Downloaded 1,122 times



















































This document discusses the key characteristics of computer memory, including location, capacity, unit of transfer, access methods, performance, physical type, physical characteristics, and organization. It covers different types of memory like CPU registers, main memory, cache, disk, and tape. The different access methods like sequential, direct, random, and associative access are explained. The memory hierarchy and performance aspects like access time, memory cycle time, and transfer rate are defined. Factors like cache size, mapping function, replacement algorithm, write policy, block size that impact cache performance are also summarized.
Defining characteristics of memory including location, capacity, transfer unit, access methods, performance, and organizational structure.
Categorizes memory locations into CPU, internal, and external types to understand where data is physically stored.
Discusses memory capacity measured in word size and byte count, essential for determining data storage limits.
Describes internal and external units of transfer, governed by data bus width and addressable units like words and clusters.
Explains sequential, direct, random, and associative access methods to illustrate how data retrieval works in memory.
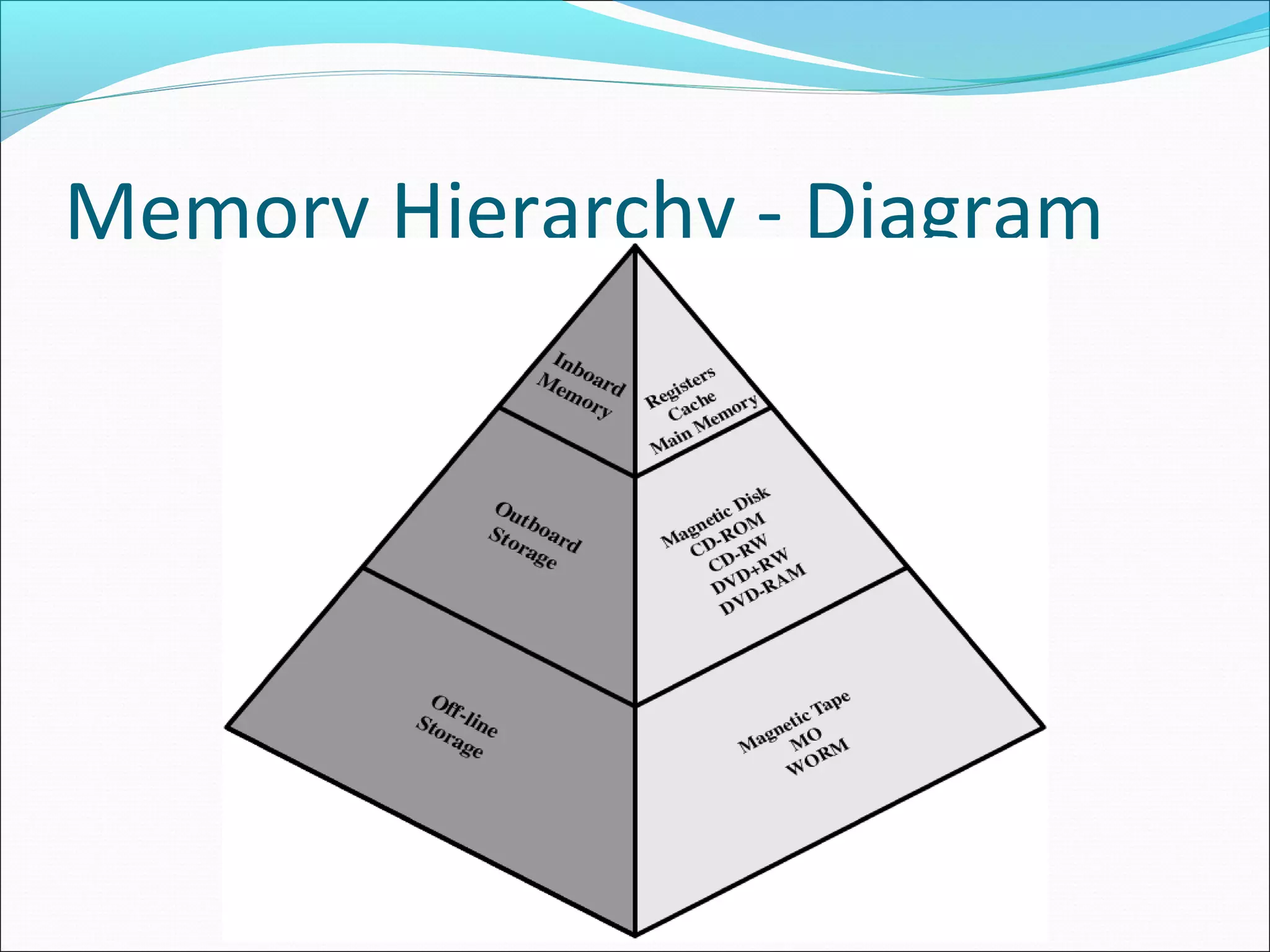
Presents the memory hierarchy from registers and caches to external memory, visualizing structure and organization.
Key performance indicators like access time, memory cycle time, and transfer rate that affect overall system speed.
Identifies different types of physical memory (semiconductor, magnetic, optical) and discusses physical characteristics such as decay and volatility.
Explores physical arrangement of bits into words and the practical implications of memory organization.
Analyzes cost, capacity, and speed considerations that impact memory choices and system performance.
Lists the hierarchical memory levels from registers to tape, outlining progression of storage type and speed.
Discusses the potential of using static RAM for fast computing, addressing the cost implications and questions about caching.
Introduces the concept of locality of reference, emphasizing clustered memory references during program execution.
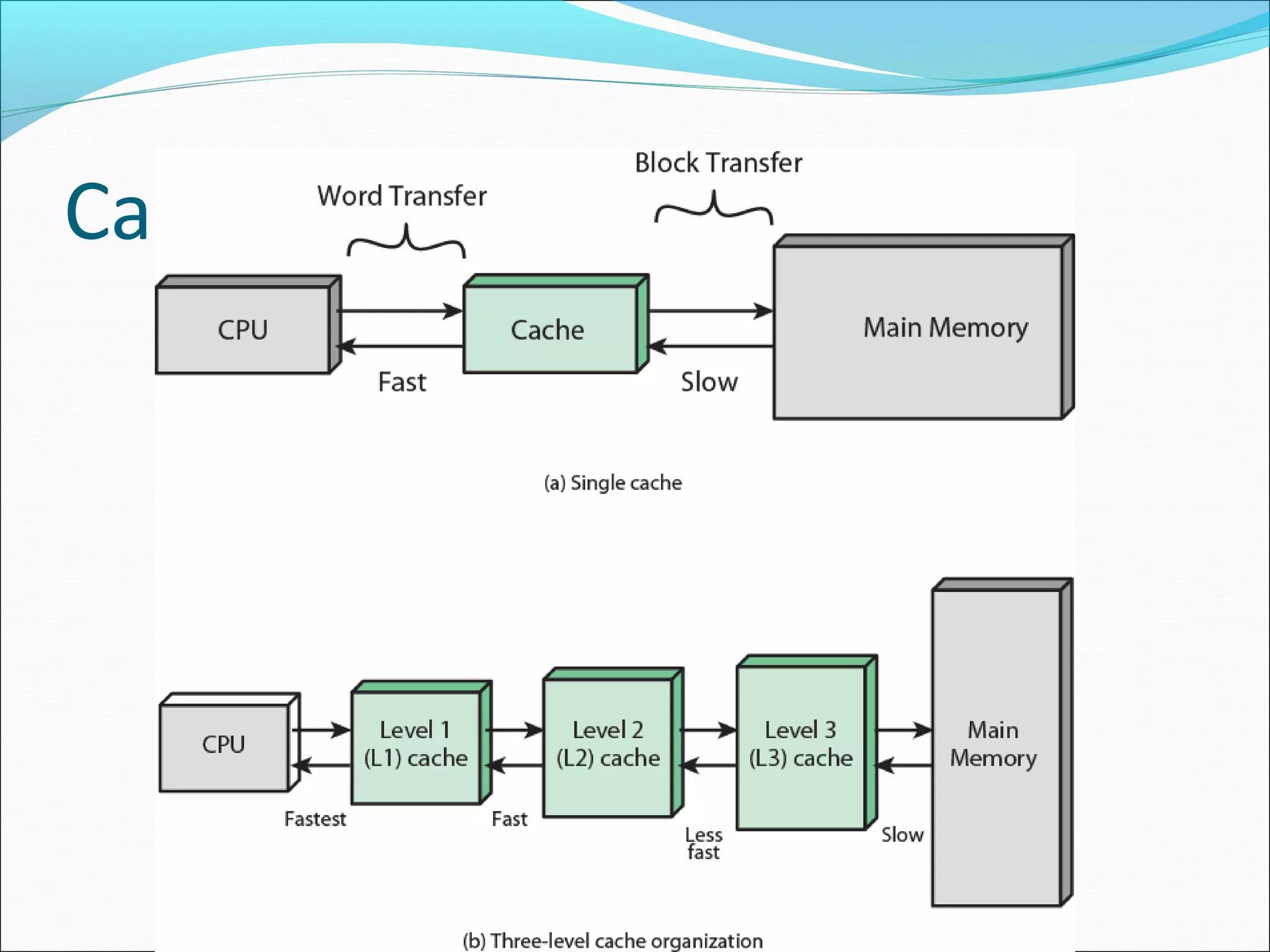
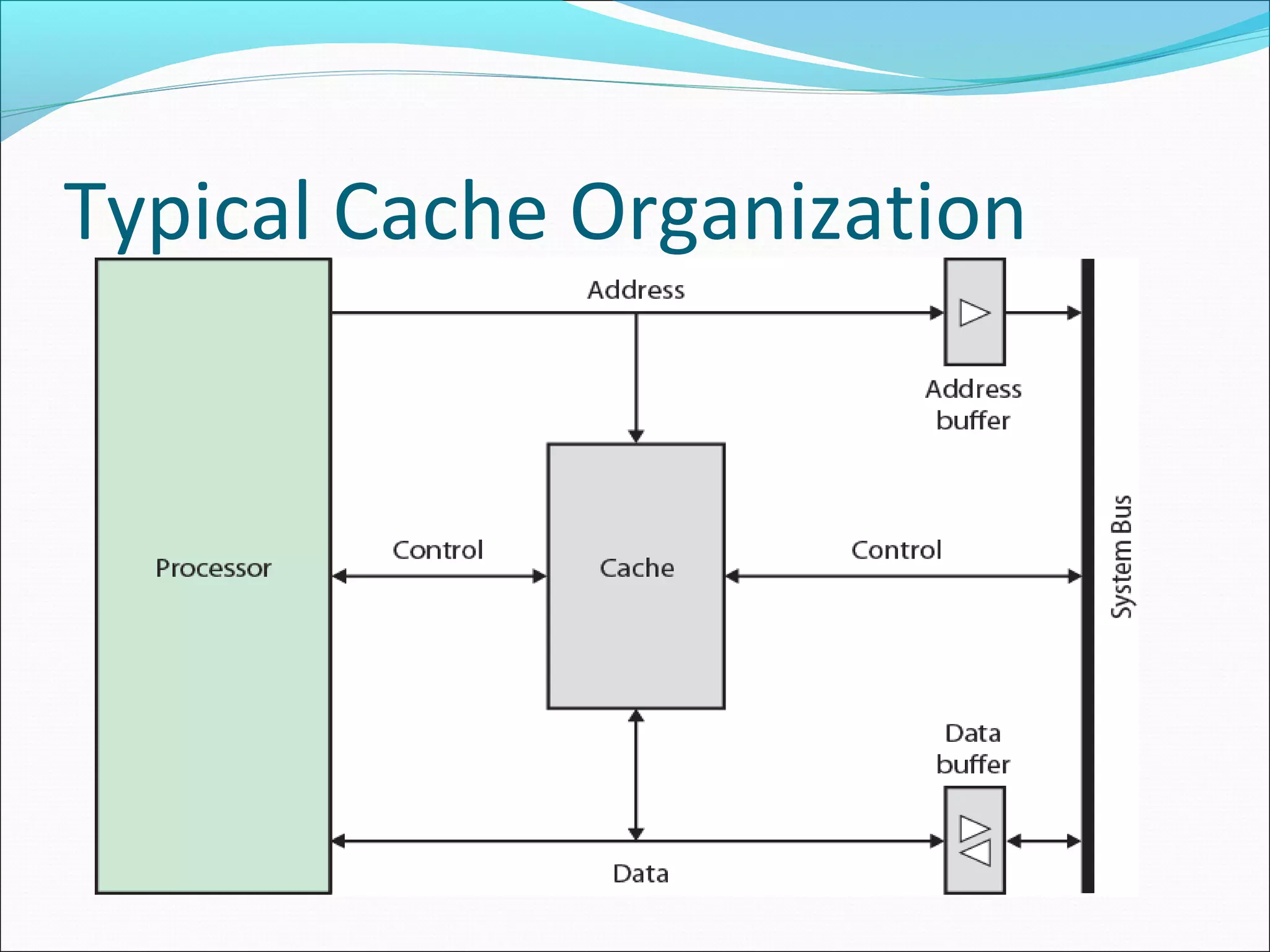
Describes the purpose and position of cache memory in the system architecture as a bridge between CPU and main memory.
Illustrates the structural relationship between cache and main memory, emphasizing their interconnected roles.
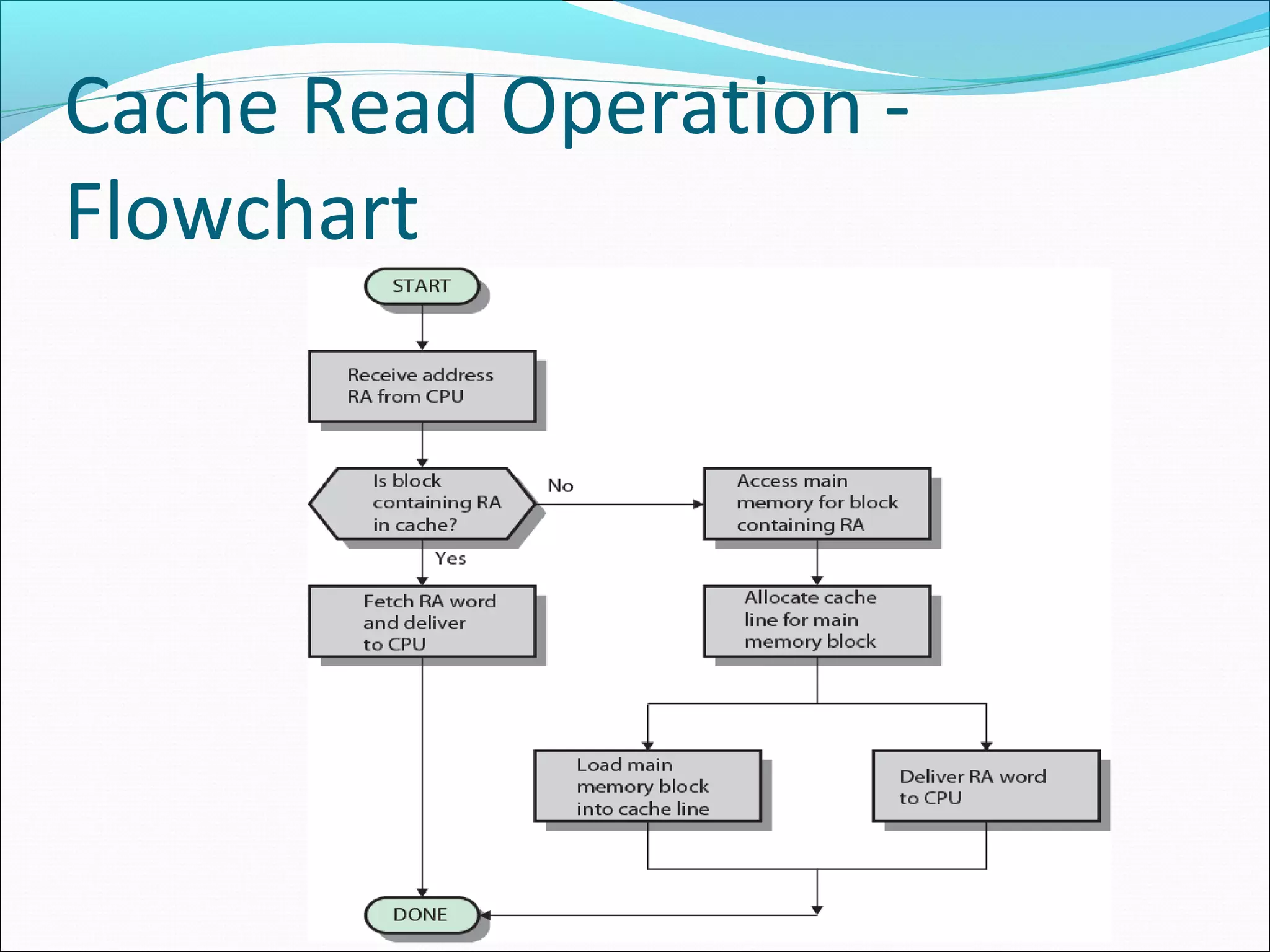
Details the process of cache memory operation, including how data is requested and accessed from cache.
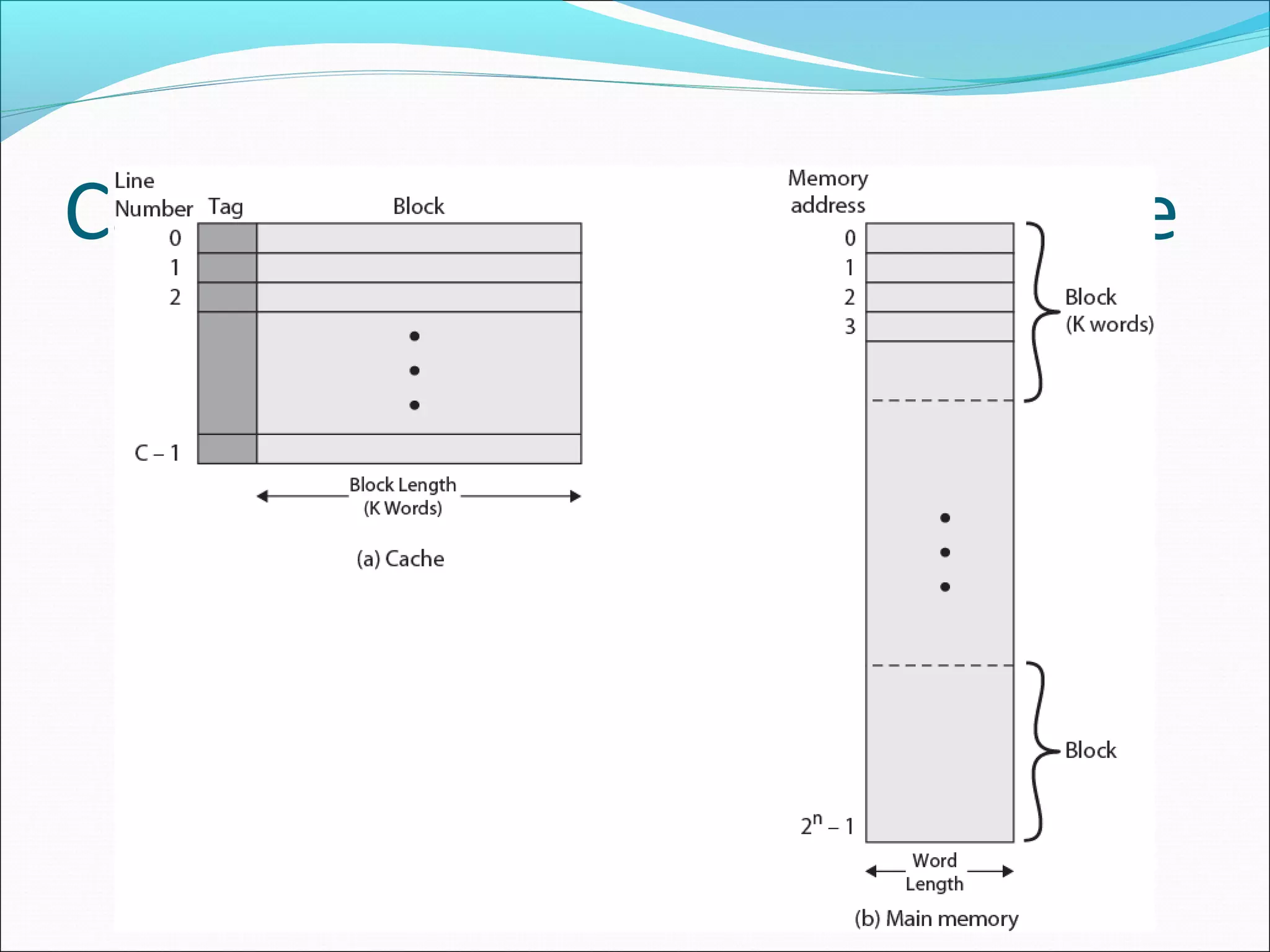
Discusses design elements of cache such as addressing, size, mapping function, and replacement algorithms vital for efficiency.
Analyzes impacts of cache size on speed and cost, highlighting trade-offs in system design.
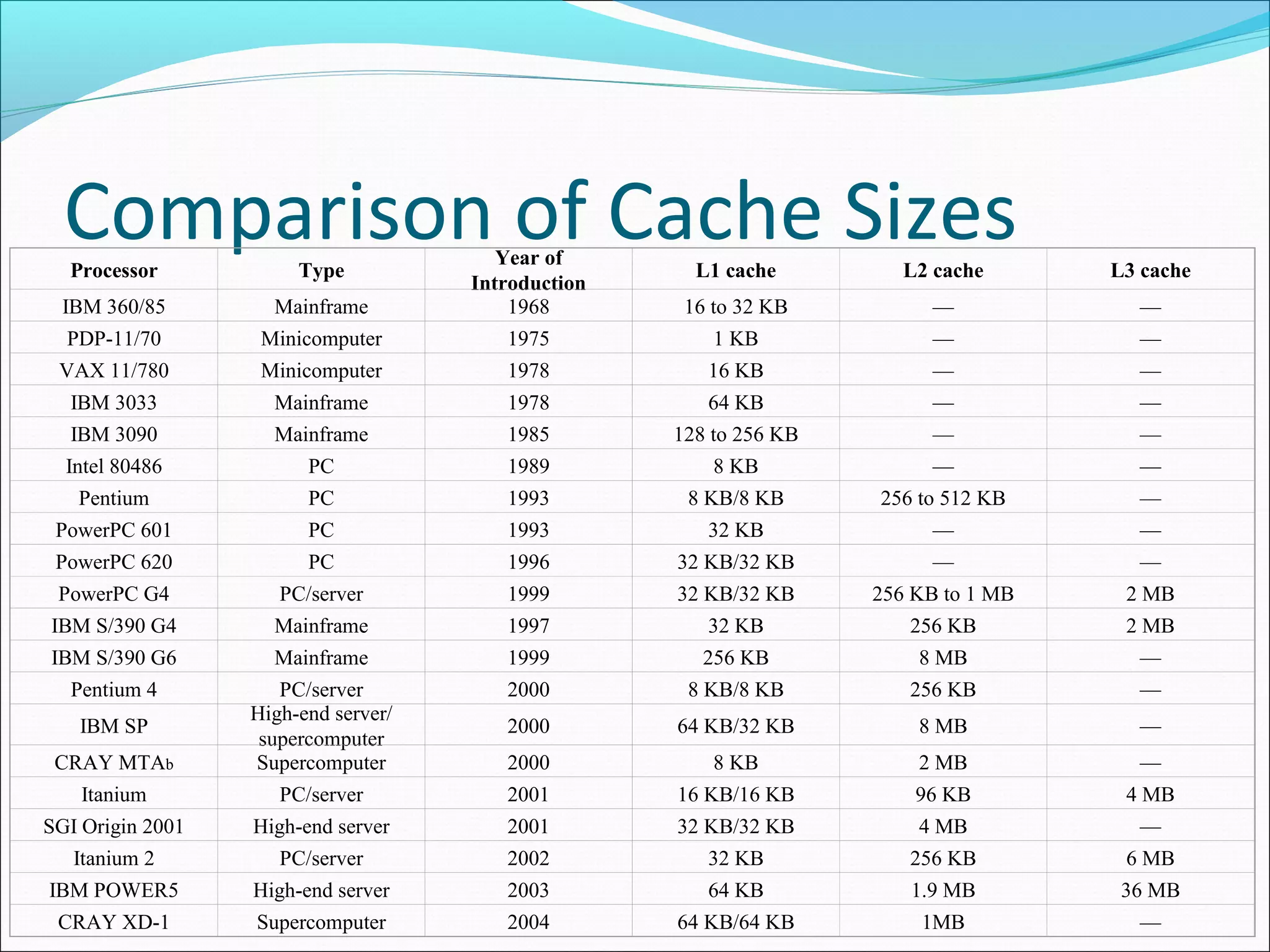
Presents typical cache organization and compares cache size across various computing architectures over time.
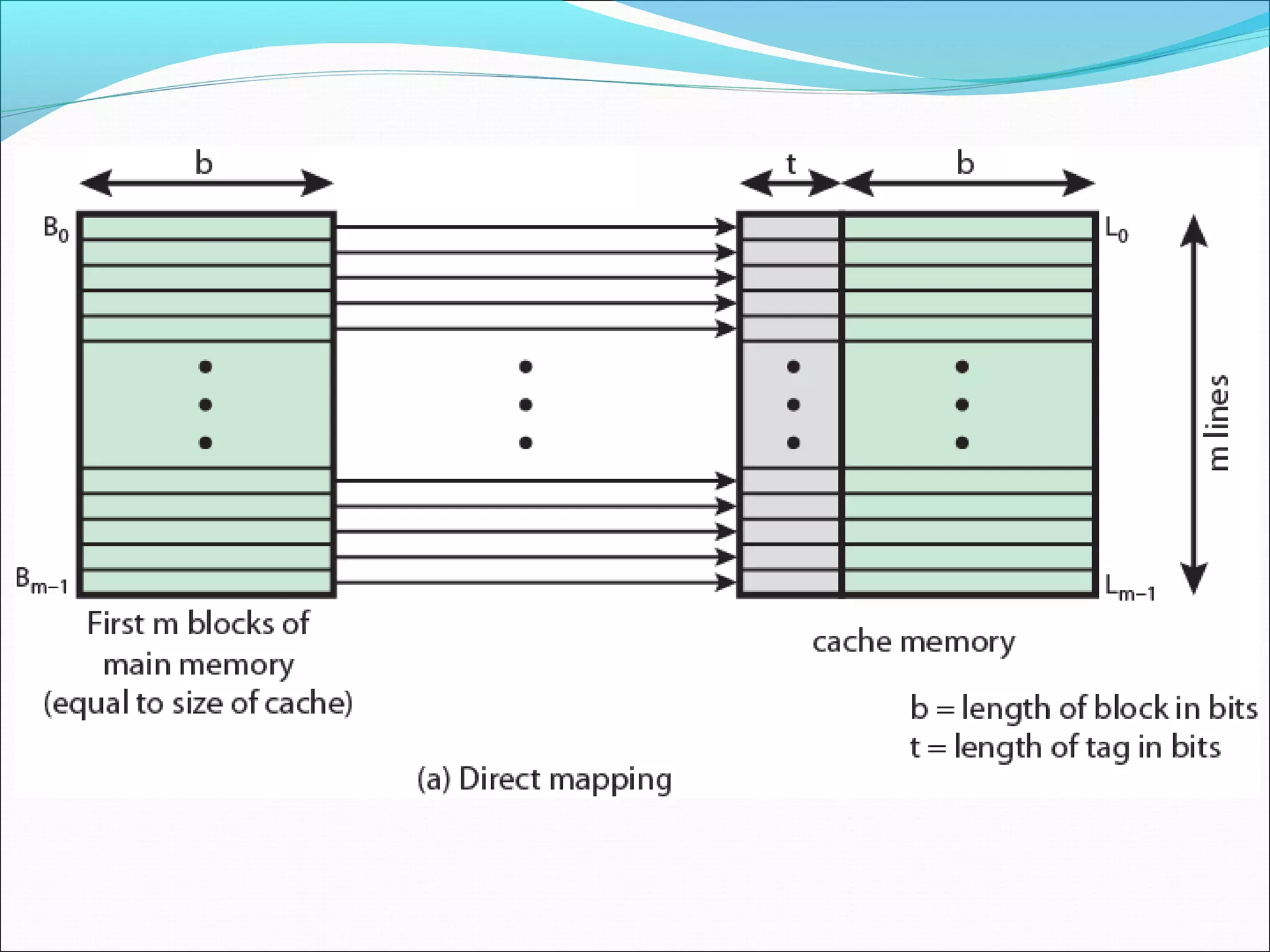
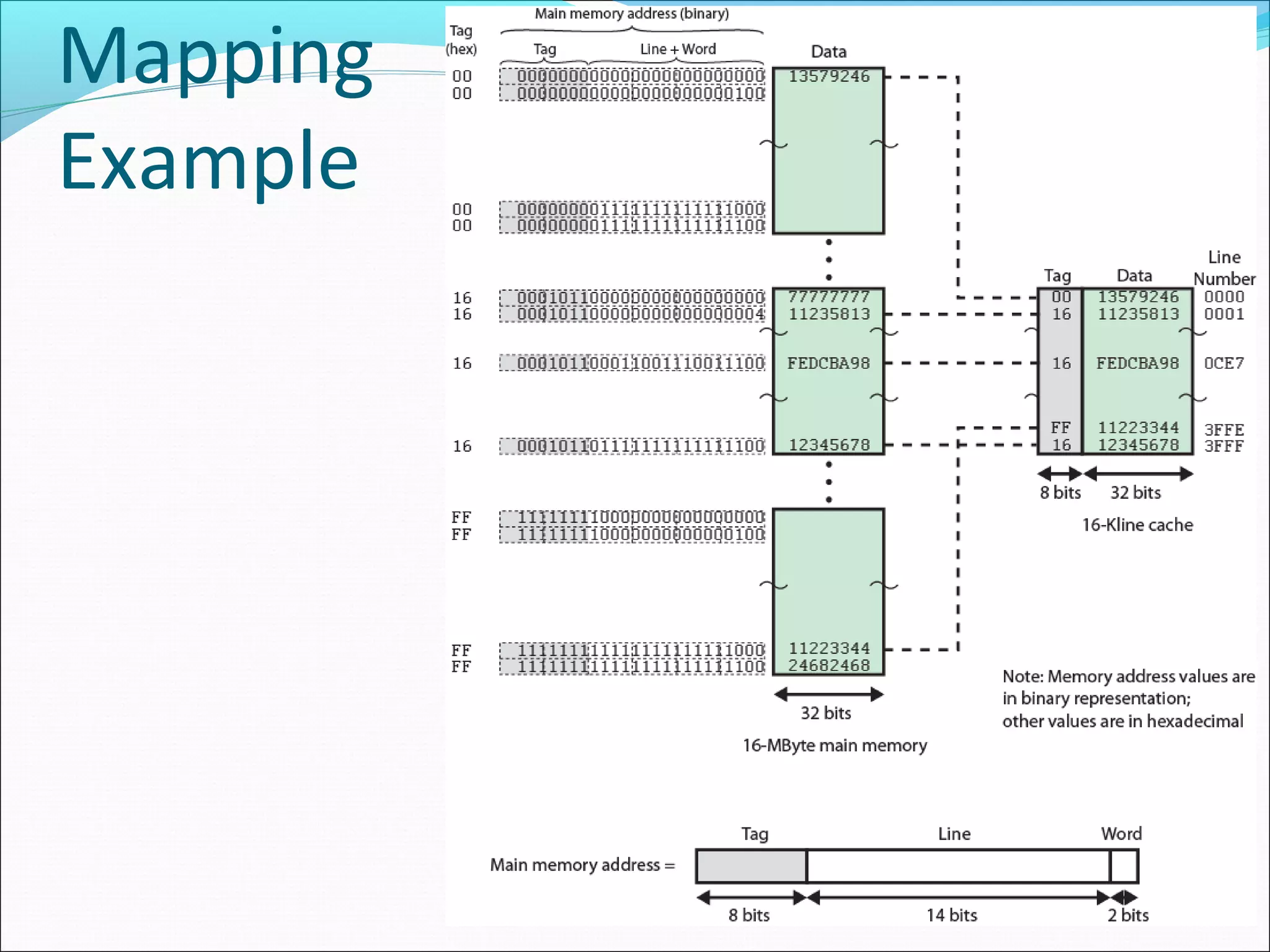
Discusses mapping functions determining how blocks of main memory correspond to cache lines in a structured manner.
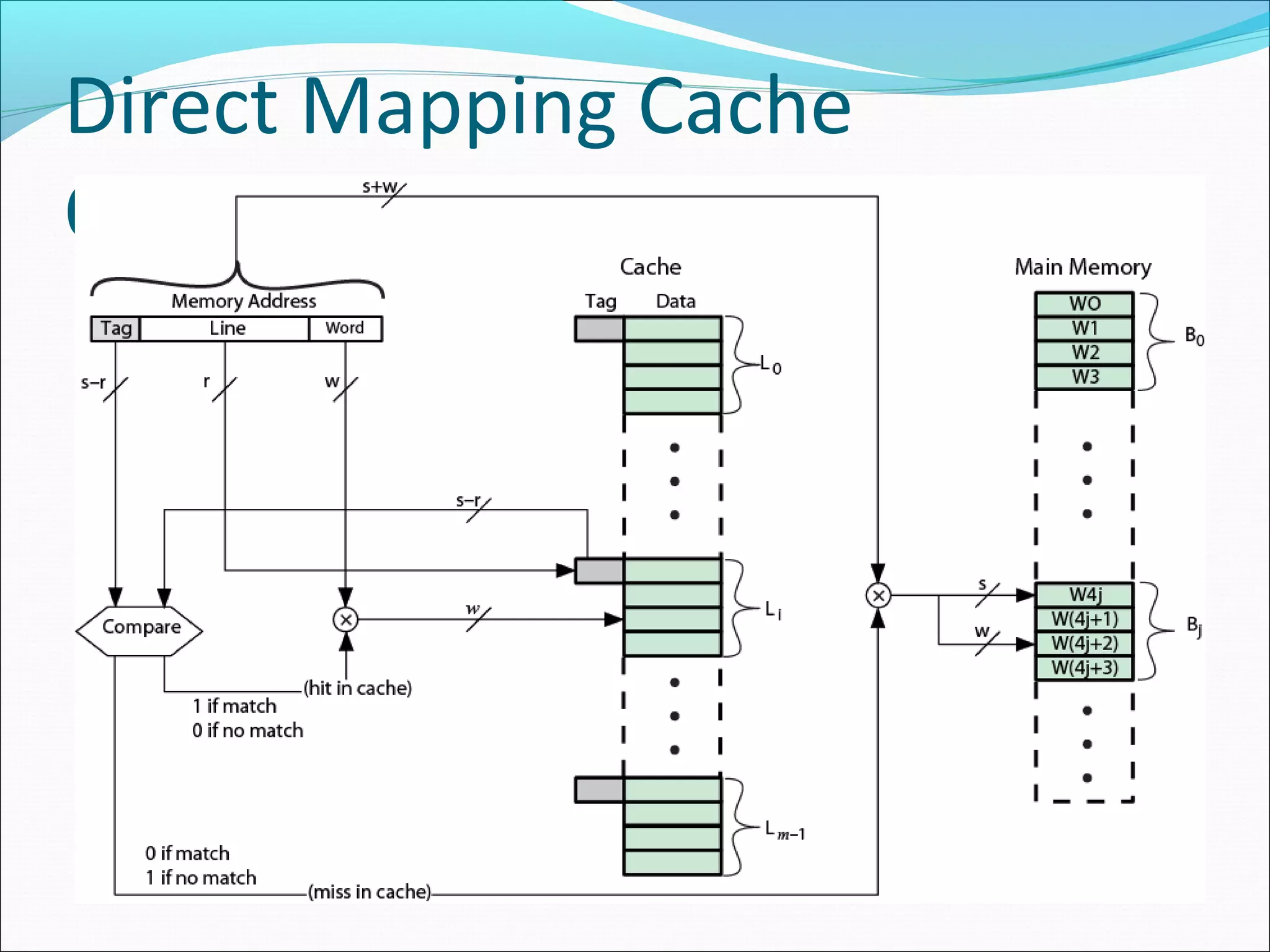
Explains the concept of direct mapping, how addresses are structured, and the implications for cache organization.
Outlines the advantages and disadvantages of direct mapping in caching and its performance implications.
Describes the victim cache concept for reducing miss penalties and improving efficiency between cache levels.
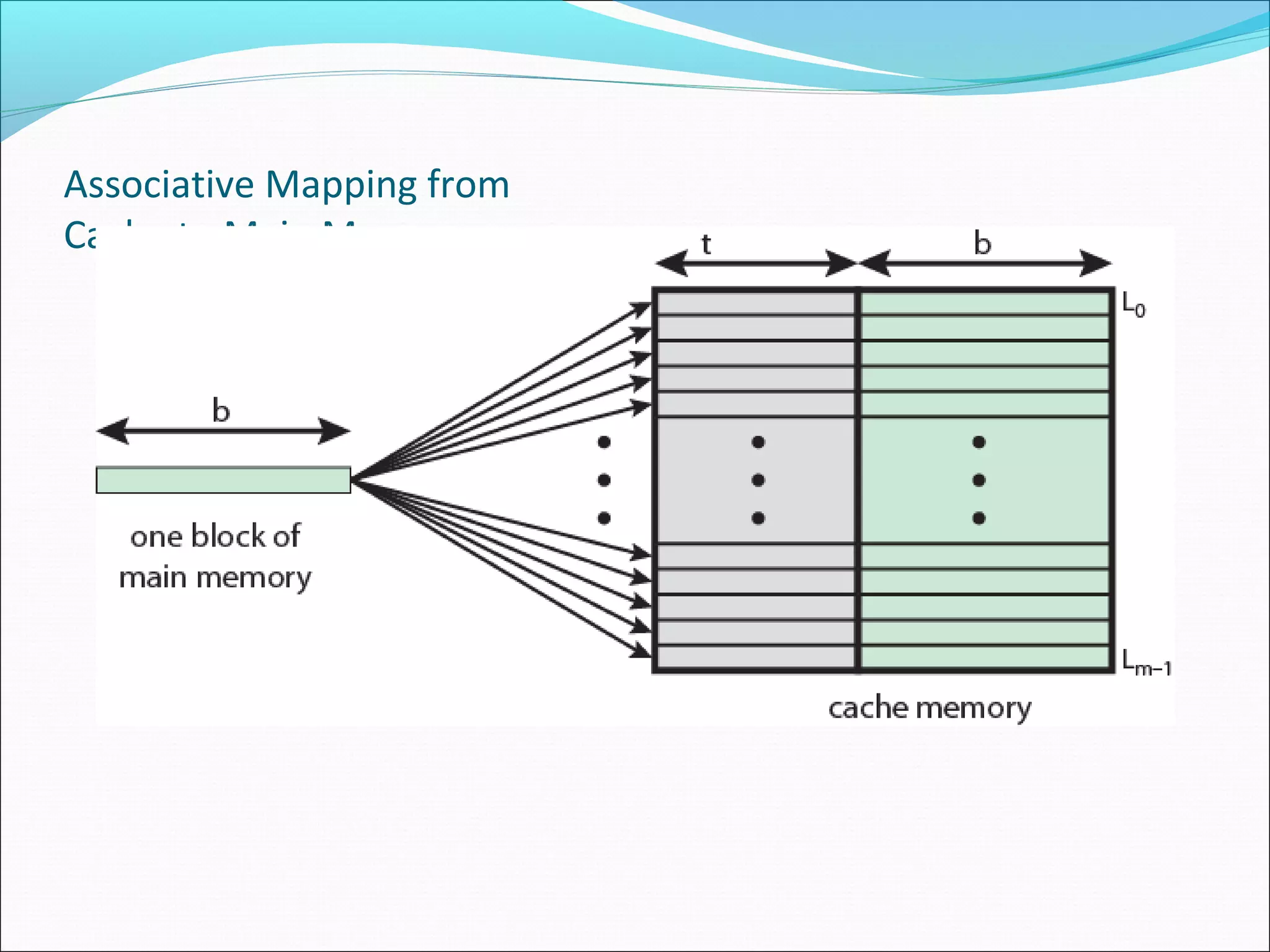
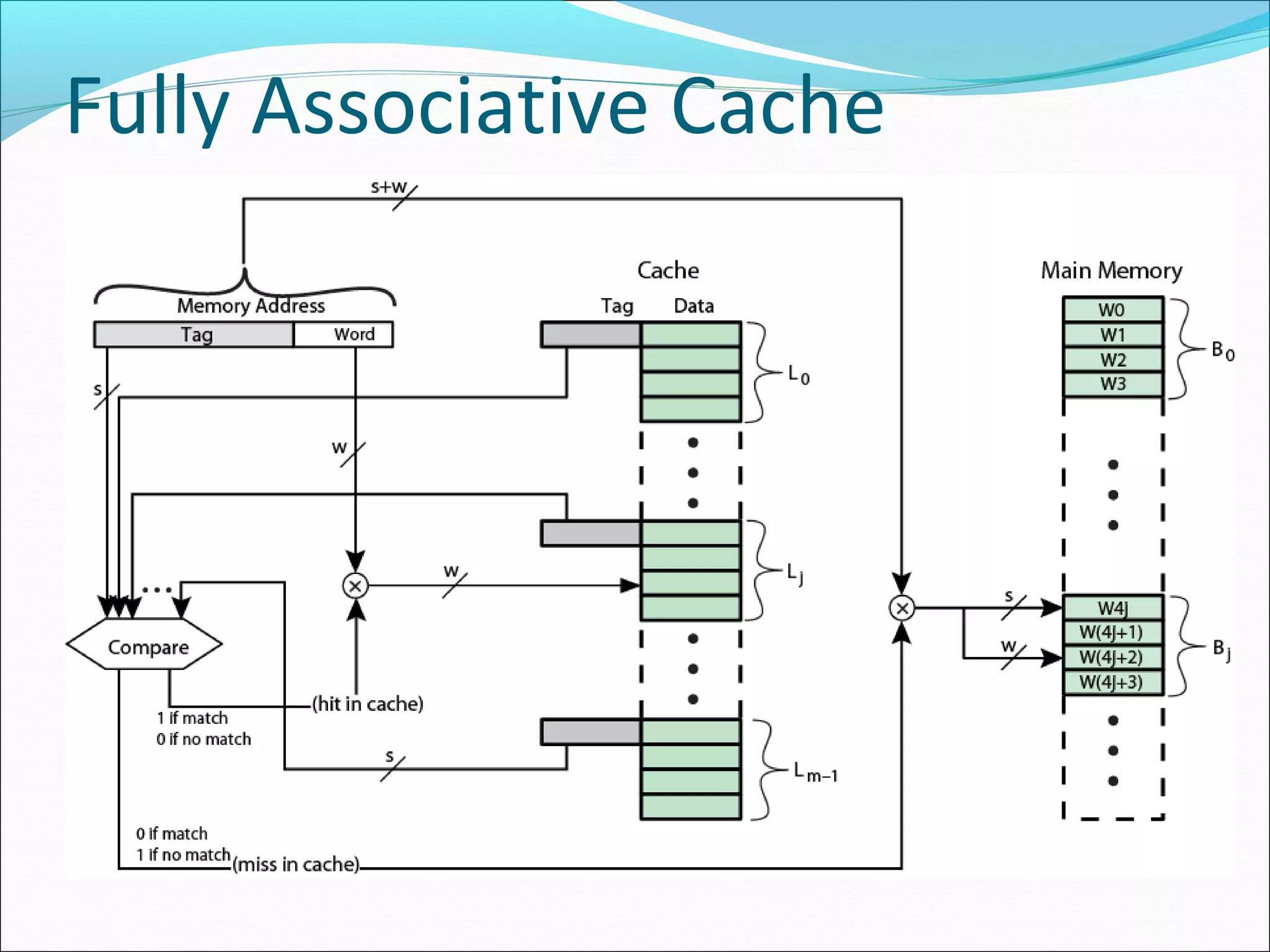
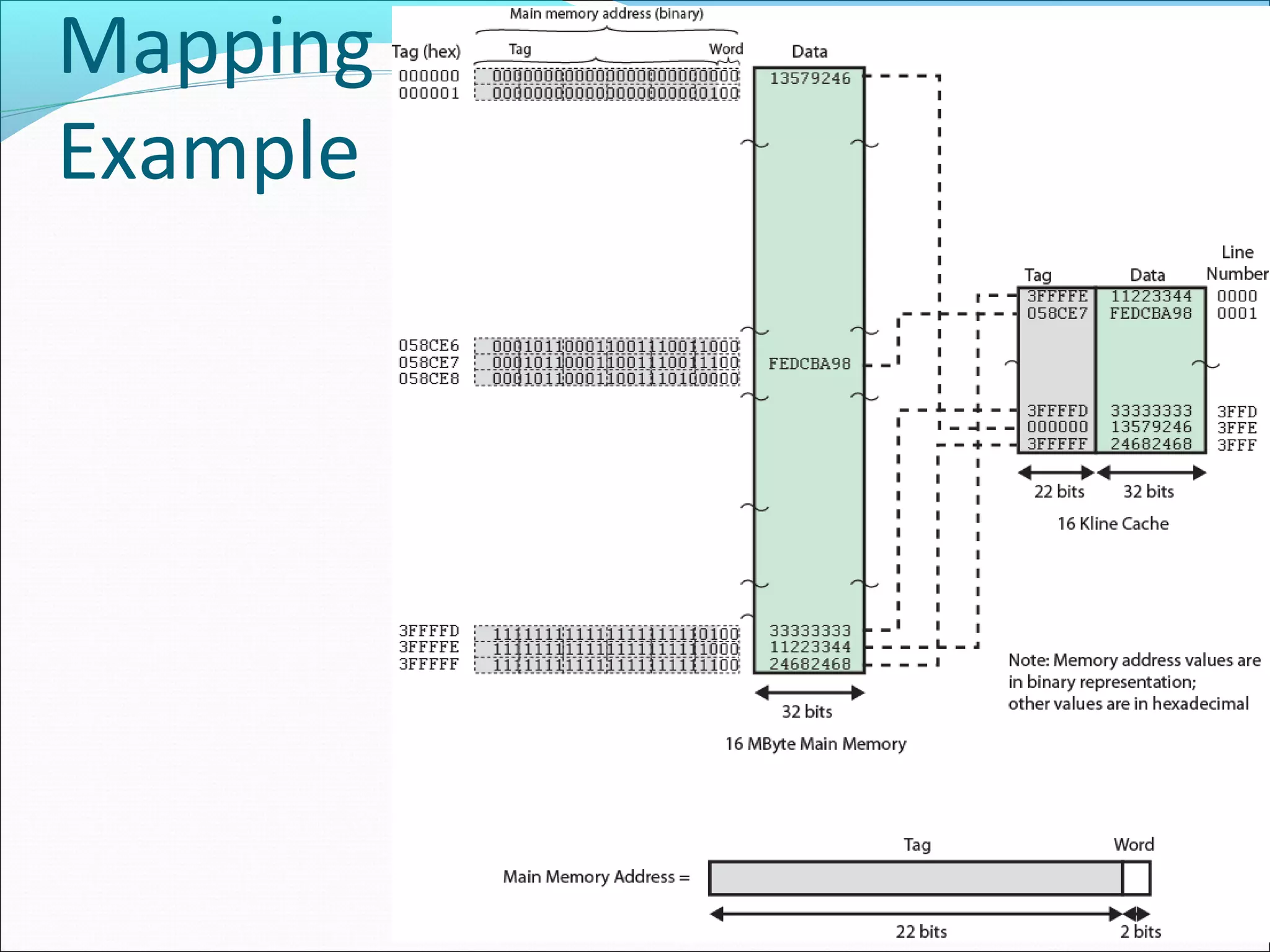
Explains associative mapping, focusing on how any memory block can go into any cache line and its influence on cache performance.
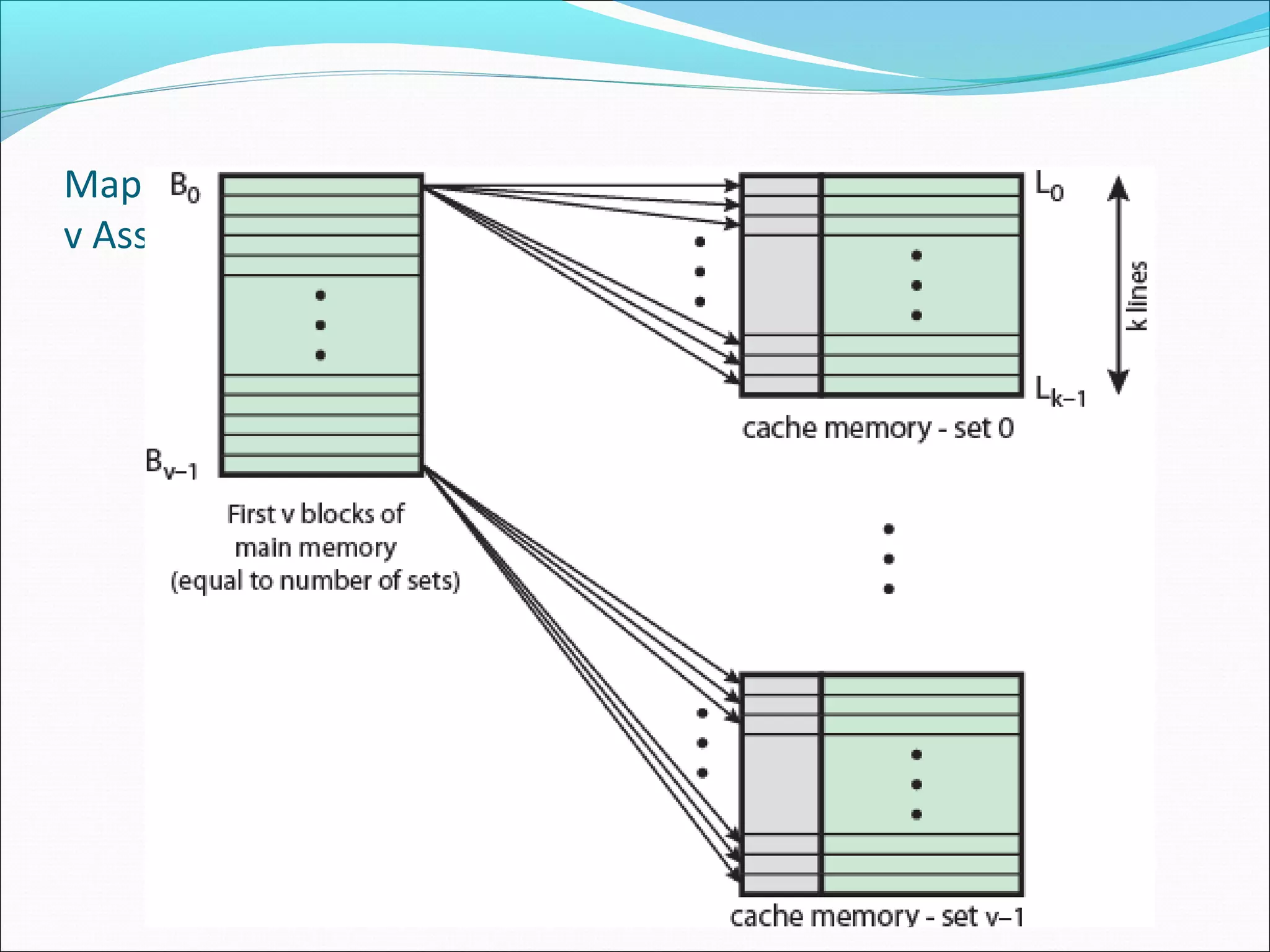
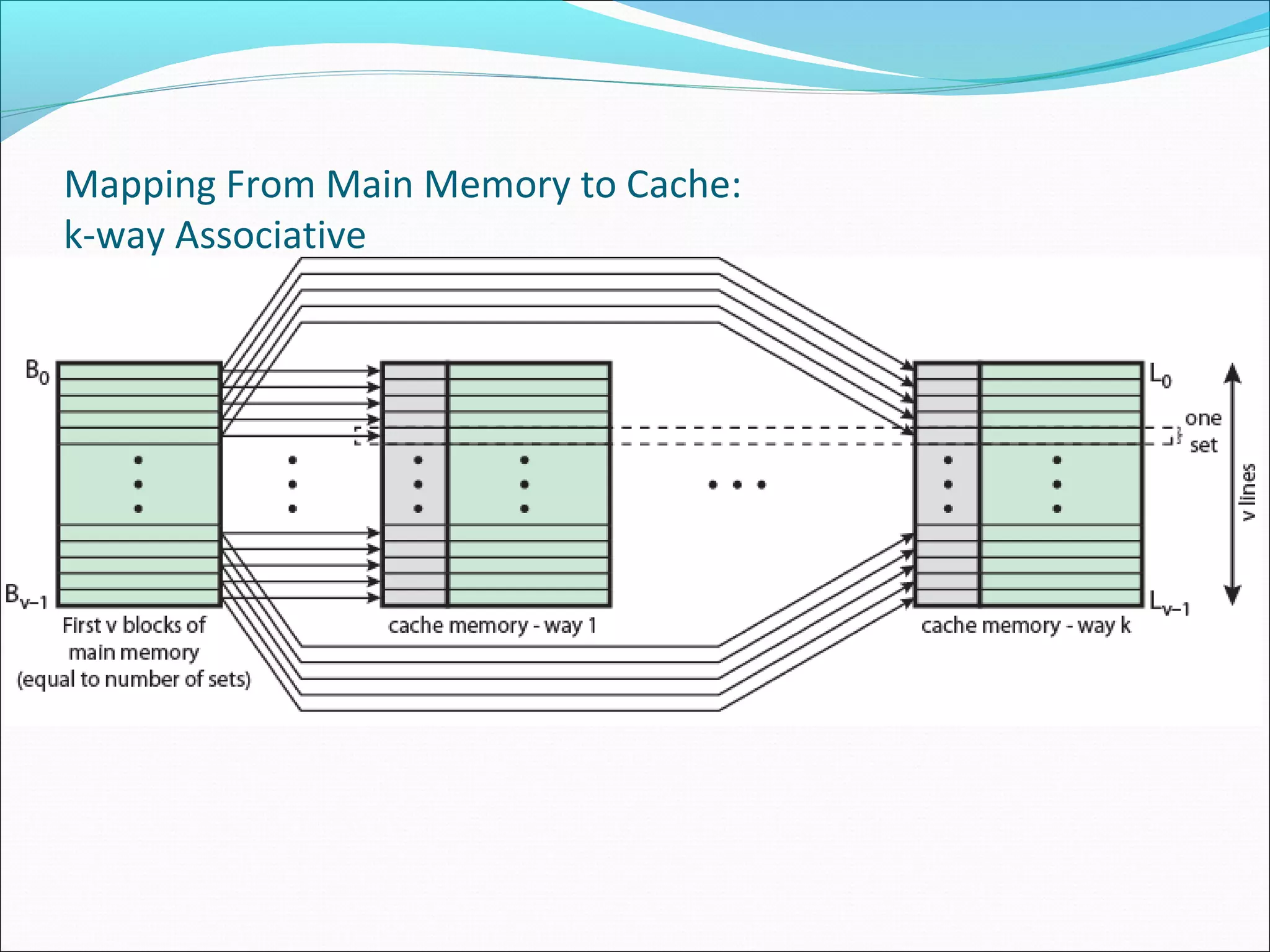
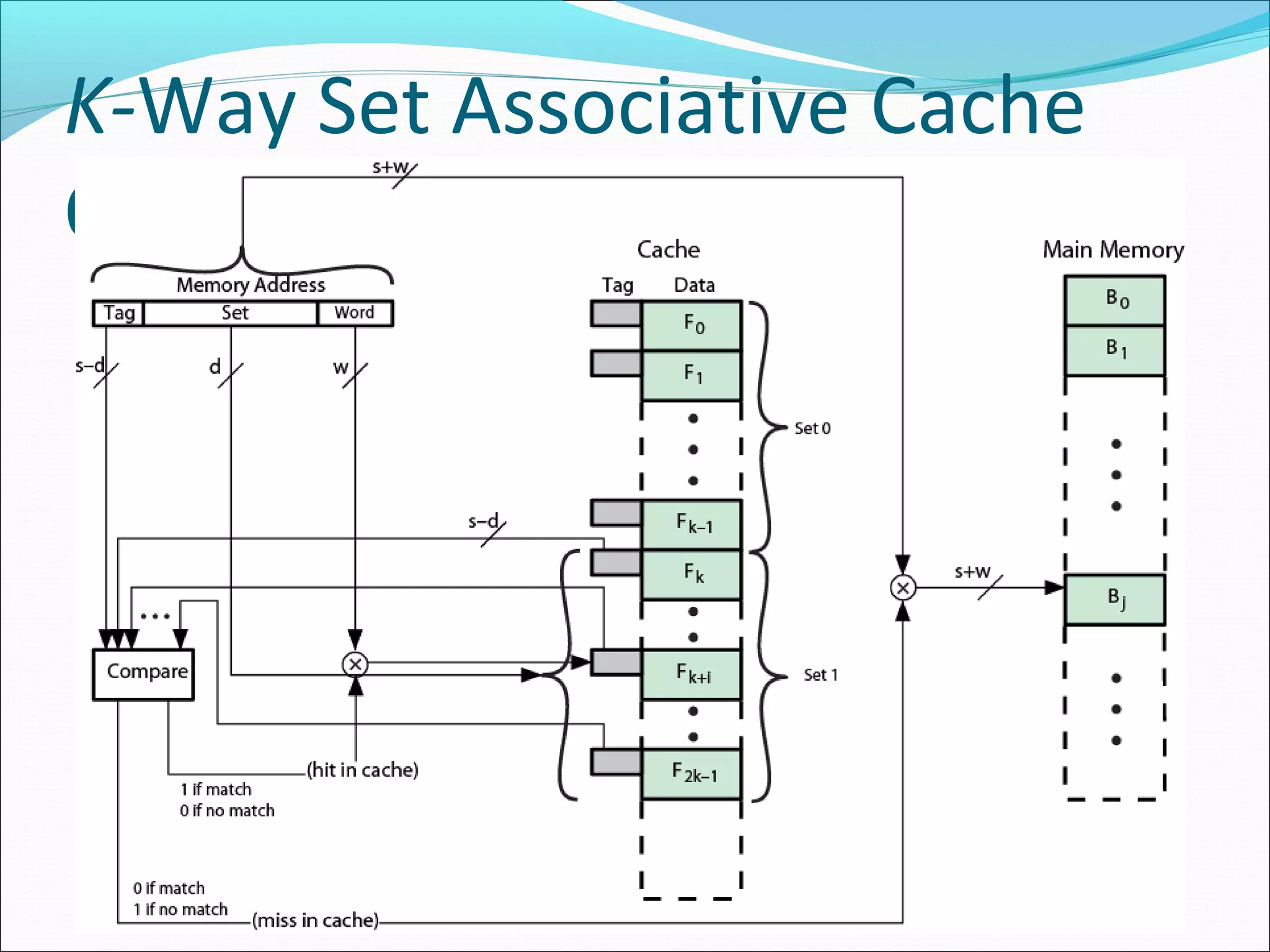
Examines set associative mapping, illustrating how blocks are organized within sets for improved efficiency.
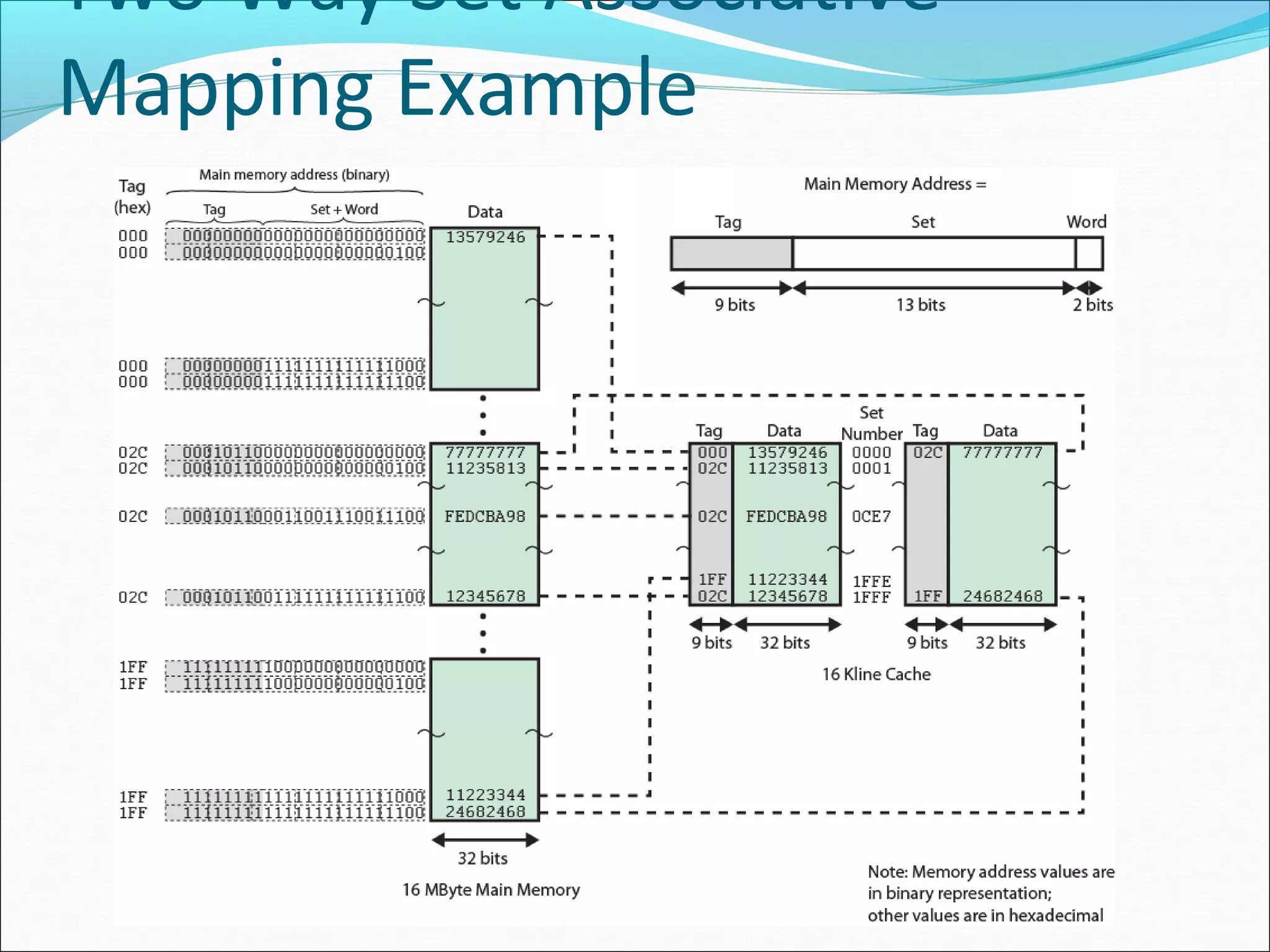
Provides examples of set associative mapping, detailing address structure and performance for differing configurations.
Compares performance metrics between direct and set associative caches, revealing impacts of cache size and complexity.
Discusses various cache replacement algorithms including LRU, FIFO, and random, focusing on speed and efficiency.
Examines write policies like write-through and write-back, discussing implications on data integrity and performance.
Highlights the significance of multilevel caches, emphasizing their speed advantages and integration into modern architectures.
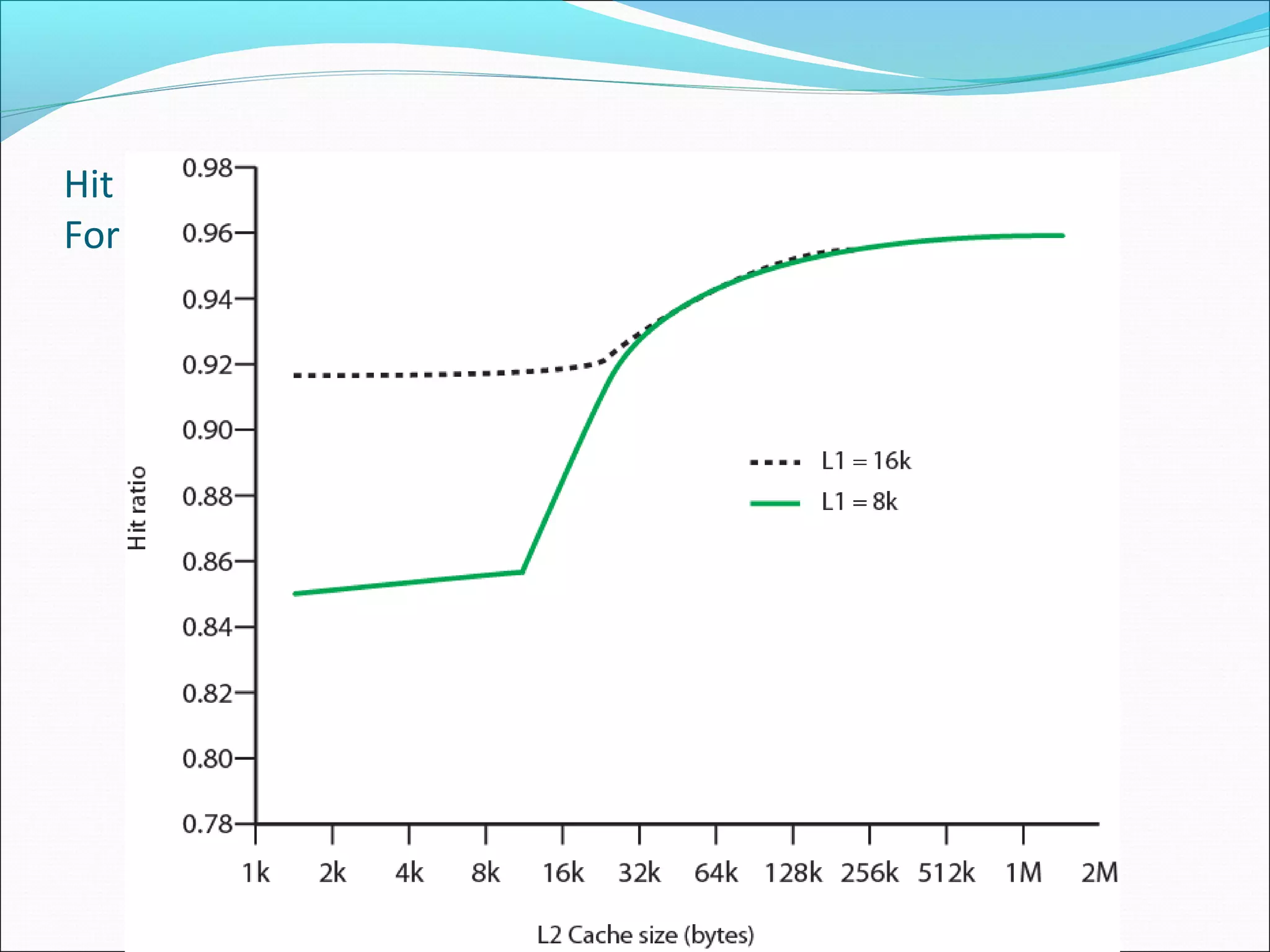
Analyzes hit ratios for different cache sizes, affecting overall system performance in retrieving data.
Evaluates unified and split cache configurations, discussing advantages for instruction and data management in processors.
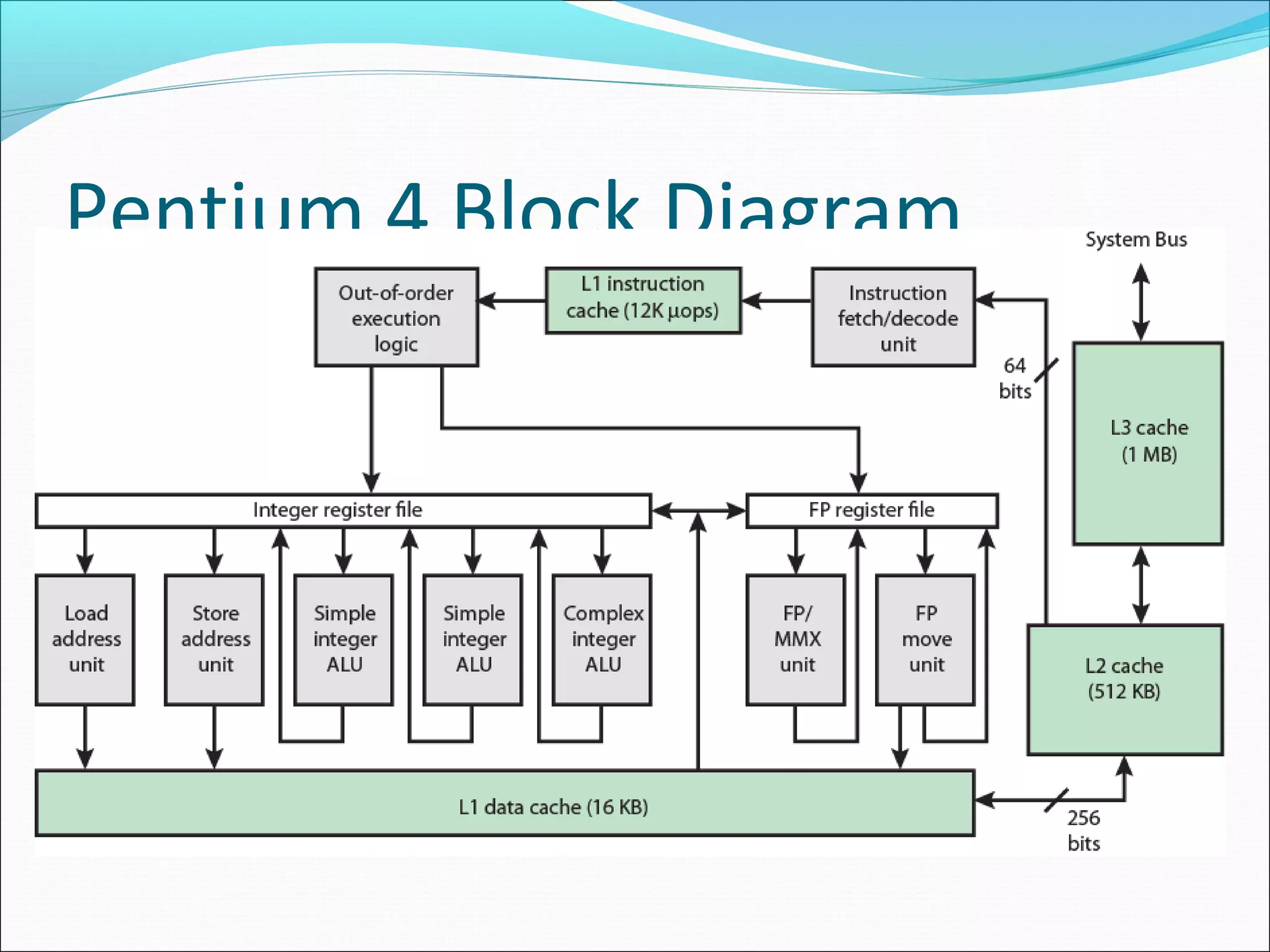
Details the cache structure in Pentium 4, describing critical components and memory organization.
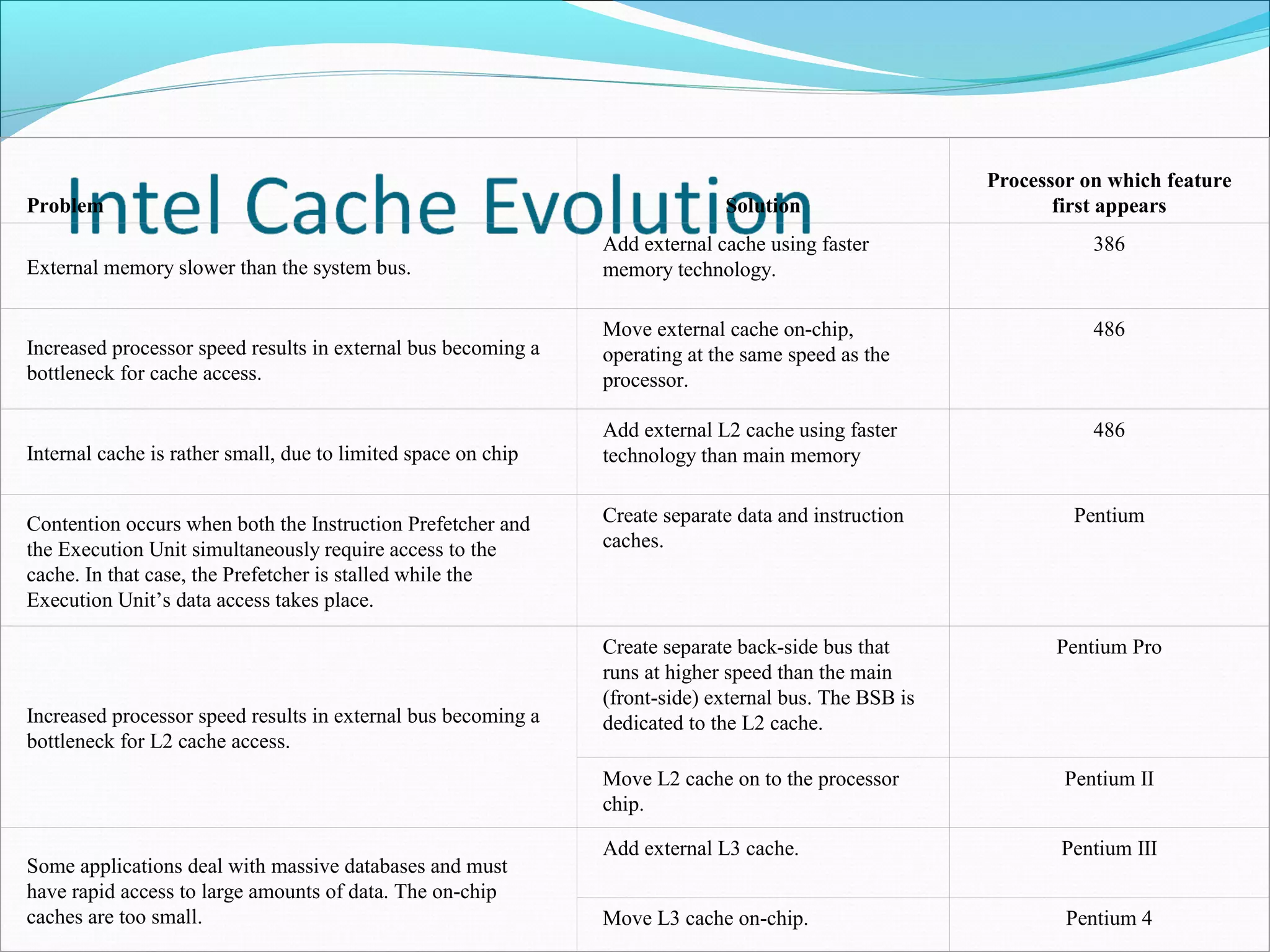
Summarizes historical evolution of processor cache technologies, addressing changes and solutions in the architecture.
Describes the architectural design of Pentium 4, focusing on instruction fetching, execution units, and cache interactions.
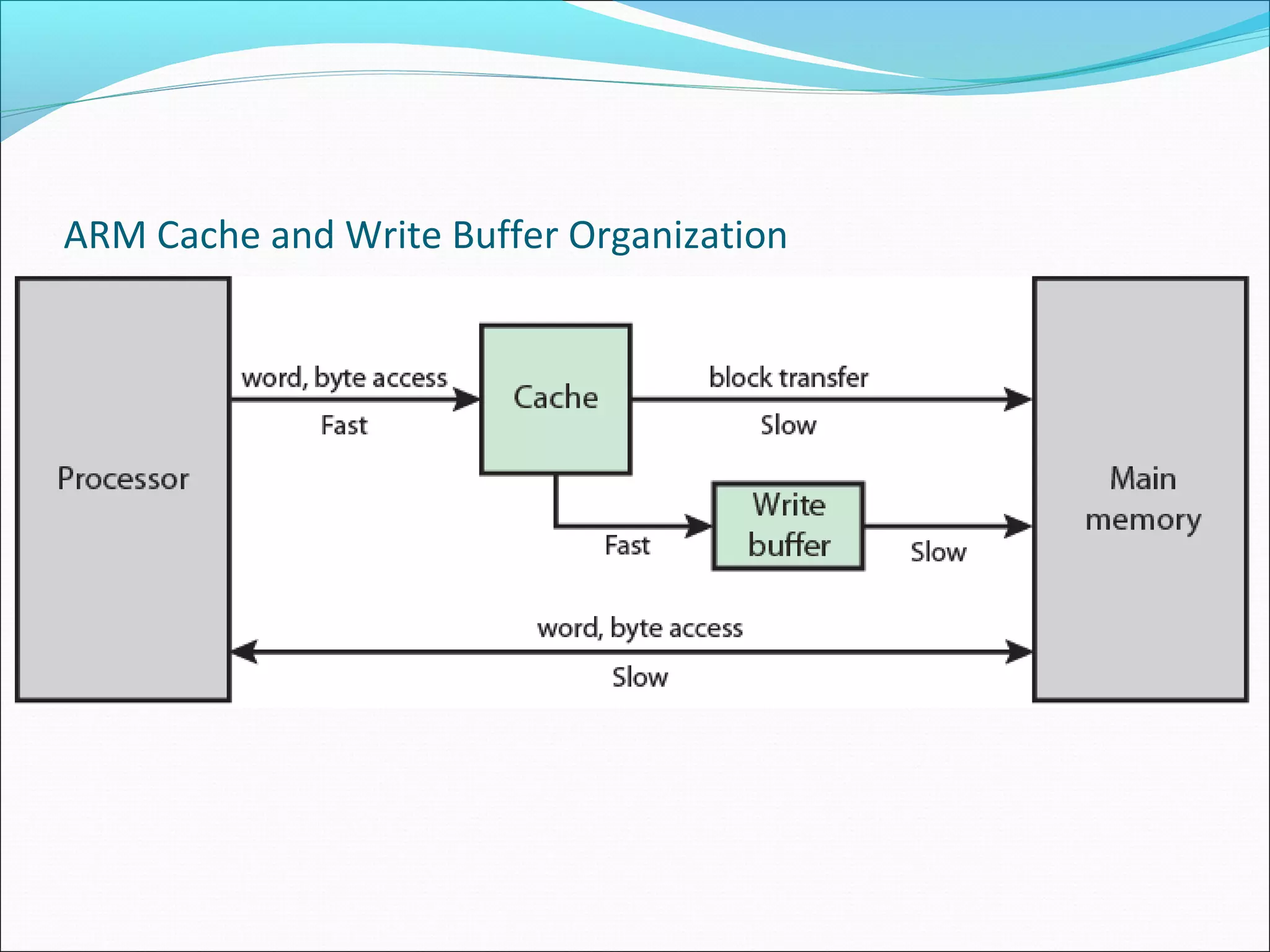
Details ARM cache organization and its efficiency via a FIFO write buffer between cache and main memory.
Lists various online sources for comprehensive information on cache technology, including manufacturer websites.























































































