Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Jiro Nishitoba
PPTX, PDF
1,049 views
深層学習による自然言語処理勉強会2章前半
株式会社レトリバで行われた「深層学習による自然言語処理」勉強会で用いた資料です。
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 16
2
/ 16
3
/ 16
4
/ 16
5
/ 16
6
/ 16
7
/ 16
8
/ 16
9
/ 16
10
/ 16
11
/ 16
12
/ 16
13
/ 16
14
/ 16
15
/ 16
16
/ 16
More Related Content
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PPTX
Deep learning chapter4 ,5
by
ShoKumada
PDF
03_深層学習
by
CHIHIROGO
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PPTX
深層学習による自然言語処理勉強会2章前半
by
Kei Shiratsuchi
PPTX
深層学習による自然言語処理勉強会3章前半
by
Jiro Nishitoba
PDF
「深層学習による自然言語処理」読書会 4.2記憶ネットワーク@レトリバ
by
scapegoat06
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
Deep learning chapter4 ,5
by
ShoKumada
03_深層学習
by
CHIHIROGO
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
深層学習による自然言語処理勉強会2章前半
by
Kei Shiratsuchi
深層学習による自然言語処理勉強会3章前半
by
Jiro Nishitoba
「深層学習による自然言語処理」読書会 4.2記憶ネットワーク@レトリバ
by
scapegoat06
Similar to 深層学習による自然言語処理勉強会2章前半
PDF
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
BERTに関して
by
Saitama Uni
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PDF
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
PDF
PRML5
by
Hidekazu Oiwa
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
ニューラルネットワークの数理
by
Task Ohmori
PDF
20150803.山口大学集中講義
by
Hayaru SHOUNO
PPTX
Back propagation
by
T2C_
PPTX
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
PDF
はじぱた7章F5up
by
Tyee Z
PPTX
レトリバ勉強会資料:深層学習による自然言語処理2章
by
Hiroki Iida
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
PDF
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
深層学習の数理
by
Taiji Suzuki
PRML Chapter 5
by
Masahito Ohue
BERTに関して
by
Saitama Uni
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
PRML5
by
Hidekazu Oiwa
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
ニューラルネットワークの数理
by
Task Ohmori
20150803.山口大学集中講義
by
Hayaru SHOUNO
Back propagation
by
T2C_
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
はじぱた7章F5up
by
Tyee Z
レトリバ勉強会資料:深層学習による自然言語処理2章
by
Hiroki Iida
Deep Learningの基礎と応用
by
Seiya Tokui
20160329.dnn講演
by
Hayaru SHOUNO
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
More from Jiro Nishitoba
PPTX
Icml読み会 deep speech2
by
Jiro Nishitoba
PPTX
全体セミナー20170629
by
Jiro Nishitoba
PPTX
全体セミナーWfst
by
Jiro Nishitoba
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
PPTX
全体セミナー20180124 final
by
Jiro Nishitoba
PPTX
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
PPTX
Retrieva seminar jelinek_20180822
by
Jiro Nishitoba
PPTX
20190509 gnn public
by
Jiro Nishitoba
PDF
Chainer meetup20151014
by
Jiro Nishitoba
PPTX
Hessian free
by
Jiro Nishitoba
PPTX
20180609 chainer meetup_es_pnet
by
Jiro Nishitoba
Icml読み会 deep speech2
by
Jiro Nishitoba
全体セミナー20170629
by
Jiro Nishitoba
全体セミナーWfst
by
Jiro Nishitoba
Emnlp読み会資料
by
Jiro Nishitoba
全体セミナー20180124 final
by
Jiro Nishitoba
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
Retrieva seminar jelinek_20180822
by
Jiro Nishitoba
20190509 gnn public
by
Jiro Nishitoba
Chainer meetup20151014
by
Jiro Nishitoba
Hessian free
by
Jiro Nishitoba
20180609 chainer meetup_es_pnet
by
Jiro Nishitoba
Recently uploaded
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
by
Graat(グラーツ)
深層学習による自然言語処理勉強会2章前半
1.
深層学習による自然言語処理第2章 株式会社レトリバ 西鳥羽 二郎
2.
このスライドの範囲 • 2章 ニューラルネットの基礎 •
2.1章 教師あり学習 • 2.1.1章 教師あり学習の定義 • 2.1.2章 損失関数 • 2.1.3章 教師あり学習に用いるデータ • 2.2章 順伝搬型ニューラルネット • 2.2.1章 行列とベクトルのかけ算 • 2.2.2章 モデル • 2.3章 活性化関数 • 2.4章 勾配法 • 2.4.1章 勾配法による関数最小化 • 2.4.2章 ミニバッチによる確率的最適化 • 2.5章 誤差伝搬法 • 2.5.1章 ニューラルネットの微分 • 2.5.2章 深いニューラルネットの難しさ
3.
ニューラルネットの基礎 • この章では一貫してニューラルネットワークのことを 「ニューラルネット」と呼ぶ • 以下の順で説明する •
機械学習とは • 誤差伝搬法とは • 広く使われているニューラルネットの構造(次回)
4.
2.1章 教師あり学習 • 教師あり学習 •
訓練データ: (入力, 入力に対して予測したい対象の正解) • 訓練データを用いて予測モデルを学習する •
5.
2.1.1章 教師あり学習 入 力 ( 訓 練 デ ー タ ) 損 失 関 数 (x(n), y(n)) 予測モデル
損 失 L(Θ)
6.
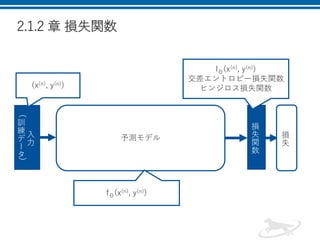
2.1.2 章 損失関数 入 力 ( 訓 練 デ ー タ ) 損 失 関 数 (x(n),
y(n)) 予測モデル 損 失 lΘ(x(n), y(n)) 交差エントロピー損失関数 ヒンジロス損失関数 fΘ(x(n), y(n))
7.
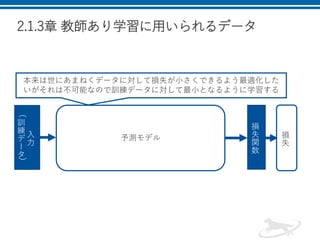
2.1.3章 教師あり学習に用いられるデータ 入 力 ( 訓 練 デ ー タ ) 損 失 関 数 本来は世にあまねくデータに対して損失が小さくできるよう最適化した いがそれは不可能なので訓練データに対して最小となるように学習する 予測モデル 損 失
8.
2.1.3章 教師あり学習に用いられるデータ • 学習データ(train):
学習に用いるデータ • 開発データ(development, validation): 学習には用いない が、学習を調整するためにうまく学習ができているかを確 認するための正解事例 • 評価データ(test): 学習したモデルを最後に評価するための 正解事例
9.
2.2章 順伝搬型ニューラルネット 2.2.2章 モデル •
予測モデルfΘ(x(n), y(n)) として最も簡単な順伝搬型(Feed Forward Neural Network)を説明する • 行列Wをかけてベクトルbを足すという演算を繰り返す 入 力 h(1) h(2) h(3) … h(L) o h(1)=W (1) x+b(1) h(2)=W (2) h(1)+b(2) h(3)=W (3) h(2)+b(3) o=W (L) h(L-1)+b(L)
10.
2.2.2章 モデルの続き • W
(1), W (2),…, W (L), b(1), b(2),…, b(L) はすべてパラメータと なる • 今まで出ていたΘの一例 • 隠れ状態ベクトルの次元数が大きく、層の数が多いほど表 現力が強い
11.
2.3章 活性化関数 • 各隠れ層の状態ベクトルに対して行列演算を行った後、非 線形な関数を適用する •
sigmoid • tanh • ReLU • 層を深くする際には活性化関数が必要 • 例) W (l+1) (W (l) (h (l-1) ))という2層のニューラルネットを構築し た時W=(W (l+1) W (l))の行列をもとにW(h)となるような1層の ニューラルネットを構築できる
12.
2.4章 勾配法 2.4.1章 勾配法による関数最小化 •
学習とは損失関数L(Θ)の最小化である • パラメータΘを勾配法を用いて調整する • 勾配法 • パラメータΘのある値において目的関数を線形直線で近似 • 逐次的にパラメータを更新 • Θ(k+1)=Θ(k)-η∂L(Θ(k)) • η: 学習率(パラメータ)
13.
2.4.2章 ミニバッチ化による確率的勾配法 • 式(2.1)は全訓練データに対する損失だが、データ数が多い と求めるのは難しい •
1訓練データで損失及び勾配を求めてパラメータを更新す る確率的勾配法を用いる • 現実的には全データでも1データでもなく複数のデータで の損失及び勾配を求めて平均を求めるミニバッチ法を用い る
14.
2.5章 誤差伝搬法 2.5.1章 ニューラルネットの微分 •
ニューラルネットにおいて目的関数の偏微分を求めるのに は誤差伝搬法を用いる • 基本的には自分で実装する必要はないだろう • 微分の連鎖律(合成関数の微分)に従うとニューラルネット のパラメータの微分はそれぞれの関数微分の積で表せる
15.
2.5.2章 深いネットワークの難しさ • 入力出力の関係を表した計算グラフにおいて偏微分の値は 損失関数の方から逆側に計算する 入 力 ( 訓 練 デ ー タ ) 行 列 活 性 化 関 数 … 行 列 活 性 化 関 数 行 列 活 性 化 関 数 損 失 関 数 順伝搬の計算 偏微分の計算
16.
2.5.2章 深いネットワークの難しさの続き • 誤差伝搬法ではニューラルネットの各パラメータの微分は 関数微分の積で表される •
∂l(o)/ ∂o * w(o) * w(3) * w(2) * x (式2.33の一部) • 層が増えると積の回数が増える • 偏微分の値が小さい時: 指数的に小さくなる(勾配消失) • 偏微分の値が大きい時: 指数的に大きくなる(勾配爆発) • 深層学習とはいうものの、層が深いと学習は難しい • ResNetのような回避策を用いると1000層以上の学習もできる
Download