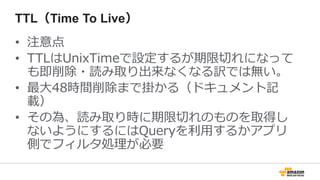
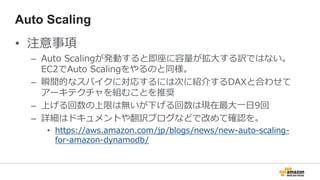
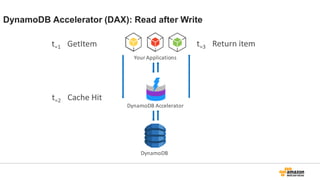
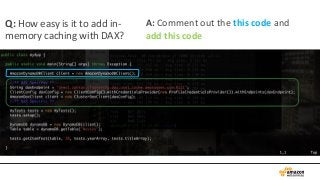
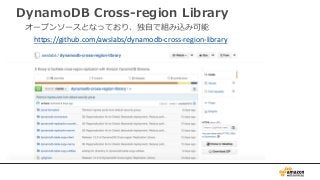
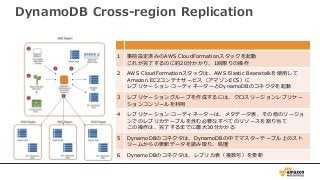
注意事項
• 現在Java SDKonly。他言語対応は今後。
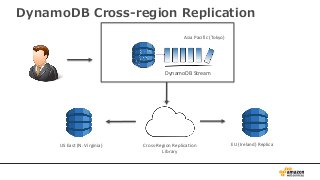
• US East (Northern Virginia)、EU (Ireland)、
US West (Oregon)、Asia Pacific (Tokyo)、US
West (Northern California) の5つの地域で利
用可能
• Instances: r3のみ
00 55 A954AA FF
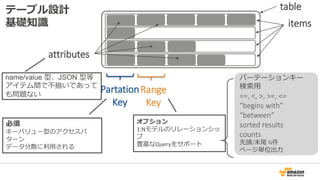
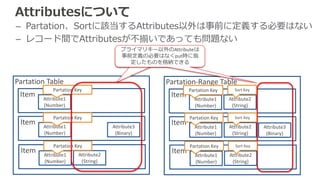
Partation Table
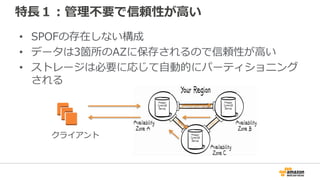
• Partation Key は単体でプライマリキーとして利用
• 順序を指定しないハッシュインデックスを構築するためのキー
• テーブルは、性能を確保するために分割(パーティショニング)される場合あり
00 FF
Id = 1
Name = Jim
Partation (1) = 7B
Id = 2
Name = Andy
Dept = Engg
Partation (2) = 48
Id = 3
Name = Kim
Dept = Ops
Partation (3) = CD
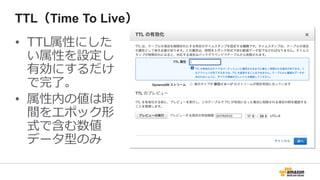
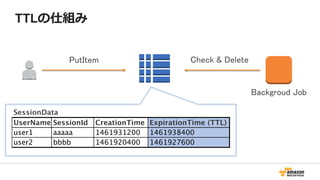
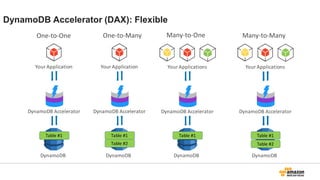
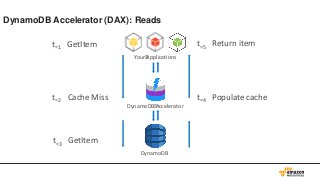
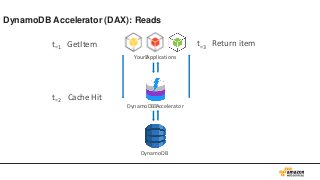
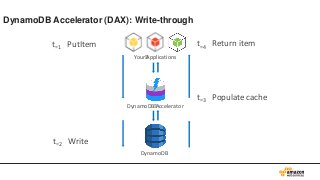
Key Space
53.
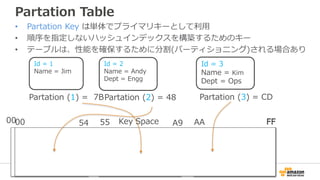
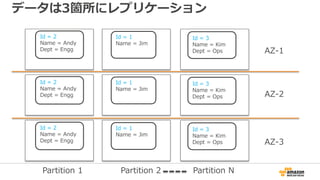
データは3箇所にレプリケーション
Id = 2
Name= Andy
Dept = Engg
Id = 3
Name = Kim
Dept = Ops
Id = 1
Name = Jim
Id = 2
Name = Andy
Dept = Engg
Id = 3
Name = Kim
Dept = Ops
Id = 1
Name = Jim
Id = 2
Name = Andy
Dept = Engg
Id = 3
Name = Kim
Dept = Ops
Id = 1
Name = Jim
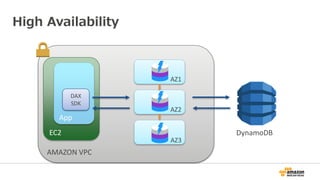
AZ-1
AZ-2
AZ-3
Partition 1 Partition 2 Partition N






















![Attributesの型
– String
– Number
– Binary
– Boolean
– Null
– 多値データ型
• Set of String
• Set of Number
• Set of Binary
– ドキュメントデータ型
• List型は、順序付きの値のコレクションを含む
• Map型は、順序なしの名前と値のペアのコレク
ションを含む
{
Day: "Monday",
UnreadEmails: 42,
ItemsOnMyDesk: [
"Coffee Cup",
"Telephone",
{
Pens: { Quantity : 3},
Pencils: { Quantity : 2},
Erasers: { Quantity : 1}
}
]
}
※ Partation Key ,Sort Keyの型は、文字列、数値、また
はバイナリでなければならない](https://image.slidesharecdn.com/20170809blackbelt-dynamodb-170809095923/85/AWS-Black-Belt-Online-Seminar-2017-Amazon-DynamoDB-50-320.jpg)




















































































![[よくわかるクラウドデータベース] リクルートにおけるRedshift導入・活用事例](https://cdn.slidesharecdn.com/ss_thumbnails/20140117aws-140128175458-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[AWSマイスターシリーズ] Amazon DynamoDB](https://cdn.slidesharecdn.com/ss_thumbnails/20131002aws-meister-regenerate-dynamodb-public-131004025730-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] A33:Amazon DynamoDB Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a33amazon-dynamodbamazondataservicejapan-150623010315-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[よくわかるクラウドデータベース] CassandraからAmazon DynamoDBへの移行事例](https://cdn.slidesharecdn.com/ss_thumbnails/cassandraamazondynamodb-140216194358-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)


