Downloaded 29 times





















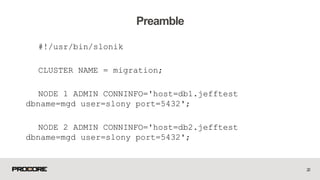






















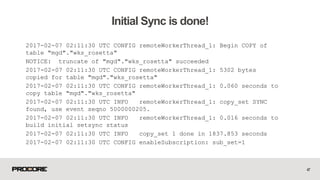







This document provides instructions for minimizing downtime when performing a major version upgrade of PostgreSQL using logical replication with Slony. It discusses various methods for performing the upgrade, including dump/restore, pg_upgrade, and logical replication with Slony. It then provides a step-by-step guide to setting up logical replication between two PostgreSQL nodes using Slony, including initializing the cluster and nodes, creating replication sets, subscribing nodes, and monitoring the initial synchronization process. The document demonstrates how Slony allows performing a graceful switchover and switchback between nodes when upgrading PostgreSQL versions.





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




