Downloaded 437 times









![Document Databases: JavaScript Object Notation
• A JSON document is a collection of key/value pairs, where a value can
be yet another collection of key/value pairs.
string: a string value (e.g. “marko”, “rodriguez”).
number: a numeric value (e.g. 1234, 67.012).
boolean: a true/false value (e.g. true, false)
null: a non-existant value.
array: an array of values (e.g. [1,“marko”,true])
object: a key/value map (e.g. { “key” : 123 })
The JSON specification is very simple and can be found at http://www.json.org/.
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-13-2048.jpg)
![Document Databases: JavaScript Object Notation
{
_id : "D0DC29E9-51AE-4A8C-8769-541501246737",
name : "Marko A. Rodriguez",
homepage : "http://markorodriguez.com",
age : 30,
location : {
country : "United States",
state : "New Mexico",
city : "Santa Fe",
zipcode : 87501
},
interests : ["graphs", "hockey", "motorcycles"]
}
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-14-2048.jpg)
![Document Databases: Handling JSON Documents
• Use object-oriented “dot notation” to access components.
> marko = eval({_id : "D0DC29E9...", name : "Marko...})
> marko._id
D0DC29E9-51AE-4A8C-8769-541501246737
> marko.location.city
Santa Fe
> marko.interests[0]
graphs
All document database examples presented are using MongoDB [http://mongodb.org].
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-15-2048.jpg)



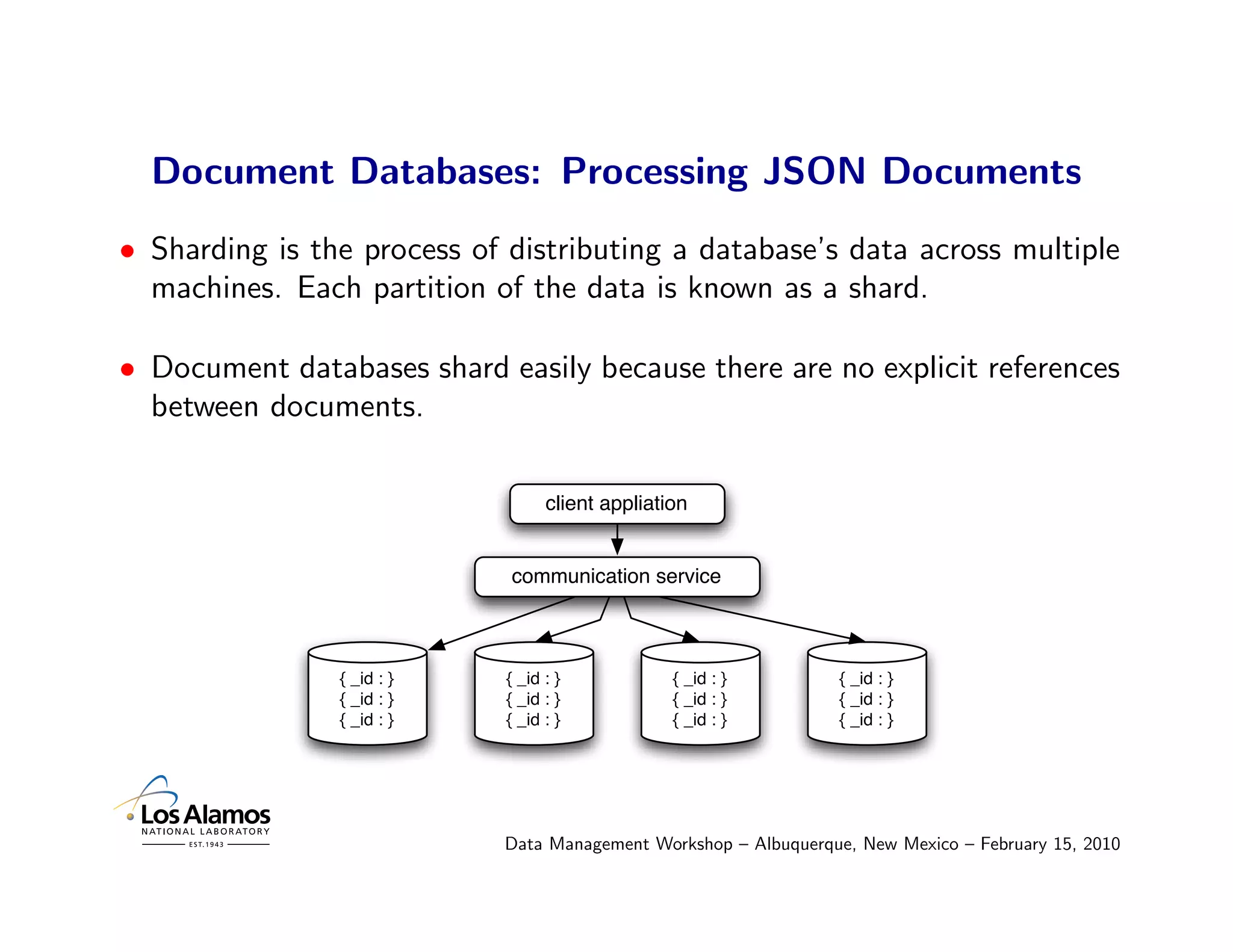

![Document Databases: Processing JSON Documents
• Create a distribution of the Grateful Dead original song performances.
> map = function(){
if(this.properties.song_type == "original")
emit(this.properties.performances, 1);
};
> reduce = function(key, values) {
var sum = 0;
for(var i in values) {
sum = sum + values[i];
}
return sum;
};
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-21-2048.jpg)

![{ _id : 122, { _id : 100, { _id : 91,
properties : { properties : { properties : {
name : "CASEY ..." name : "PLAYIN..." name : "TERRAP..."
performances : 312 performances : 312 performances : 302
}} }} }}
map = function(){
if(this.properties.song_type == "original")
emit(this.properties.performances, 1);
};
key value
312 : 1
312 : 1
302 : 1
...
key values
312 : [1,1]
302 : [1]
...
reduce = function(key, values) {
var sum = 0;
for(var i in values) {
sum = sum + values[i];
}
return sum;
};
{
312 : 2
302 : 1
...
}
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-23-2048.jpg)
![Document Databases: Processing JSON Documents
> db[results.result].find()
{ "_id" : 0, "value" : 11 }
{ "_id" : 1, "value" : 14 }
{ "_id" : 2, "value" : 5 }
{ "_id" : 3, "value" : 8 }
{ "_id" : 4, "value" : 3 }
{ "_id" : 5, "value" : 4 }
...
{ "_id" : 554, "value" : 1 }
{ "_id" : 582, "value" : 1 }
{ "_id" : 583, "value" : 1 }
{ "_id" : 594, "value" : 1 }
{ "_id" : 1386, "value" : 1 }
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-24-2048.jpg)

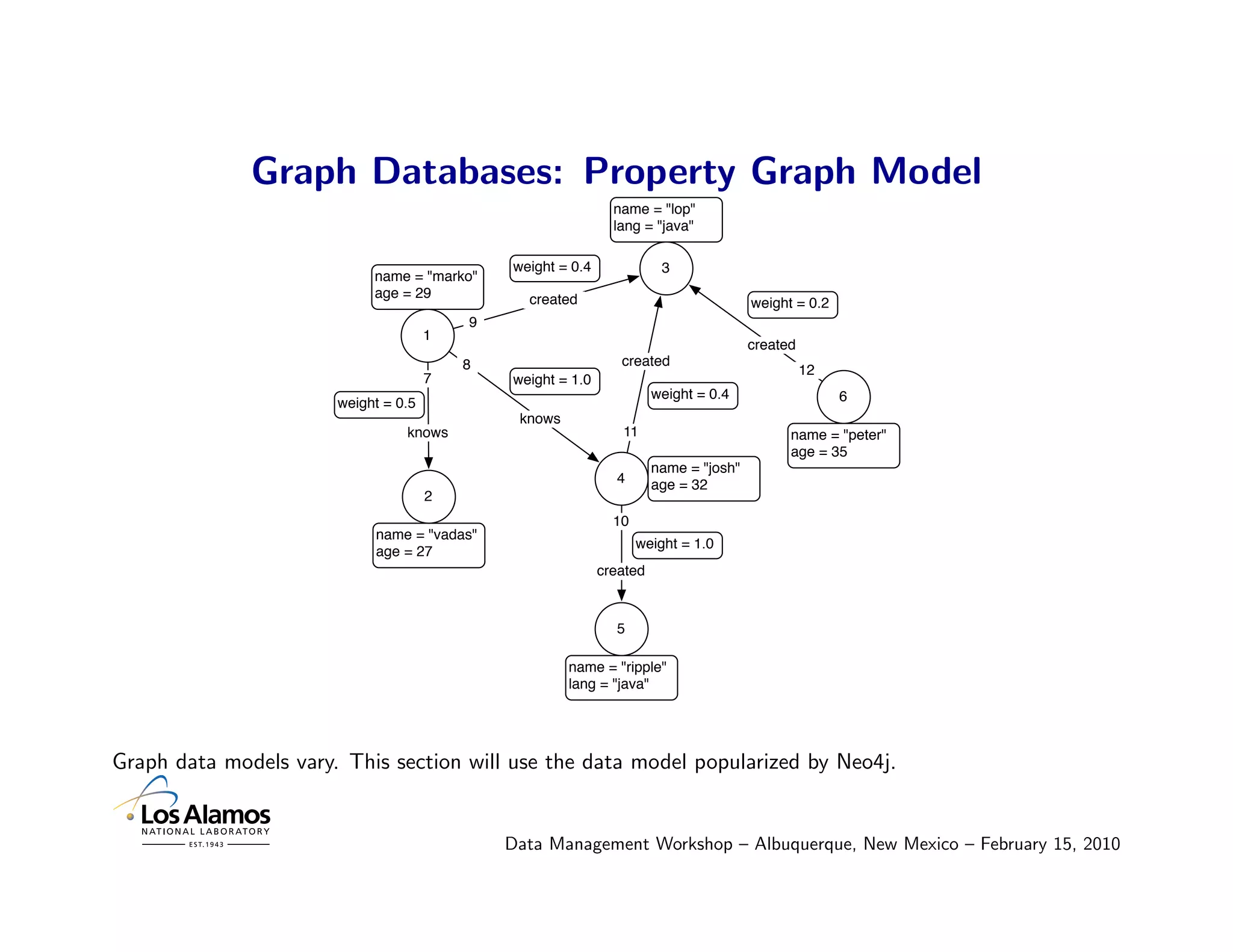

![Graph Databases: Moving Around a Graph in Gremlin
gremlin> $_ := g:key(‘name’,‘marko’)
==>v[1]
gremlin> ./outE
==>e[7][1-knows->2]
==>e[9][1-created->3]
==>e[8][1-knows->4]
gremlin> ./outE/inV
==>v[2]
==>v[3]
==>v[4]
gremlin> ./outE/inV/@name
==>vadas
==>lop
==>josh
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-28-2048.jpg)
![Graph Databases: Inserting Vertices and Edges
• Lets create a Grateful Dead graph.
gremlin> $_g := neo4j:open(‘/tmp/grateful-dead’)
==>neo4jgraph[/tmp/grateful-dead]
gremlin> $v := g:add-v(g:map(‘name’,‘TERRAPIN STATION’))
==>v[0]
gremlin> $u := g:add-v(g:map(‘name’,‘TRUCKIN’))
==>v[1]
gremlin> $e := g:add-e(g:map(‘weight’,1),$v,‘followed_by’,$u)
==>e[2][0-followed_by->1]
You can batch load graph data as well: g:load(‘data/grateful-dead.xml’) using the GraphML
specification [http://graphml.graphdrawing.org/]
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-29-2048.jpg)

![Graph Databases: Finding Vertices
• Find the vertex with the name TERRAPIN STATION.
• Find the name of all the songs that followed TERRAPIN STATION in
concert more than 3 times.
gremlin> $_ := g:key(‘name’,‘TERRAPIN STATION’)
==>v[0]
gremlin> ./outE[@weight > 3]/inV/@name
==>DRUMS
==>MORNING DEW
==>DONT NEED LOVE
==>ESTIMATED PROPHET
==>PLAYING IN THE BAND
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-31-2048.jpg)

![Graph Databases: Processing Graphs
• Find all songs related to TERRAPIN STATION according to concert
behavior.
$e := 1.0
$scores := g:map()
repeat 75
$_ := (./outE[@label=‘followed_by’]/inV)[g:rand-nat()]
if $_ != null()
g:op-value(‘+’,$scores,$_/@name,$e)
$e := $e * 0.85
else
$_ := g:key(‘name, ‘TERRAPIN STATION)
$e := 1.0
end
end
Data Management Workshop – Albuquerque, New Mexico – February 15, 2010](https://image.slidesharecdn.com/datamanagement-2010-100428010914-phpapp02/75/An-Overview-of-Data-Management-Paradigms-Relational-Document-and-Graph-33-2048.jpg)





Here are the key steps: 1. Create vertex for each band member with properties like name, etc 2. Create vertex for each song with properties like title 3. Create edge between band member and song to indicate they performed it 4. Add properties to edges like number of performances This models the relationships between band members and songs they played in a graph structure optimized for traversal.



































































