P o st g r e S Q L F o r A u r o r a
Aurora is now fully compatible with
both PostgreSQL and MySQL
8.
1/10th The CostOf
Commercial Grade
Databases
Fully PostgreSQL
Compatible
Several times better
performance than typical
PostgreSQL database
Scalable,
Durable and Secure
Migrate From
RDS For PostgreSQL
Amazon Aurora PostgreSQL-Compatible Edition
9.
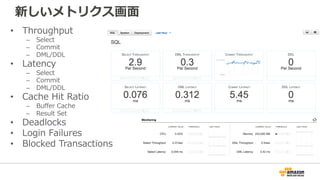
新しいメトリクス画⾯
• Throughput
– Select
–Commit
– DML/DDL
• Latency
– Select
– Commit
– DML/DDL
• Cache Hit Ratio
– Buffer Cache
– Result Set
• Deadlocks
• Login Failures
• Blocked Transactions
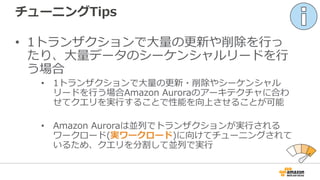
チューニングTips
#1> SELECT *FROM Table;
#1> SELECT * FROM Table WHERE id BETWEEN 1 AND 10000;
#2> SELECT * FROM Table WHERE id BETWEEN 10001 AND 20000;
#3> SELECT * FROM Table WHERE id BETWEEN 20001 AND 30000;
#4> .........
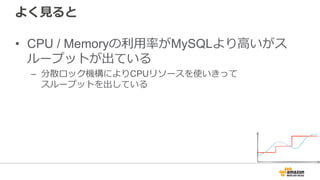
• SELECT (Parallel Read Aheadで大幅性能改善)
• DELETE / UPDATE
#1> DELETE * FROM Table WHERE id
>= 100000;
#1> DELETE FROM Table WHERE id BETWEEN 10000 AND 20000;
#2> DELETE FROM Table WHERE id BETWEEN 20001 AND 30000;
#3> DELETE FROM Table WHERE id BETWEEN 300001AND 40000;
#4> .........
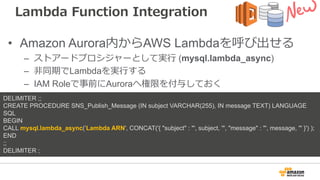
Lambda Function Integration
•Amazon Aurora内からAWS Lambdaを呼び出せる
– ストアードプロシジャーとして実⾏ (mysql.lambda_async)
– ⾮同期でLambdaを実⾏する
– IAM Roleで事前にAuroraへ権限を付与しておく
DELIMITER ;;
CREATE PROCEDURE SNS_Publish_Message (IN subject VARCHAR(255), IN message TEXT) LANGUAGE
SQL
BEGIN
CALL mysql.lambda_async(’Lambda ARN', CONCAT('{ "subject" : "', subject, '", "message" : "', message, '" }') );
END
;;
DELIMITER ;
54.
Load Data FromS3
• S3バケットに保存されたデータを直接Auroraにインポー
ト可能
– テキスト形式(LOAD DATA FROM S3)・XML形式(LOAD XML FROM S3)
– LOAD DATA INFILEとほぼ同様のオプションをサポート (圧縮形式のデータ
は現在未サポート)
<row column1="value1" column2="value2" />
<row column1="value1" column2="value2" />
<row>
<column1>value1</column1>
<column2>value2</column2>
</row>
<row>
<field name="column1">value1</field>
<field name="column2">value2</field>
</row>
55.
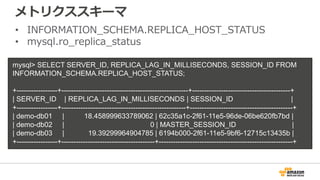
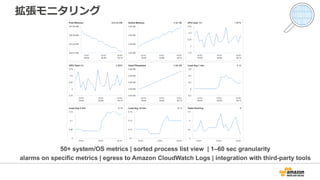
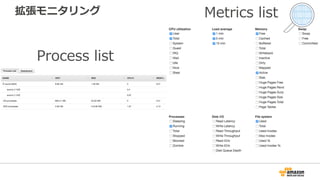
拡張モニタリング
50+ system/OS metrics| sorted process list view | 1–60 sec granularity
alarms on specific metrics | egress to Amazon CloudWatch Logs | integration with third-party tools
































![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://image.slidesharecdn.com/amazonauroratips-170307140000/85/Aurora-Amazon-Aurora-64-320.jpg)






































![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)








![[MANABIYA] 20180323 Amazon Aurora with PostgreSQL Compatibility](https://cdn.slidesharecdn.com/ss_thumbnails/20180323manabiyaaurorapostgresql-180323071750-thumbnail.jpg?width=640&height=640&fit=bounds)







![[PGConf.ASIA 2018]Deep Dive on Amazon Aurora with PostgreSQL Compatibility](https://cdn.slidesharecdn.com/ss_thumbnails/20181212pgconfasiaaurorapostgresql-181212055637-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)







