Downloaded 608 times


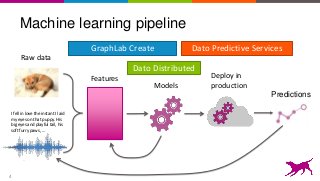







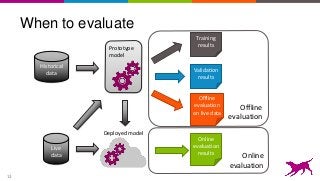






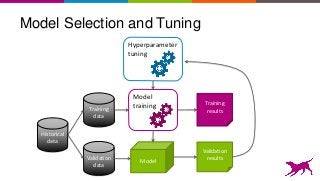

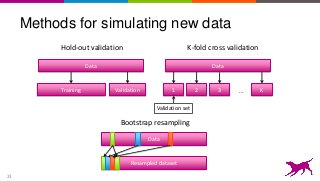
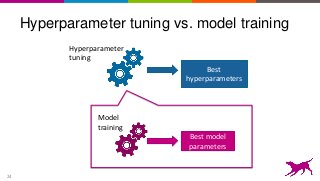
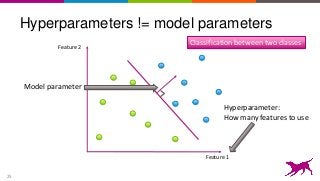


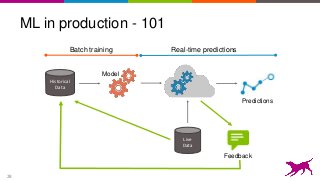
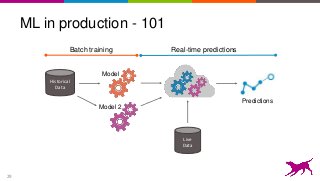

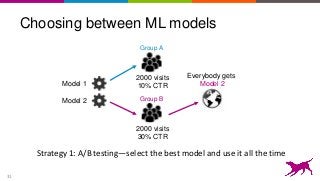
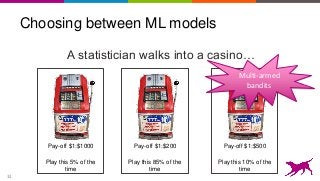
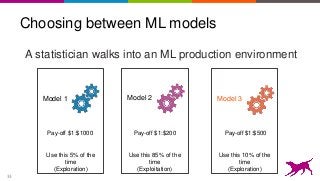



This is an overview on evaluating machine learning models: when, how, metrics, datasets, methods. Topics include metrics, validation, hyperparameter tuning, A/B testing, and multi-armed bandits. It's a summary of my short report on the topic: http://oreil.ly/1LkP2tn.








































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)




