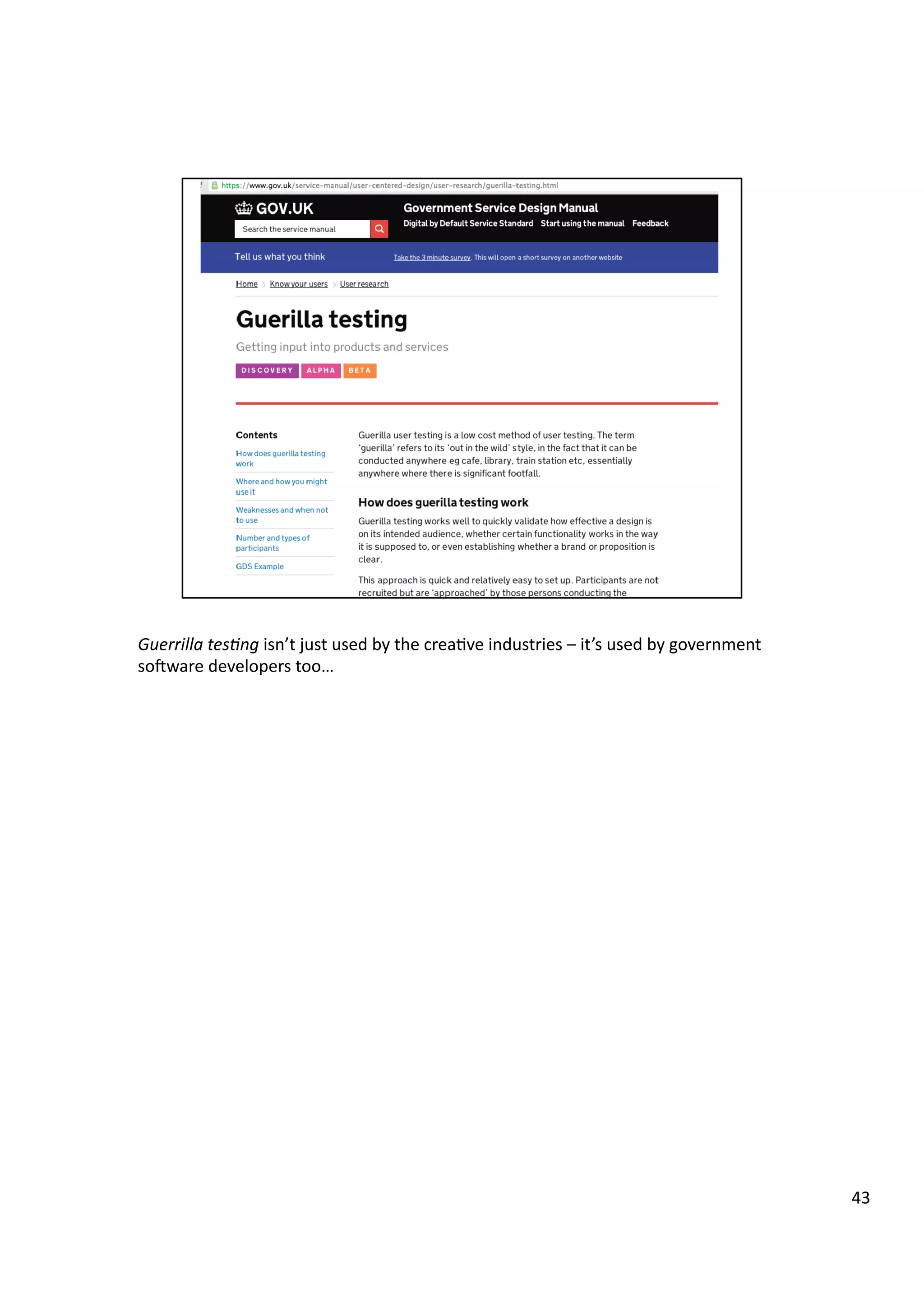
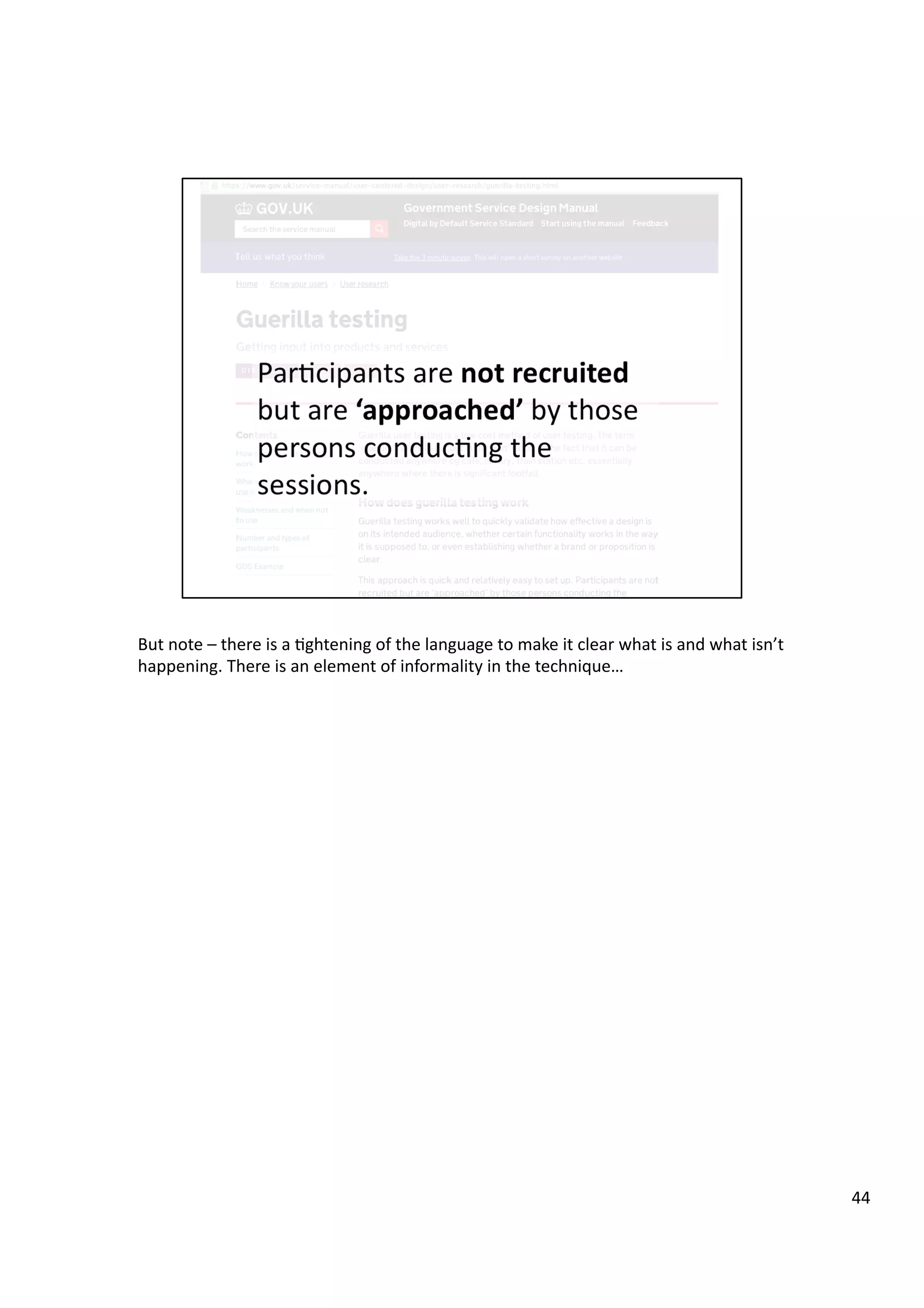
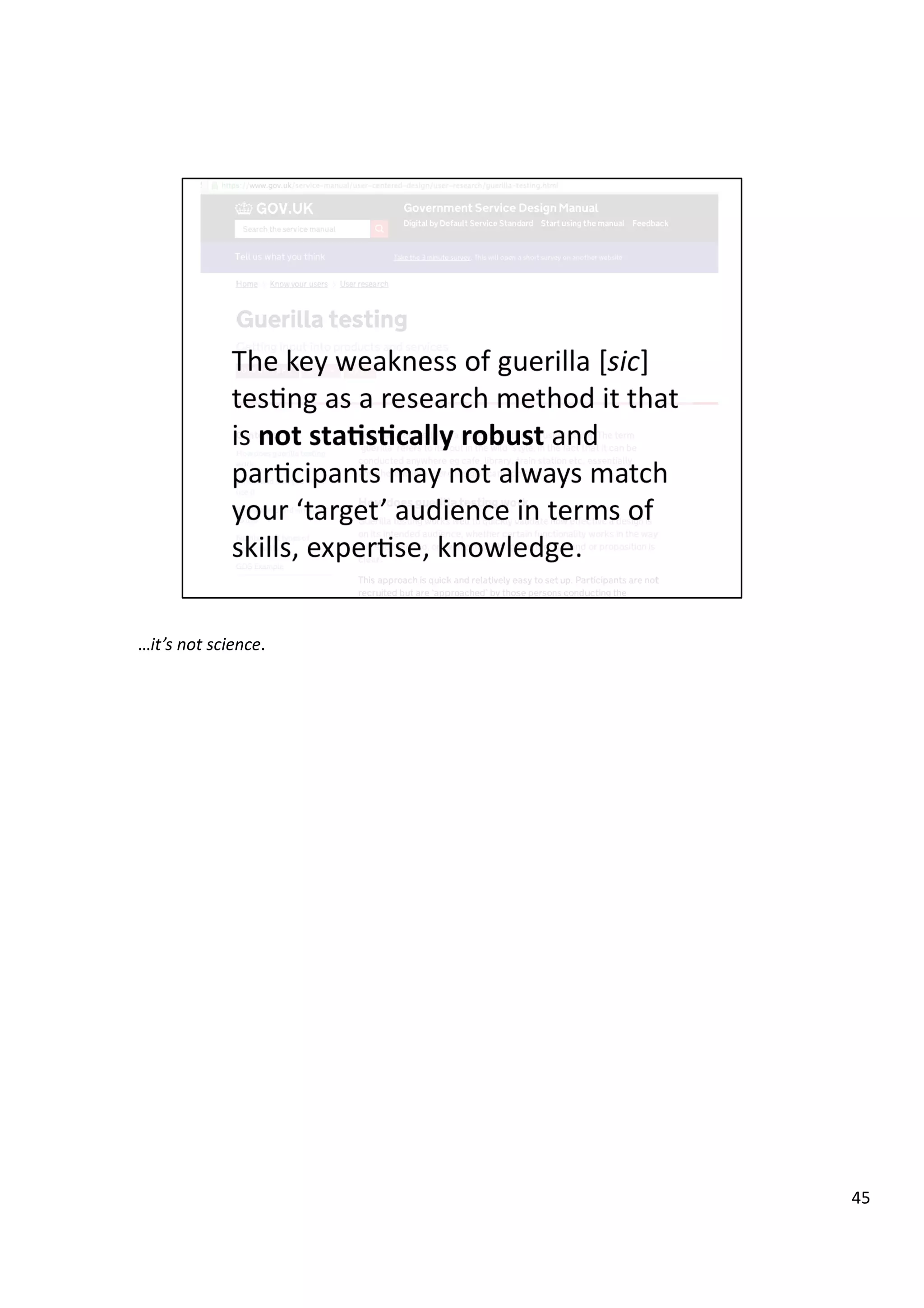
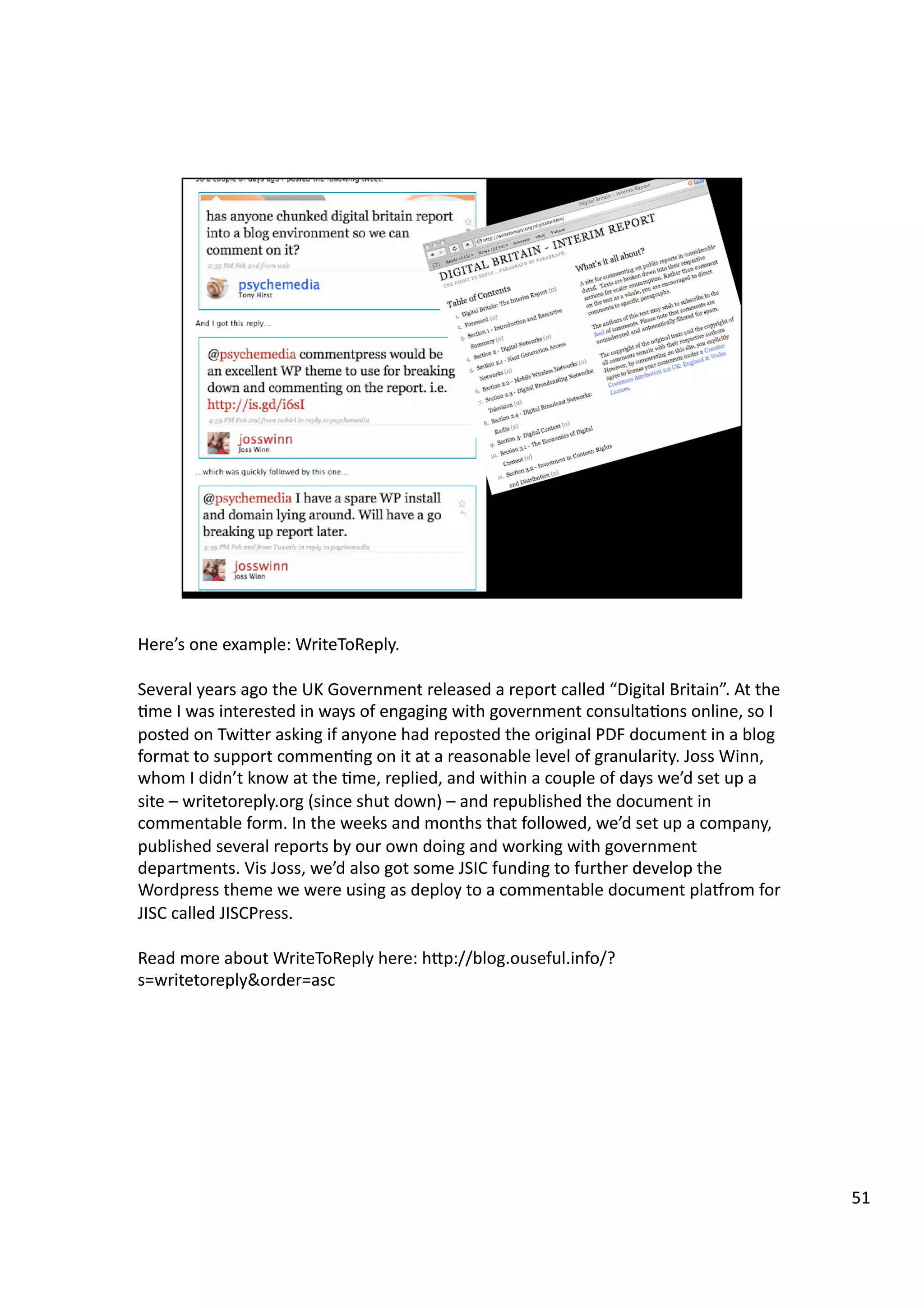
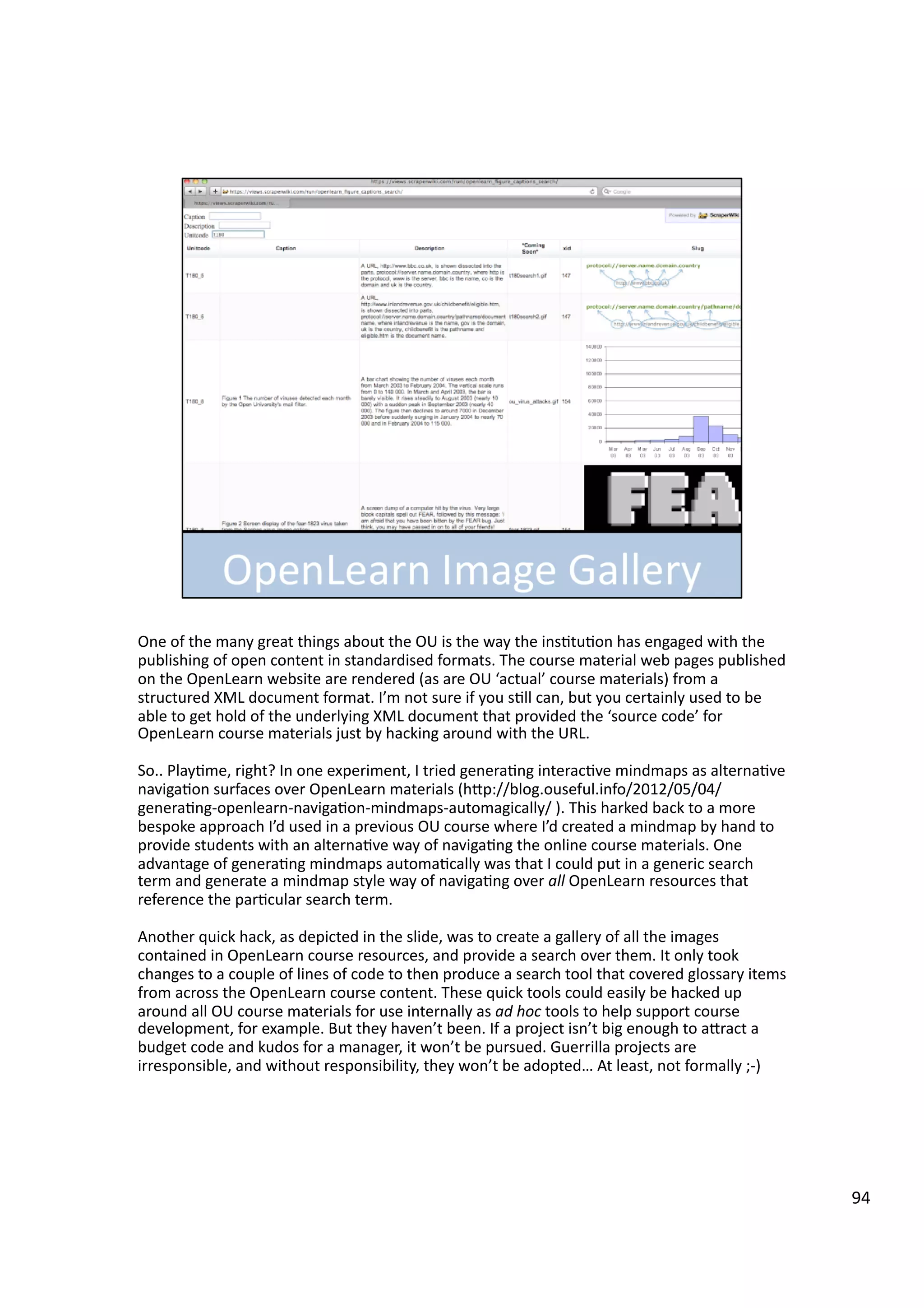
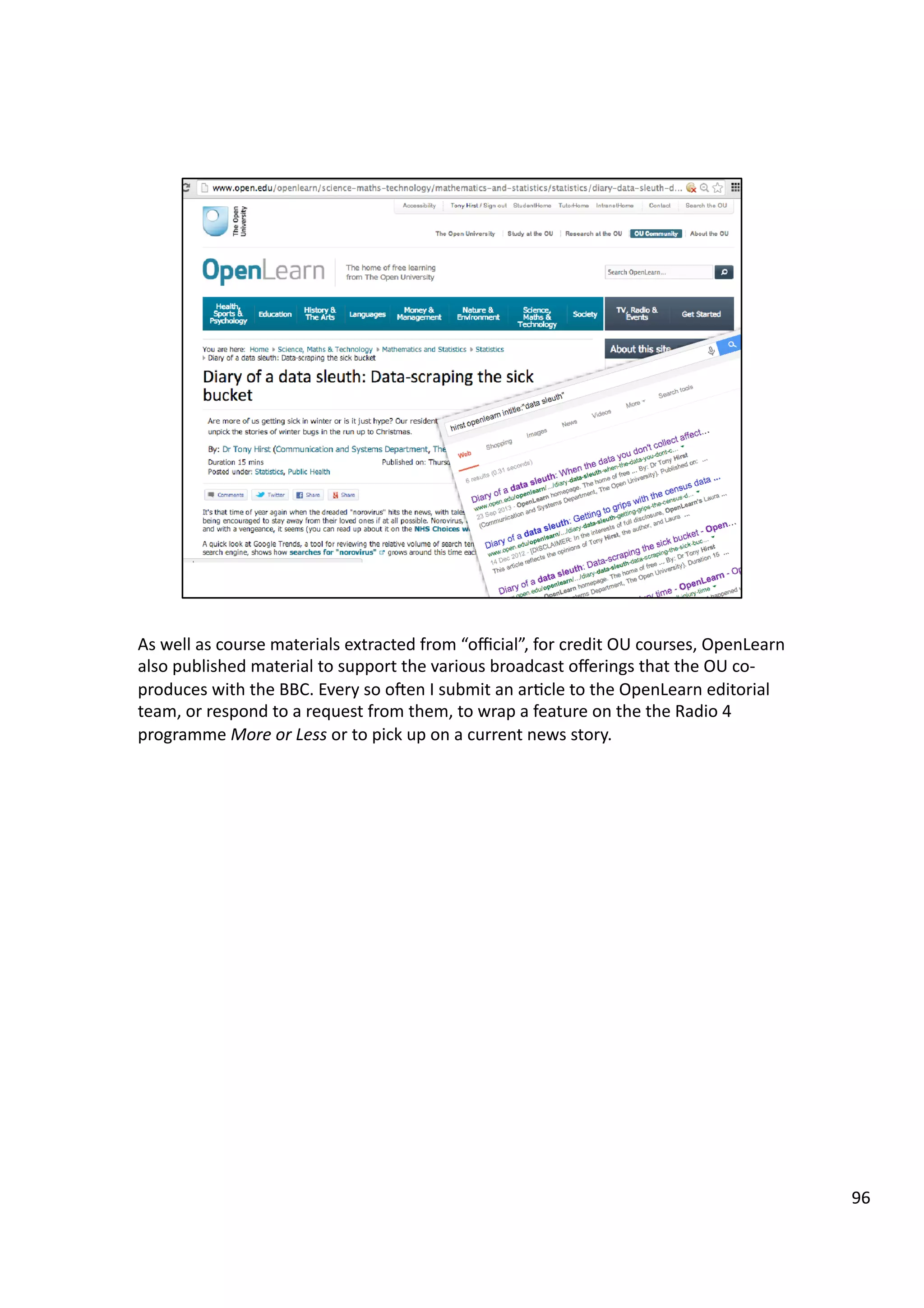
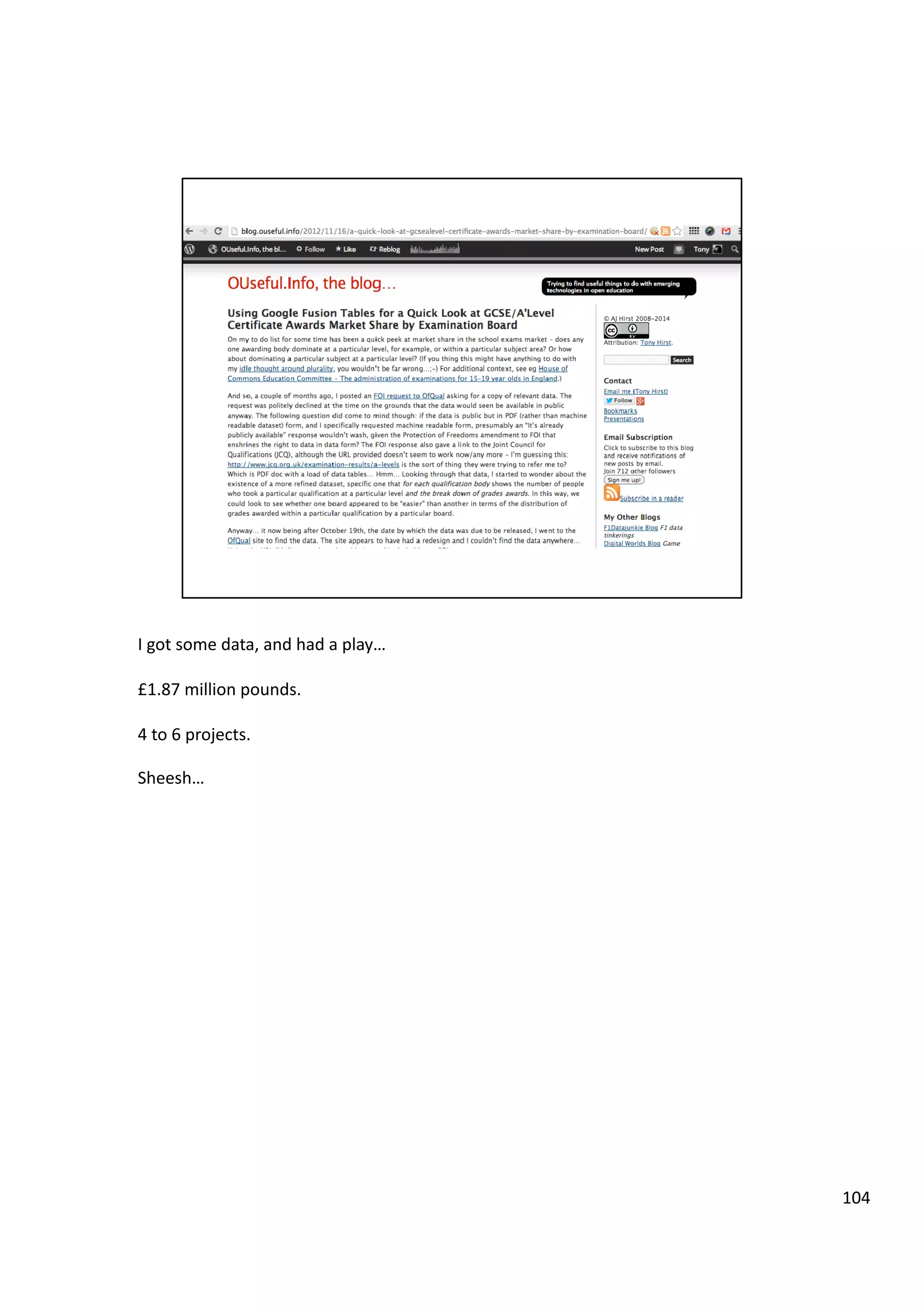
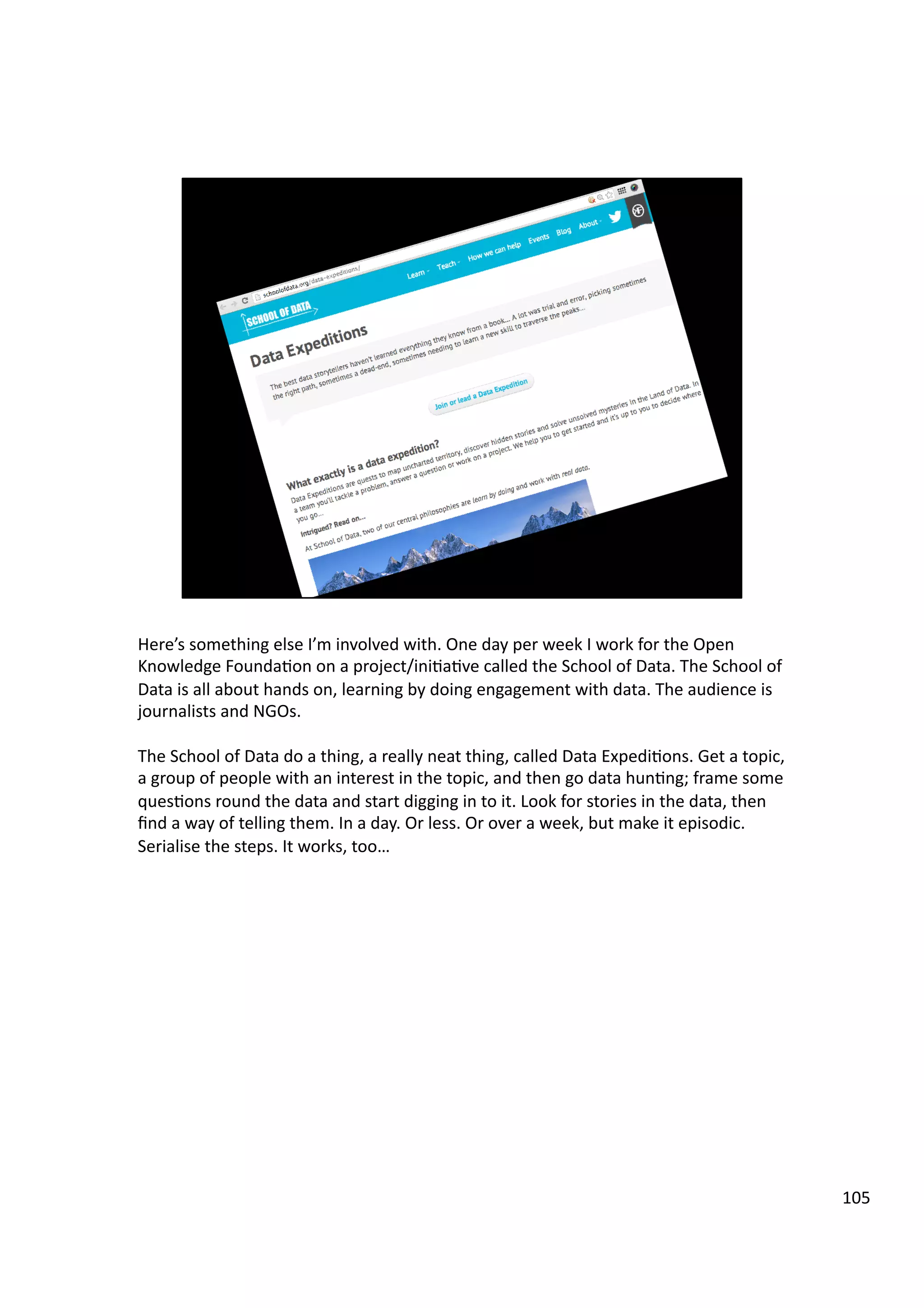
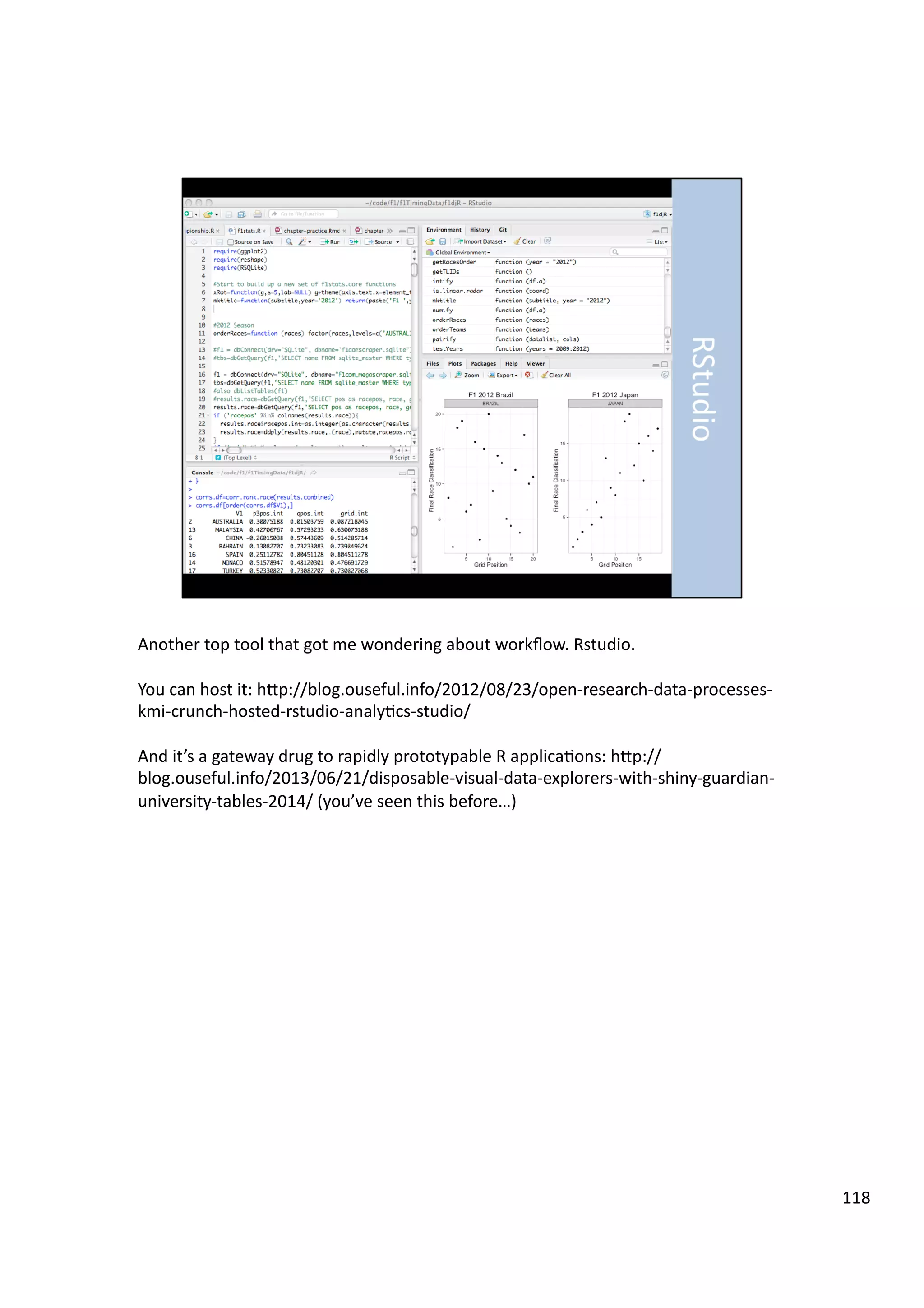
Downloaded 10 times



















![Are
there
any
other
forms
of
guerrilla
ac3vity
that
might
give
us
a
steer?
[A
note
on
info
skills.
I’m
not
sure
where
or
when
I
learned
it,
but
very
early
on
in
life
I
learned
how
to
navigate
books
in
general,
and
then,
later,
how
to
navigate
technical
books,
text
books
and
academic
texts:
book
3tle
and
author
for
an
idea
of
what
was
in
the
book,
along
with
the
notes
on
the
back
cover
or
side
papers;
chapter
lis3ngs
for
gegng
an
idea
of
the
structure
of
a
book,
page
numbers
for
finding
or
remembering
specific
pages,
page
headers
for
keeping
track
or
reorien3ng
myself
within
a
book
or
naviga3ng
it
while
skimming
it,
indexes
for
finding
the
loca3on
by
page
of
a
par3cular
idea,
topic,
person,
or
place;
lists
of
figures
for
finding
out
where
the
pictures
were,
and
maybe
more
about
them;
lists
of
tables
for
finding
where
the
data
is,
and
so
on.
I
also
learned
to
navigate
the
directories
I
use
on
a
daily
basis
on
the
web:
advanced
search
pages
offer
many
ways
of
limi3ng
a
search
to
make
it
more
powerful,
but
how
many
people
use
them?
And
how
many
people
know
that
those
search
limits
are
accessible
by
addi3onal
commands
–
search
limits
–
placed
in
the
search
box.
(Indeed,
that’s
oeen
how
advanced
search
limits
are
added
to
a
search.)
In
this
case,
I
am
limi3ng
my
search
to
pages
on
the
English
version
of
Wikipedia
by
asking
only
for
results
on
h@p://en.wikipedia.org,
to
pages
that
are
actual
Wikipedia
entries
(inurl:wiki
–
look
at
the
URL/web
address
of
a
Wikipedia
page
and
you’ll
spot
why
I
added
that
par3cular
term
-‐
h@p://en.wikipedia.org/wiki/Guerrilla_gardening);
and
further
asking
that
the
word
guerrilla
appears
in
the
page
3tle.
If
you
want
to
search
content
on
the
OU
website.
A
site:open.ac.uk
limit
will
do
it
for
you.
If
you
want
to
search
across
UK
government
websites,
limit
by
site:.gov.uk;
and
so
on.
There
are
other
useful
limits
too:
filtetype:
limits
results
to
par3cular
documents
types:
filetype:ppt
for
Powerpoint
decks
(though
a
beHer
one
there
is,
in
brackets,
the
combined
(filetype:ppt
OR
filetype:pptx)
search
limit),
filetype:pdf
for
PDFs,
or
(filetype:xls
OR
filetype:xlsx
OR
filetype:csv)
to
return
spreadsheet
and
CSV
data
files.]
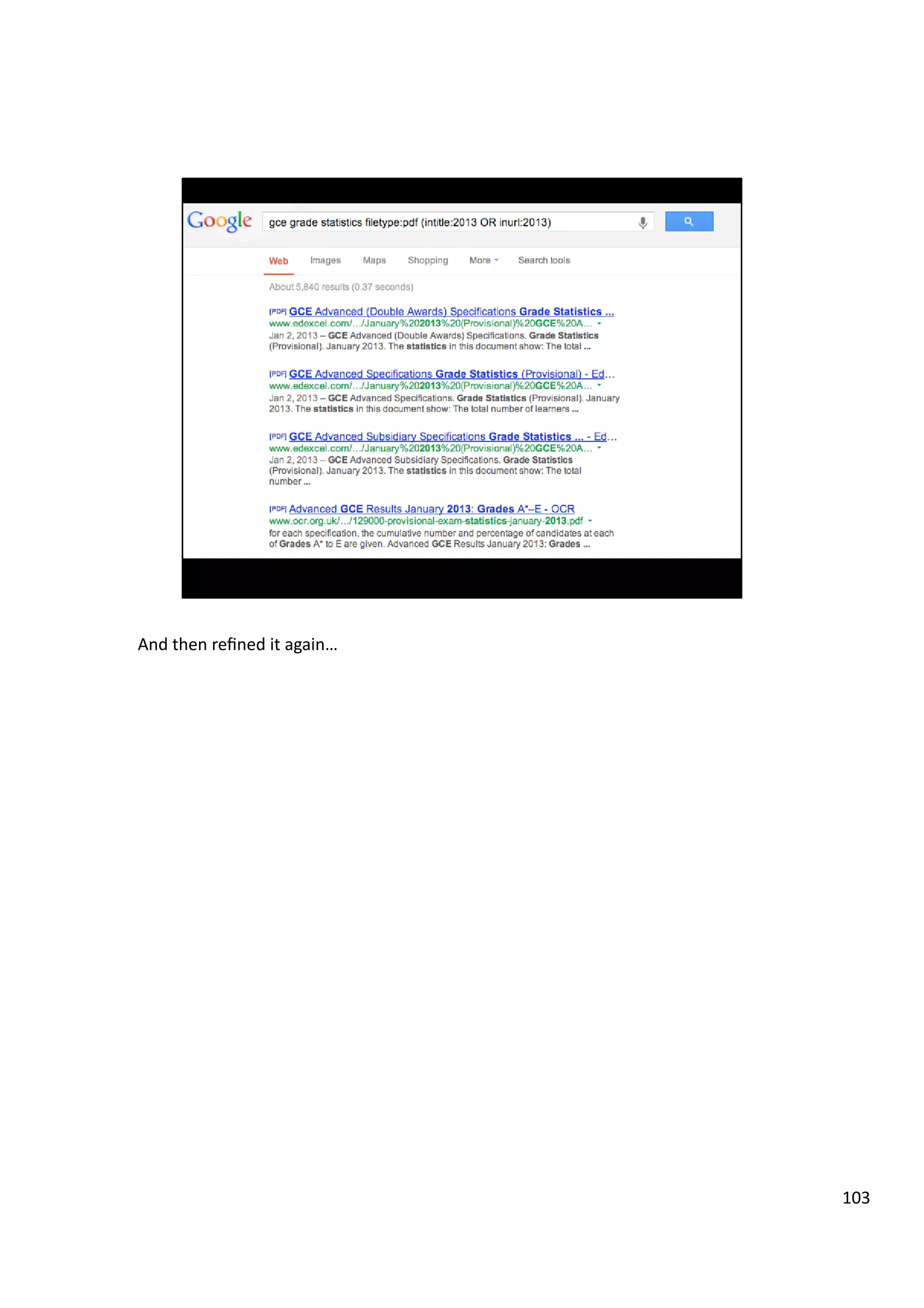
22](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-22-2048.jpg)



![How
does
this
sound?
”The
act
of
guerrilla
research
is
focused
on
cause
and
effect,
not
the
research
piece
itself.
It
aims
to
produce
an
effect
within
the
minds
of
those
people
that
live
within
the
environment
being
altered.
It
does
not
necessarily
aim
to
produce
research
that
is
meaningful
as
research.”
[The
workshop
addi3onally
turned
up
the
idea
of
guerrilla
gardening,
sowing
seeds
or
taking
over
land
without
permission
and
pugng
it
to
use.
This
has
far
more
of
the
feel
I
think
Mar3n
was
sugges3ng…
again,
according
to
Wikipedia,
“the
act
of
gardening
on
land
that
the
gardeners
do
not
have
the
legal
rights
to
u7lize,
such
as
an
abandoned
site,
an
area
that
is
not
being
cared
for,
or
private
property.”
This
is
very
much
in
the
style
of
not
asking
for
permission,
of
iden3fying
a
valuable
but
underu3lised
or
otherwise
neglected
resource,
and
pugng
it
to
some
sort
of
use
that
is
construc3ve
within
the
environment
and
of
benefit
to
the
environment
and
its
inhabitants.]
28](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-28-2048.jpg)











![Thoughts
on
guerrilla
research
from
an
occasional
prac33oner.
The
brief?
“Permission
free,
no
funding,
jfdi,
quicker
to
do
research
than
write
bid..”
[I
added
to
the
slides
as
Mar7n
Weller
presented,
trying
to
bring
in
addi7onal
examples
from
my
own
ed-‐tech
7nkerings
to
reflect
the
interests
of
the
#elesig
community.
Unfortunately,
I
didn’t
have
7me
to
then
prune/revise
the
narra7ve!
So
here’s
the
overkill
version!]
Some
reflec7ons
on
my
own
“prac7ce”
-‐
is
this
guerrilla
research?
47](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-47-2048.jpg)









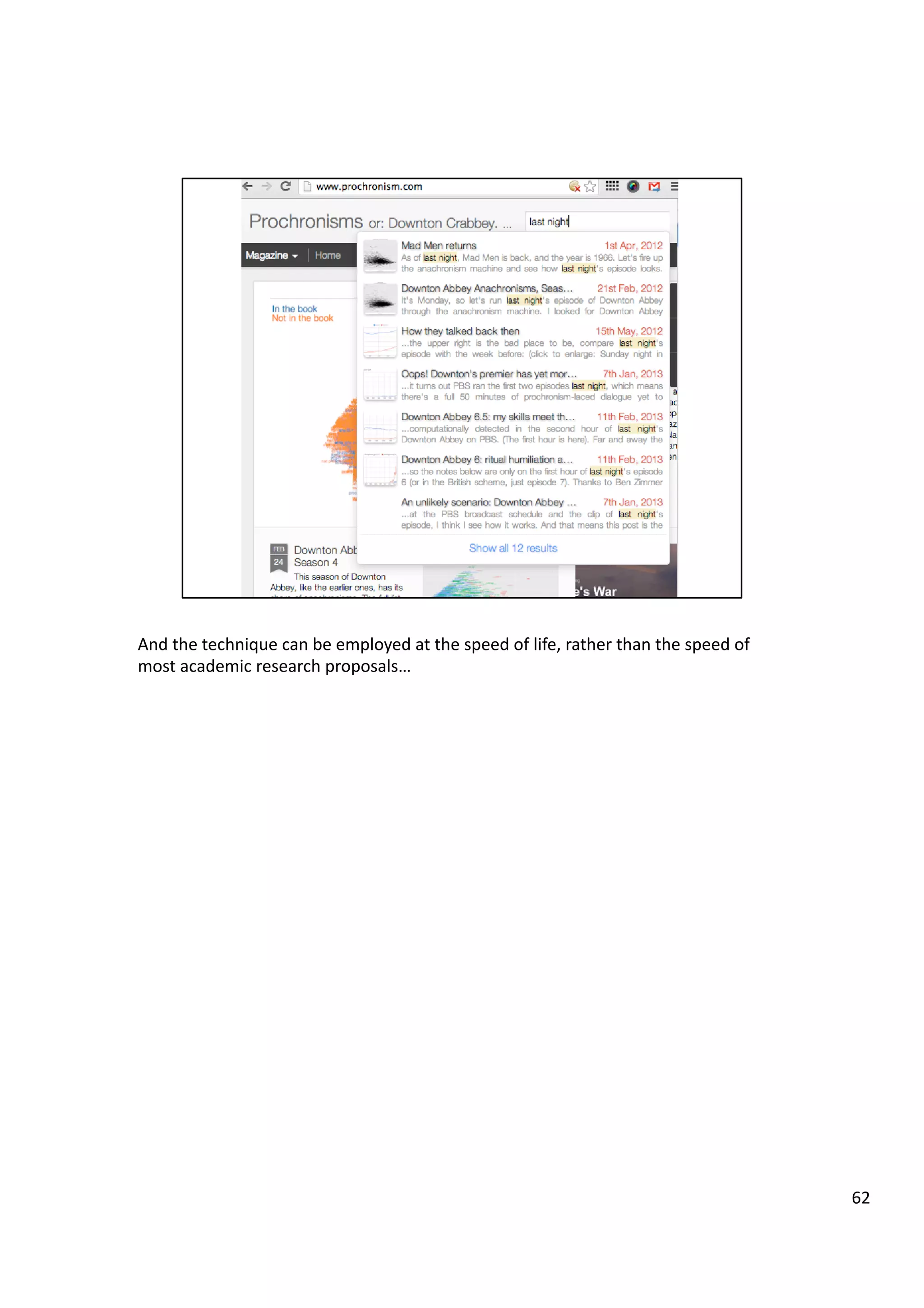

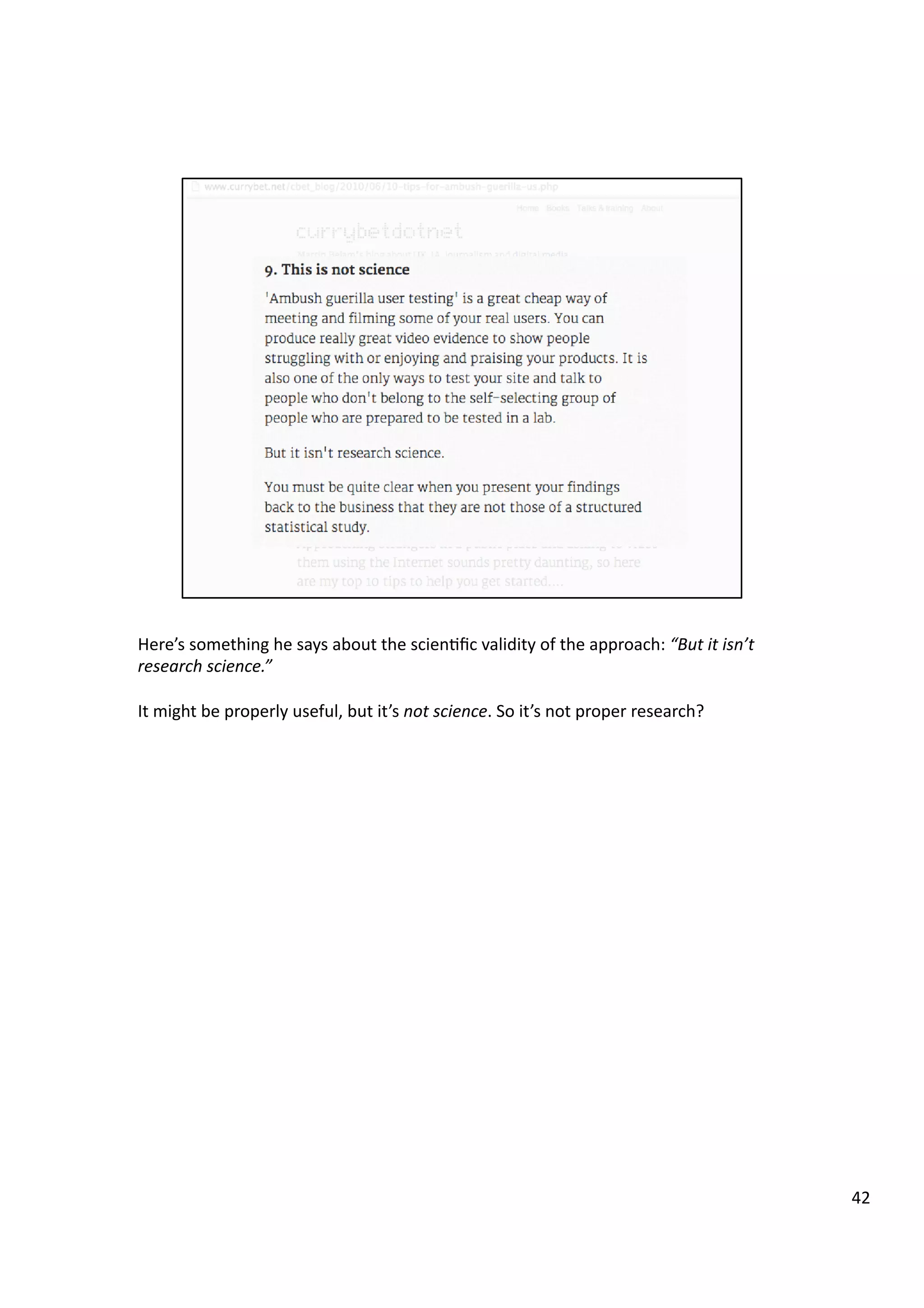
![A
technique
I
have
found
useful
I
first
saw
used
by
MaH
Morrison
(@mediaczar)
[hHp://blog.magicbeanlab.com/networkanalysis/how-‐should-‐page-‐admins-‐deal-‐with-‐
flame-‐wars/
].
We
had
both
been
learning
about
genera3ng
charts
using
the
ggplot2
library
in
R,
and
swapping
techniques
we
had
learned.
One
chart
in
par3cular
jumped
out
at
me,
not
least
because
the
coding
schemed
it
use
was
so
simple,
yet
it
produced
some
startlingly
original
charts
(to
me
at
least).
The
chart
type
is
a
scaHerplot;
along
the
x-‐axis
we
have
a
3me
base,
in
this
case,
the
‘number’
of
a
post
on
a
Facebook
wall.
On
the
y-‐axis,
we
have
accession
number
of
individusal
pos3ng
on
to
the
wall.
The
first
individual
has
accession
number
1,
the
second
accession
number
2,
and
so
on.
If
someone
returns
to
post
several
3mes,
we
use
the
accession
number
from
the
first
3me
we
saw
them.
This
technique
–
which
we
started
to
call
accession
plots,
or
accession
charts
–
was
completely
new
to
me.
And
very
generalisable.
64](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-64-2048.jpg)
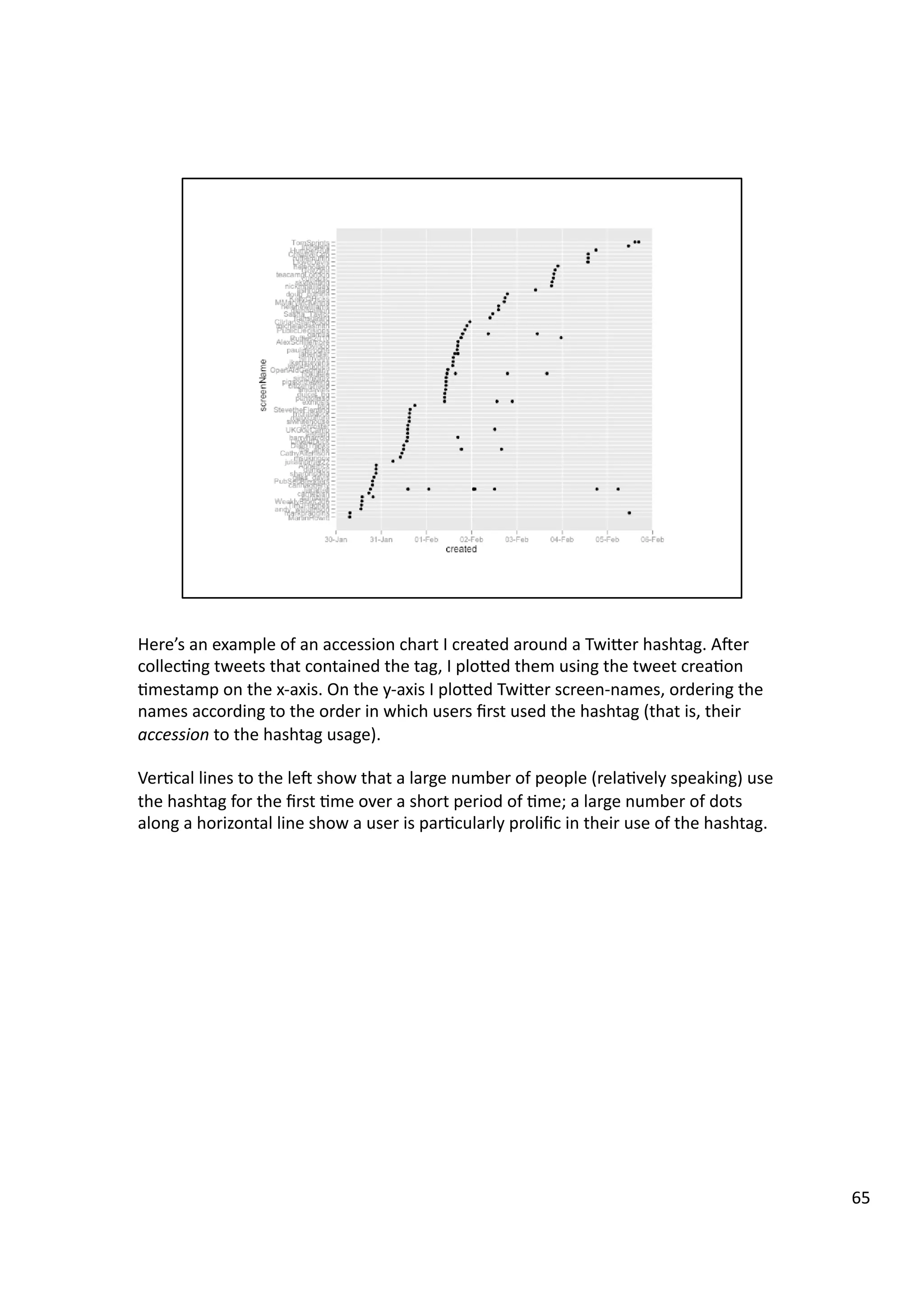
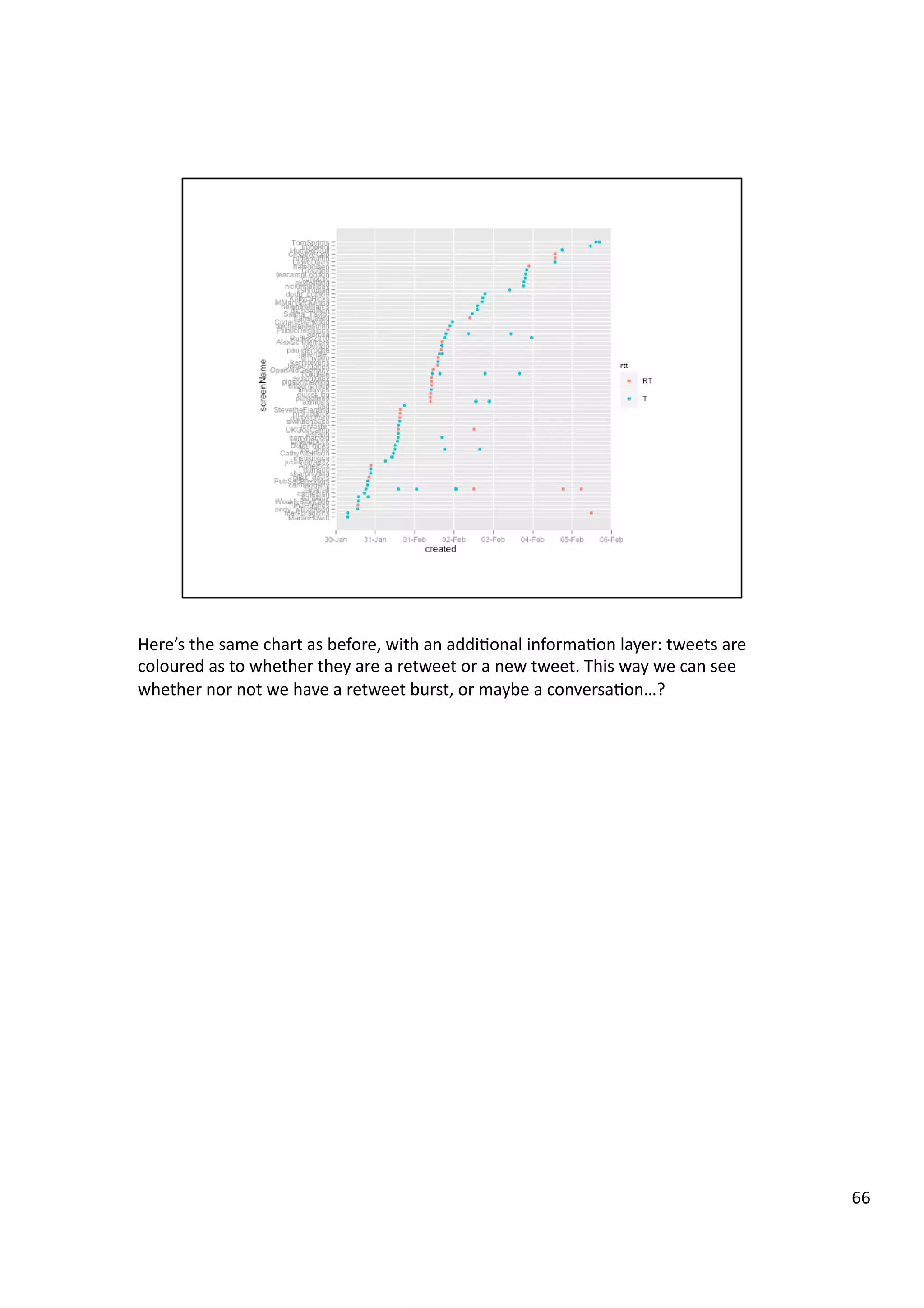
![Here’s
another
TwiHer
chart,
again
using
an
accession
number
device
on
the
y-‐axis,
but
this
3me
related
to
the
accession
number
of
followers
of
an
individual
[hHp://blog.ouseful.info/2013/04/05/es3mated-‐follower-‐
accession-‐charts-‐for-‐twiHer/
].
(If
you
get
the
friends
or
followers
list
of
someone
on
TwiHer,
it
is
in
reverse
chronological
order.)
In
this
chart,
accession
number
1
is
the
first
person
to
follow
the
named
individual,
number
2
the
send
person
to
follow
them,
and
so
on.
The
x-‐axis
the
number
of
days
ago
(from
the
3me
the
chart
was
generated)
that
each
follower
had
first
joined
TwiHer.
The
chart
thus
plots
accession
number
when
following
a
specified
individual
against
3me
since
joining
twiHer
(in
days).
We
see
two
features
in
the
chart:
a) a
sharp
edge
1500
days
ago,
which
corresponds
to
a
3me
when
the
number
of
TwiHer
users
in
general
exploded;
b) A
cut
off
line,
marked
red,
that
provides
an
es3mate
of
the
date
when
follower
with
accession
number
N
started
following
the
target
individual.
Generally,
this
informa3on
is
not
available
–
the
follower
list
orders
the
followers
of
an
individual
but
doesn’t
tell
you
when
they
started
following.
However,
note
that
person
X
cannot
follow
person
Y
before
person
X
joins
TwiHer.
As
accession
number
y-‐increases,
if
we
keep
track
of
the
most
recent
TwiHer
user
crea3on
date
seen
so
far
(the
right
most
point
seen
to
date)
and
plot
that
in
red,
we
get
an
es3mate
of
when
users
started
to
follow
the
target.
(Read
it
this
way:
suppose
that
in
week
M,
a
user
joins
TwiHer
and
immediately
follows
the
target
account
on
date
dM,
gaining
follower
accession
number
aM
for
that
account,
user
with
accession
number
aM+1
can’t
have
started
following
the
target
un3l
at
least
date
dM,
even
if
both
they
and
the
target
account
have
been
on
TwiHer
for
many
months
prior
to
that
date.)
The
line
chart
at
the
boHom
of
the
graph
is
actually
derived
data
that
provides
a
count
of
how
many
people
are
es3mated
to
have
started
following
the
target
on
each
day.
In
this
case
we
see
a
spike
440
or
so
days
ago.
This
chart
actually
corresponds
to
an
MP
–
the
day
they
got
a
sharp
increase
in
followers
was
the
day
they
were
elected.
Looking
up
the
dates
corresponding
to
spikes
on
other
MPs’
follower
accession
chart
in
news
archives
turns
up
other
similar
effects,
as
well
as
scandal
stories
that
hit
the
news,
were
shared
on
TwiHer,
and
lead
to
people
following
the
MP
as
a
result
[hHp://blog.ouseful.info/2013/03/04/what-‐happened-‐then-‐using-‐
approximated-‐twiHer-‐follower-‐accession-‐to-‐iden3fy-‐poli3cal-‐events/
].
Having
shared
this
technique
via
my
blog,
several
other
people
picked
it
up
and
started
using
it
in
more
formal
research
[hHp://mappingonlinepublics.net/2013/07/08/introducing-‐twiHer-‐follower-‐accession-‐graphs/
].
67](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-67-2048.jpg)


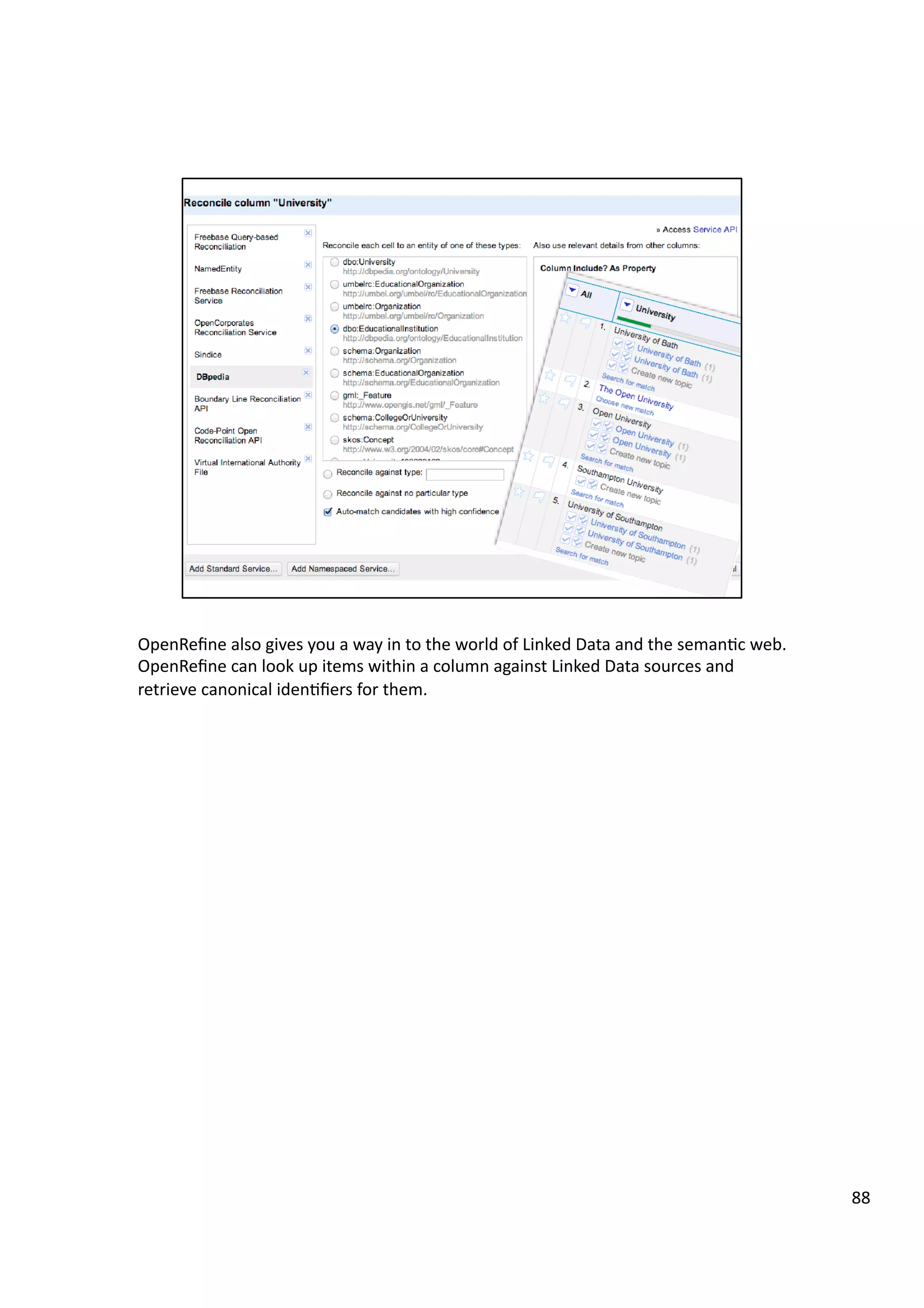
![For
some
years
the
OU
has
been
publishing
open
data
(on
data.open.ac.uk)
about
OU
courses
and
resources.
One
of
the
datasets
lists
courses
and
courses
they
are
related
to.
Grabbing
a
copy
of
this
whole
dataset,
then
graphing
connec3ons
between
courses
that
are
related
to
each
other
and
mapping
the
result
using
a
force
directed
network
layout
algorithm
that
tries
to
posi3on
nodes
that
are
connected
to
each
other
close
to
each
other,
we
can
generate
a
map
that
shows
how
OU
courses
relate
to/cluster
with
each
other
[hHp://blog.ouseful.info/2011/01/30/open-‐university-‐
undergraduate-‐module-‐map/
].
Try
gegng
such
a
macroscopic
view
from
the
OU
courses
website…
70](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-70-2048.jpg)
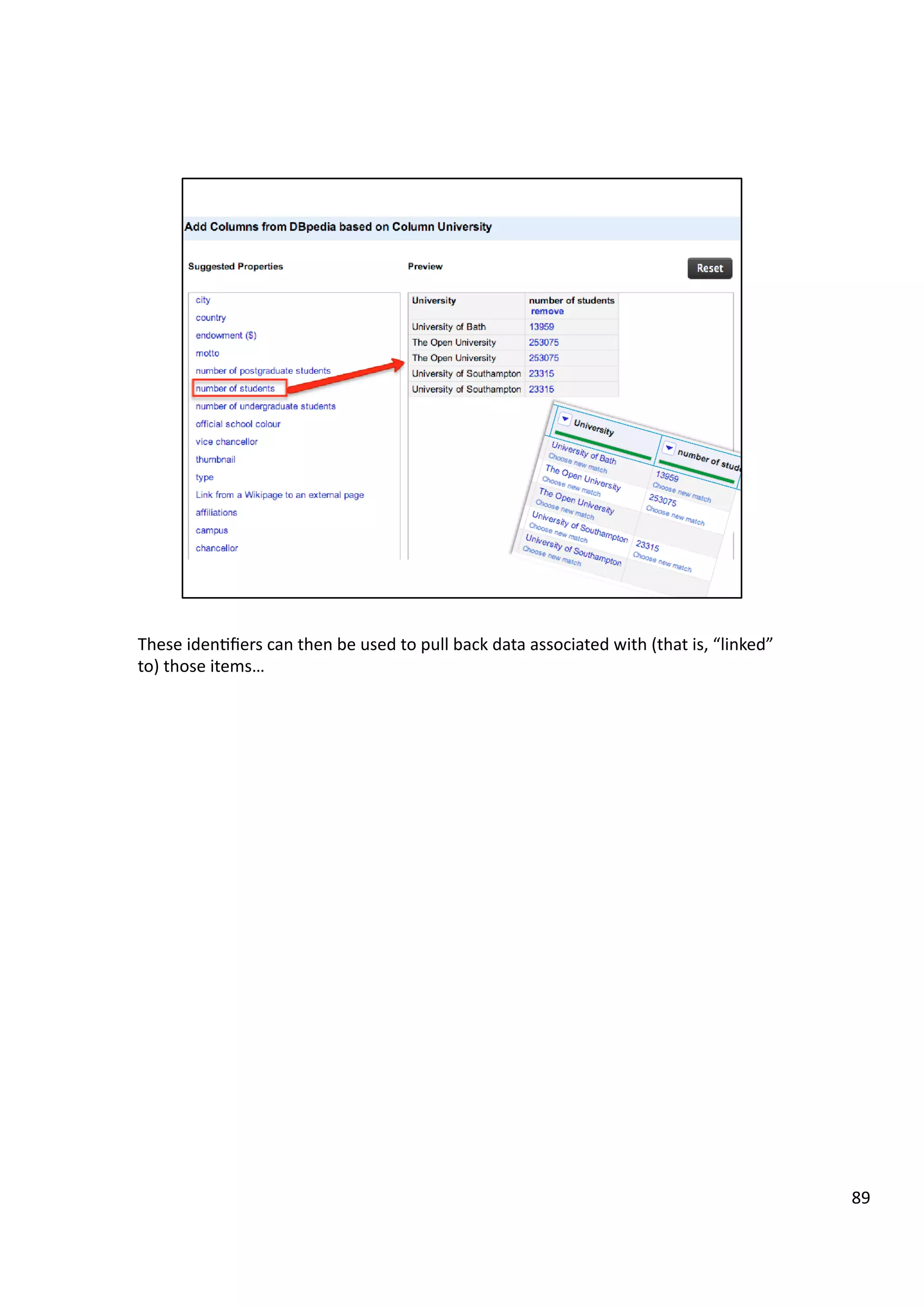
![This
is
a
macroscopic
view
over
MP
vo3ng
behaviour
over
a
parliament
several
governments
ago
(data
was
grabbed
from
the
public
whip
website,
I
think?).
Each
row
is
an
MP,
the
rows
grouped
by
party
(Labour,
the
government
at
the
3me,
is
the
top
block;
then
LibDems,
then
Conserva3ves,
then
Other).
Each
column
is
a
separate
division/vote
in
the
House
of
Commons.
The
colour
show
whether
the
MP
voted
for
or
against
the
mo3on
(I
think?!)
[
hHp://blog.ouseful.info/2010/04/22/visualising-‐
whether-‐the-‐libdems-‐side-‐with-‐the-‐tories-‐or-‐labour-‐in-‐parliamentary-‐votes/
].
Once
you
get
your
eye
in,
you
see
that
the
LibDems
tended
to
vote
with
the
Conserva3ves
in
many
case.
When
you
really
get
your
eye
in,
you
can
also
spot
rebels.
The
black
horizontal
lines
are
where
an
MP
didn’t
vote
–
possibly
because
they’re
a
minister
doing
other
things…
(This
was
actually
an
interac3ve
visualisa3on
generated
using
Processing
–
you
could
hove
over
points
to
find
the
name
of
each
MP,
the
par3cular
vote,
etc.)
The
idea
of
this
visualisa3on
nd
the
summaries
and
analy3c
ques3ons
is
suggests
is
part
of
the
value
of
this
piece,
rather
than
it’s
u3lity
as
a
visualisa3on
of
the
data
itself.
Here
are
some
other
experiments
using
another
source
of
vote
data,
this
3me
from
general
elec3ons:
hHp://blog.ouseful.info/2010/05/03/playing-‐with-‐processing-‐arc-‐
and-‐general-‐elec3on-‐data-‐2005/
71](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-71-2048.jpg)
![Every
presenta3on
I
do,
I
try
to
get
some
Formula
One
data
in!
This
is
data
grabbed
from
the
McLaren
live
dashboard,
an
online
interac3ve
that
McLaren
ran
for
several
years
that
streamed
telemetry
data
rela3ng
to
speed,
“g-‐
force”,
throHle
and
brake
control,
gear,
distance
round
circuit
and
la3tude
and
longitude
of
the
two
McLaren
cars
during
race
weekends
[
hHp://blog.ouseful.info/
2010/04/07/f1-‐data-‐junkie-‐driver-‐dna/
].
The
line
charts
on
the
lee
are
a
typical
display.
The
right
charts
I
called
DNA
charts
–
distance
round
the
circuit
is
on
the
horizontal
x-‐axis,
lap
number
on
the
y-‐axis.
The
charts
show
the
remarkable
consistency
of
the
drivers.
The
top,
blue
strip
shows
the
gear
(1
to
7);
the
green
strip
shows
the
throHle
pedal
depression
(0-‐100%),
and
the
red
strip
shows
the
brake
(0-‐100%).
The
light
blue
strip
is
a
composite
of
the
previous
three
strips.
The
whiter
the
pixel,
the
closer
it
is
to
100%
throHle
in
7th
gear
with
no
braking.
The
boHom
two
traces
show
the
longitudinal
and
lateral
g-‐force
respec3vely.
For
the
longitudinal
trace,
red
shows
braking
–
being
forced
into
the
steering
wheel;
green
shows
accelera3on
–
being
forced
back
into
your
seat.
You’ll
see
the
greatest
g-‐force
under
braking
occurs
when
the
brakes
are
slapped
full
on…
(the
red
bits
in
the
third
and
fieh
traces
line
up).
For
the
la3tudinal
g-‐force,
the
red
shows
the
driving
being
flung
to
the
lee
(i.e.
right
hand
corner),
the
green
shows
them
being
pushed
out
to
the
right.
72](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-72-2048.jpg)
![We
can
also
pair
the
DNA
charts
of
the
two
McLaren
drivers,
and
then
look
for
differences…
[
hHp://blog.ouseful.info/2010/04/18/f1-‐data-‐junkie-‐mclaren-‐driver-‐
comparison-‐snapshots/
]
Midway
round
the
circuit,
we
no3ce
the
NGear
traces
markedly
differ,
for
example.
73](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-73-2048.jpg)








![If
you
haven’t
made
an
FOI
request
before,
and
you’re
happy
for
it
to
be
made
publicly,
whatdotheyknow.com
makes
it
easy:
select
the
pubic
organisa3on
you’d
like
to
make
a
request
to,
and
you
can
send
an
email
directly
to
the
right
address.
Any
responses
are
managed
by
the
service.
If
you
browse
through
responses
to
requests,
you
see
many
of
them
include
data
files
(CSV
files
or
Excel
spreadsheets).
A
quick
hack
I
produced
[hHp://blog.ouseful.info/
2012/04/28/the-‐foi-‐route-‐to-‐real-‐fake-‐open-‐data-‐via-‐whatdotheyknow/
]
indexed
the
requests
that
returned
data
files
so
I
could
use
it
as
an
index
of
FOId
data.
(Note
that
just
because
data
is
released
under
FOI
it
doesn’t
mean
it’s
openly
licensed…)
Not
all
FOI
requests
are
made
through
WhatDoTheyKnow,
of
course
(journalists
wouldn’t
take
to
make
requests
made
as
part
of
an
inves3ga3on
available
via
a
public
service
where
other
people
can
see
what
they
are
reques3ng).
Informa3on
about
FOI
requests
made
to
organisa3ons
is,
however,
public
informa3on…
Some
organisa3ons
rou3nely
publish
a
disclosure
log,
where
they
publish
informa3on
about
requests
and
responses
with
personal
informa3on
removed.
In
other
cases,
you
may
have
to
FOI
the
same
informa3on…
83](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-83-2048.jpg)
![The
Guardian
Data
Store
has
been
republishing
public
data
via
Google
Spreadsheets
for
some
3me.
Each
year,
it
publishes
the
data
used
for
its
university
rankings
tables.
This
example
[hHp://blog.ouseful.info/2012/09/04/filtering-‐guardian-‐university-‐data-‐
every-‐which-‐way-‐you-‐can/
]
shows
how
I
used
the
Google
Visualisa3on
API
to
provide
a
quick
tool
for
exploring
the
rankings
based
on
selec3vely
filtering
across
each
of
the
ranking
factors.
This
year,
I
used
the
R
Shiny
library
to
produce
an
interac3ve
explorer
using
R:
hHp://
blog.ouseful.info/2013/06/21/disposable-‐visual-‐data-‐explorers-‐with-‐shiny-‐guardian-‐
university-‐tables-‐2014/
84](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-84-2048.jpg)
![If
you
don’t
feel
comfortable
building
your
own
applica3on
from
lines
of
code
(even
if
it
only
takes
10
or
20
lines
of
code
you
can
largely
copy
and
paste
from
other
people
who’ve
done
similar
things
before…)
tools
like
Google
Fusion
Tables
allow
you
to
interac3vely
explore
quite
large
datasets.
The
example
shown
here
provides
an
environment
for
exploring
chari3es
data
[
hHp://blog.ouseful.info/2013/05/01/a-‐
quick-‐peek-‐at-‐some-‐chari3es-‐data/
].
Whilst
Fusion
Tables
look
like
spreadsheets,
they
have
several
benefits:
1) they
can
be
used
to
store
much
larger
datasets
than
you
can
load
in
to
a
spreadsheet;
2) it’s
easy
to
merge
different
tables
that
share
a
common
column
(hence
“fusion”
tables?).
If
VLOOKUP
confuses
you,
this
makes
it
much
easier
and
works
across
tables
too;
3) you
can
add
filters
to
tables
to
see
just
the
informa3on
you
want;
4) genera3ng
pivot
table
style
summary
reports
is
easy
(and
these
work
across
filtered
data
too);
5) genera3ng
charts
is
easy
(and
these
work
across
filtered
data
too);
6) If
you
address
data,
Google
Fusion
Tables
can
geocode
it
for
you
too,
so
you
can
add
markers
to
a
map,
and
colour
them
by
data
values;
7)
if
you
have
shapefile
data
or
data
that
can
be
merged
with
shapefiles
(eg
MP
cons3tuencies),
you
can
use
Google
Fusion
Tables
to
make
choropleth
maps.
85](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-85-2048.jpg)









![Means,
Opportunity
–
and
Mo3ve.
Why
bother?
Not
for
promo3on
[hHp://blog.ouseful.info/2010/08/26/in-‐for-‐a-‐penny-‐
in-‐for-‐a-‐pound-‐my-‐promo3on-‐case-‐for-‐support/
x
several
aHempts
so
far;
one
reason
I
dropped
to
4
days
per
week.].
So
why?
106](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-106-2048.jpg)









![Exploring
workflows
that
embed
research
in
context,
exploring
tools
that
help
make
research
more
readable,
more
reproducible,
more
transparent,
seems
to
me
to
be
important
from
an
ed
tech
perspec3ve.
Notebook
style
working
works
for
me,
in
this
sense
[
hHp://blog.ouseful.info/2014/02/13/doodling-‐with-‐ipython-‐notebooks-‐for-‐
educa3on/
].
Have
you
tried
it
yet?
[
hHp://blog.ouseful.info/2014/02/26/3me-‐to-‐
drop-‐calculators-‐in-‐favour-‐of-‐notebook-‐programming/
]
Or
virtual
machines?
[
hHp://blog.ouseful.info/2013/12/02/packaging-‐soeware-‐for-‐
distance-‐learners-‐vms-‐101/
]
Use
either
as
context,
maybe,
for
some
guerrilla
research
of
your
own.
If
anyone
asks,
you’re
evalua3ng
the
notebook
way
of
working.
But
as
you
and
I
know,
that’s
also
to
provide
cover…
(Which
reminds
me:
have
I
men3oned
sabotage
yet…
or
corporate
foolery?
hHp://
blog.ouseful.info/2008/12/09/corporate-‐foolery-‐and-‐the-‐abilene-‐paradox/
)
By
the
by,
the
screen
shot
demonstrates
another
excuse
for
ac3vity.
Replica3ng
(and
in
this
case,
not)
a
piece
of
outstanding
work….
117](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-117-2048.jpg)



![Last
tool.
Last
toy.
This
is
Gephi
[
hHp://gephi.org
]
–
a
cross-‐playorm
desktop
tool
that’s
great
for
genera3ng
effec3ve
network
visualisa3ons.
I
have
some
tutorials
and
sample
datasets
if
anyone
wants
to
give
it
a
whirl…[
hHp://blog.ouseful.info/2012/11/09/drug-‐deal-‐
network-‐analysis-‐with-‐gephi-‐tutorial/
Or
do
some
guerrilla
research
around
your
Facebook
network
by
googling
this:
site:blog.ouseful.info
in7tle:"facebook
network”
Alterna3vely,
see
if
what
they
like
reveals
anything
about
you…
hHp://
blog.ouseful.info/2012/01/04/social-‐interest-‐posi3oning-‐visualising-‐facebook-‐friends-‐
likes/
]
122](https://image.slidesharecdn.com/guerrillaresaearch-wtf-140320145503-phpapp01/75/Guerrilla-resaearch-wtf-122-2048.jpg)







The document discusses the concept of "guerrilla research" through exploring various definitions and examples. It considers guerrilla research as potentially unconventional research that challenges accepted norms or paradigms through novel hypotheses or untried techniques. Small grants are discussed as a traditional form of smaller-scale research that still requires considerable overhead to submit bids. The etymology of "guerrilla" suggests guerrilla research may refer to "little research" on a smaller, resistance-like scale compared to larger conventional projects.















































