Download as PDF, PPTX




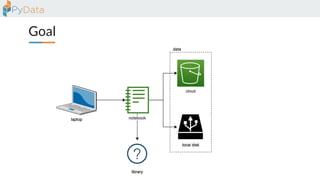
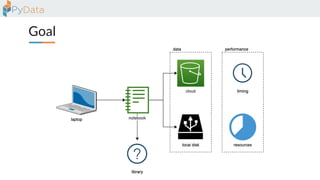





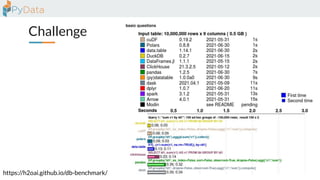
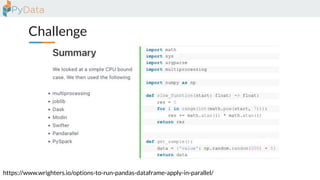

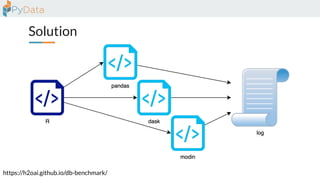
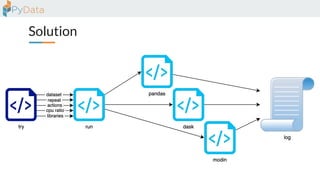



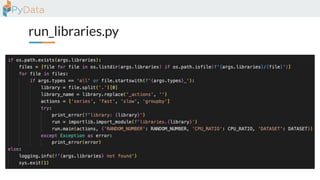
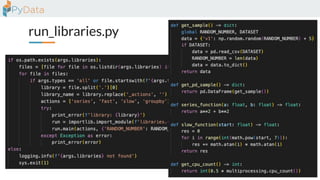
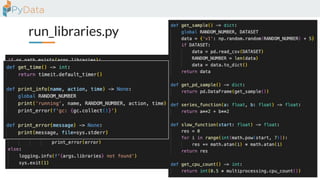
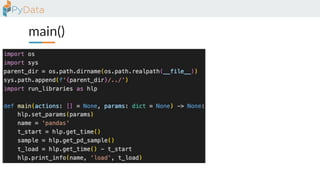
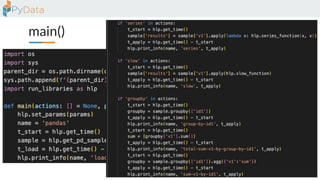
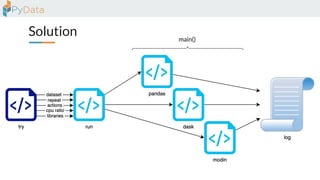

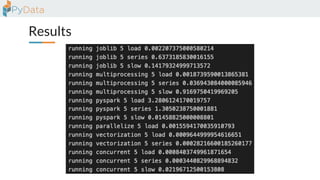
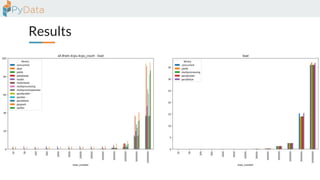
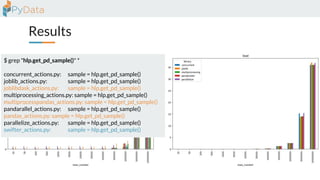
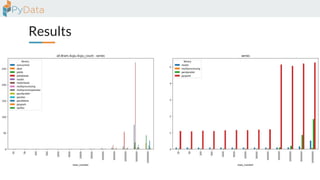
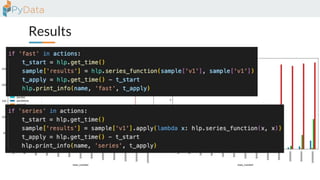
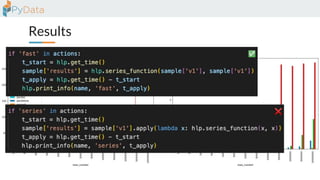
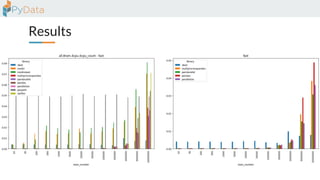
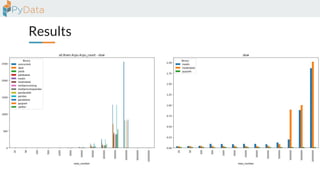
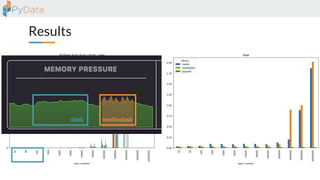
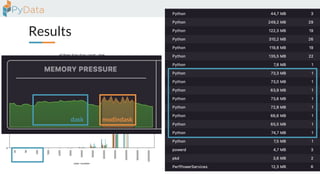
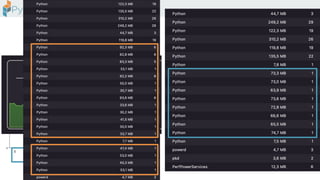
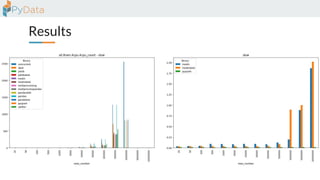
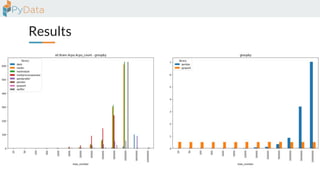
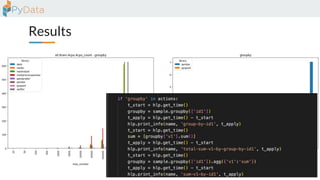
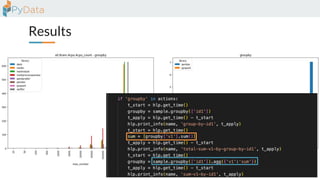
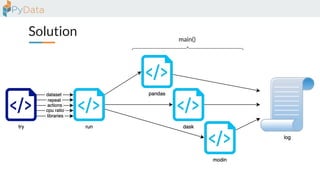
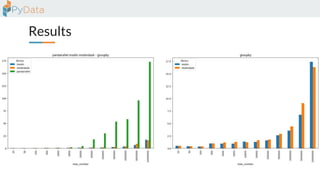
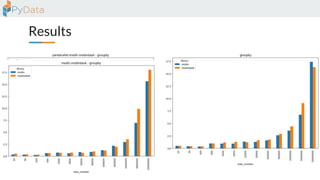
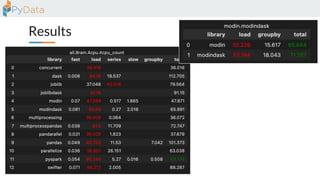
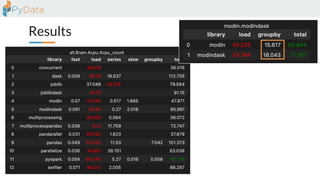
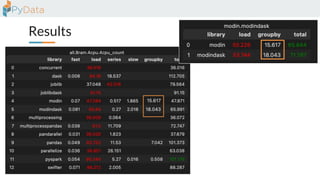
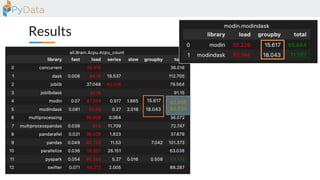





The document discusses the parallelization of data processing with a focus on performance challenges and results using various libraries like pandas, Dask, and Modin on different datasets. It compares execution times, highlights best practices for optimizing performance, and emphasizes the importance of vectorization and multiprocessing. Resources such as links to benchmarking tools and related works are provided to support the findings.



































































