Downloaded 219 times

![Who am I?
• Wisely Chen ( thegiive@gmail.com )
• Sr. Engineer inYahoo![Taiwan] data team
• Loves to promote open source tech
• Hadoop Summit 2013 San Jose
• Jenkins Conf 2013 Palo Alto
• Coscup 2006, 2012, 2013 , OSDC 2007,2014, Webconf
2013, Coscup 2012, PHPConf 2012 , RubyConf 2012](https://image.slidesharecdn.com/pyconapac-140516231658-phpapp02/75/PySaprk-2-2048.jpg)









![Python Word Count
• counts = file.flatMap(lambda line: line.split(" "))
You can find the
latest Spark
documentation,
including the
guide
Original text List
['You', 'can', 'find', 'the',
'latest', 'Spark',
'documentation,',
'including', 'the', ‘guide’]](https://image.slidesharecdn.com/pyconapac-140516231658-phpapp02/75/PySaprk-23-2048.jpg)
![Python Word Count
• .map(lambda word: (word, 1))
List Tuple List
[ (‘You’,1) , (‘can’,1),
(‘find’,1) , (‘the’,1) ….,
………..
(‘the’,1) , (‘guide’ ,1) ]
['You', 'can', 'find', 'the',
'latest', 'Spark',
'documentation,',
'including', 'the', ‘guide’]](https://image.slidesharecdn.com/pyconapac-140516231658-phpapp02/75/PySaprk-24-2048.jpg)
![Python Word Count
• .reduceByKey(lambda a, b: a + b)
Tuple List Reduce Tuple List
[ (‘You’,1) ,
(‘can’,1),
(‘find’,1) ,
(‘the’,1),
………..
(‘the’,1) ,
(‘guide’ ,1) ]
[ (‘You’,1) ,
(‘can’,1),
(‘find’,1) ,
(‘the’,2),
………
………..
(‘guide’ ,1) ]](https://image.slidesharecdn.com/pyconapac-140516231658-phpapp02/75/PySaprk-25-2048.jpg)








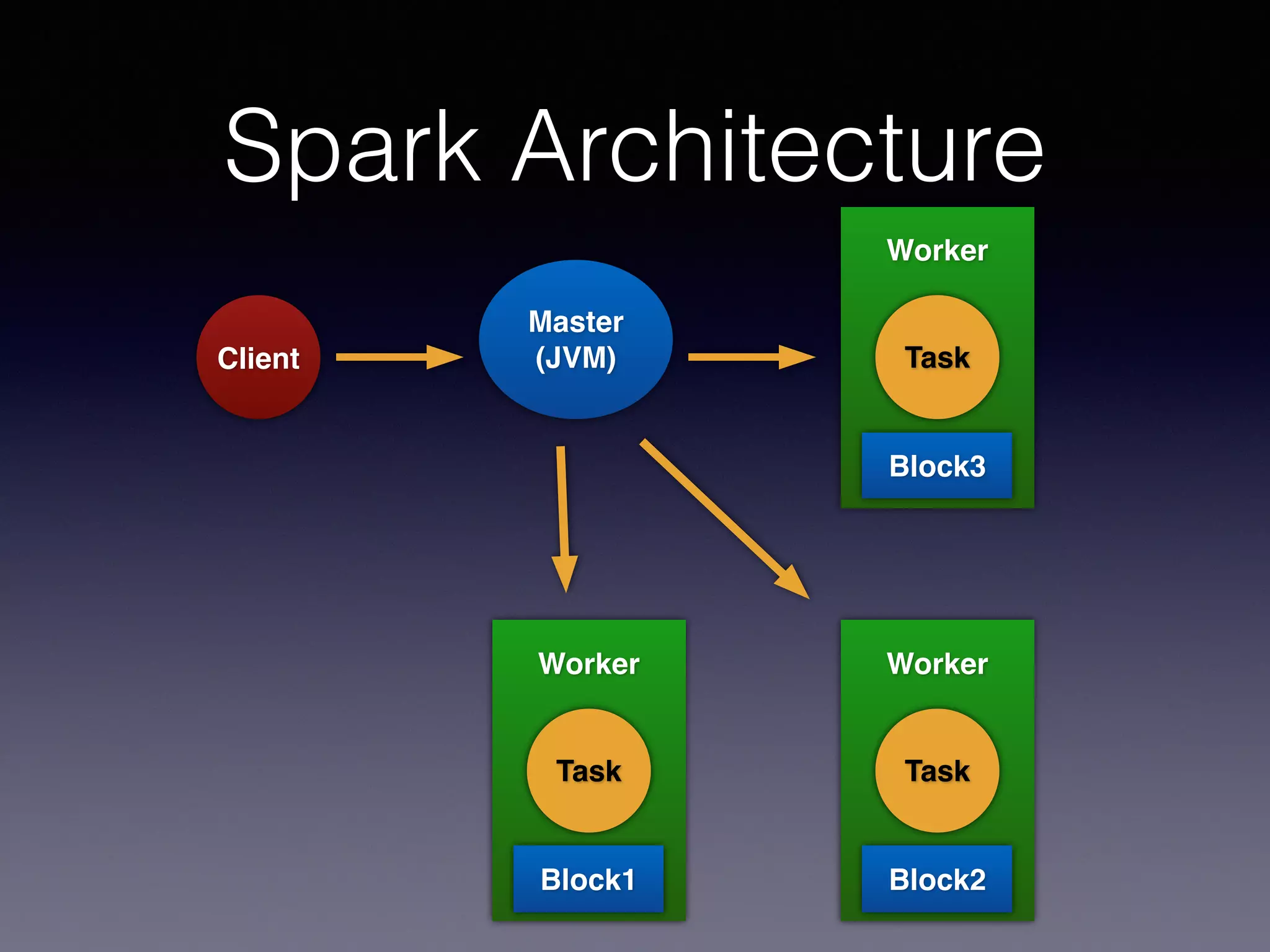
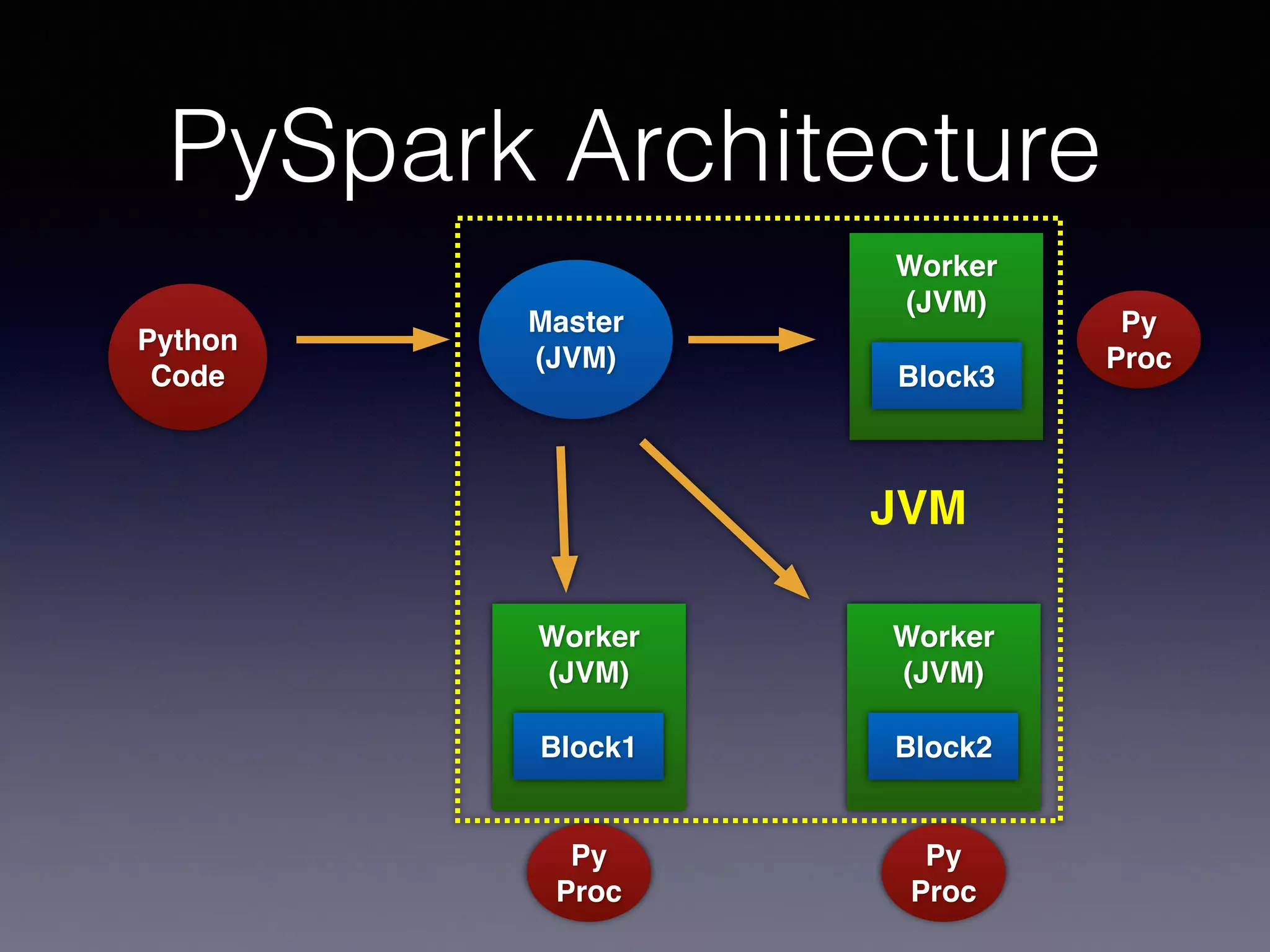
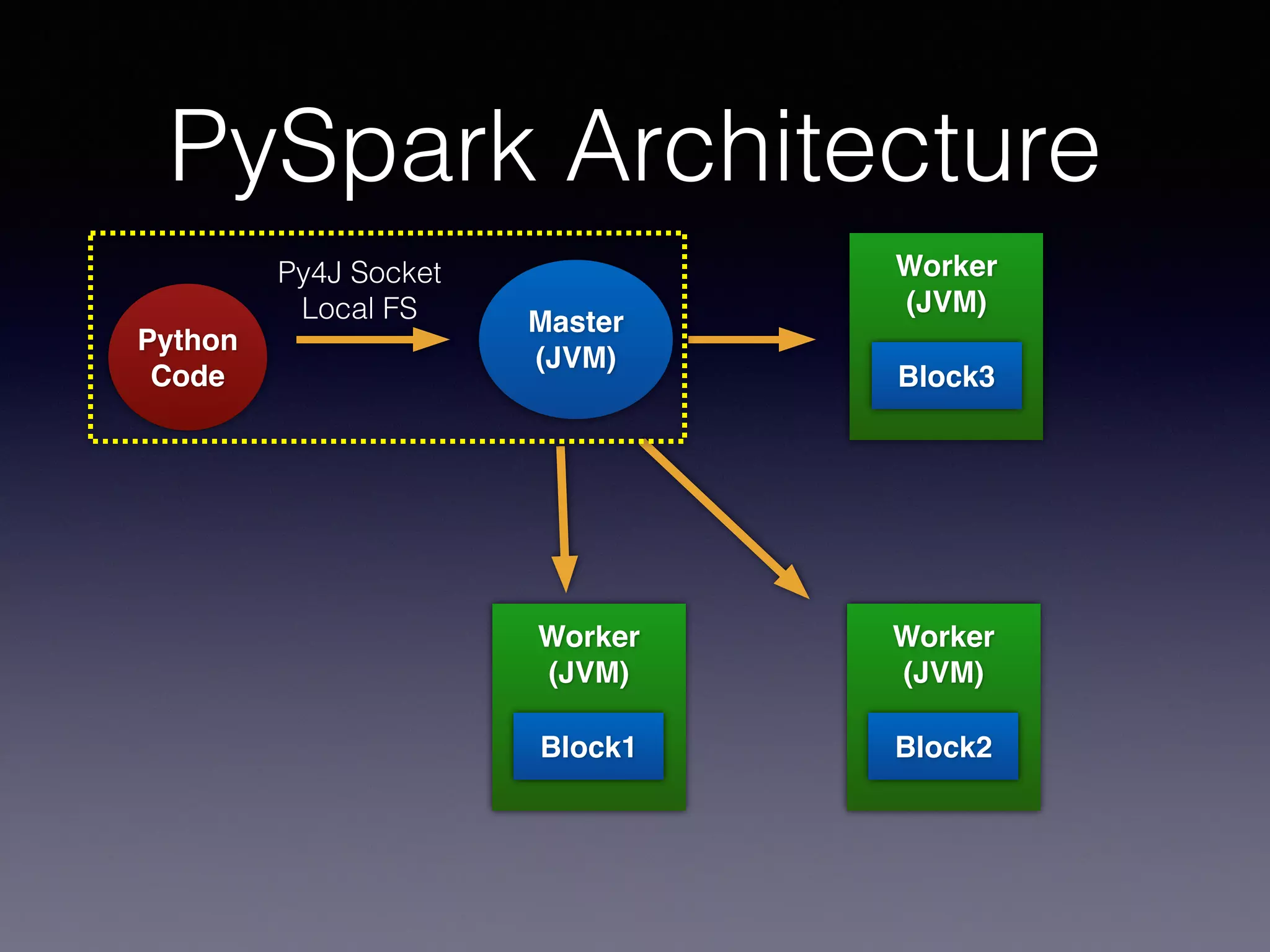
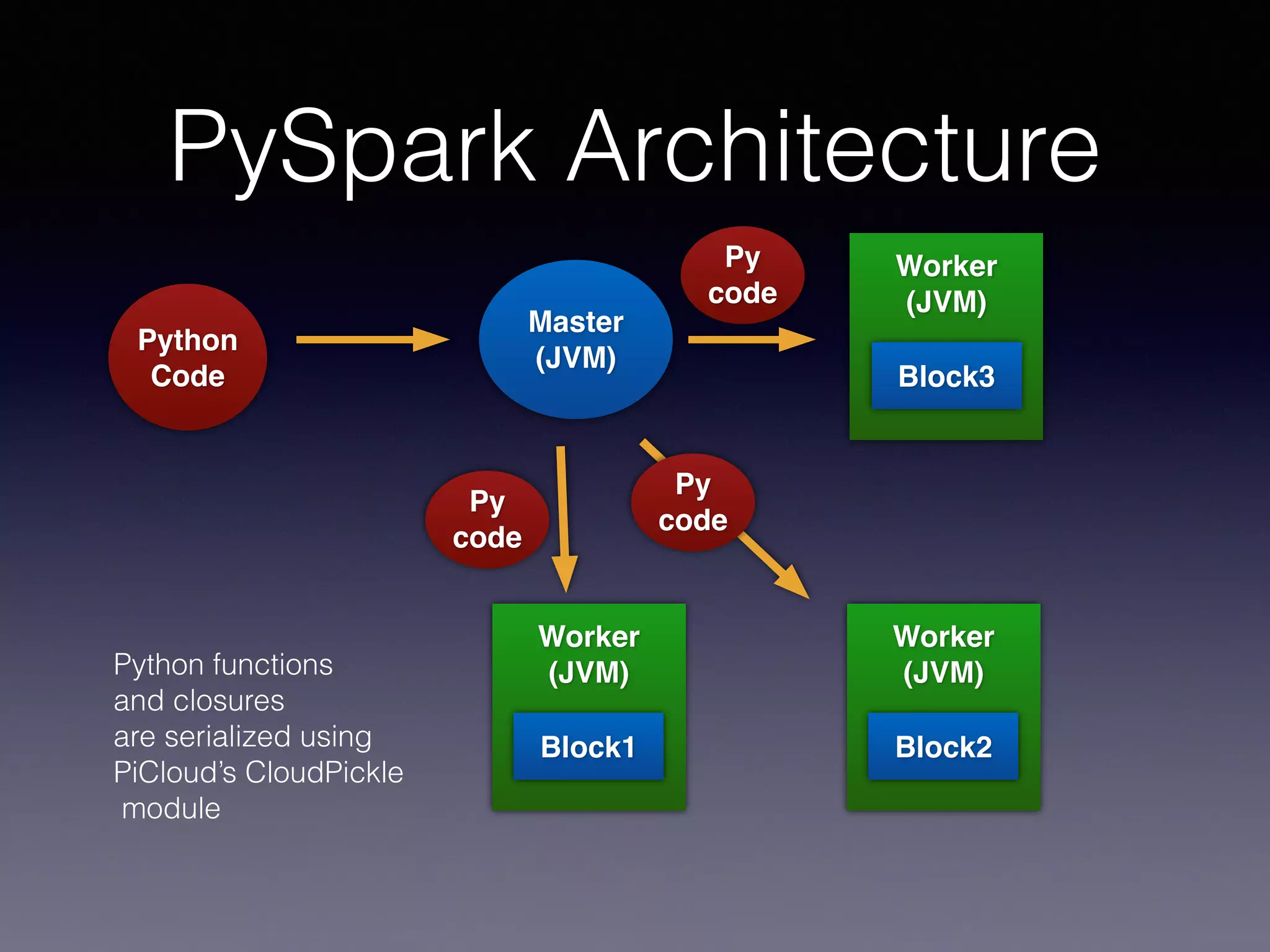
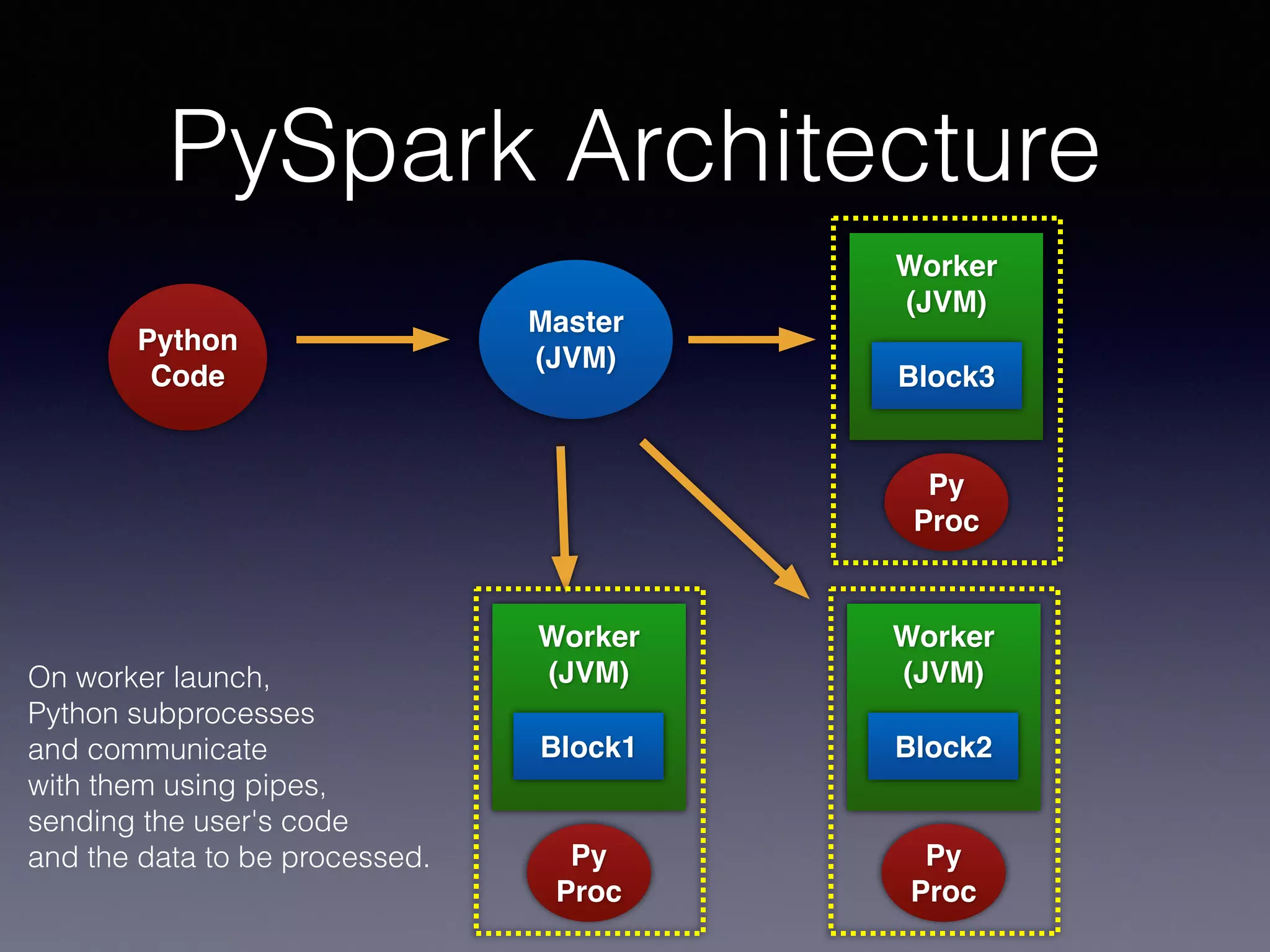
PySpark is a next generation cloud computing engine that uses Python. It allows users to write Spark applications in Python. PySpark applications can access data via the Spark API and process it using Python. The PySpark architecture involves Python code running on worker nodes communicating with Java Virtual Machines on those nodes via sockets. This allows leveraging Python libraries like scikit-learn with Spark. The presentation demonstrated recommender systems and interactive shell usage with PySpark.



































































