Rand Fishkin's slide deck from SMX Advanced Seattle 2011 showing several interesting datapoints from the 2011 Search Engine Rankings Factors survey and correlation data on SEOmoz.
Interesting Findings fromthe2011 Search Ranking FactorsThe full data is now online at http://bit.ly/rankfactors2011This deck is available online at http://bit.ly/randsmxdeckPresented for SMX Advanced, SeattleRand Fishkin, SEOmoz CEO, June 2011
2.
Understanding, Interpreting &Using Survey Opinion DataEverybody’s wrong sometimes, but there’s a lot we can learn from the aggregation of opinions
3.
#1: Opinions areNot Fact(these are smart people, but they can’t know everything about Google’s rankings)#2: Not Everyone Agrees(standard deviation can help show us the degree of consensus)#3: We Had 132 Contributors(but this group could be biased as they were editorially selected via a nomination process)http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.htmlMany thanks to all who contributed their time to take the survey!
4.
Understanding, Interpreting &Using Correlation DataThis is powerful, useful information, but with that power comes responsibility to present it accurately
5.
Methodology10,271 Keywords, pulledfrom Google AdWords US Suggestions(all SERPs were pulled from Google in March 2011, after the Panda/Farmer update)Top 30 Results Retrieved for Each Keyword(excluding all vertical/non-standard results)Correlations are for Pages/Sites that Appear Higher in the Top 30(we use the mean of Spearman’s correlation coefficient across all SERPs)Results Where <2 URLs Contain a Given Feature Are Excluded(this also holds true for results where all the URLs contain the same values for a feature)More details, including complete documentation and the raw dataset is now available at http://www.seomoz.org/article/search-ranking-factorshttp:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
6.
Correlation & DolphinsDolphinswho swim at the front of the pod tend to have larger dorsal fins, more muscular tails and more damage on their flippers. The first two might have a causal link, but the damaged flippers is likely a result of swimming at the front (i.e. having damaged flippers doesn’t make a dolphin a better front-of-the-pod-swimmer). Likewise, with ranking correlations, there’s probably many features that are correlated but not necessarily the cause of the positive/negative rankings.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
7.
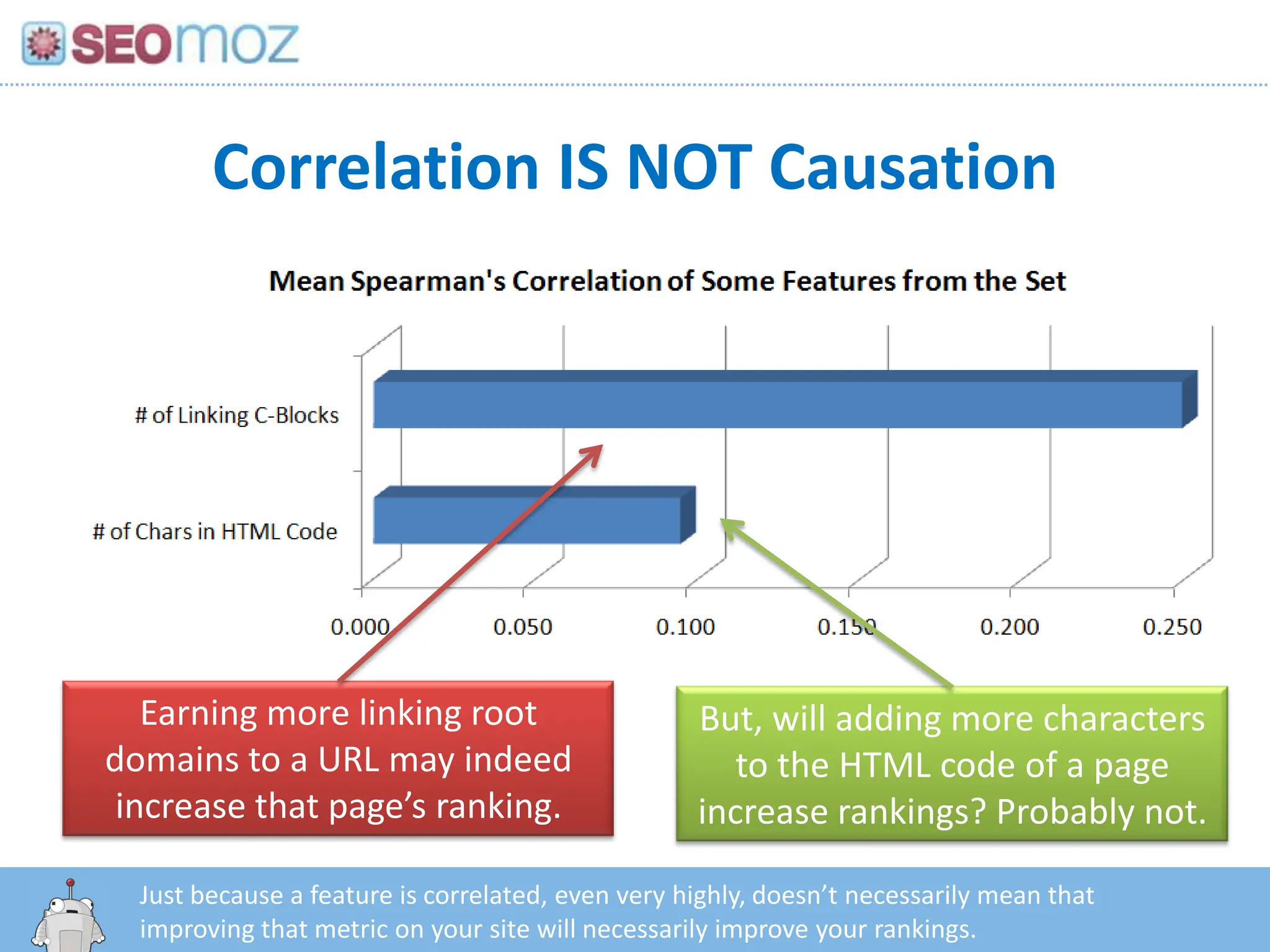
Correlation IS NOTCausationEarning more linking root domains to a URL may indeed increase that page’s ranking.But, will adding more characters to the HTML code of a page increase rankings? Probably not.Just because a feature is correlated, even very highly, doesn’t necessarily mean that improving that metric on your site will necessarily improve your rankings.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
8.
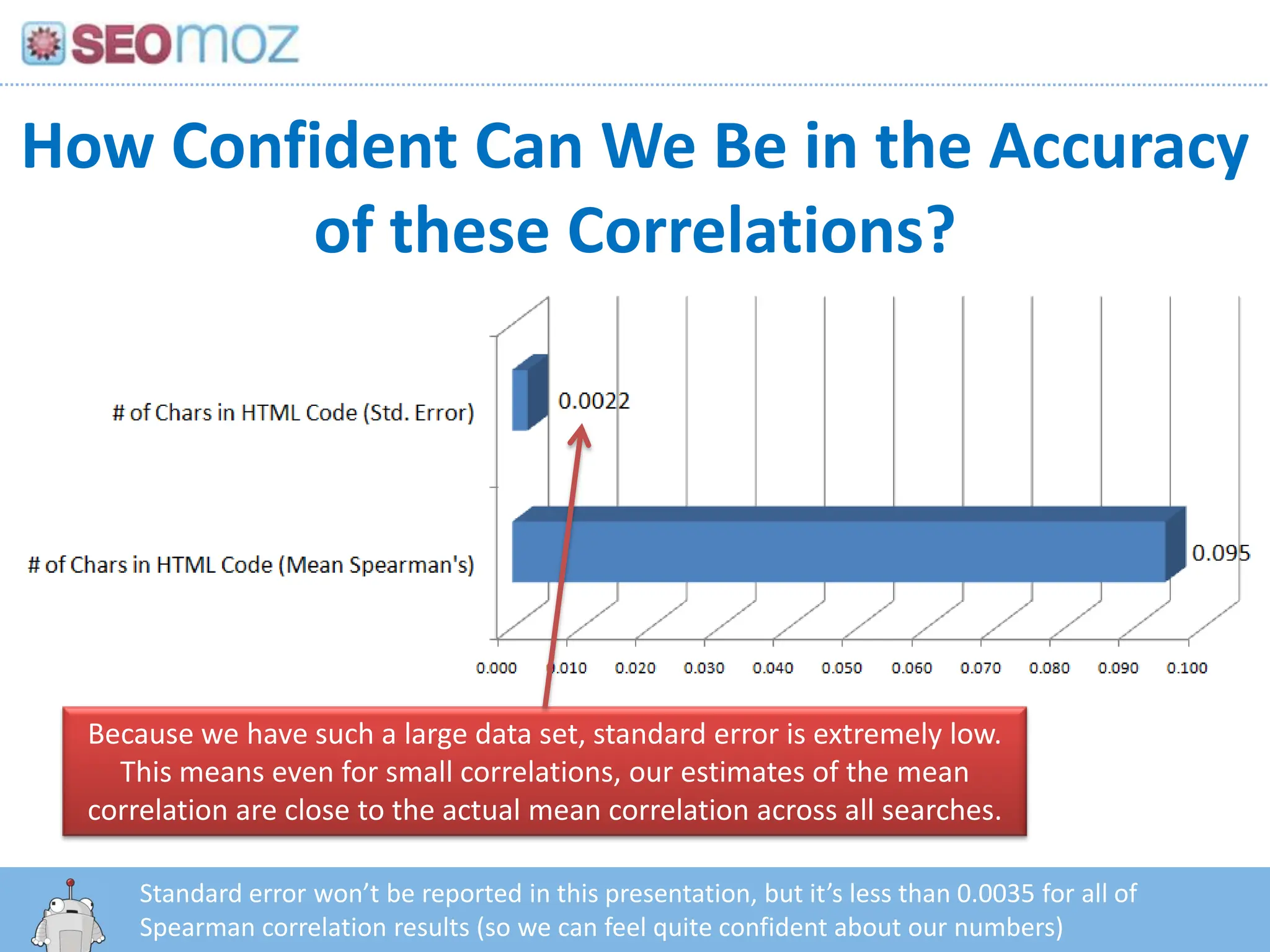
How Confident CanWe Be in the Accuracy of these Correlations?Because we have such a large data set, standard error is extremely low. This means even for small correlations, our estimates of the mean correlation are close to the actual mean correlation across all searches.Standard error won’t be reported in this presentation, but it’s less than 0.0035 for all of Spearman correlation results (so we can feel quite confident about our numbers)http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
9.
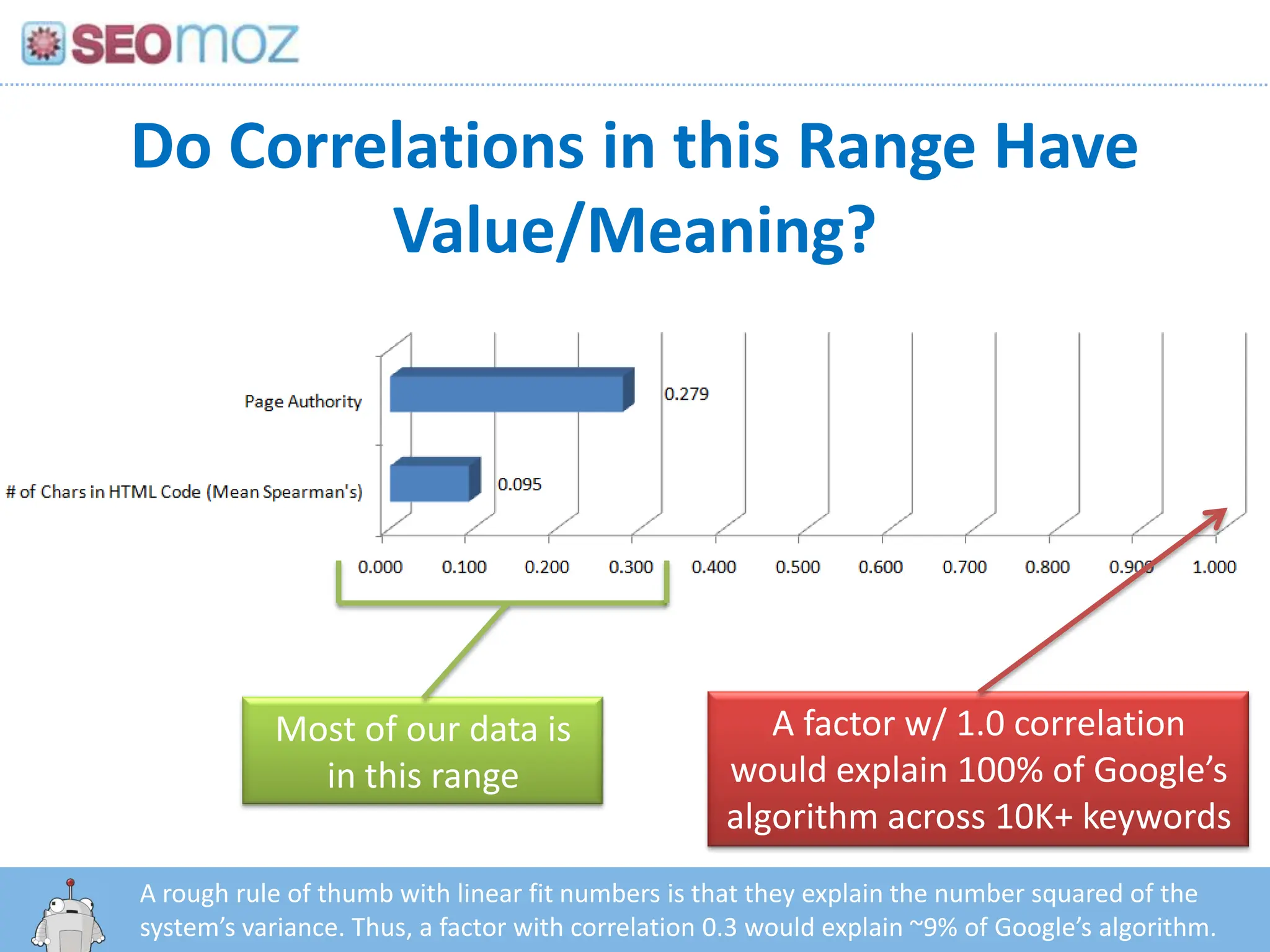
Do Correlations inthis Range Have Value/Meaning?A factor w/ 1.0 correlation would explain 100% of Google’s algorithm across 10K+ keywordsMost of our data is in this rangeA rough rule of thumb with linear fit numbers is that they explain the number squared of the system’s variance. Thus, a factor with correlation 0.3 would explain ~9% of Google’s algorithm.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
The Changing Landscapeof Google’s Ranking AlgorithmThese compare opinion/survey data from 2009 vs. 2011
12.
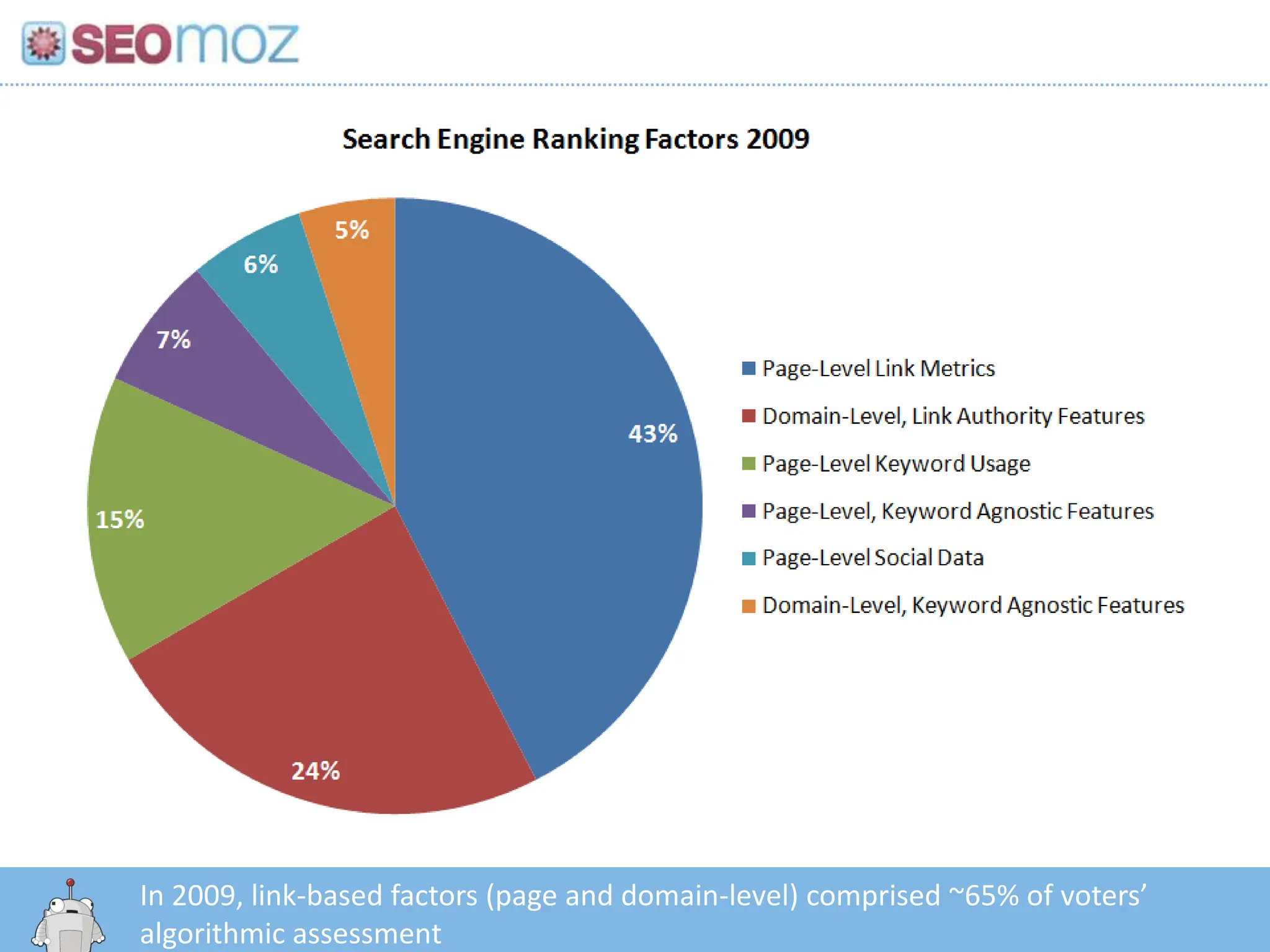
In 2009, link-basedfactors (page and domain-level) comprised ~65% of voters’ algorithmic assessmenthttp:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
13.
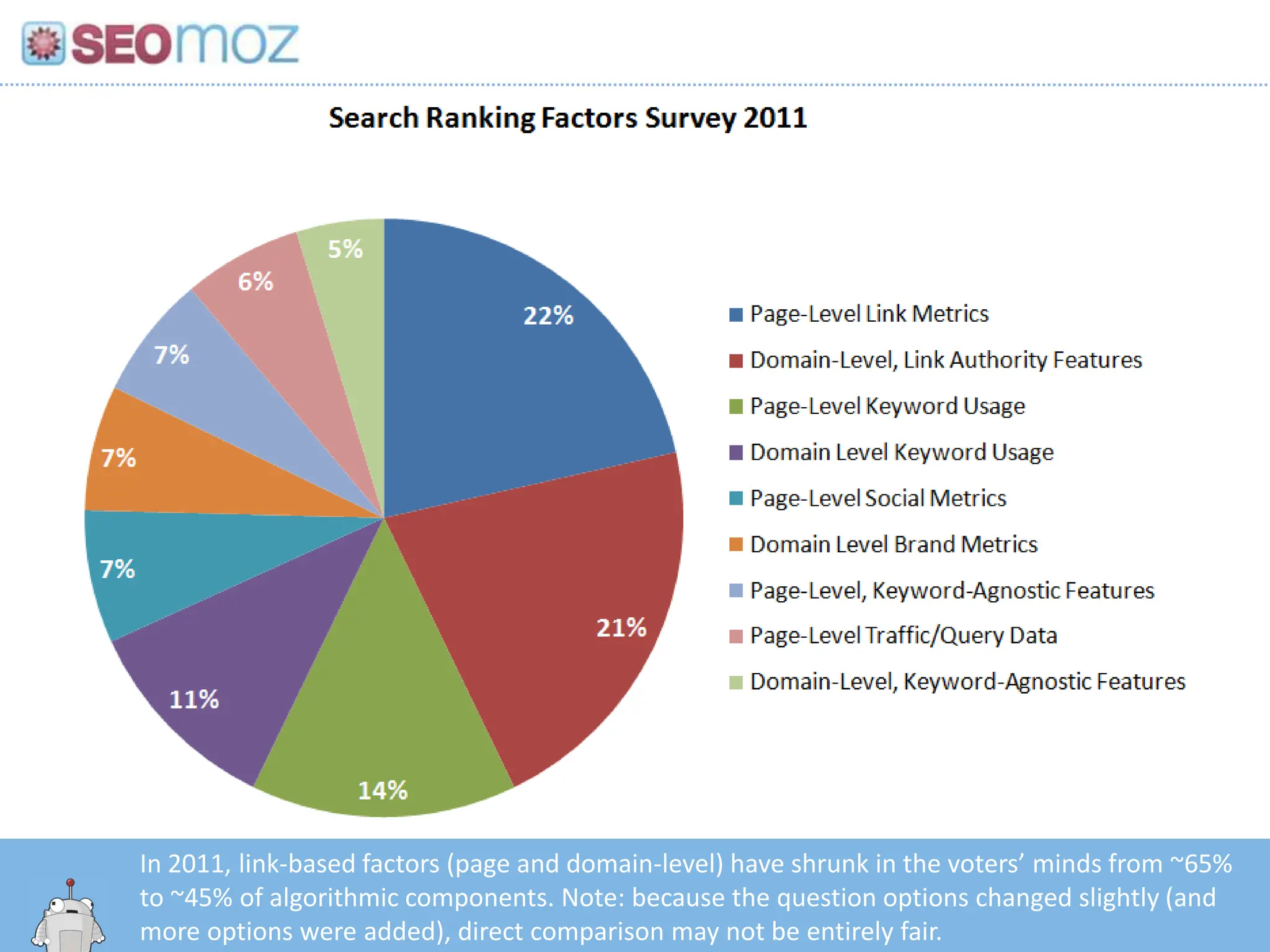
In 2011, link-basedfactors (page and domain-level) have shrunk in the voters’ minds from ~65% to ~45% of algorithmic components. Note: because the question options changed slightly (and more options were added), direct comparison may not be entirely fair.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
14.
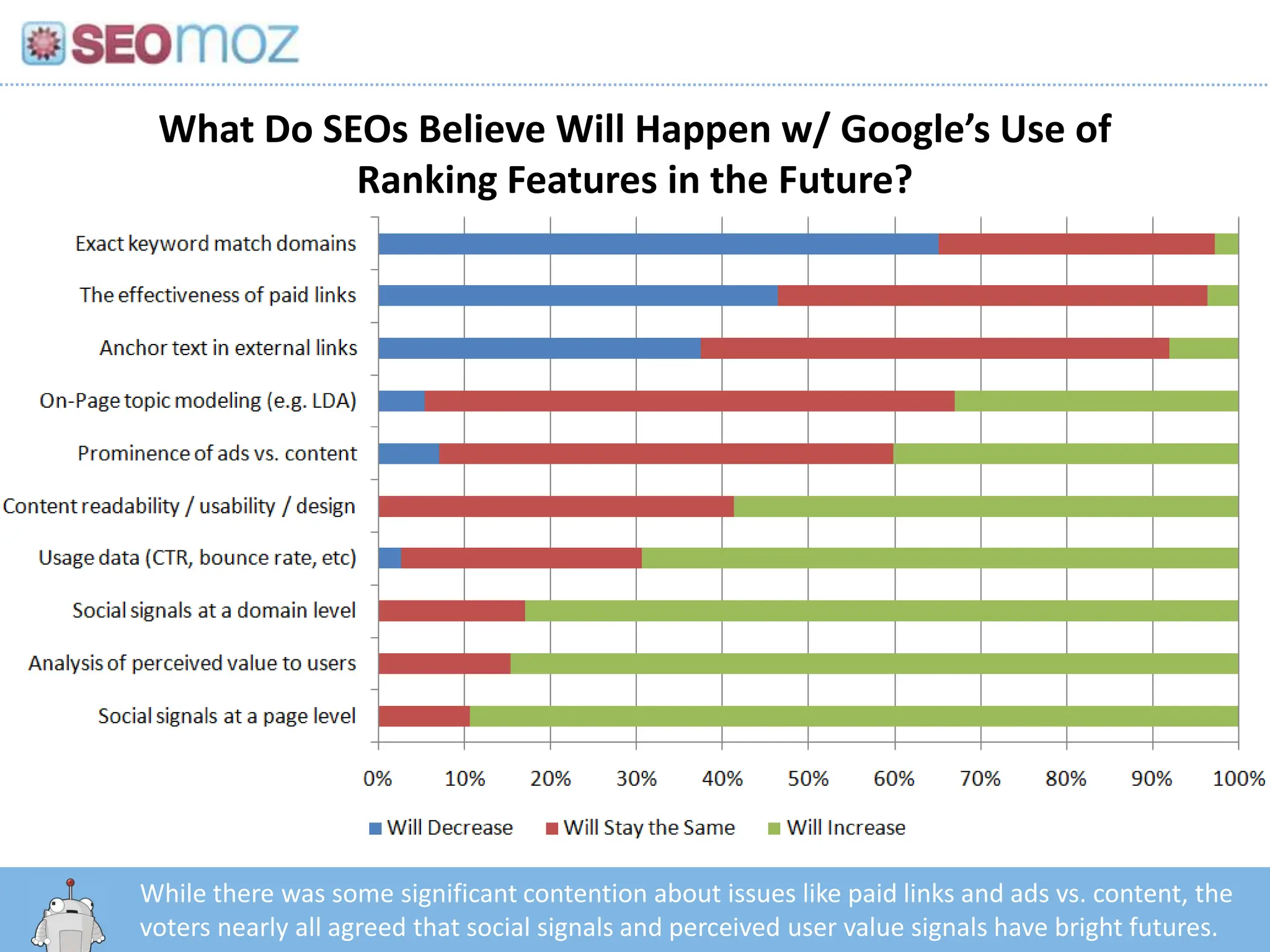
What Do SEOsBelieve Will Happen w/ Google’s Use of Ranking Features in the Future?While there was some significant contention about issues like paid links and ads vs. content, the voters nearly all agreed that social signals and perceived user value signals have bright futures.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
15.
Diversity + AnchorText:Well Correlated with Higher RankingsThese metrics are based on links that point specifically to the ranking page
16.
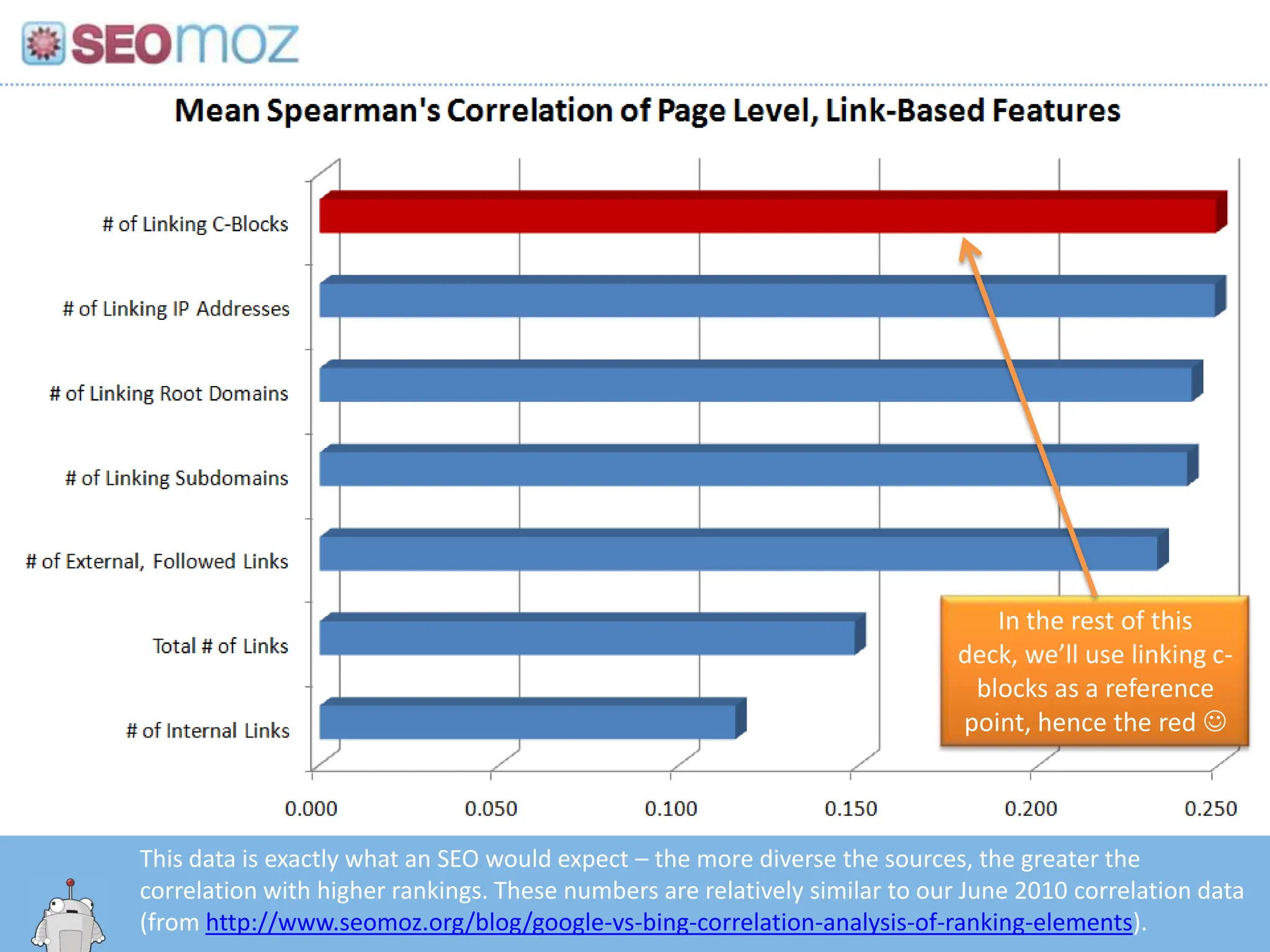
In the restof this deck, we’ll use linking c-blocks as a reference point, hence the red This data is exactly what an SEO would expect – the more diverse the sources, the greater the correlation with higher rankings. These numbers are relatively similar to our June 2010 correlation data (from http://www.seomoz.org/blog/google-vs-bing-correlation-analysis-of-ranking-elements).http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
17.
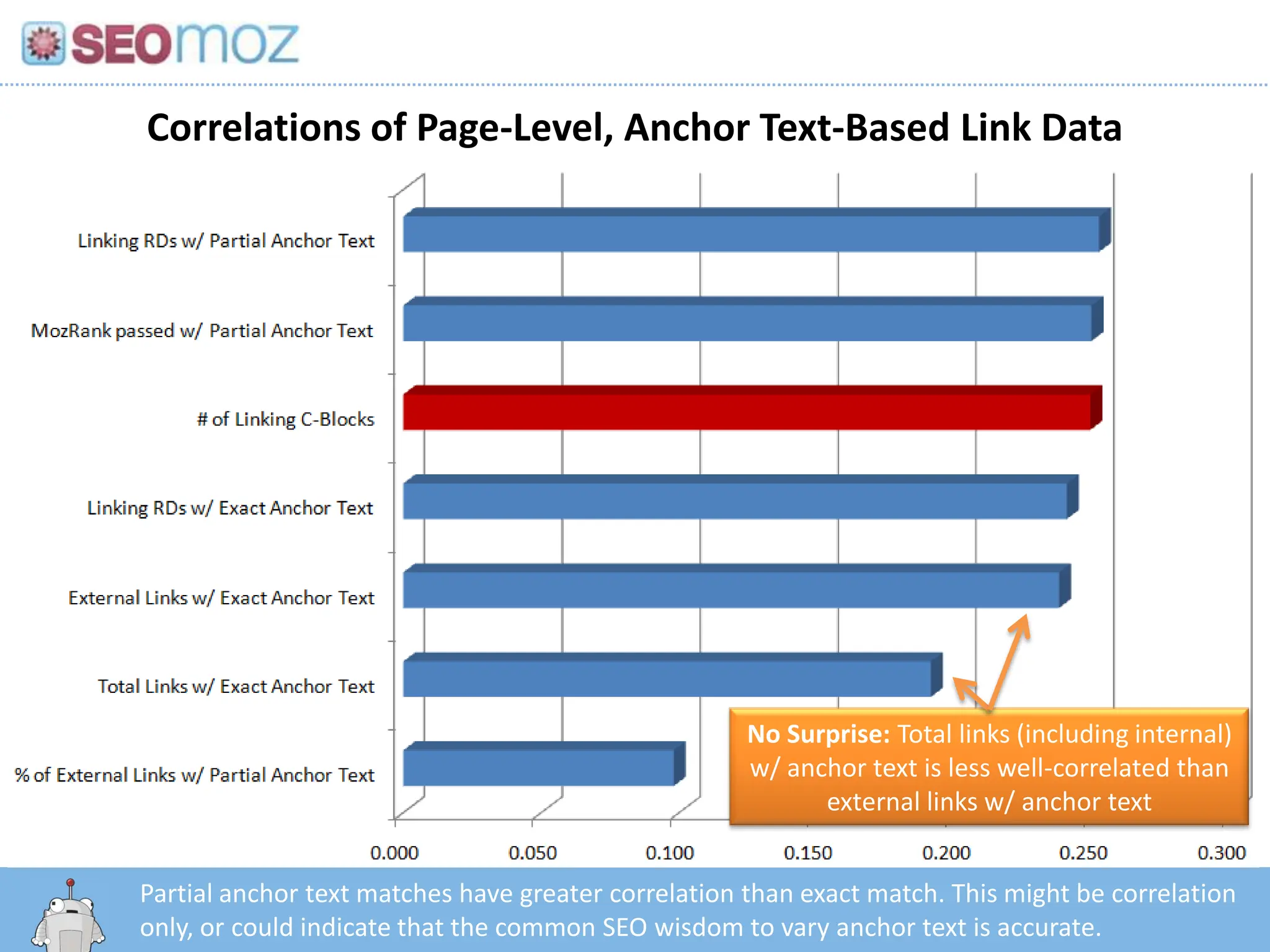
Correlations of Page-Level,Anchor Text-Based Link DataNo Surprise: Total links (including internal) w/ anchor text is less well-correlated than external links w/ anchor textPartial anchor text matches have greater correlation than exact match. This might be correlation only, or could indicate that the common SEO wisdom to vary anchor text is accurate.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
18.
ComparingPage + Domain-LevelLink SignalsThese metrics are based on links that point to anywhere on the ranking domain
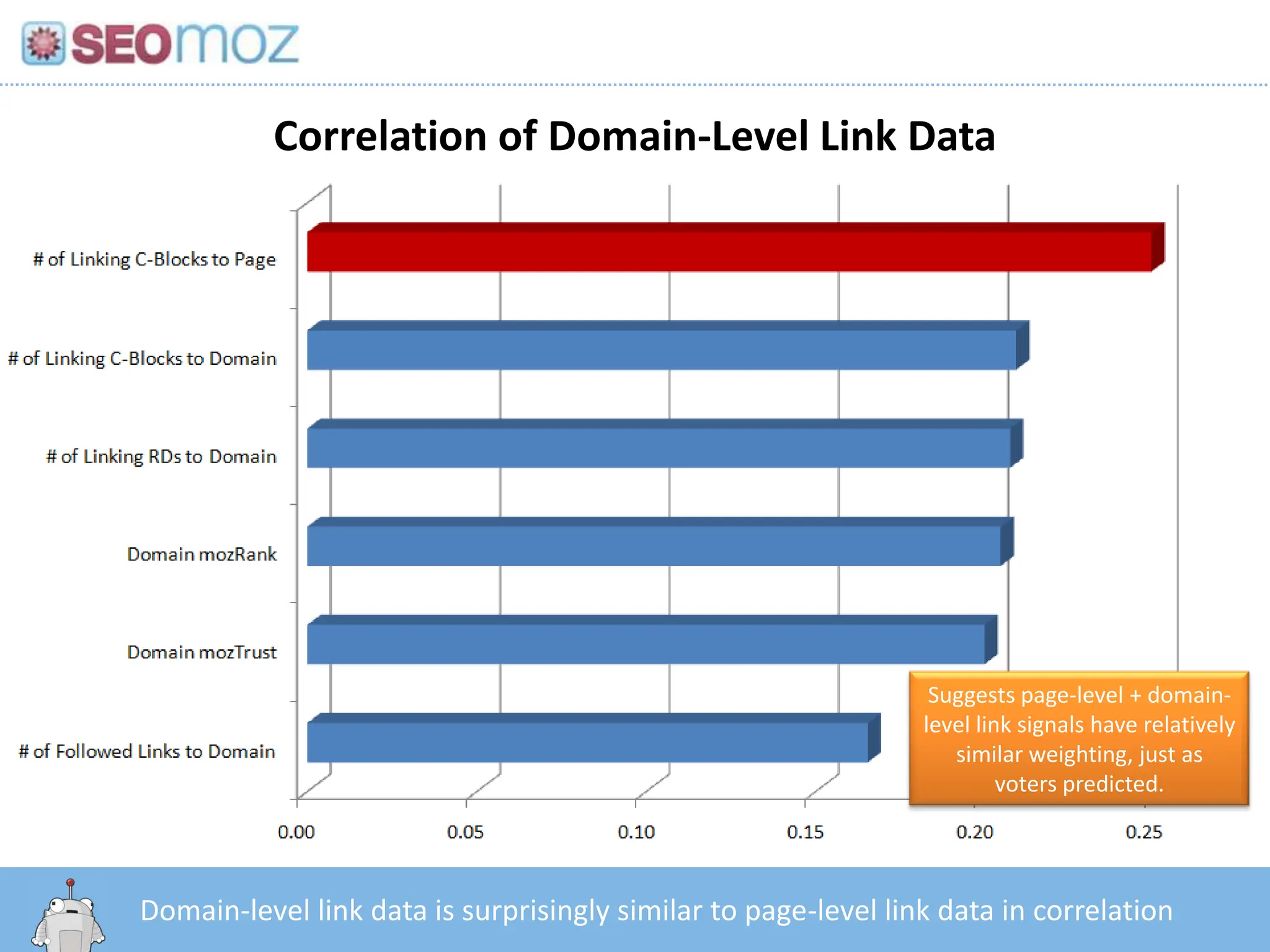
19.
Correlation of Domain-LevelLink DataSuggests page-level + domain-level link signals have relatively similar weighting, just as voters predicted.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.htmlDomain-level link data is surprisingly similar to page-level link data in correlation
20.
Have Exact MatchDomainsLost their Lustre?These signals are based on keyword-use in the root domain name.
21.
Spearman’s Correlation withGoogle Rankings forExact Match Domain Names June 2010 vs. March 2011Exact match domains (.com and all TLDs) have both fallen considerably in the past 10 monthsThis suggests that Google’s statements last year about devaluing exact match domains may have not only been serious, but are already getting into the results.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
22.
Is Google Evil?Thesemetrics come from a variety of places in the dataset, but mostly on-page stuff.
23.
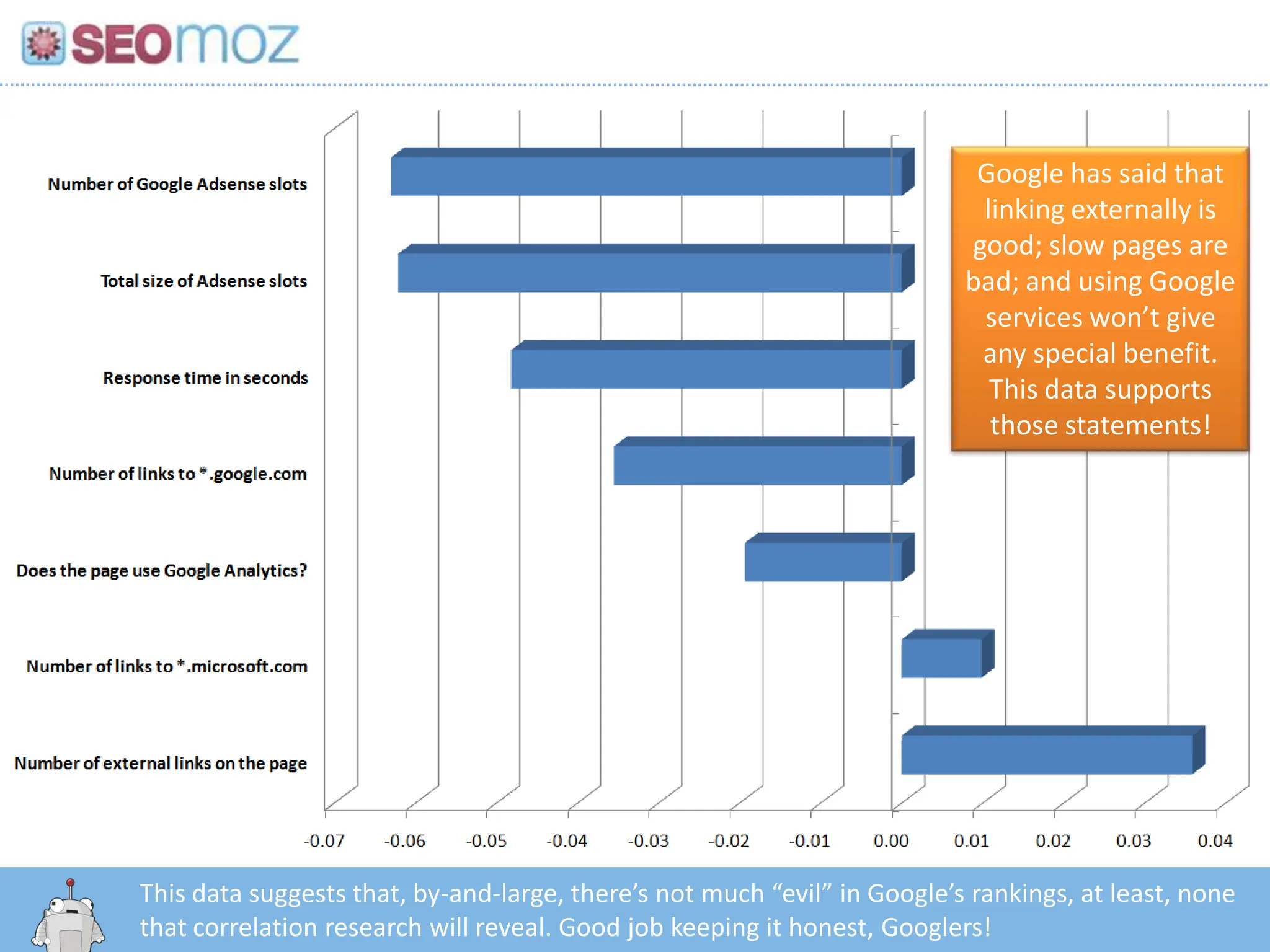
Google has saidthat linking externally is good; slow pages are bad; and using Google services won’t give any special benefit. This data supports those statements!This data suggests that, by-and-large, there’s not much “evil” in Google’s rankings, at least, none that correlation research will reveal. Good job keeping it honest, Googlers!http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
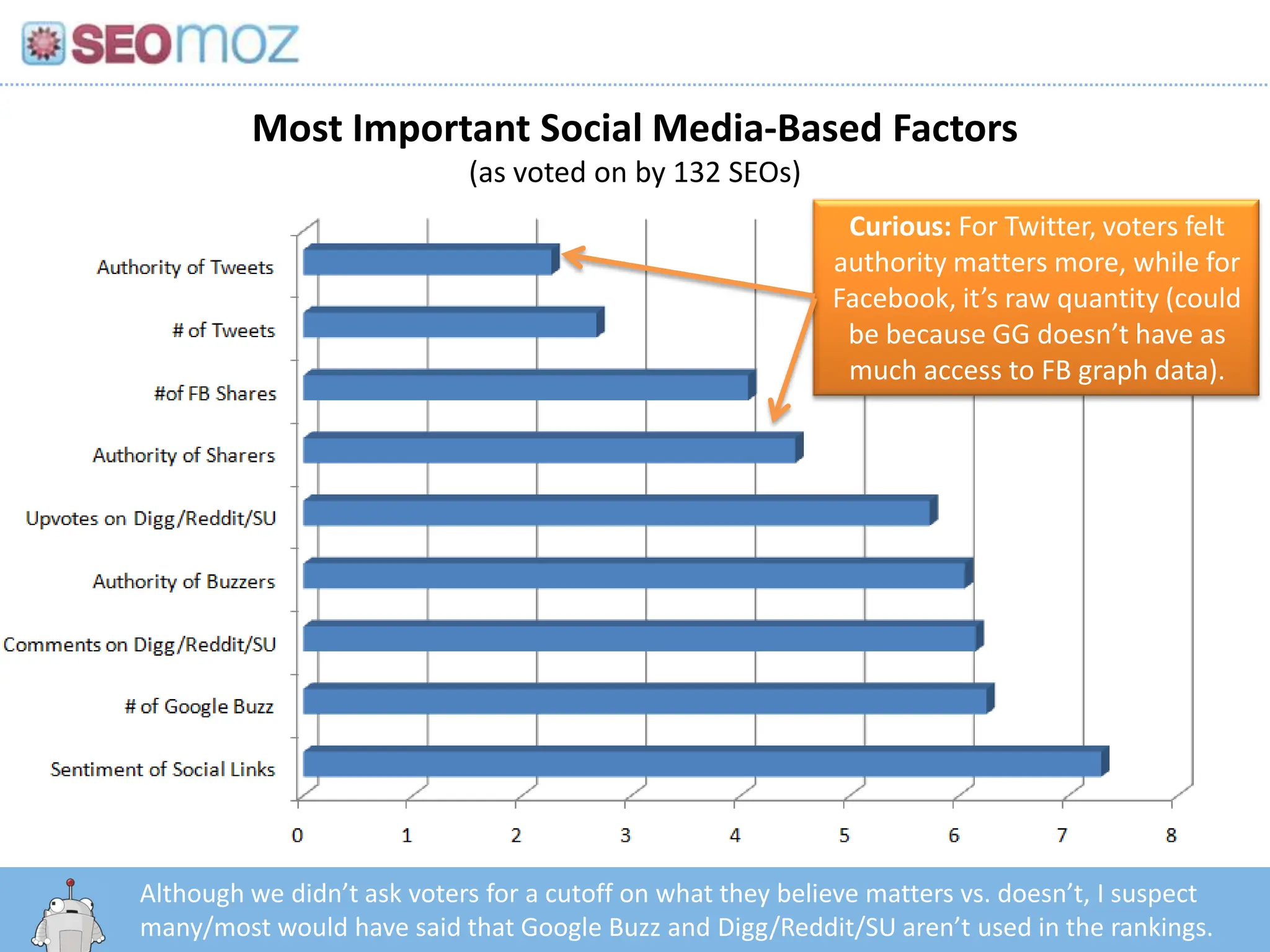
Most Important SocialMedia-Based Factors(as voted on by 132 SEOs)Curious: For Twitter, voters felt authority matters more, while for Facebook, it’s raw quantity (could be because GG doesn’t have as much access to FB graph data).Although we didn’t ask voters for a cutoff on what they believe matters vs. doesn’t, I suspect many/most would have said that Google Buzz and Digg/Reddit/SU aren’t used in the rankings.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
26.
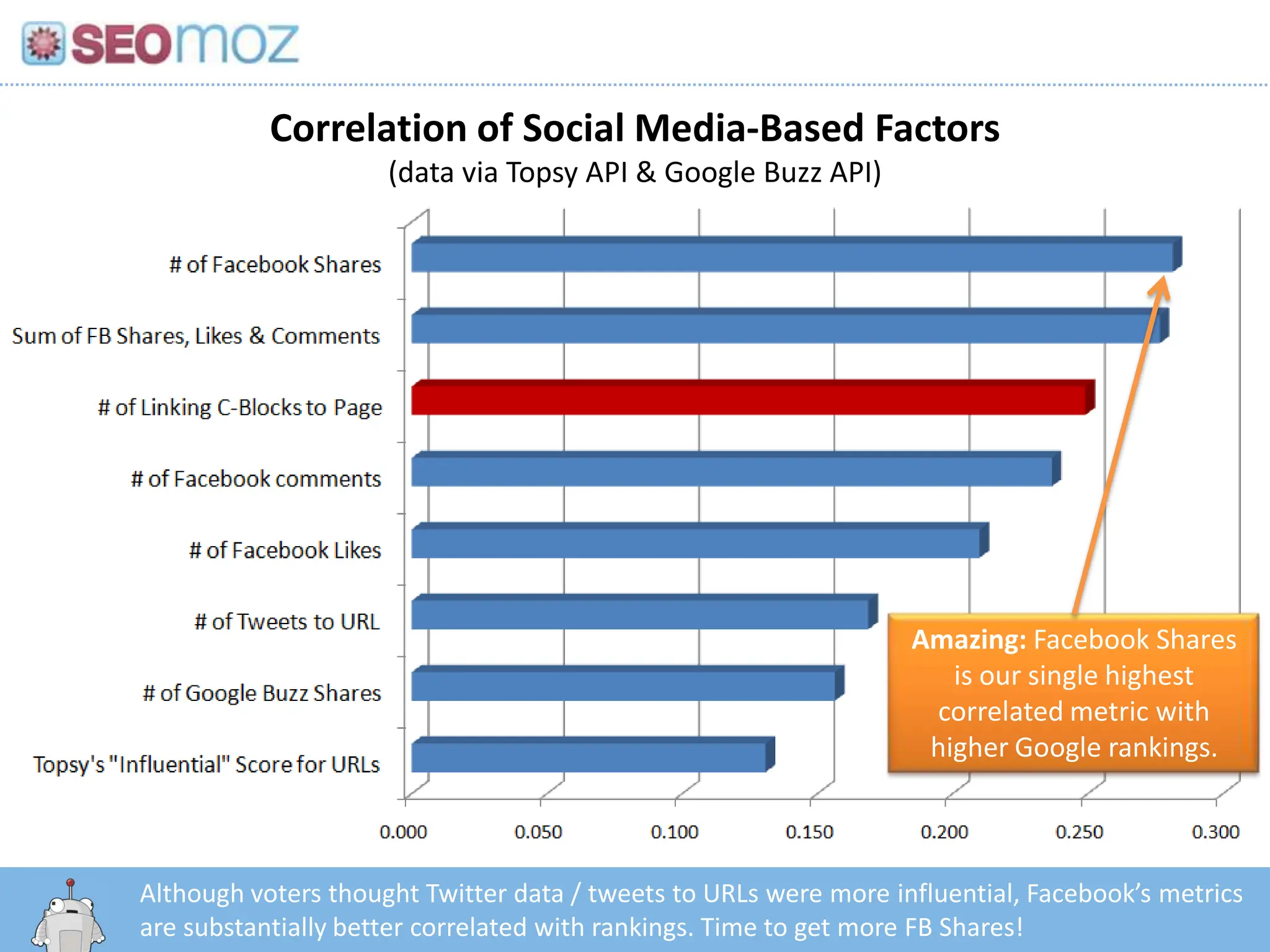
Correlation of SocialMedia-Based Factors(data via Topsy API & Google Buzz API)Amazing: Facebook Shares is our single highest correlated metric with higher Google rankings.Although voters thought Twitter data / tweets to URLs were more influential, Facebook’s metrics are substantially better correlated with rankings. Time to get more FB Shares!http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
27.
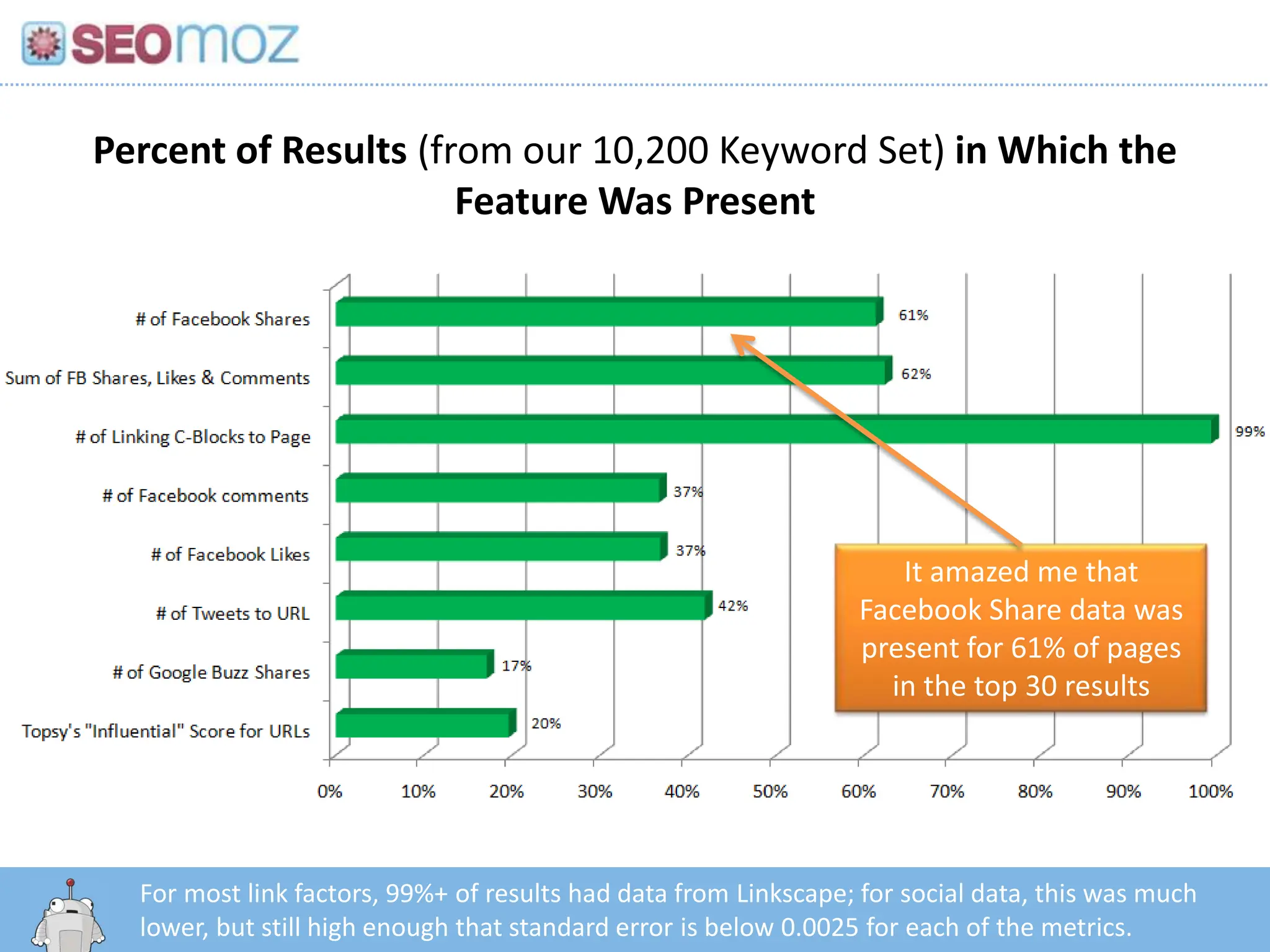
Percent of Results(from our 10,200 Keyword Set) in Which the Feature Was PresentIt amazed me that Facebook Share data was present for 61% of pages in the top 30 resultsFor most link factors, 99%+ of results had data from Linkscape; for social data, this was much lower, but still high enough that standard error is below 0.0025 for each of the metrics.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
28.
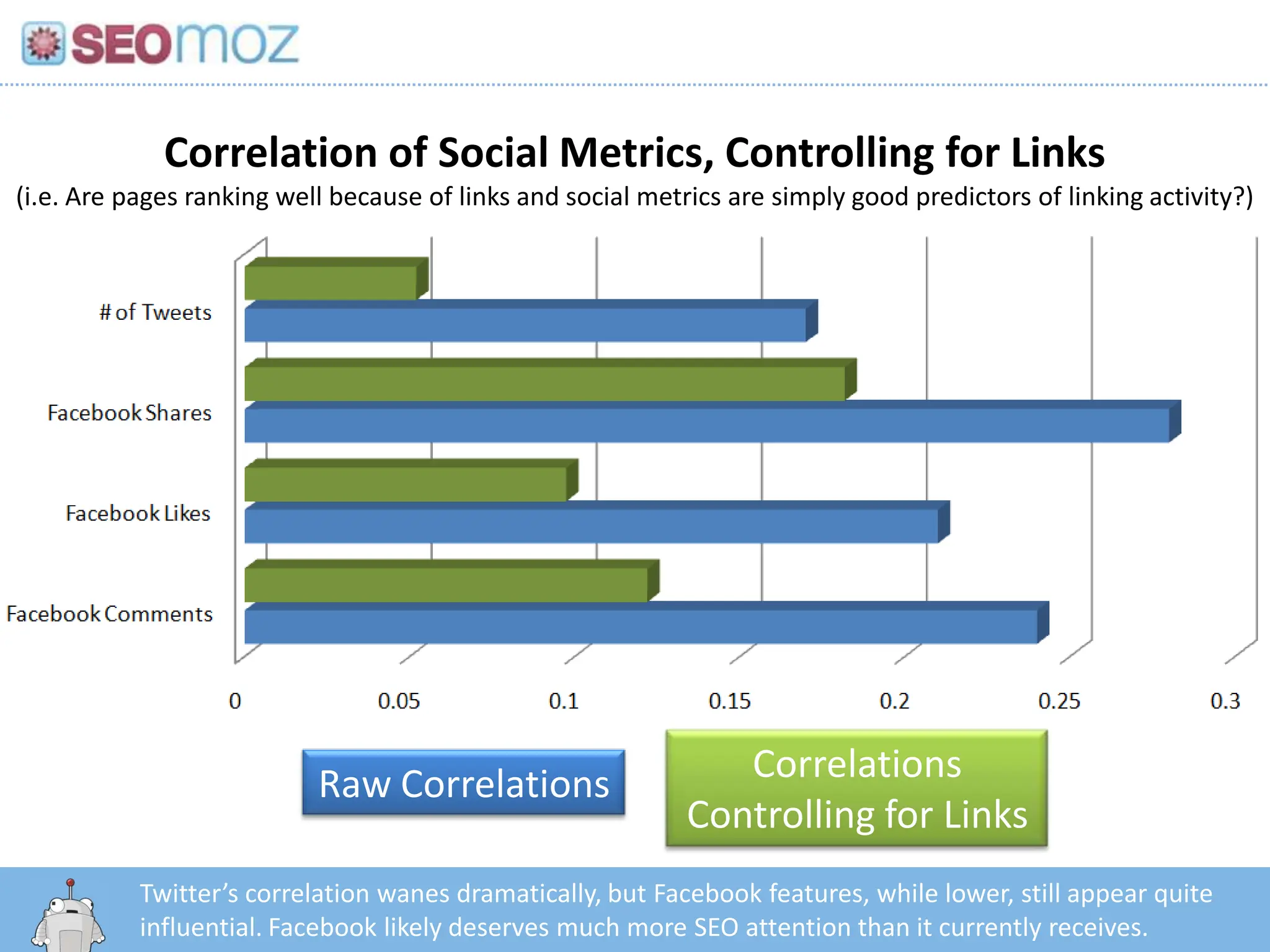
Correlation of SocialMetrics, Controlling for Links(i.e. Are pages ranking well because of links and social metrics are simply good predictors of linking activity?)Correlations Controlling for LinksRaw CorrelationsTwitter’s correlation wanes dramatically, but Facebook features, while lower, still appear quite influential. Facebook likely deserves much more SEO attention than it currently receives.http:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.html
29.
IMPORTANT!Don’t Misuse orMisattribute Correlation Data!Think of correlation data as a way of seeing features of sites that rank well, rather than a way of seeing what metrics search engines are actually measuring and counting.A well-correlated metric can often be its own reward, even if it doesn’t directly impact search engine rankings. Virtually all the data in this report reflect the best practices of inbound marketing overall – and using the data to help support these is an excellent application Thanks much!Randhttp:/googleblog.blogspot.com/2010/06/our-new-search-index-caffeine.htmlBe a responsible user of correlation data – thank you!
30.
Q+ARand FishkinCEO &Co-Founder, SEOmozThe full report is now available!http://bit.ly/rankfactors2011 Twitter: @randfish









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





