Download as PDF, PPTX










![my_callback(void *wS, void *wM, void *wVec, void *wVS, void *wVT, unsigned int
mask_value)
{
Mask mask (mask_value);
ASSERT(mask.any_on());
Wide<const float> wScale (wS);
Wide<const Vec3> wVec (wVec);
Wide<const Matrix44> wMat (wM);
Masked<Vec3> wVT_result (wVT, mask);
Masked<Vec3> wVS_result (wVS, mask);
for(int lane = 0; lane < __OSL_WIDTH; ++lane) {
Vec3 V = wVec[lane];
Float F = wScale[lane];
Matrix M = wMat[lane];
wVS_result[lane] = V*F;
wVT_result[lane] = transform(M,V);
}
}
Accessors
transparent
AOS view of SOA
SIMD OSL’s Wide Library
14](https://image.slidesharecdn.com/fromrenderman220torenderman-190812212430/85/RenderMan-The-Role-of-Open-Shading-Language-OSL-with-Intel-Advanced-Vector-Extensions-SIGGRAPH-2019-Technical-Sessions-14-320.jpg)
![my_callback(void *wS, void *wM, void *wVec, void *wVS, void *wVT, unsigned int
mask_value)
{
Mask mask (mask_value);
ASSERT(mask.any_on());
Wide<const float> wScale (wS);
Wide<const Vec3> wVec (wVec);
Wide<const Matrix44> wMat (wM);
Masked<Vec3> wVT_result (wVT, mask);
Masked<Vec3> wVS_result (wVS, mask);
for(int lane = 0; lane < __OSL_WIDTH; ++lane) {
Vec3 V = wVec[lane];
Float F = wScale[lane];
Matrix M = wMat[lane];
wVS_result[lane] = V*F;
wVT_result[lane] = transform(M,V);
}
}
Accessors
transparent
AOS view of SOA
Extract data
from a lane
of the SOA
SIMD OSL’s Wide Library
15](https://image.slidesharecdn.com/fromrenderman220torenderman-190812212430/85/RenderMan-The-Role-of-Open-Shading-Language-OSL-with-Intel-Advanced-Vector-Extensions-SIGGRAPH-2019-Technical-Sessions-15-320.jpg)
![my_callback(void *wS, void *wM, void *wVec, void *wVS, void *wVT, unsigned int
mask_value)
{
Mask mask (mask_value);
ASSERT(mask.any_on());
Wide<const float> wScale (wS);
Wide<const Vec3> wVec (wVec);
Wide<const Matrix44> wMat (wM);
Masked<Vec3> wVT_result (wVT, mask);
Masked<Vec3> wVS_result (wVS, mask);
for(int lane = 0; lane < __OSL_WIDTH; ++lane) {
Vec3 V = wVec[lane];
Float F = wScale[lane];
Matrix M = wMat[lane];
wVS_result[lane] = V*F;
wVT_result[lane] = transform(M,V);
}
}
Array subscript returns a
proxy object to that lane
Accessors
transparent
AOS view of SOA
Extract data
from a lane
of the SOA
SIMD OSL’s Wide Library
16](https://image.slidesharecdn.com/fromrenderman220torenderman-190812212430/85/RenderMan-The-Role-of-Open-Shading-Language-OSL-with-Intel-Advanced-Vector-Extensions-SIGGRAPH-2019-Technical-Sessions-16-320.jpg)
![my_callback(void *wS, void *wM, void *wVec, void *wVS, void *wVT, unsigned int
mask_value)
{
Mask mask (mask_value);
ASSERT(mask.any_on());
Wide<const float> wScale (wS);
Wide<const Vec3> wVec (wVec);
Wide<const Matrix44> wMat (wM);
Masked<Vec3> wVT_result (wVT, mask);
Masked<Vec3> wVS_result (wVS, mask);
for(int lane = 0; lane < __OSL_WIDTH; ++lane) {
Vec3 V = wVec[lane];
Float F = wScale[lane];
Matrix M = wMat[lane];
wVS_result[lane] = V*F;
wVT_result[lane] = transform(M,V);
}
}
Array subscript returns a
proxy object to that lane
Accessors
transparent
AOS view of SOA
Extract data
from a lane
of the SOA
Skips assignment if lane masked off
SIMD OSL’s Wide Library
17](https://image.slidesharecdn.com/fromrenderman220torenderman-190812212430/85/RenderMan-The-Role-of-Open-Shading-Language-OSL-with-Intel-Advanced-Vector-Extensions-SIGGRAPH-2019-Technical-Sessions-17-320.jpg)



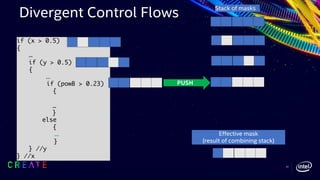
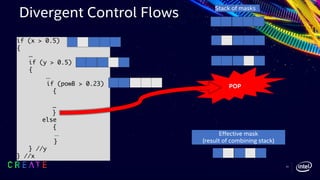
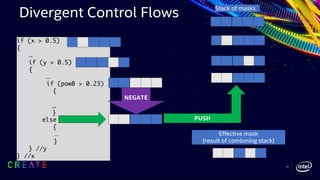
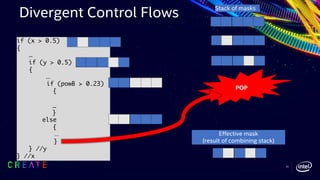
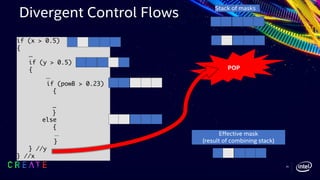
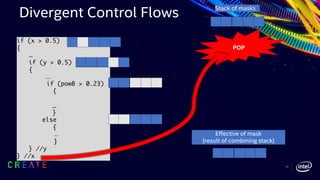










![42
Scalar computation
with
Scalar data types
Block Vectorization
with intrinsics
template<int WidthT> void operator() (MaskedAccessor<float, WidthT> wresult,
ConstWideAccessor<Vec3, WidthT> wp) const {
#pragma forceinline recursive
{
#pragma omp simd simdlen(WidthT)
for(int l=0; l< WidthT; ++l) {
Vec3 p = wp[l];
float perlinResult;
HashScalar h;
perlin_scalar(perlinResult, h, p.x, p.y, p.z);
float scaledResult = 0.5f * (perlinResult + 1.0f);
wresult[l] = scaledResult;
}
}
}
inline void operator() (float &result, const Vec3 &p) const
{
HashScalar h;
perlin(result, h, p.x, p.y, p.z);
result = 0.5f * (result + 1.0f);
}
Explicit
Outer Loop
Vectorization
(Intel® C++ Compiler)
(Clang 5+)
SIMD OSL’s Perlin Noise](https://image.slidesharecdn.com/fromrenderman220torenderman-190812212430/85/RenderMan-The-Role-of-Open-Shading-Language-OSL-with-Intel-Advanced-Vector-Extensions-SIGGRAPH-2019-Technical-Sessions-42-320.jpg)




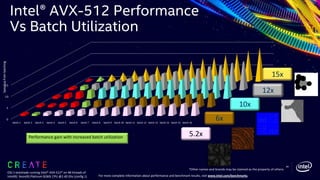
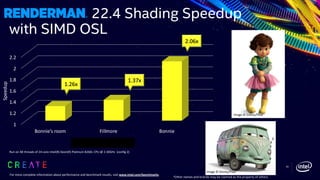
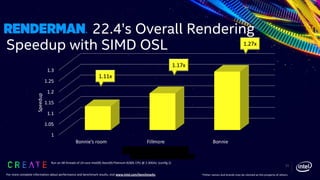






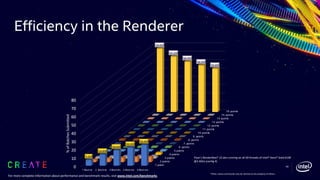





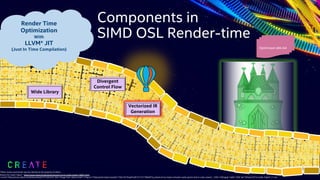
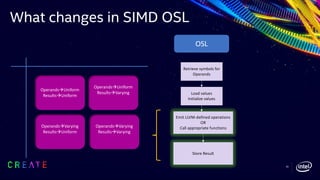
This document discusses advancements in the Open Shading Language (OSL) and its integration with Intel's Advanced Vector Extensions (AVX-512) for enhanced performance in rendering. It highlights the limitations of traditional C++ shaders and showcases OSL as an open-source, C-like domain-specific language for programmable shading in visual effects. Additionally, it delves into render-time optimizations using LLVM and strategies for managing complex shading networks.



































































