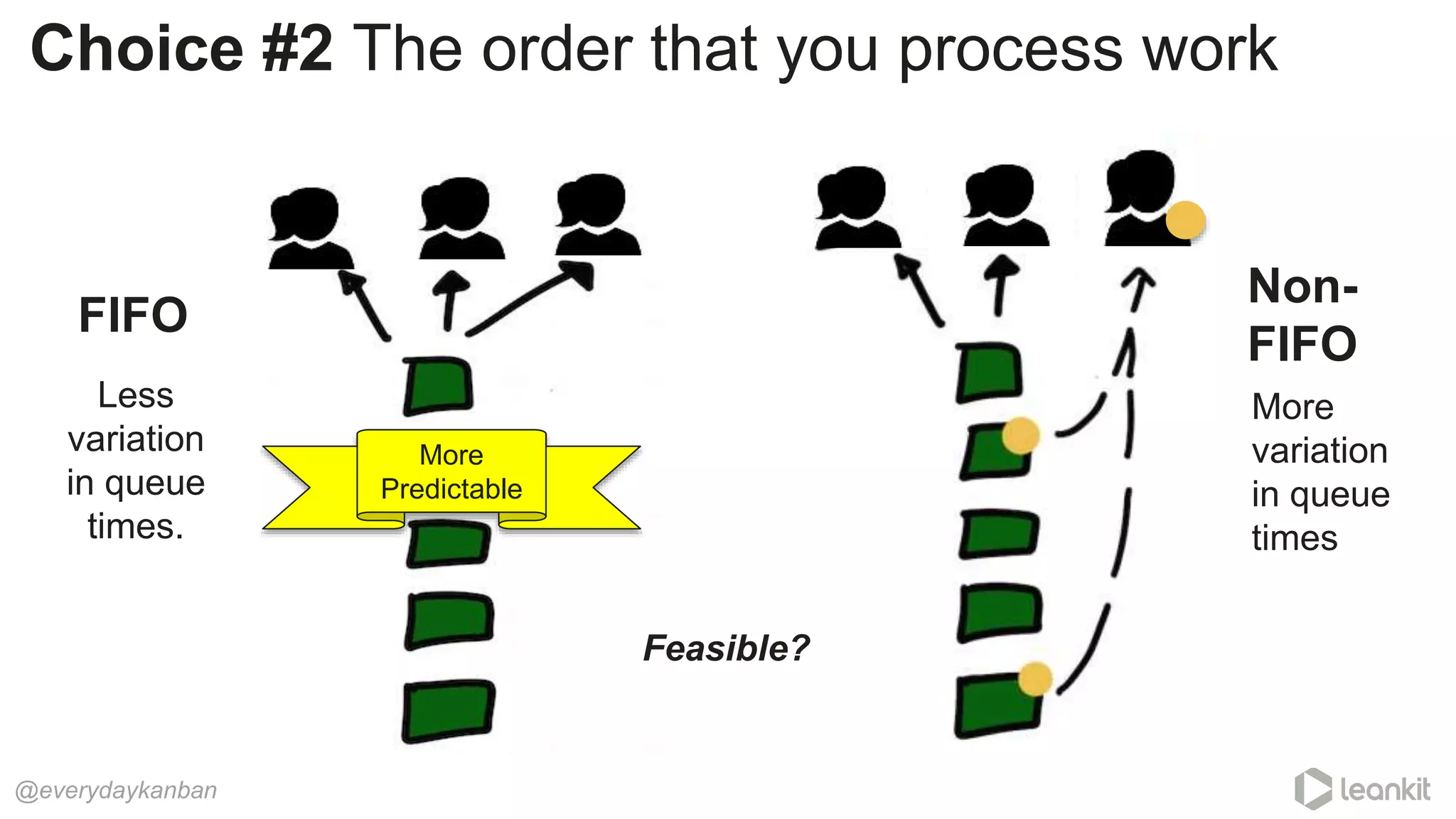
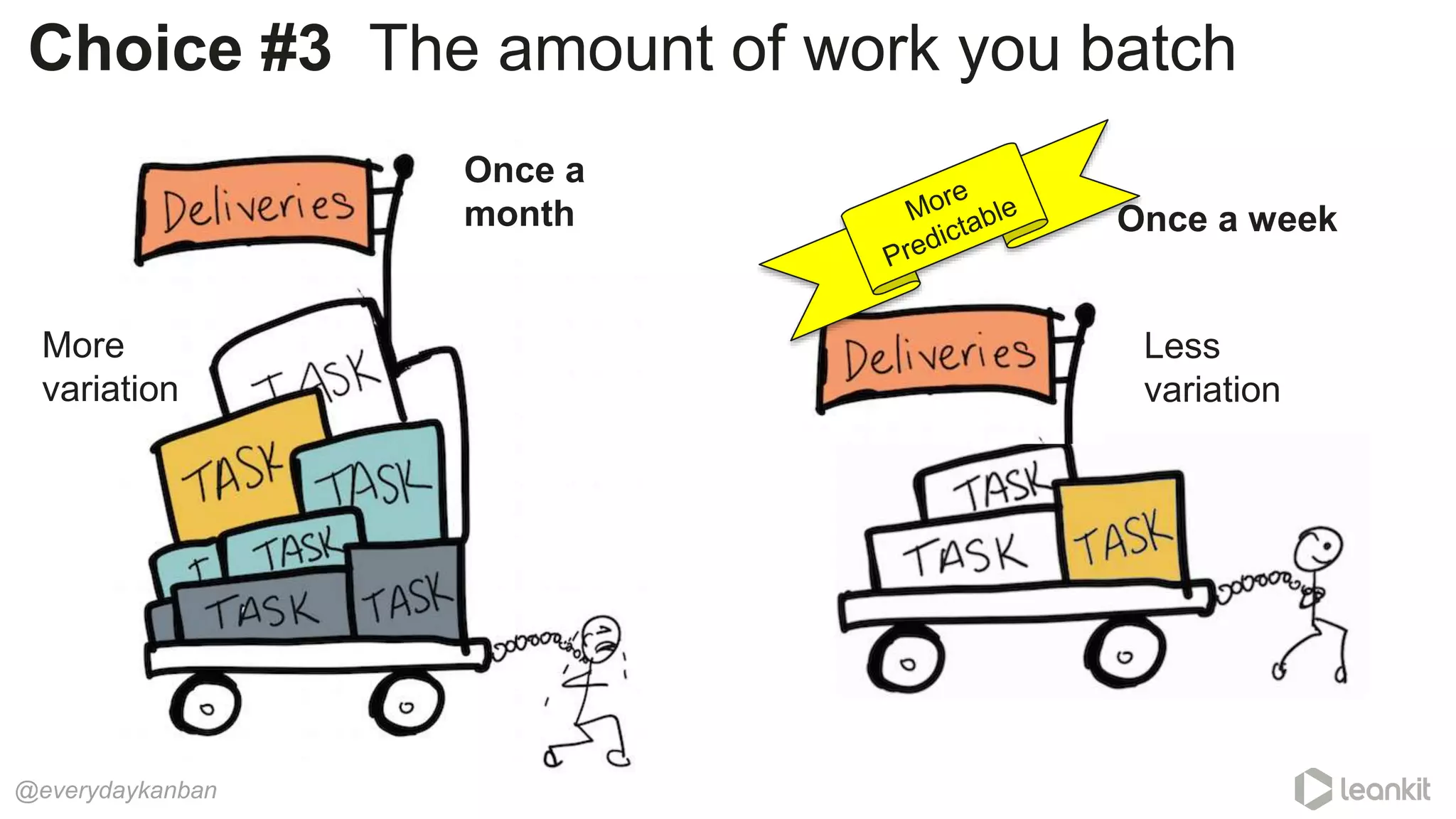


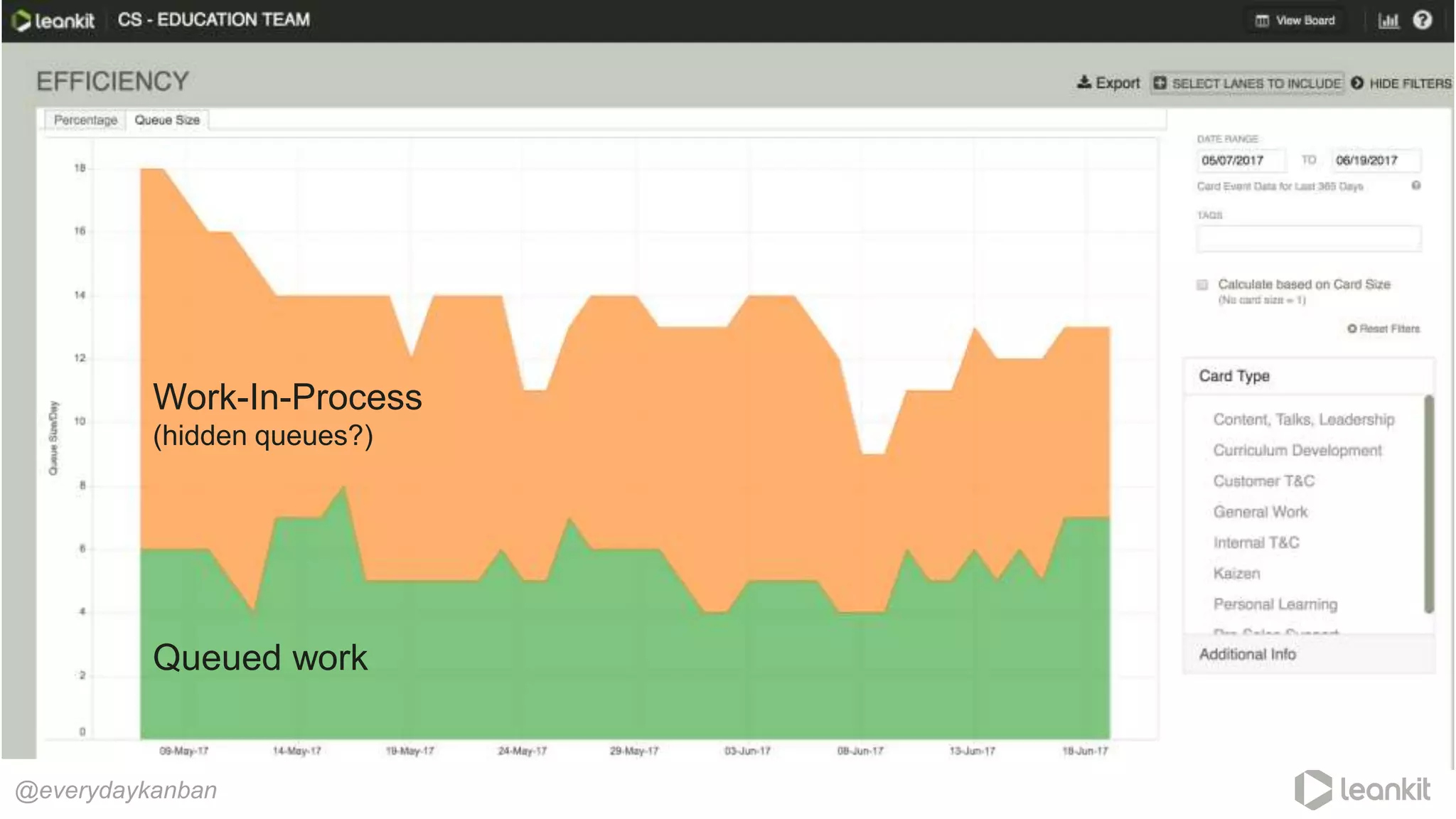
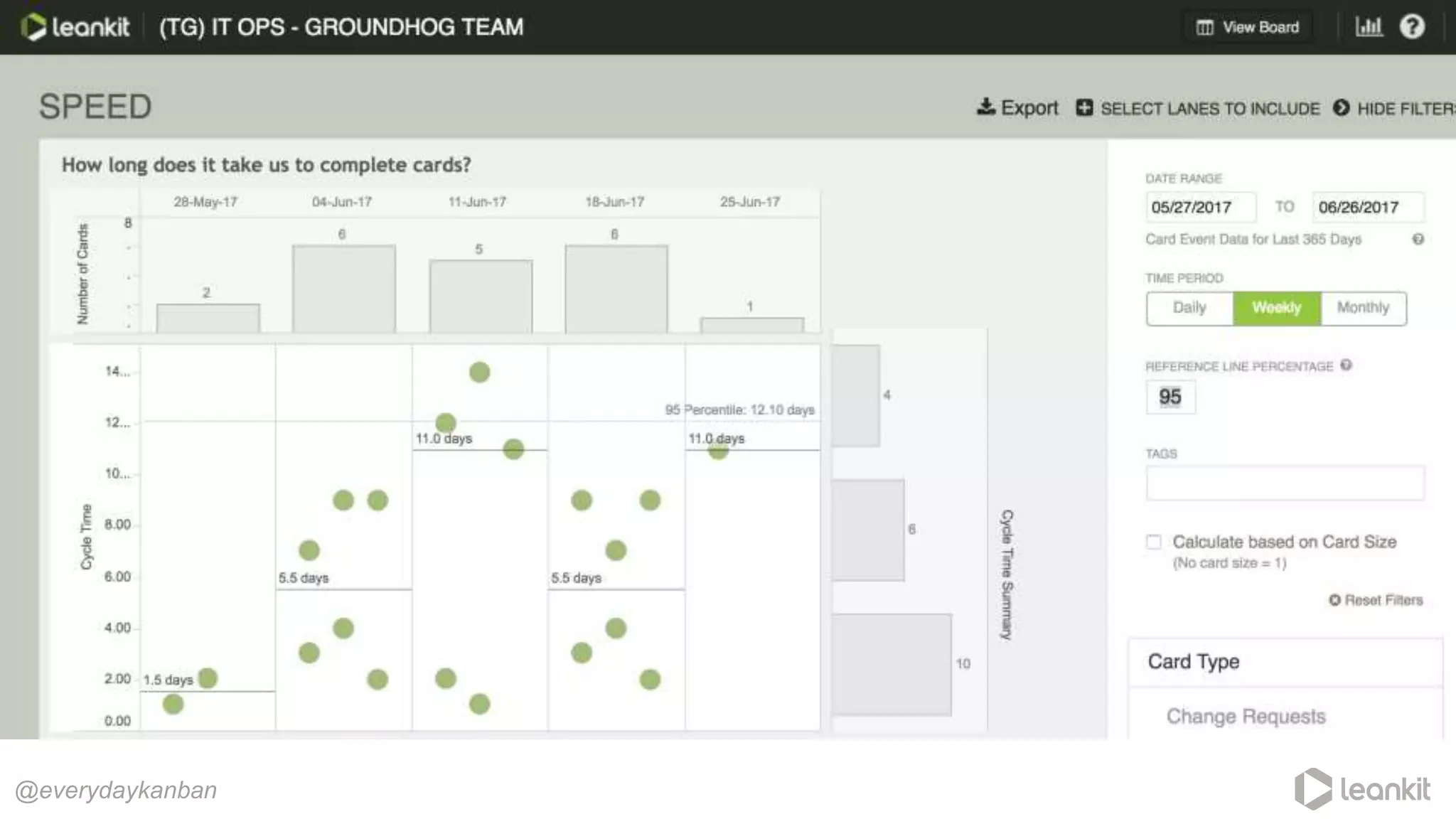
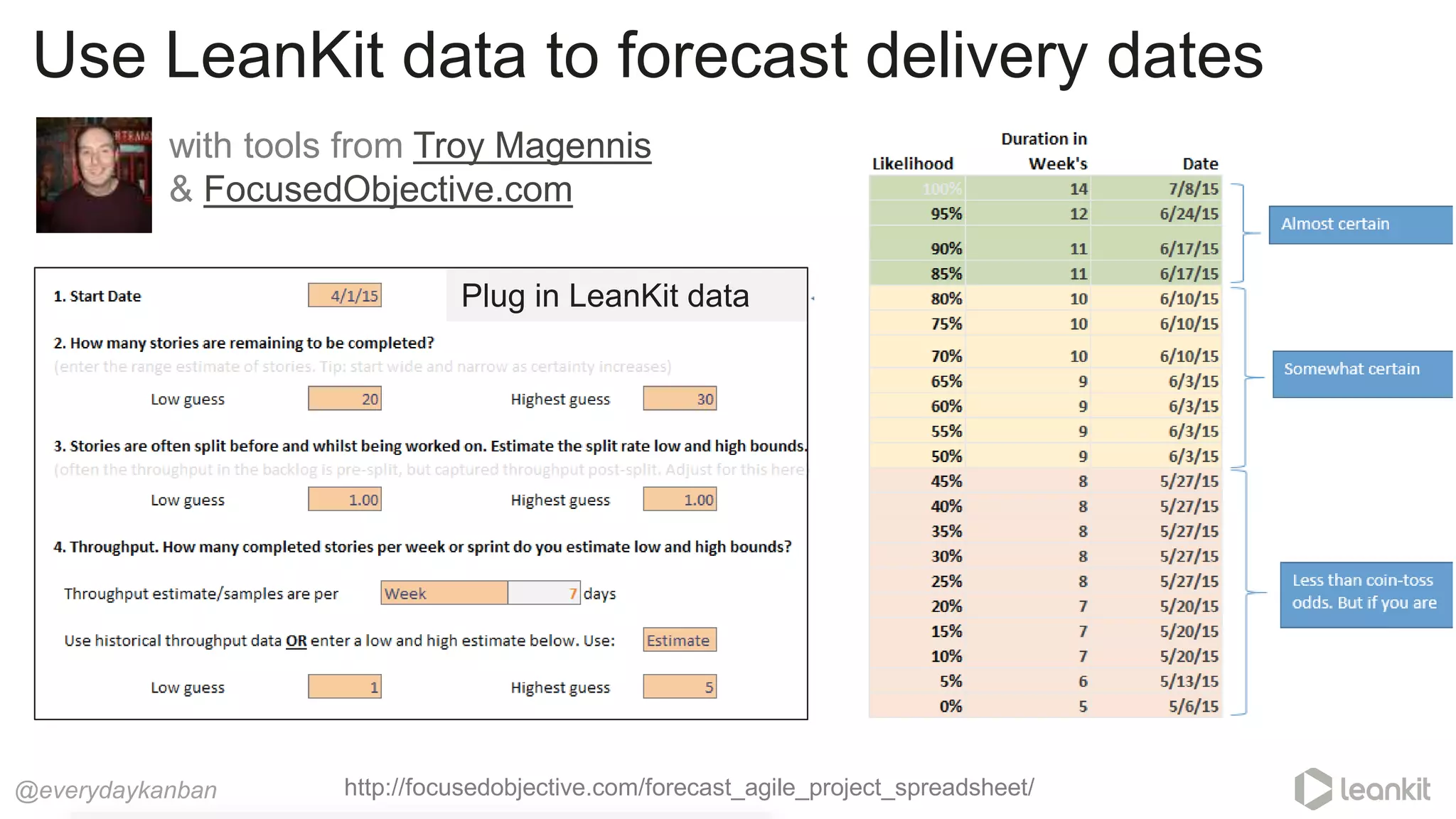


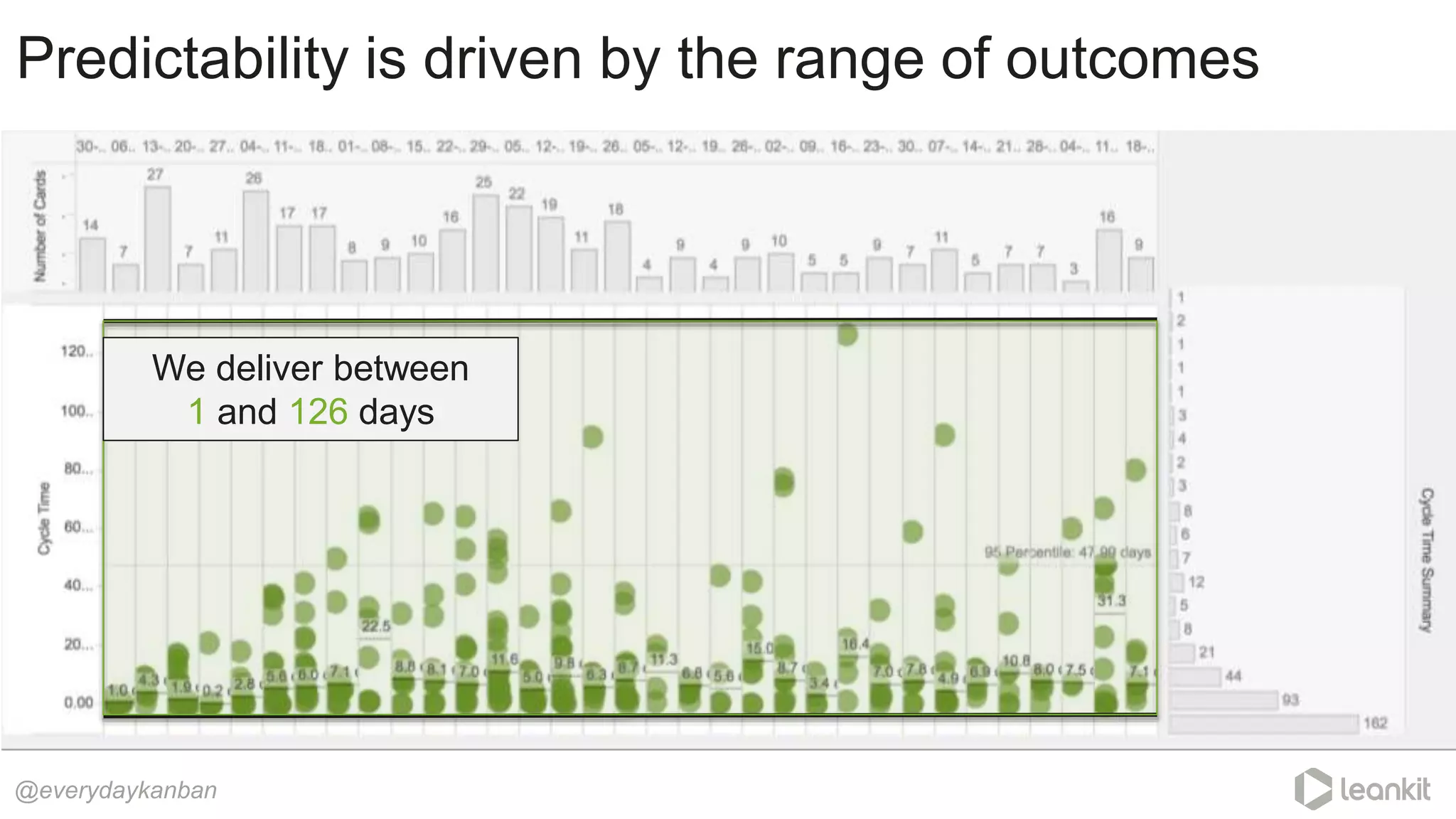
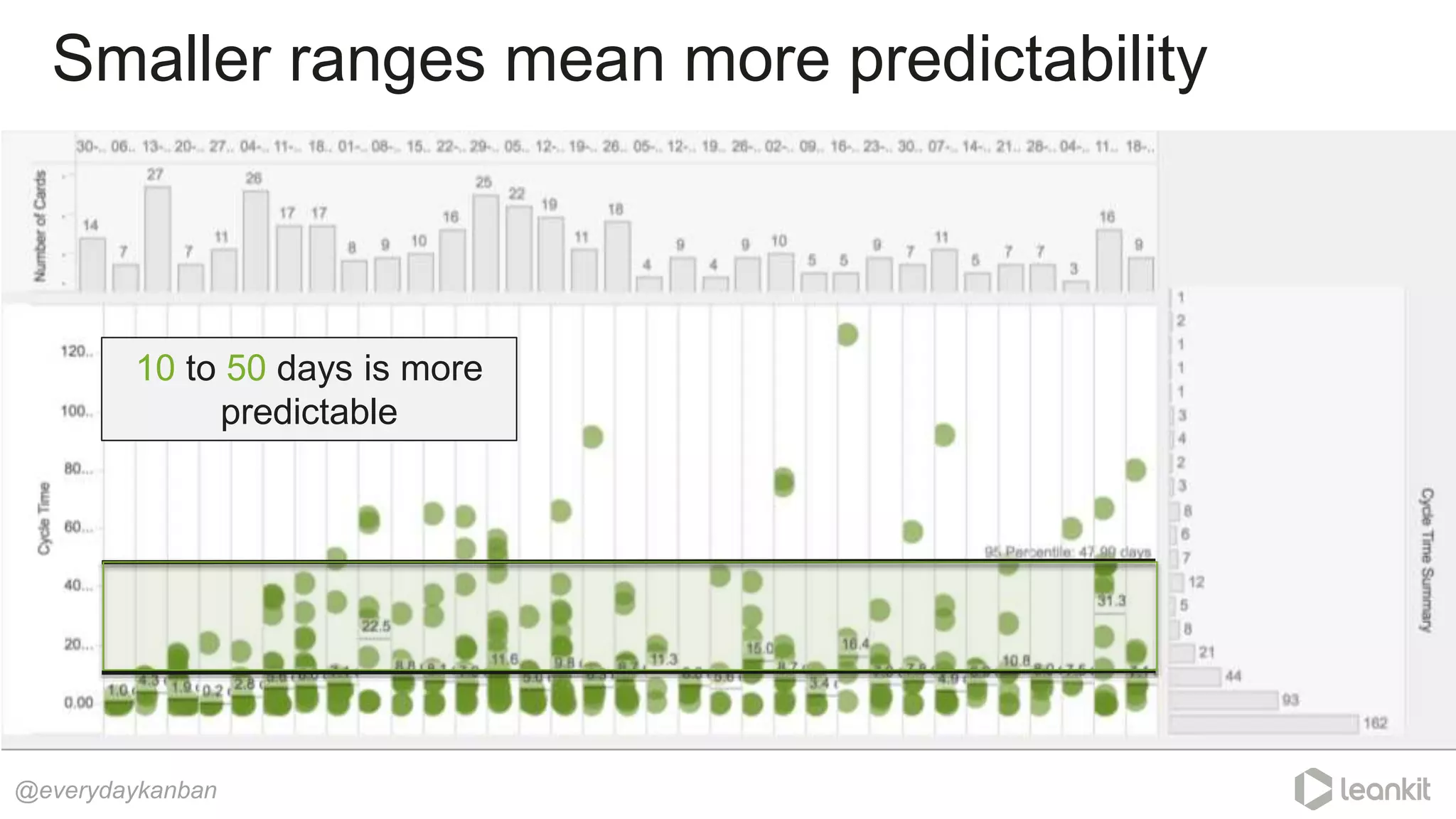
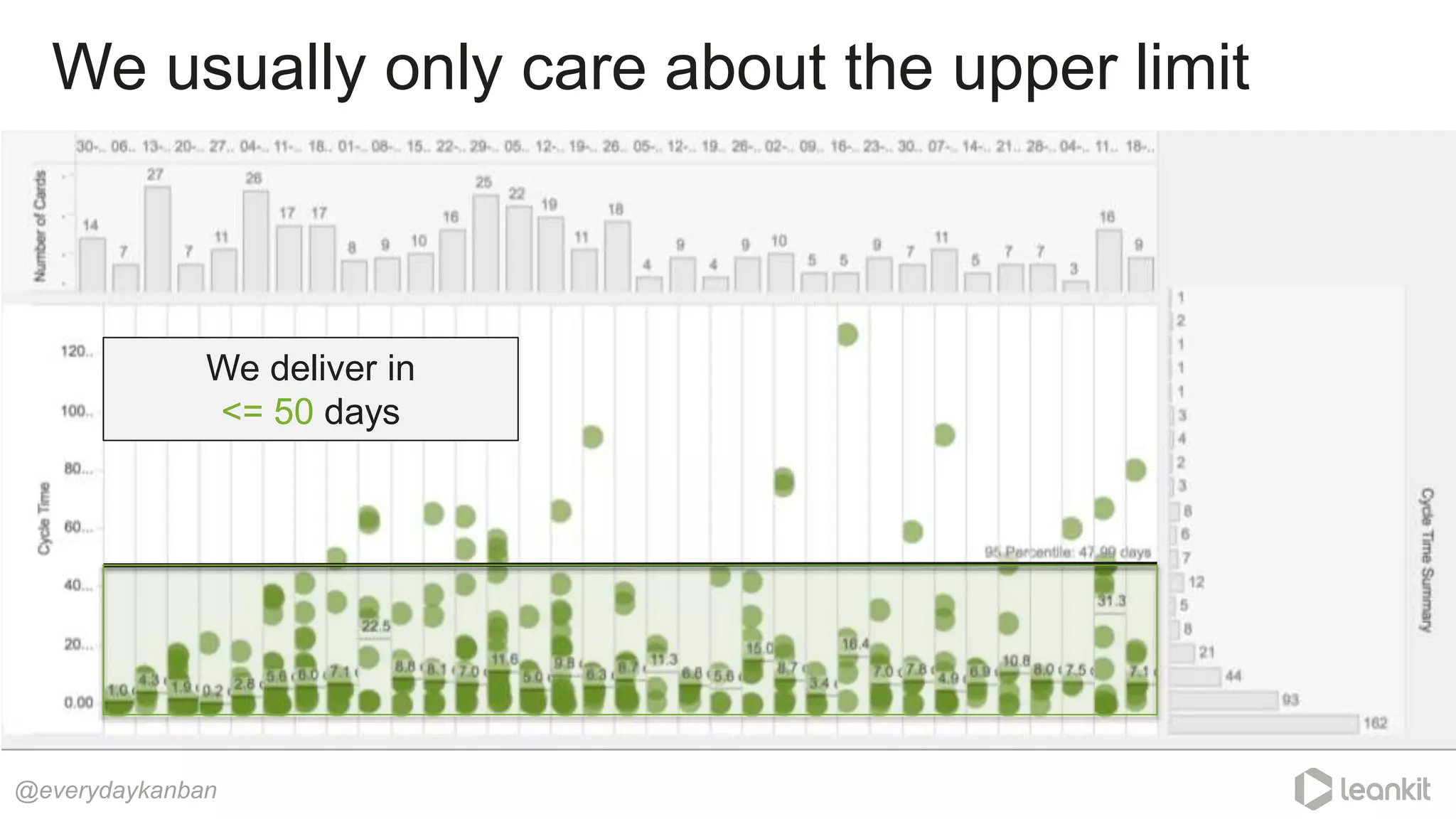
This document discusses predictability in software development and how it relates to managing work queues and flow. It provides several key points: 1. Predictability is driven by the range of outcomes, with smaller ranges meaning more predictability. Queue size and utilization also impact predictability. 2. Common practices aimed at improving reliability can actually decrease predictability by increasing variation in work and queues. 3. Queueing theory can help quantify relationships between queue size, utilization, and cycle times. Managing queues and smoothing flow is important for predictability. 4. Choices around work assignment, processing order, batching, and dependencies all impact variation in queues and predictability. Monitoring work-in-process, queued work



































































