Downloaded 47 times





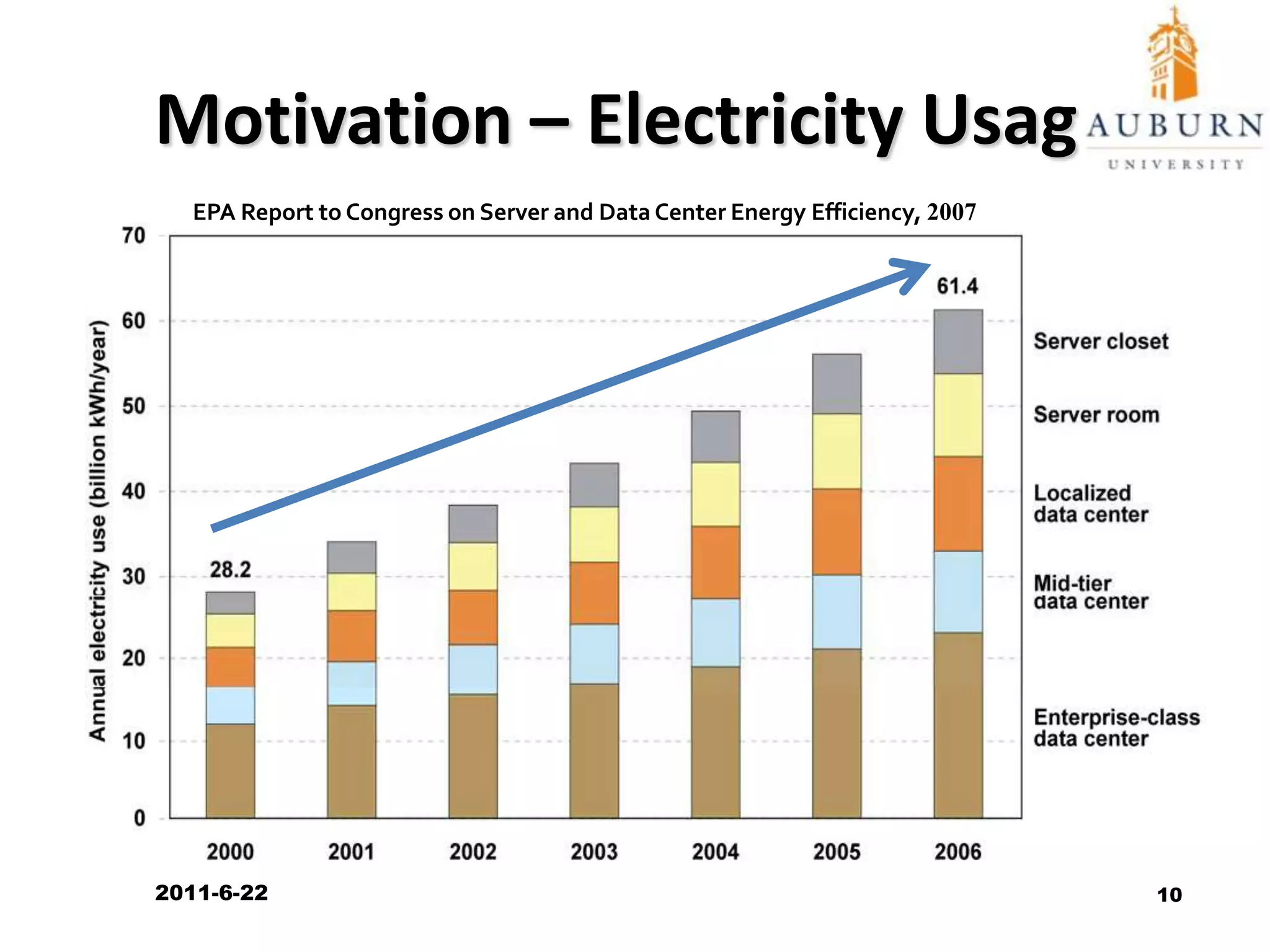
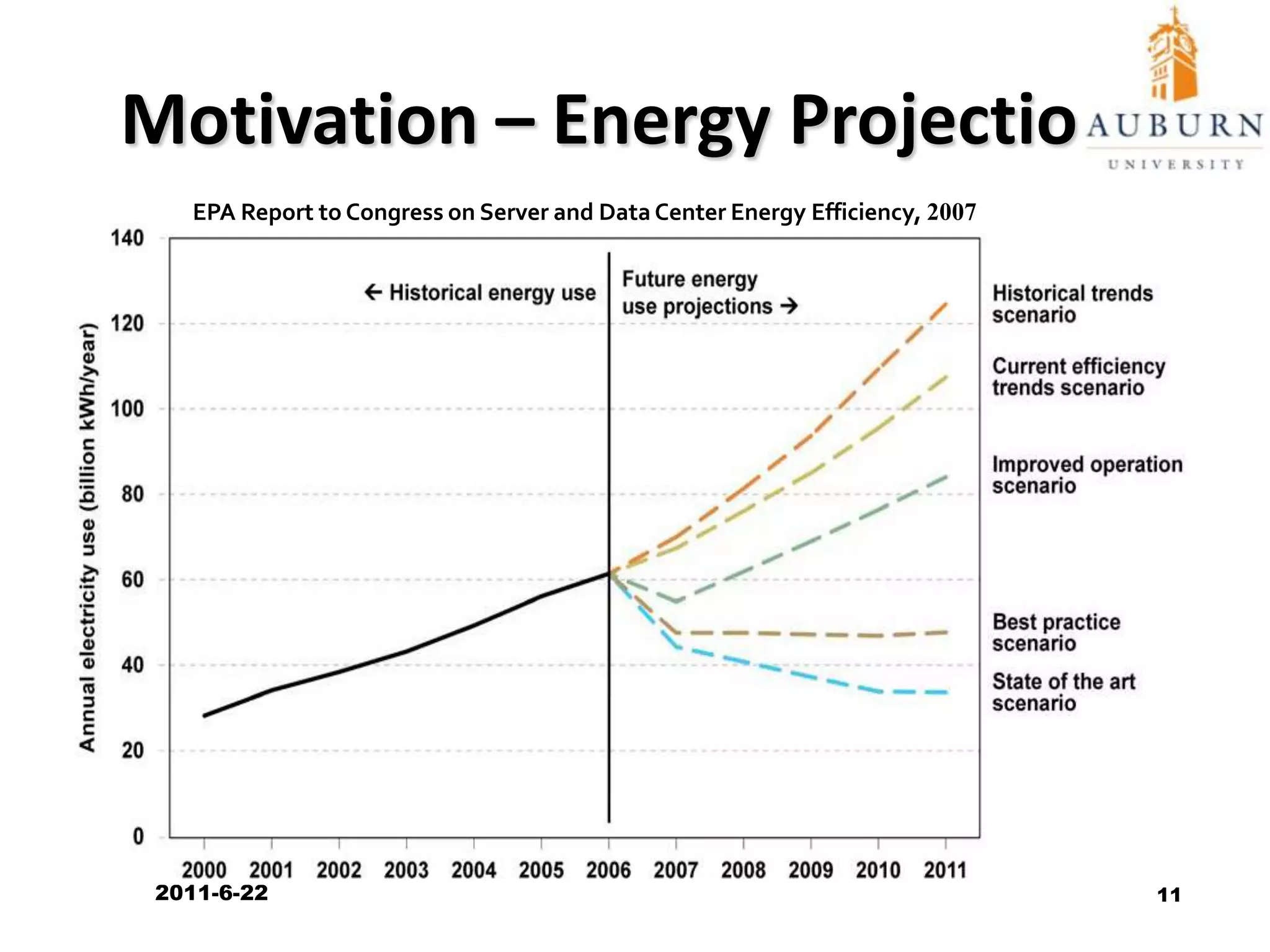
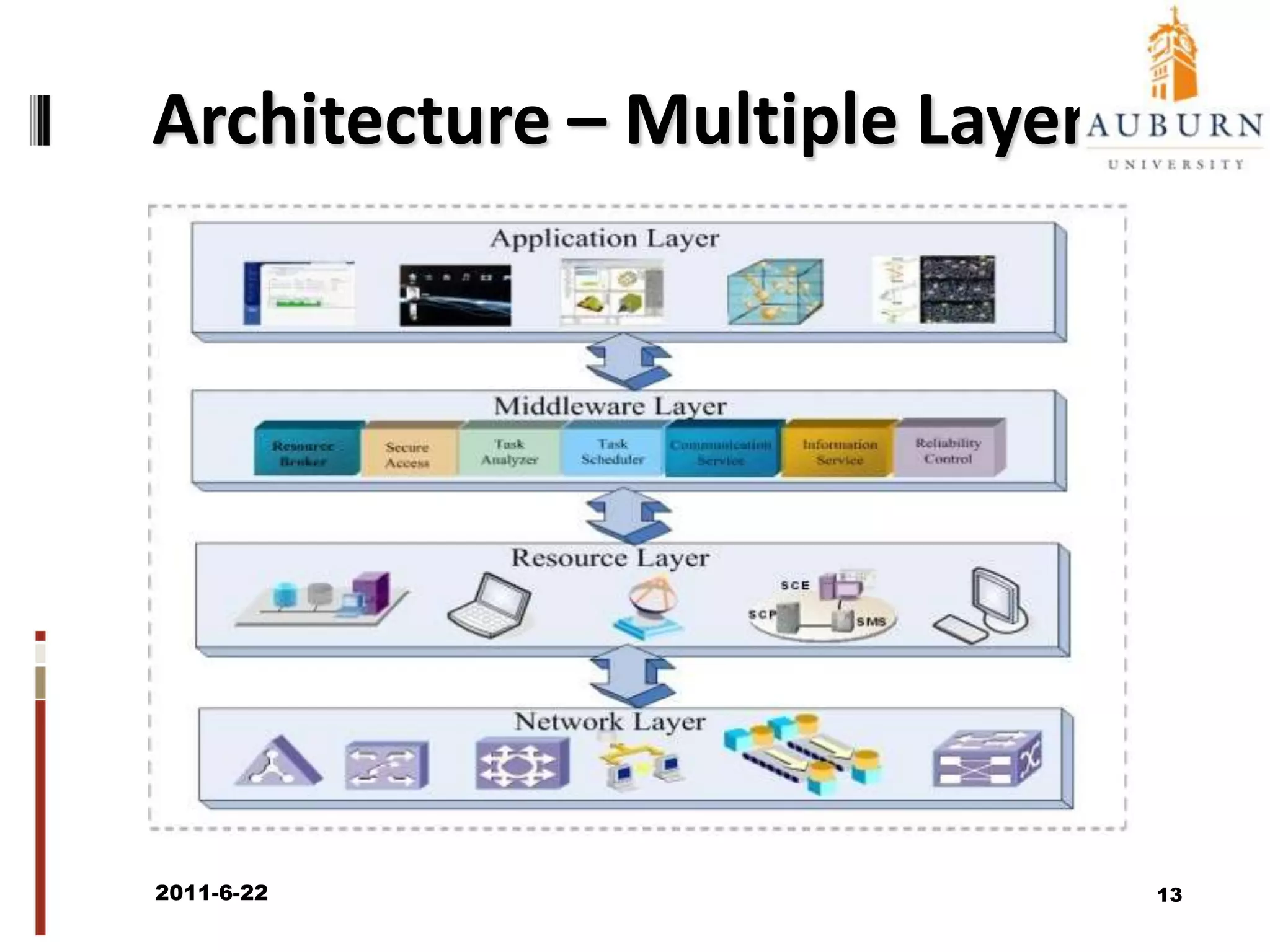

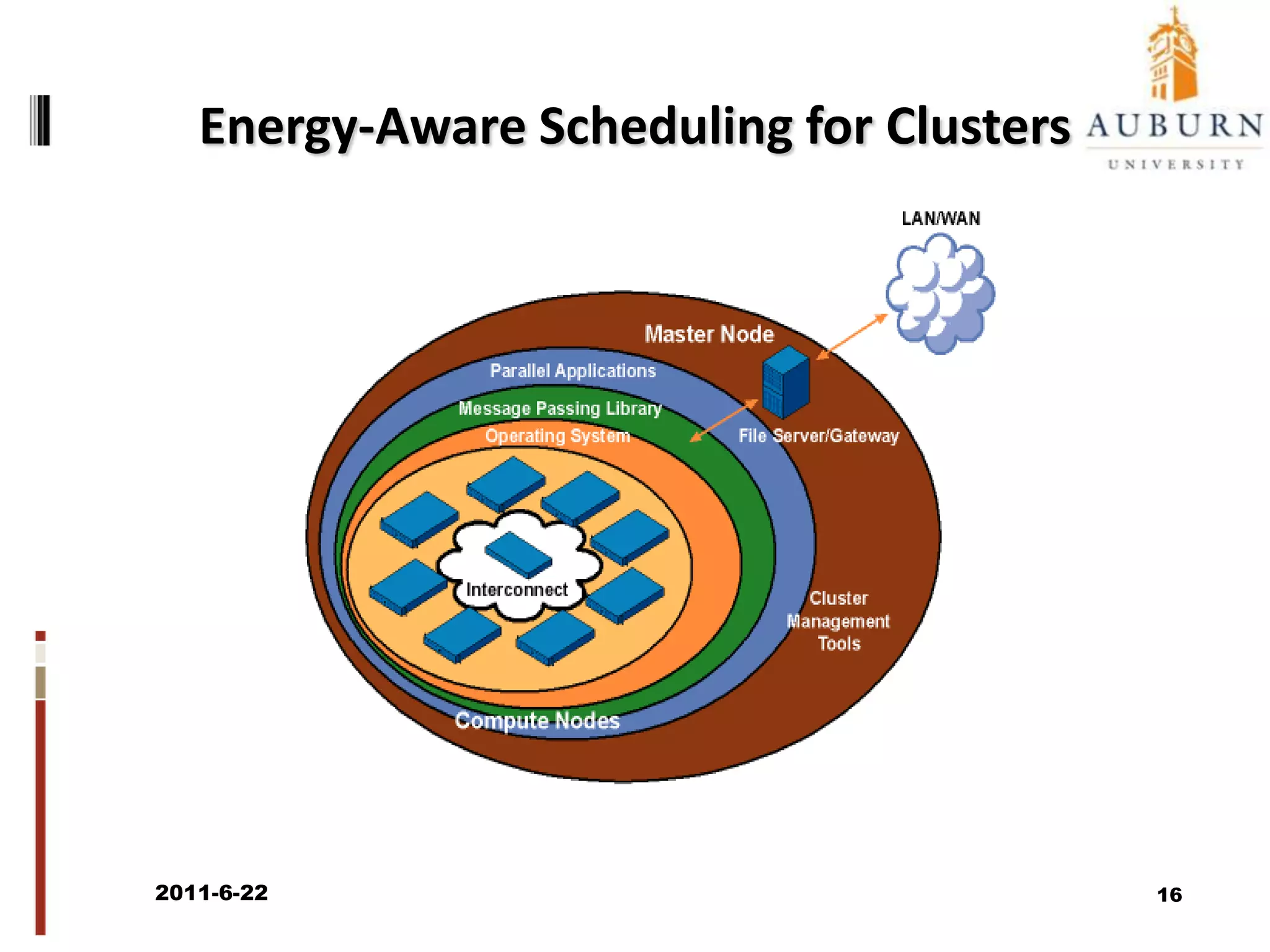
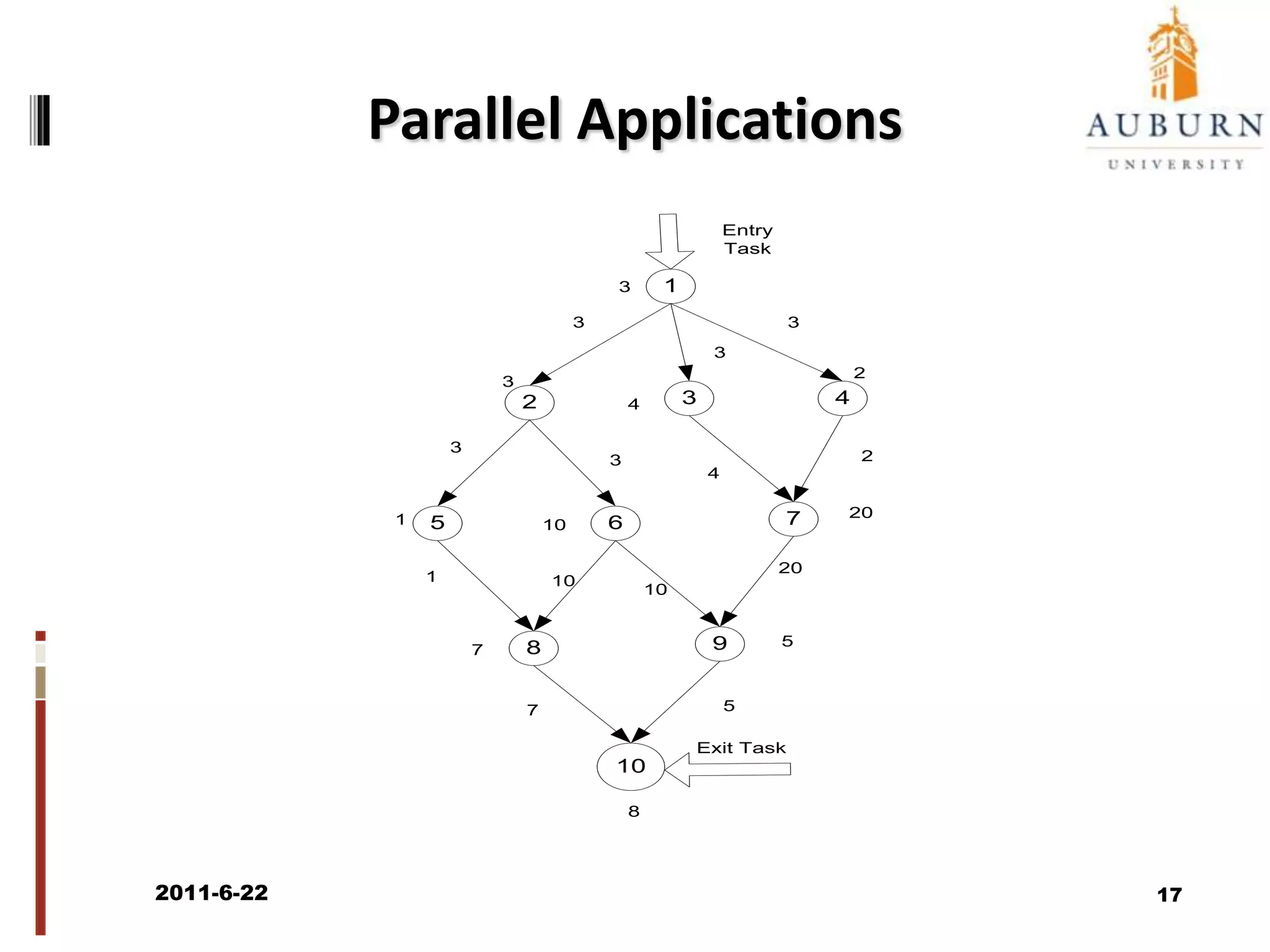
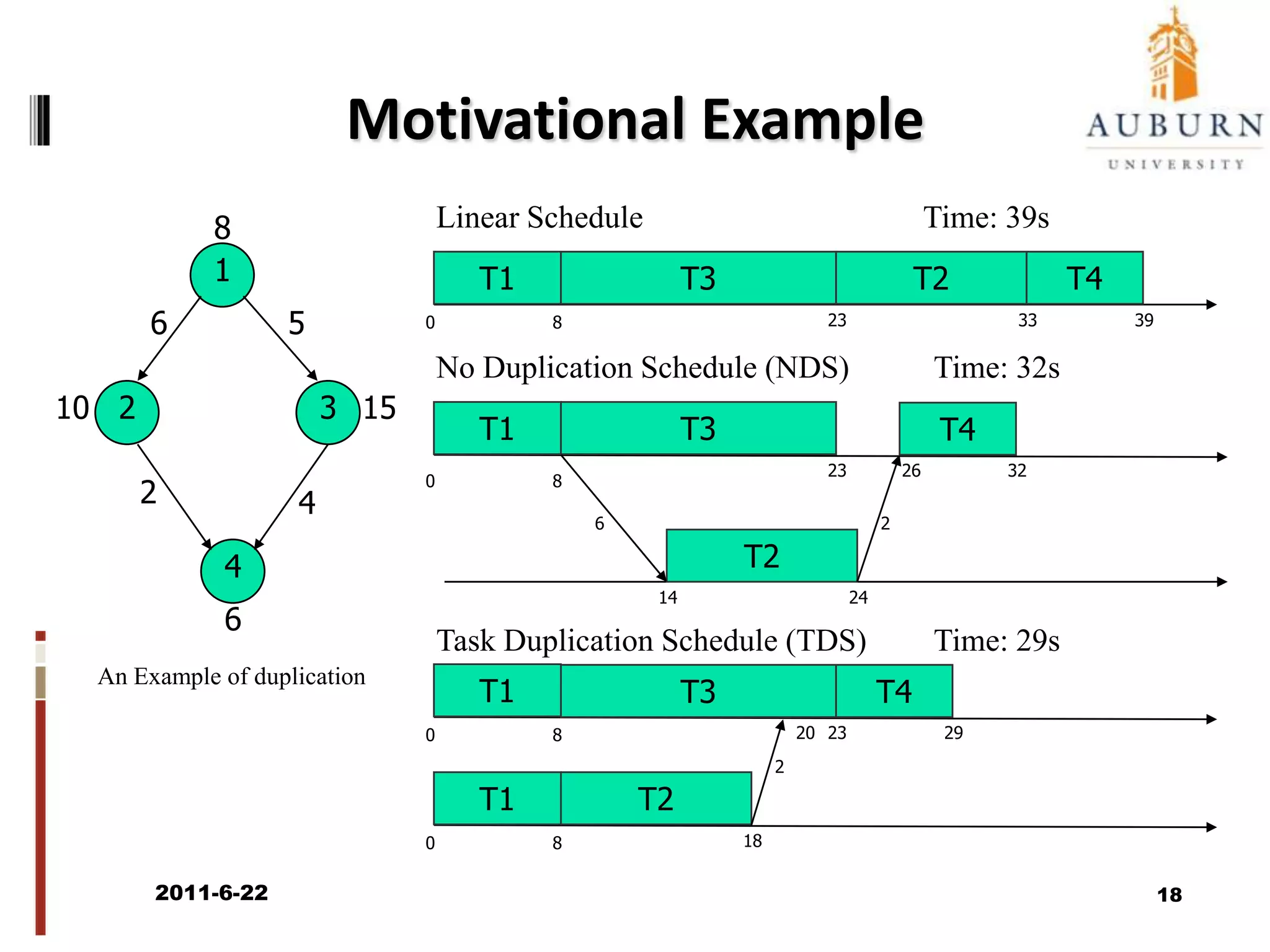
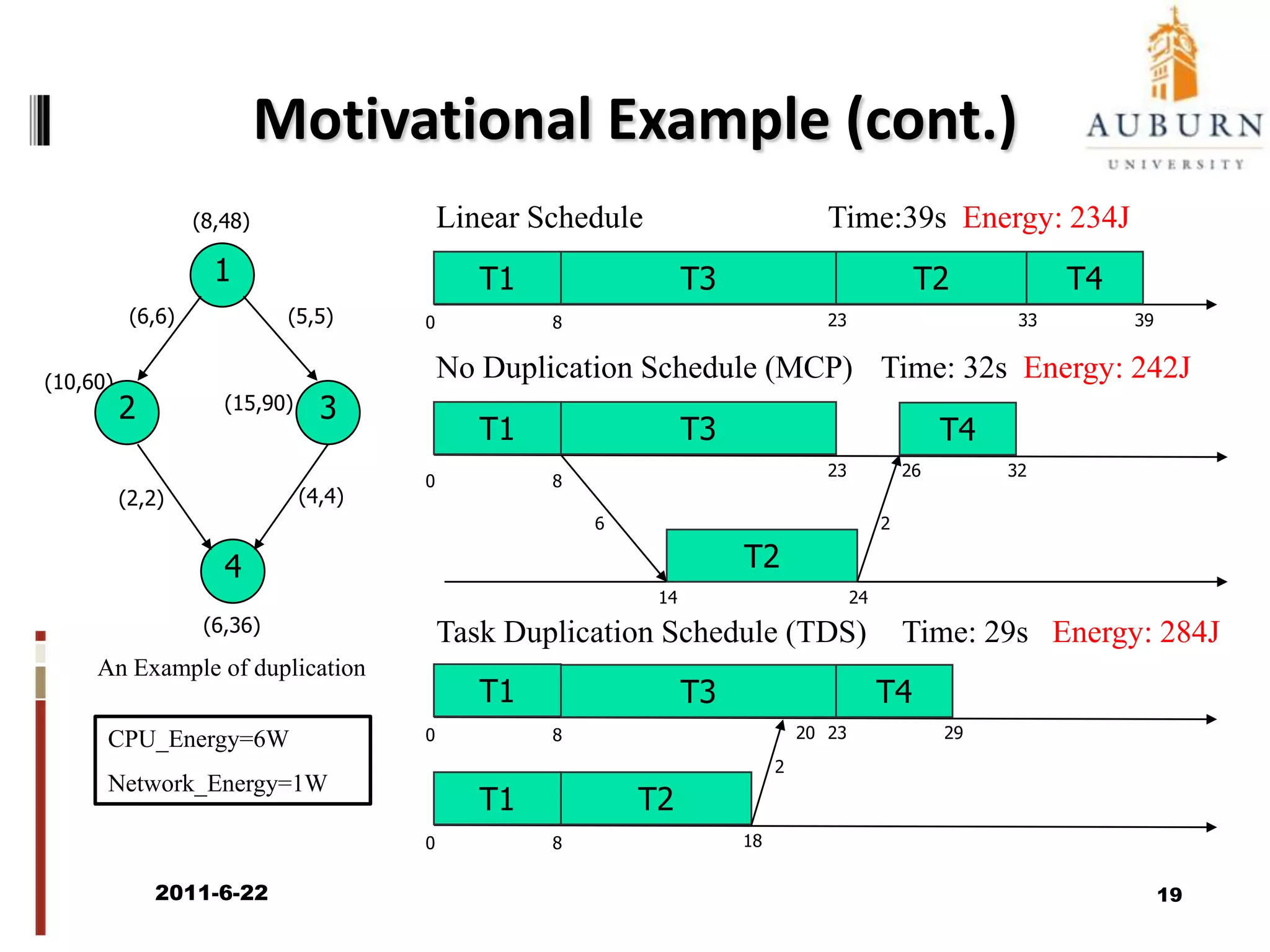
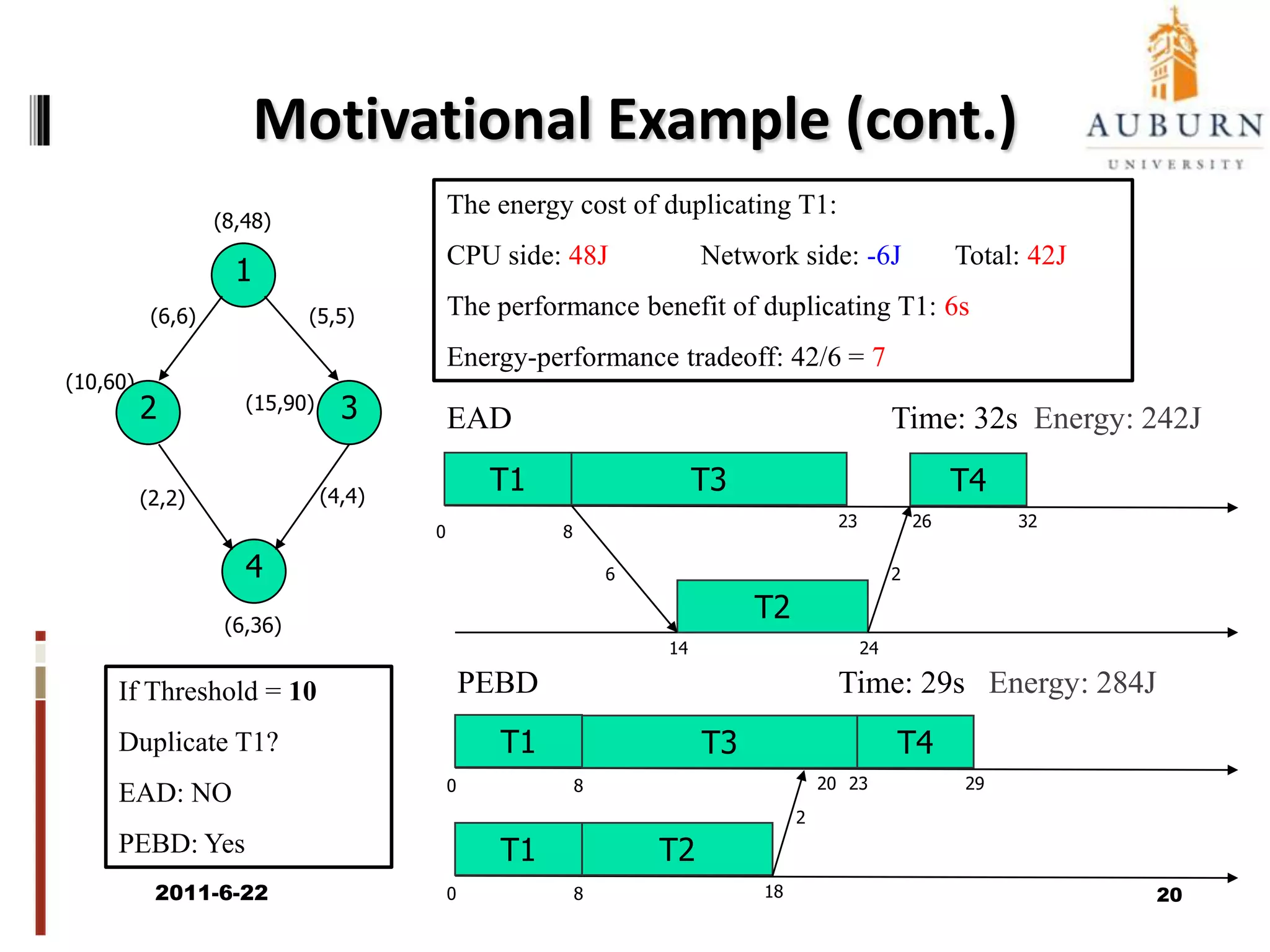
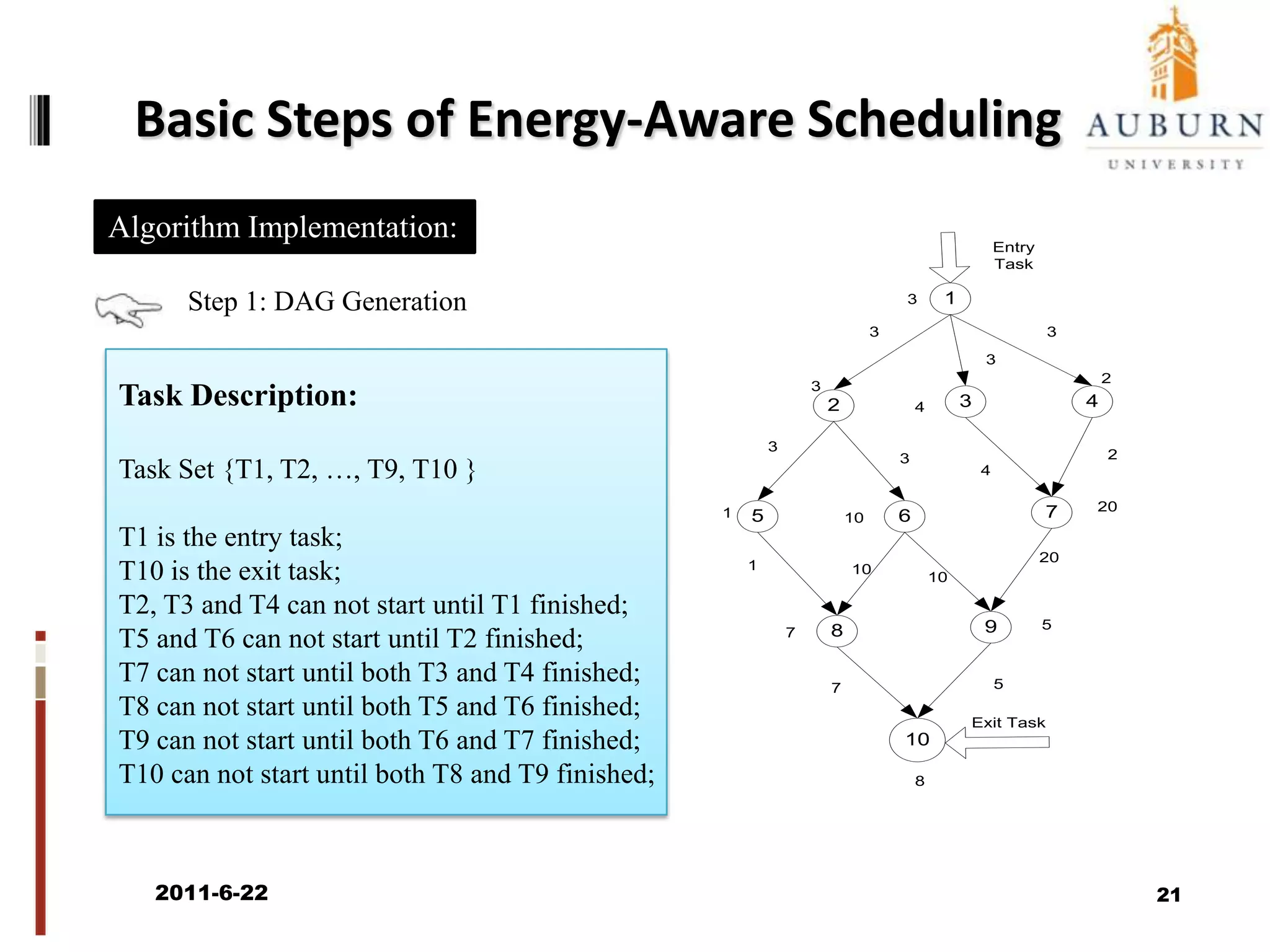
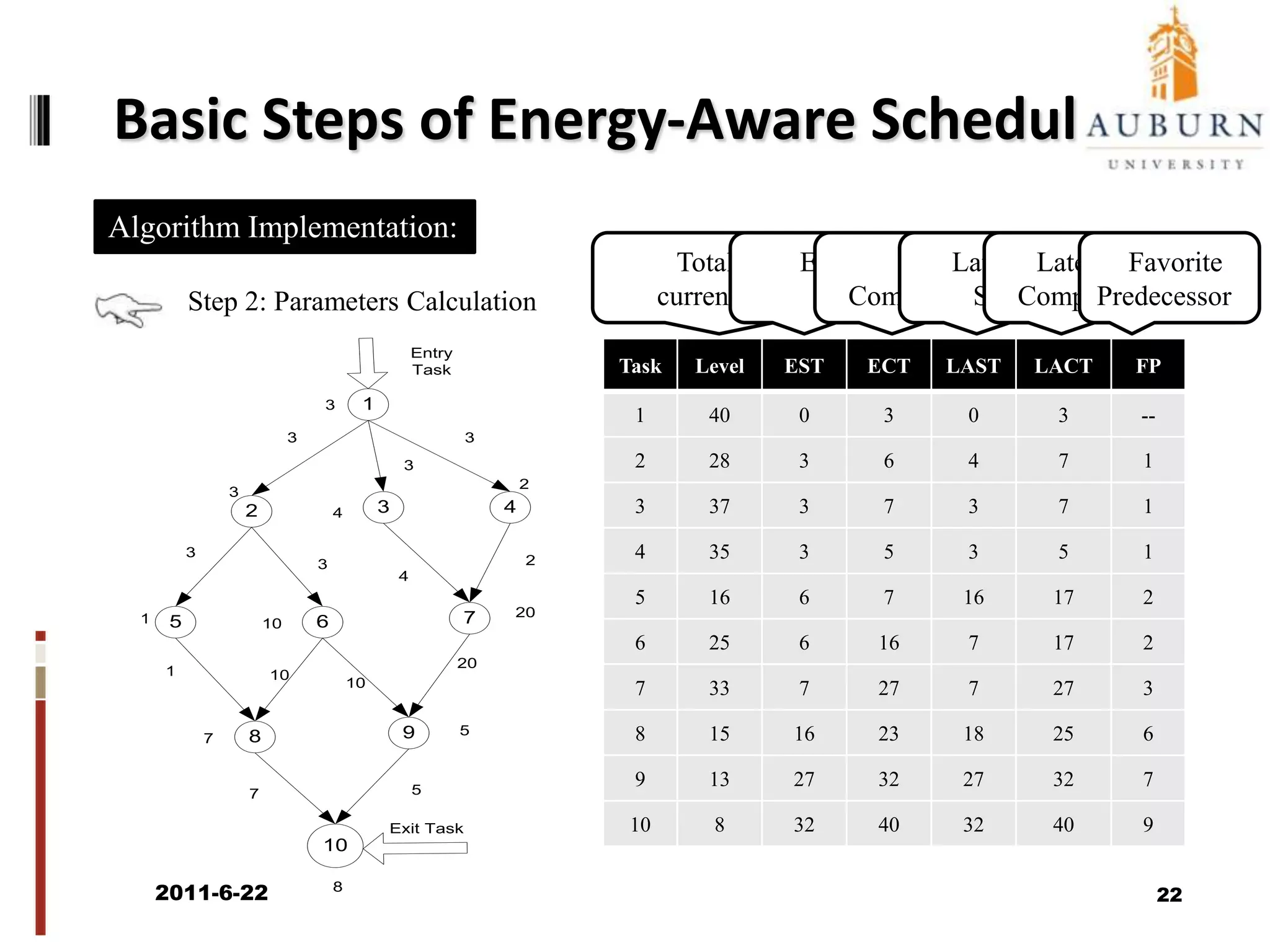
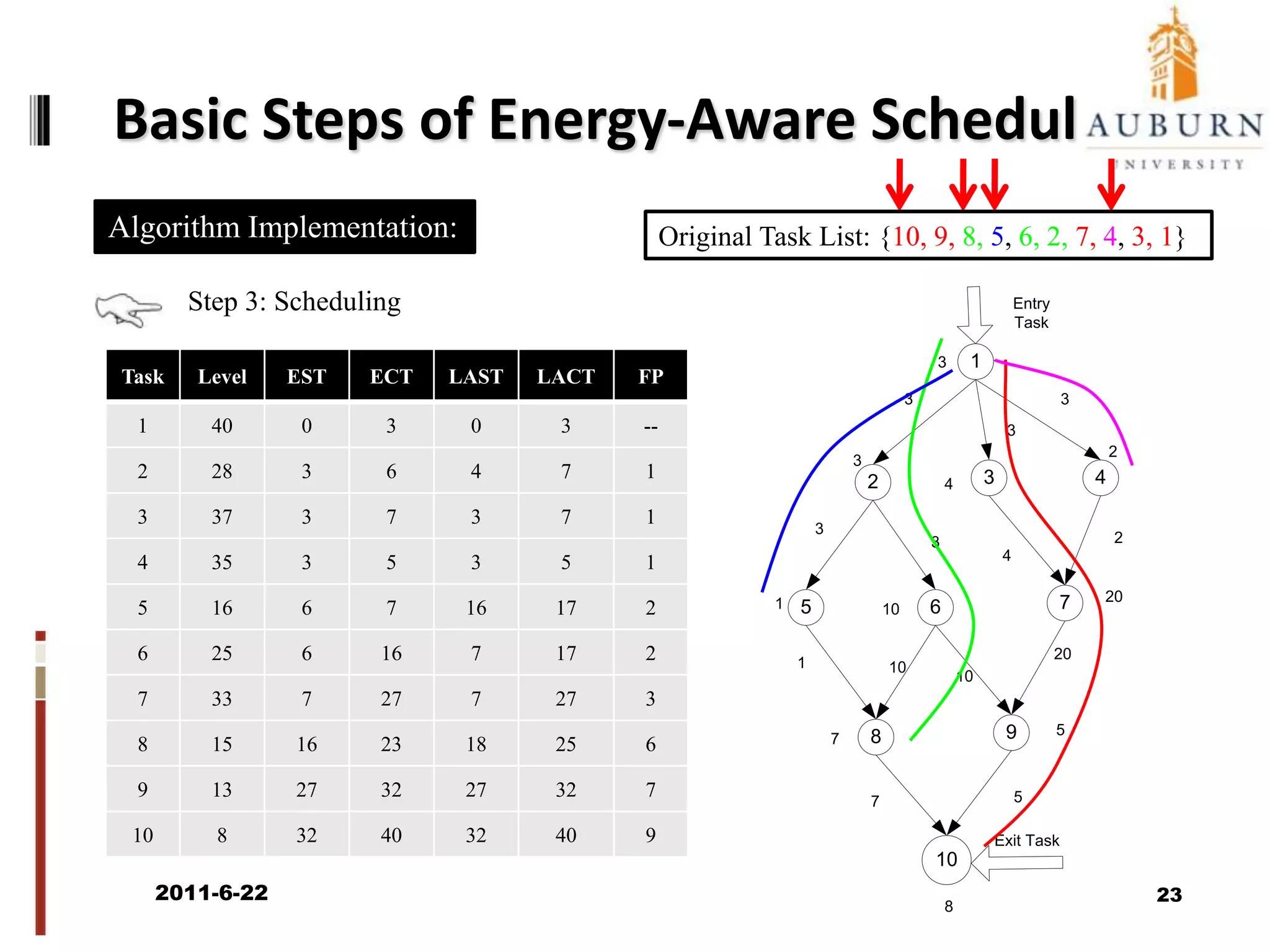
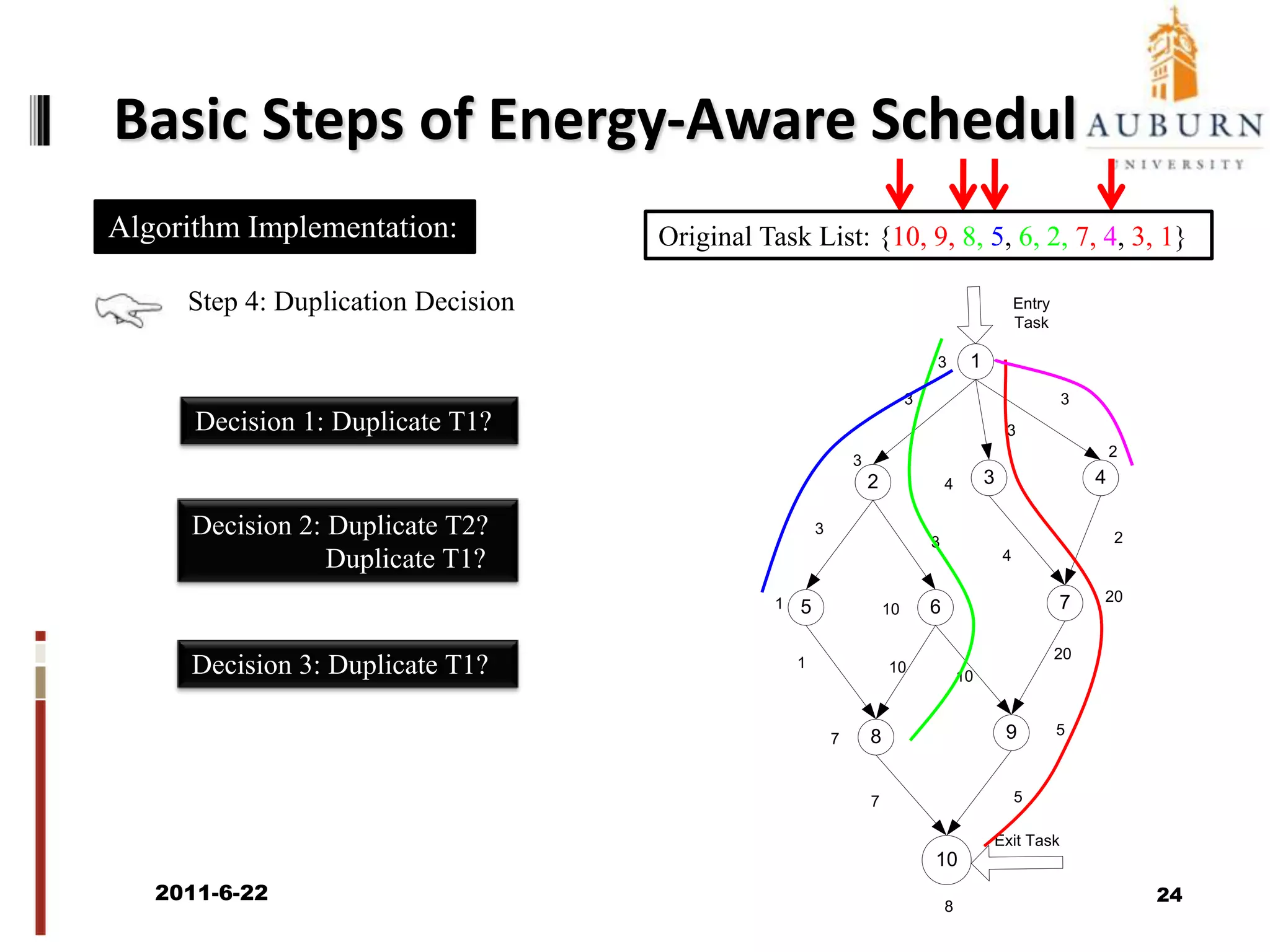
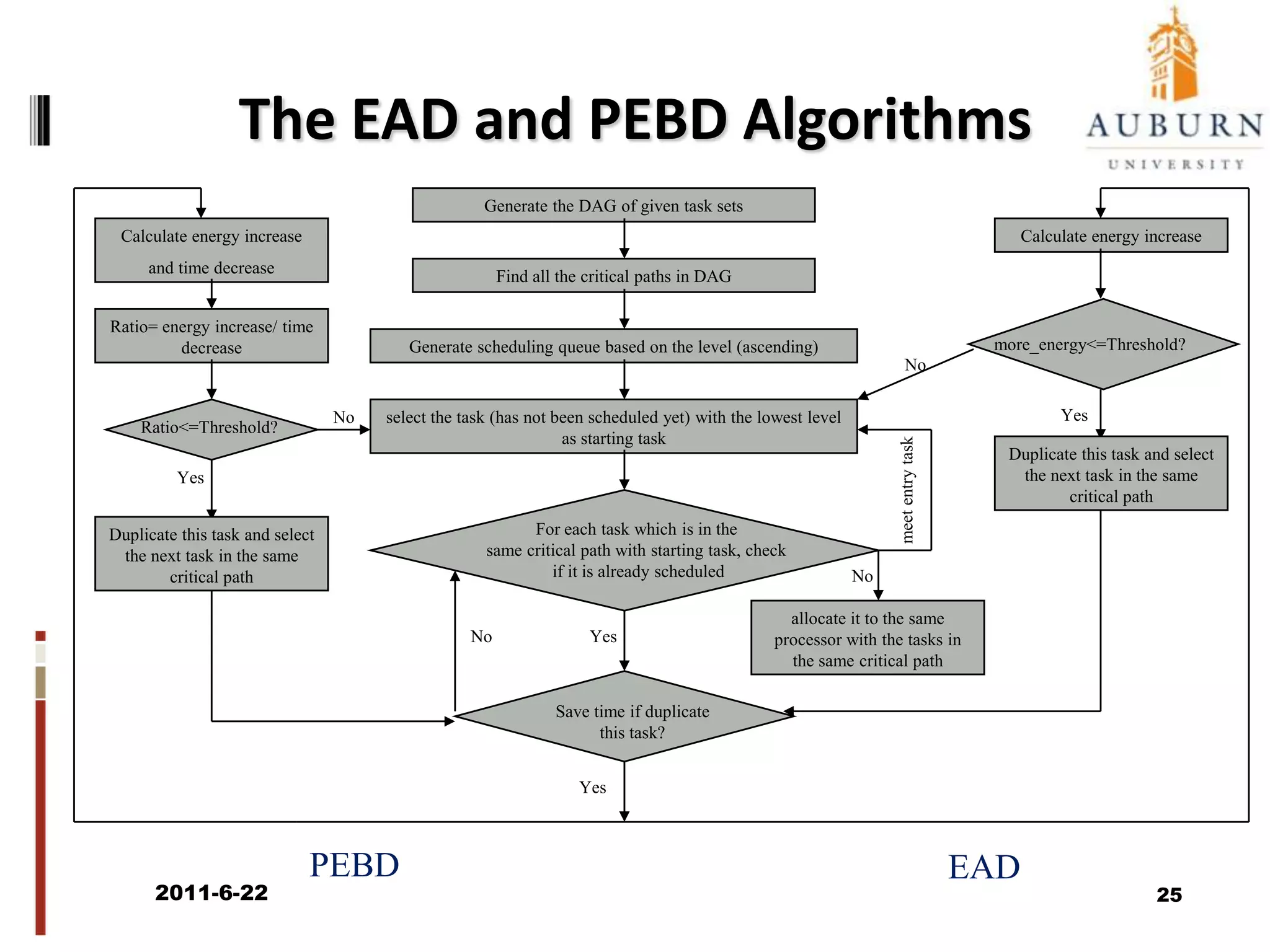
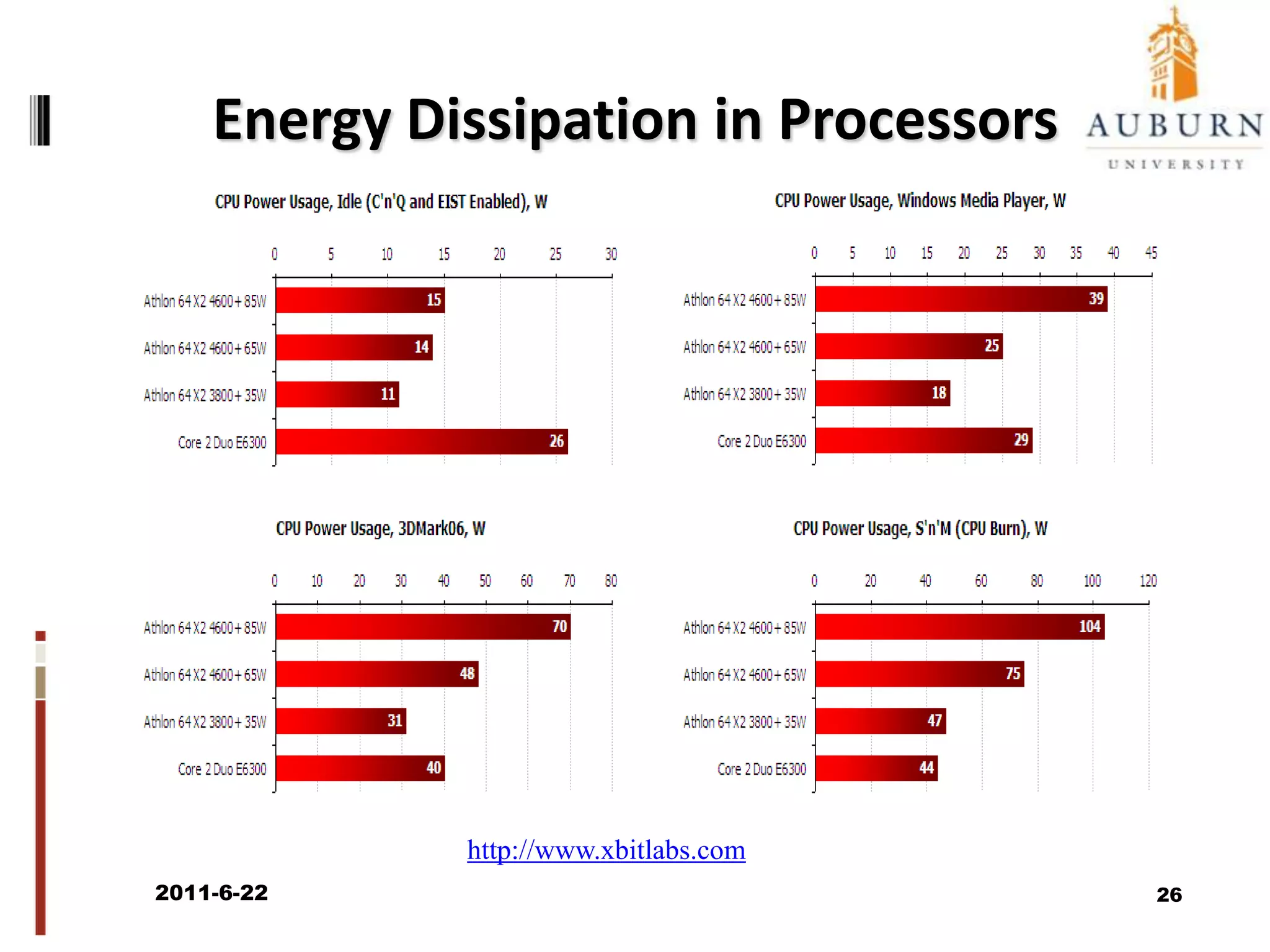
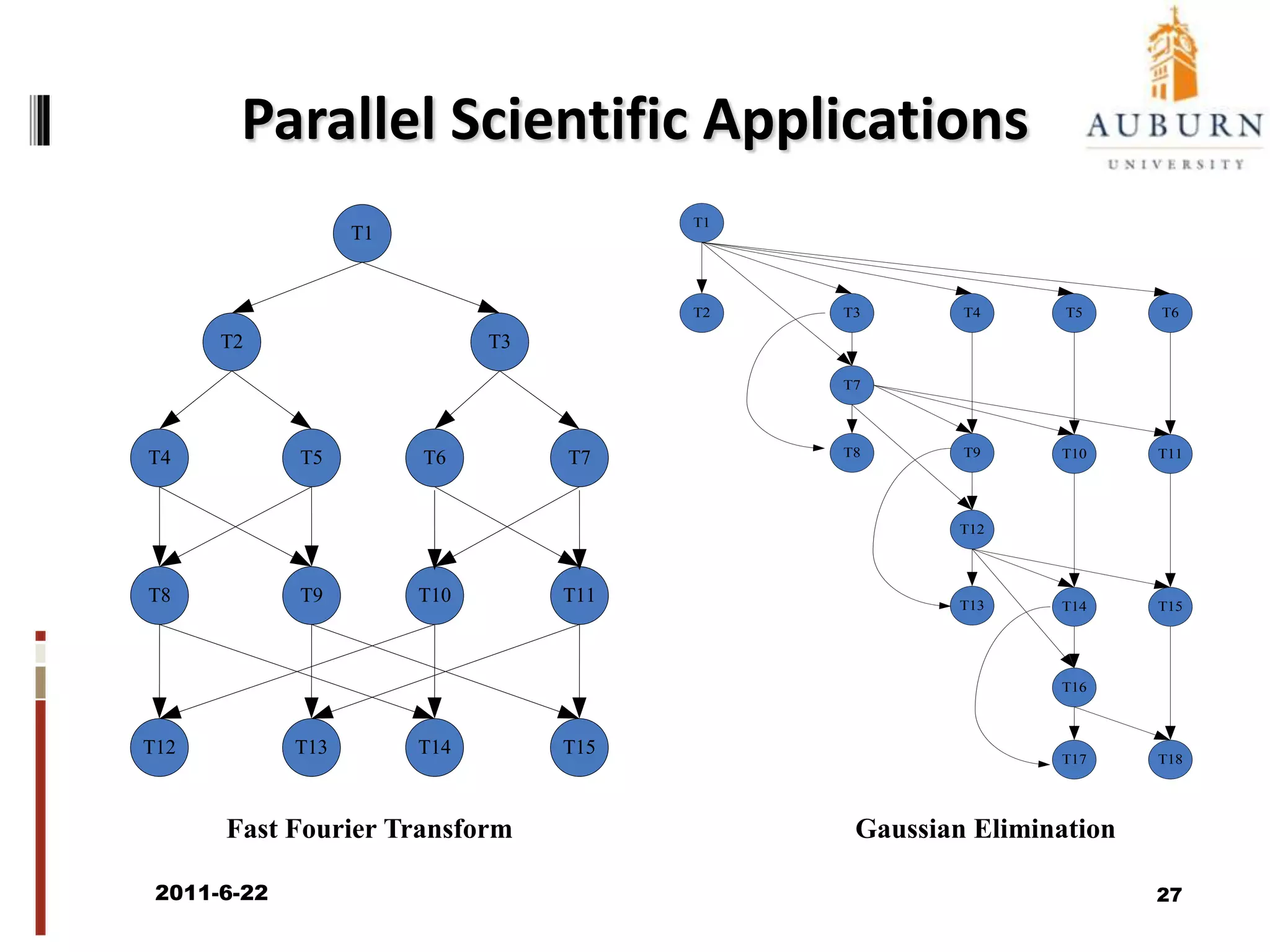
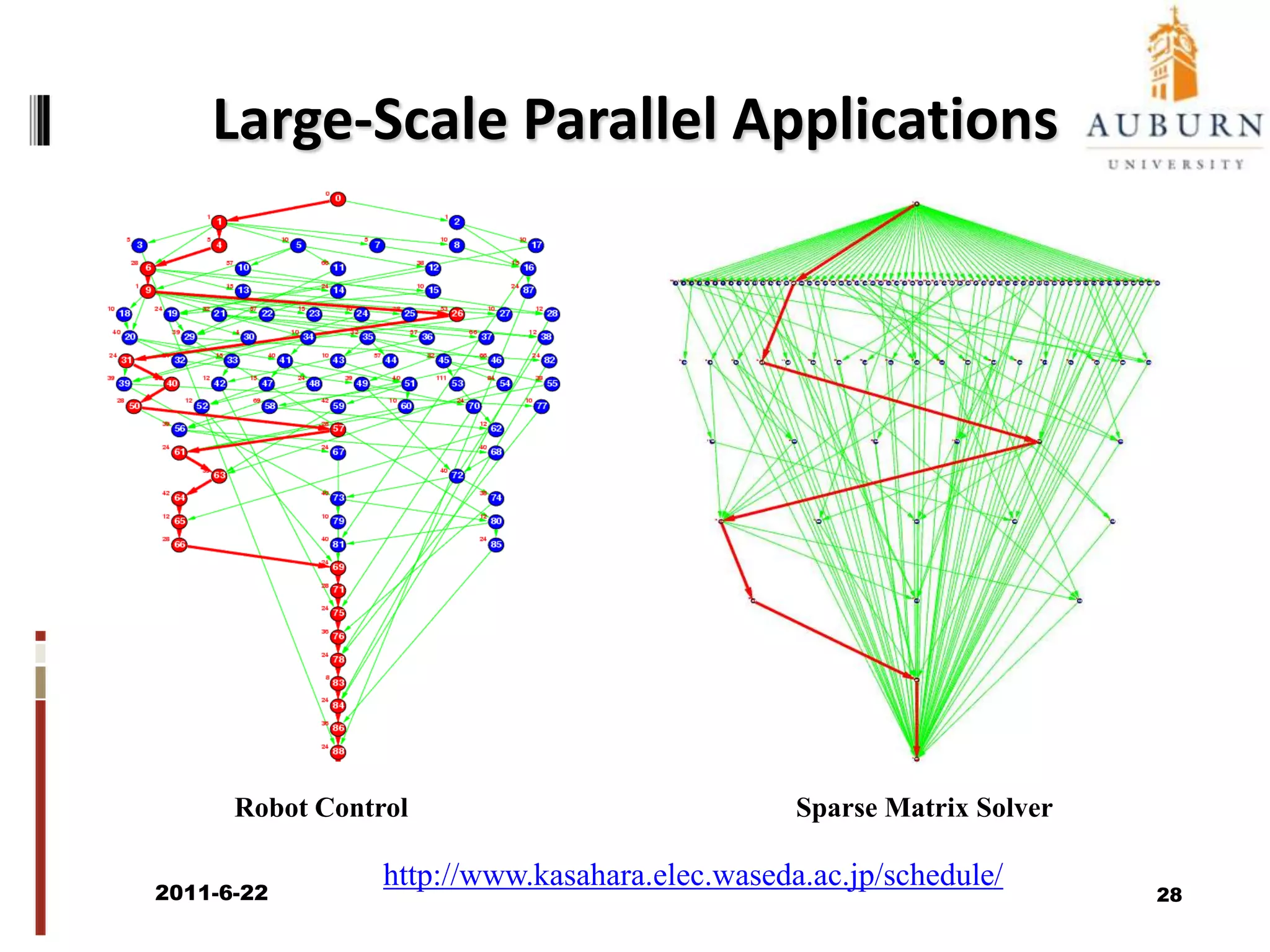
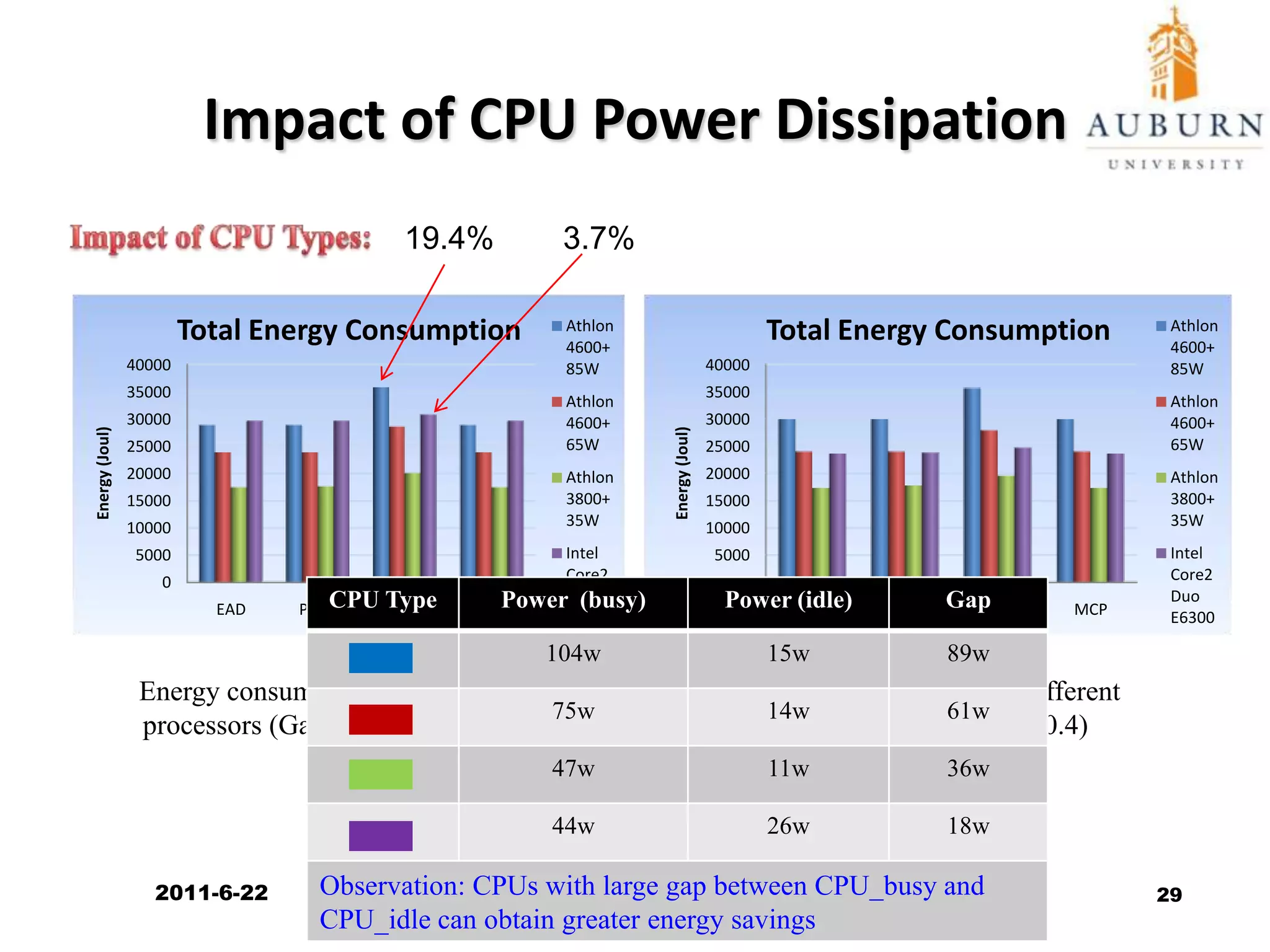
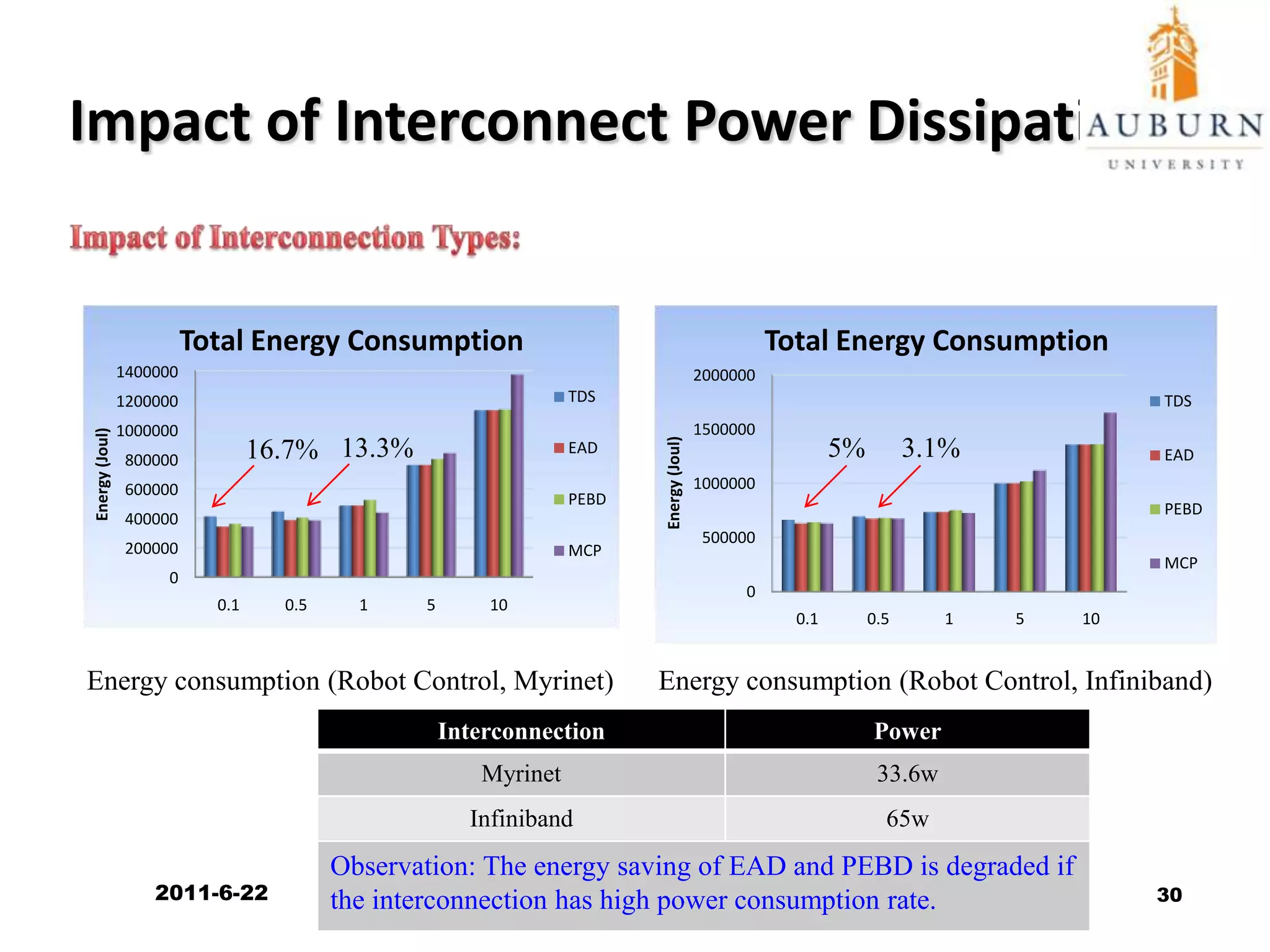
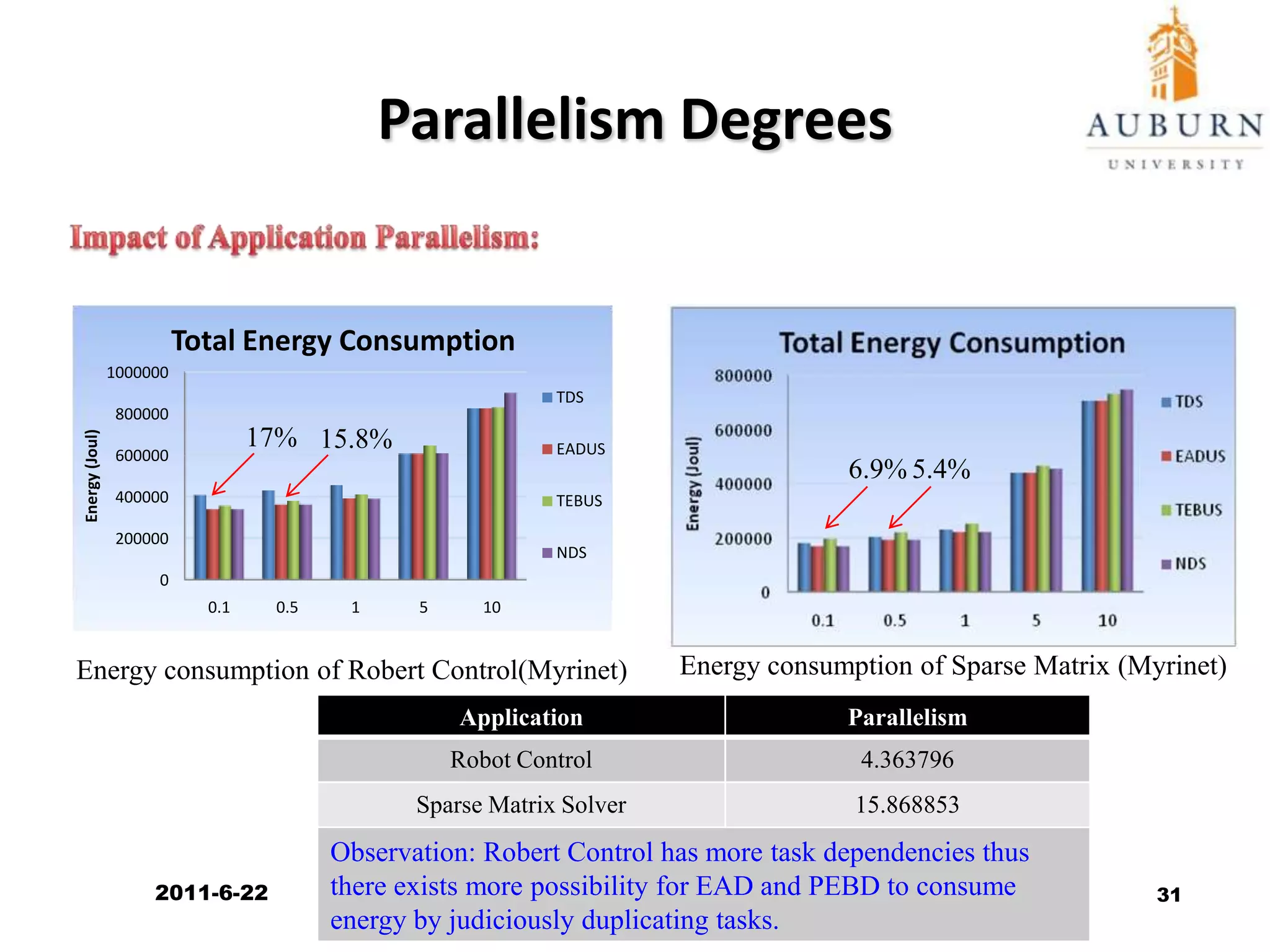
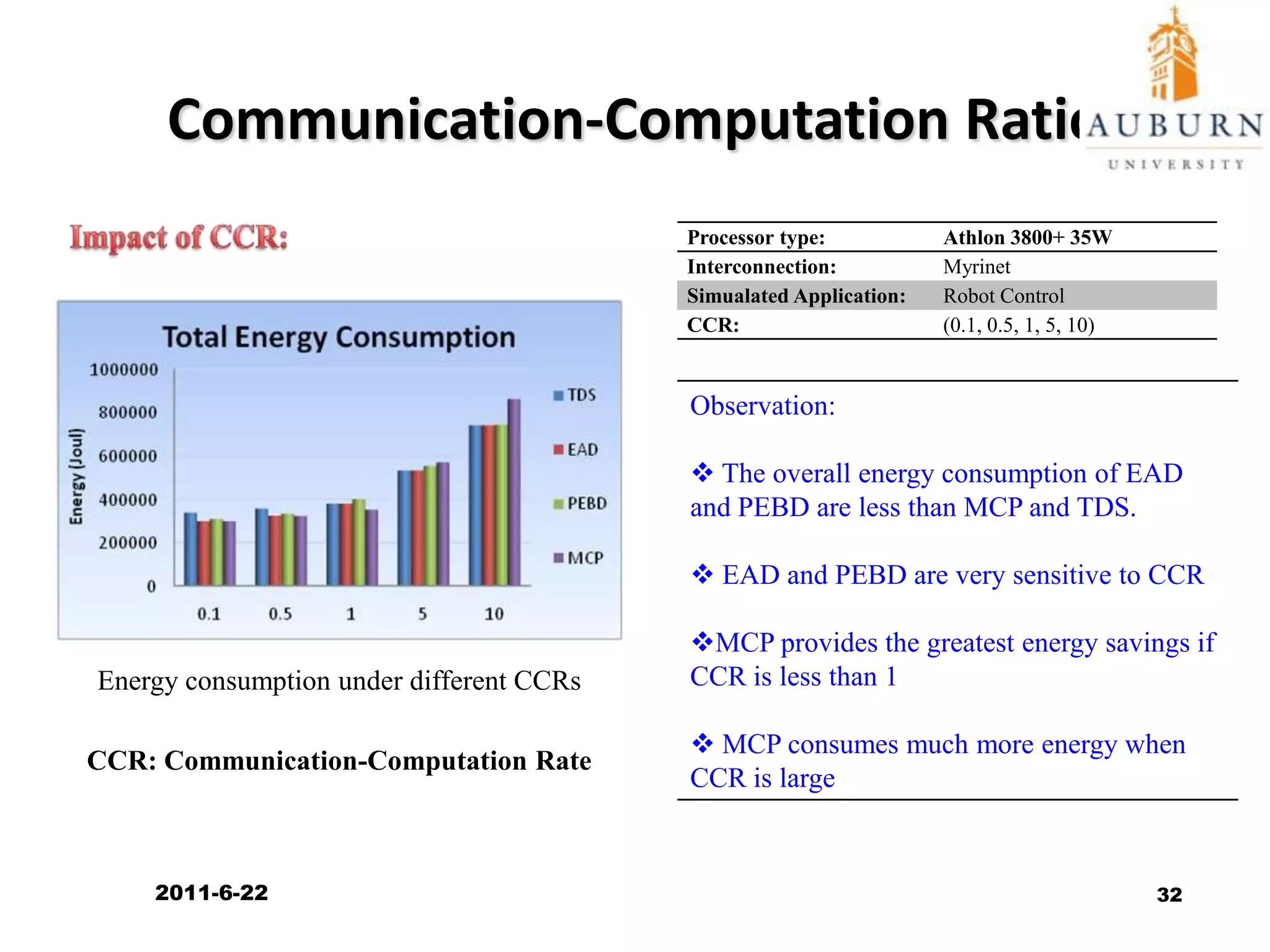
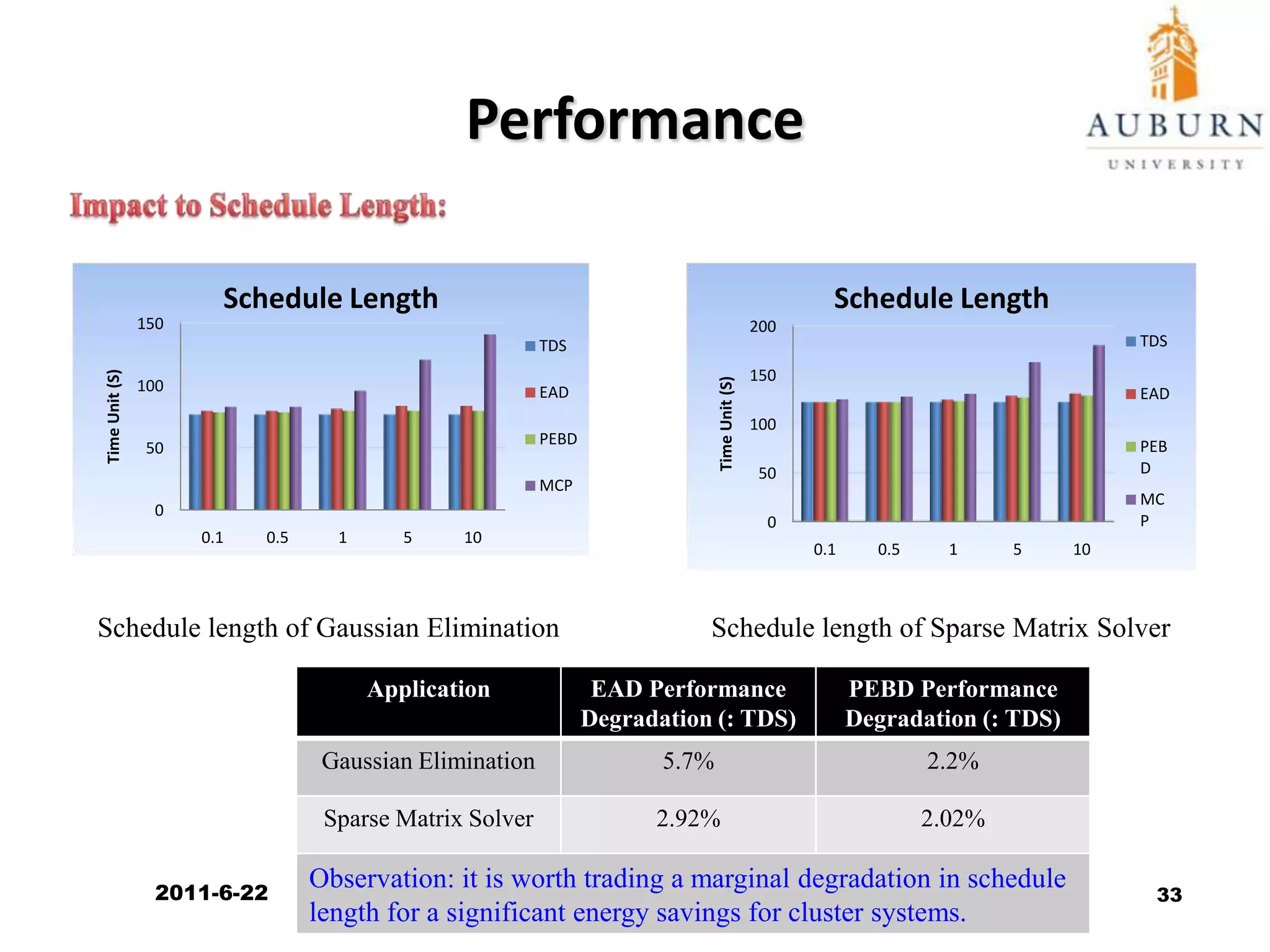
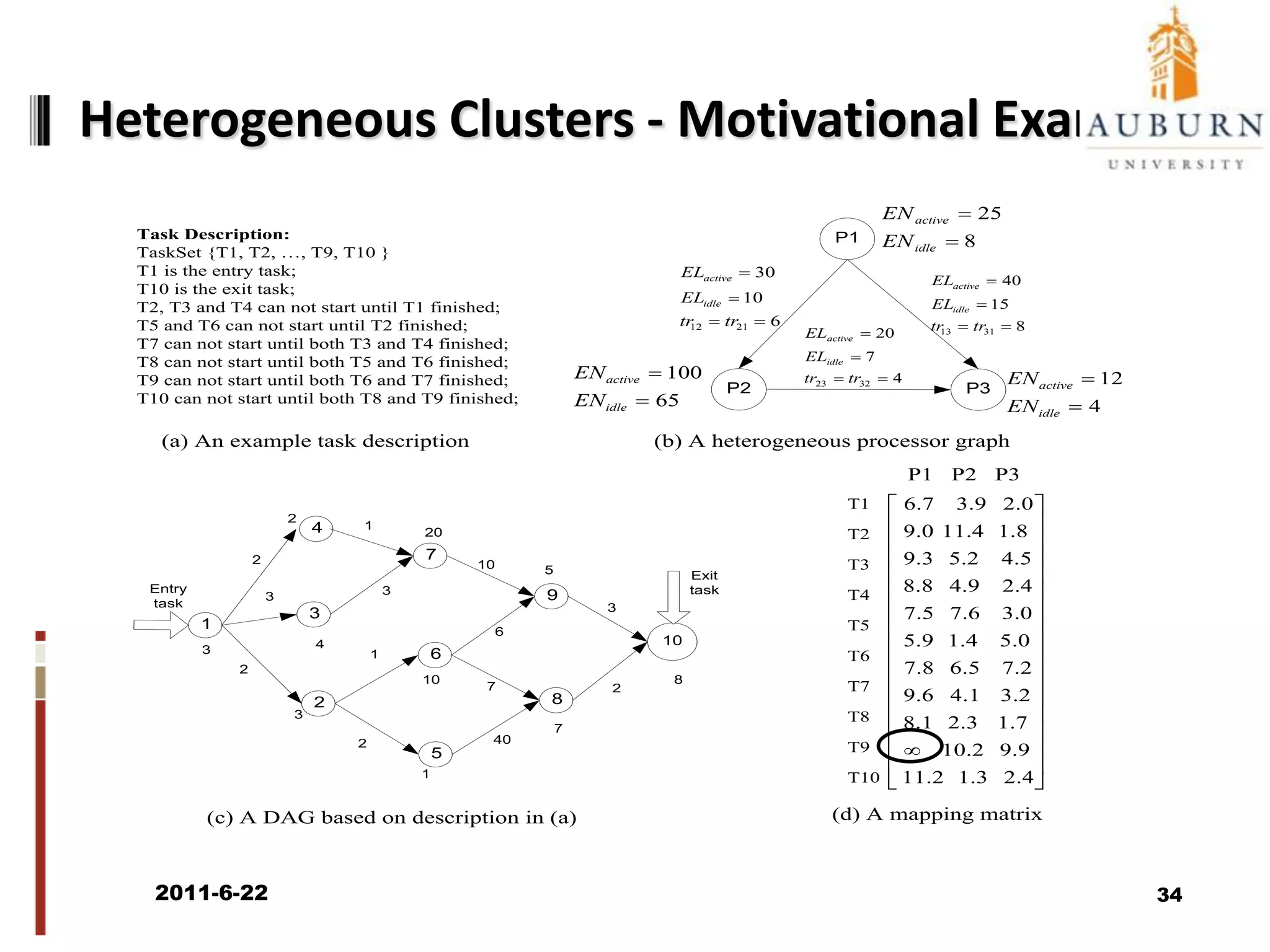
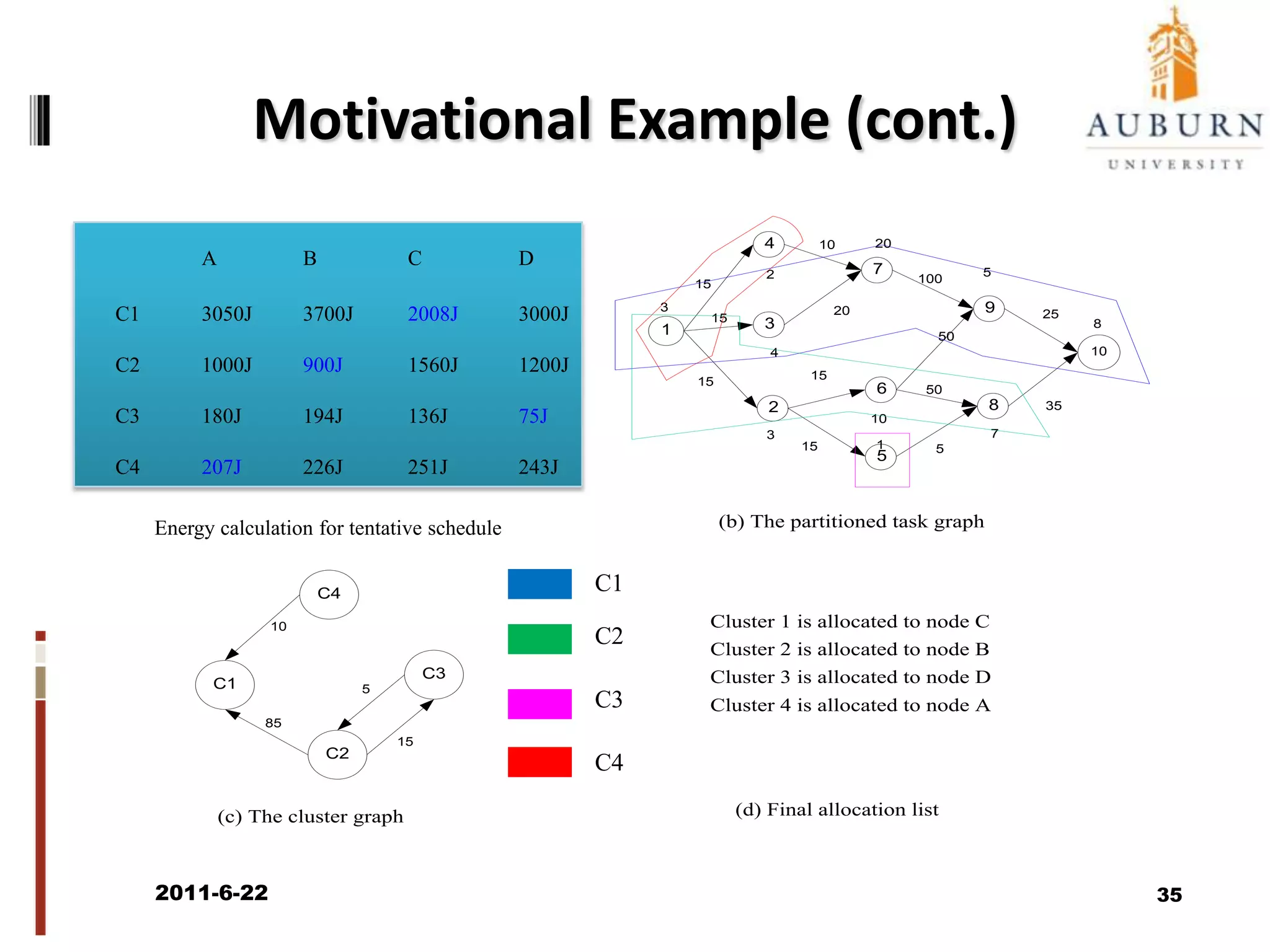
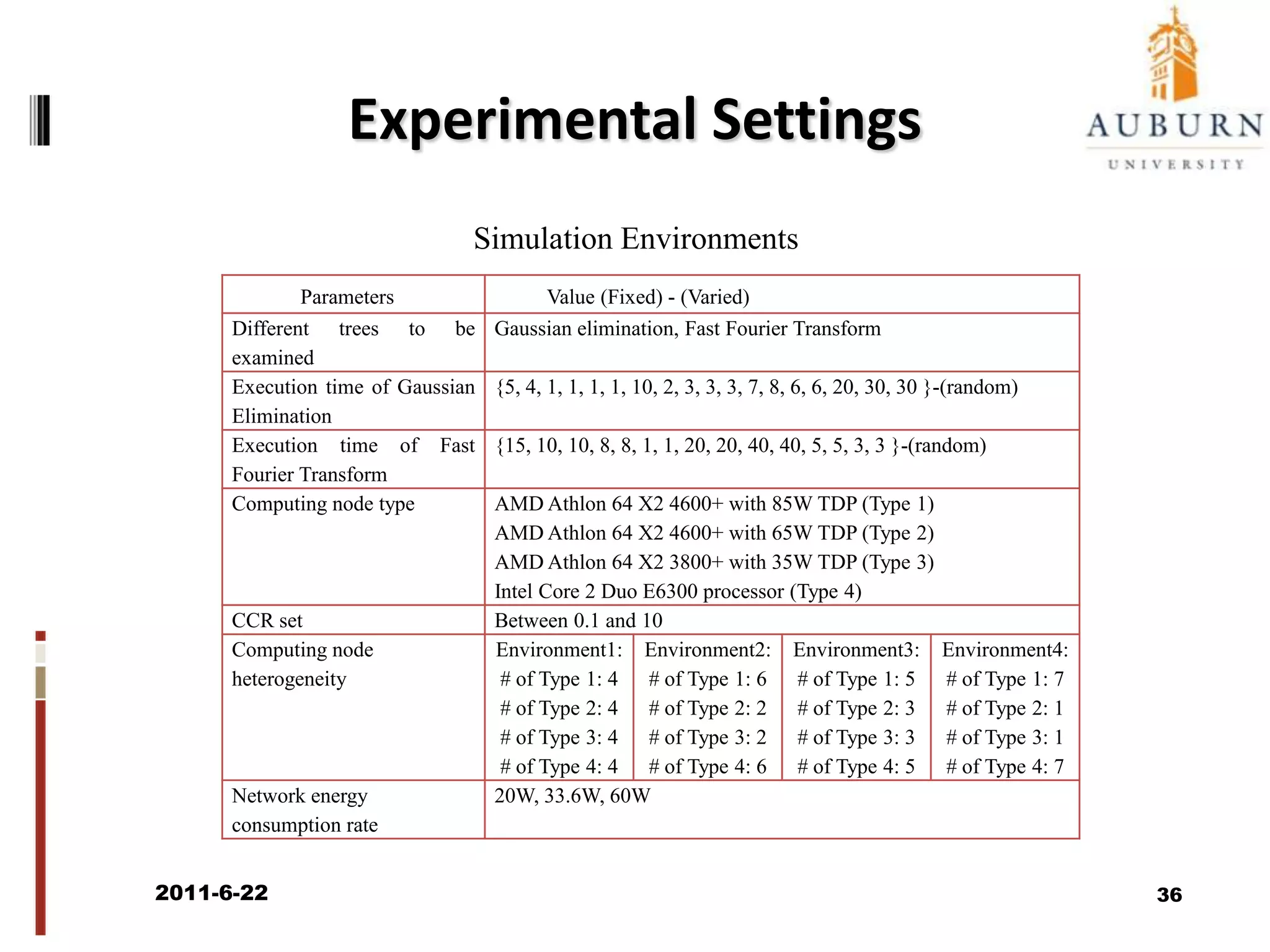
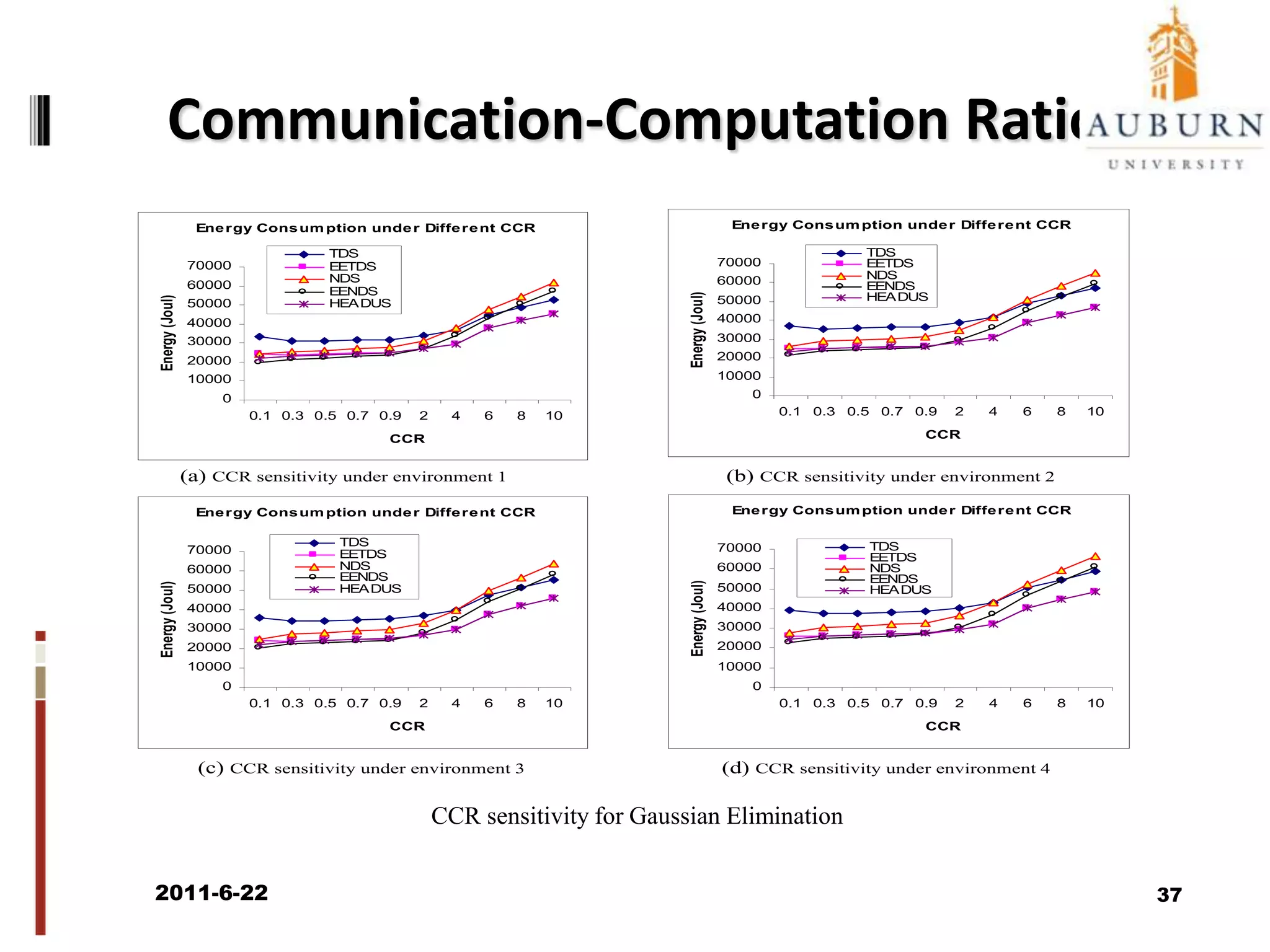
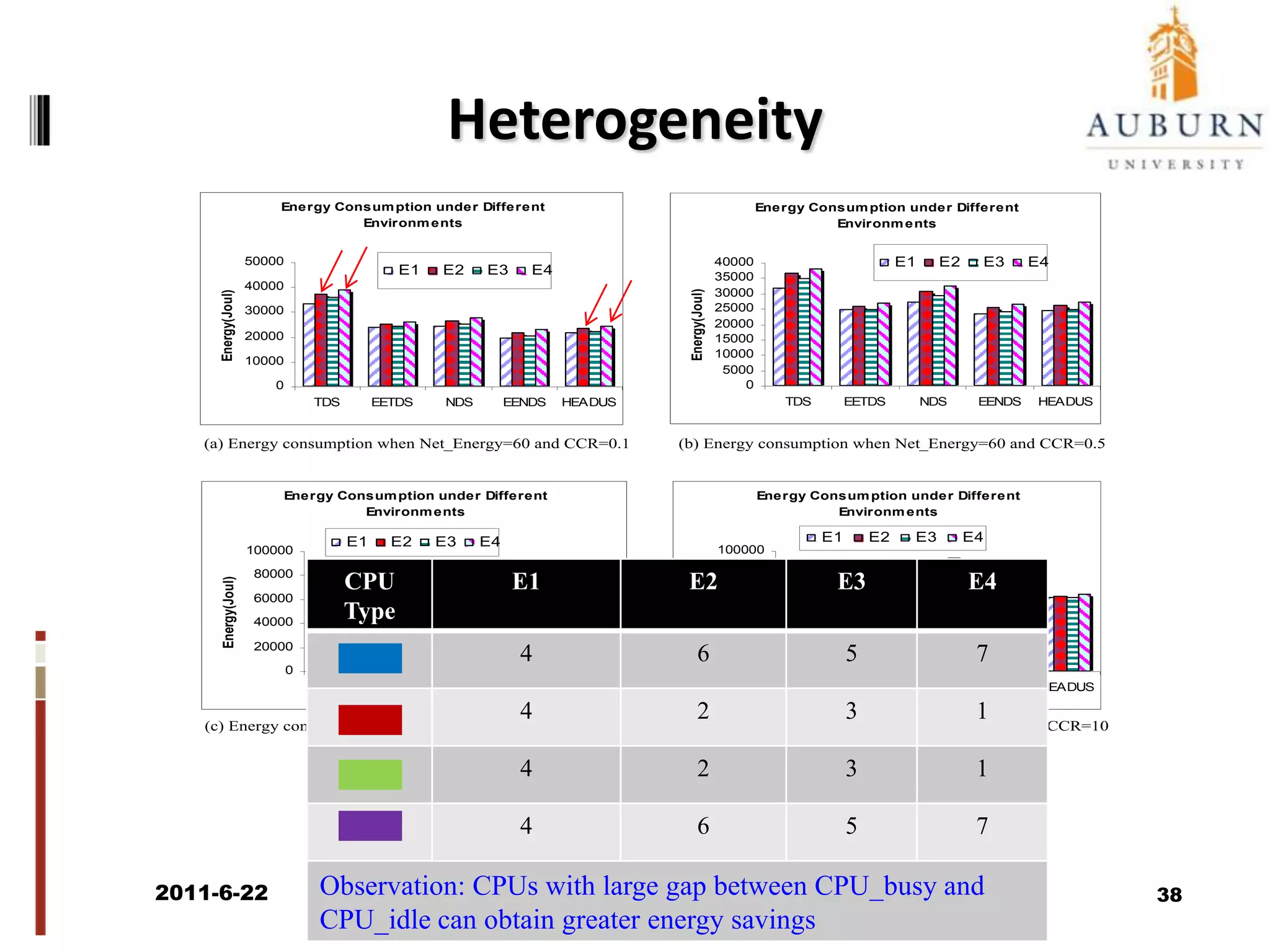




The document discusses energy-efficient scheduling for high-performance clusters, focusing on the implementation of algorithms that reduce electricity consumption in data centers. It includes motivation, architectural considerations, and detailed steps for energy-aware scheduling strategies. Case studies and examples illustrate the energy-performance trade-offs involved in task scheduling and duplication in parallel applications.



































































