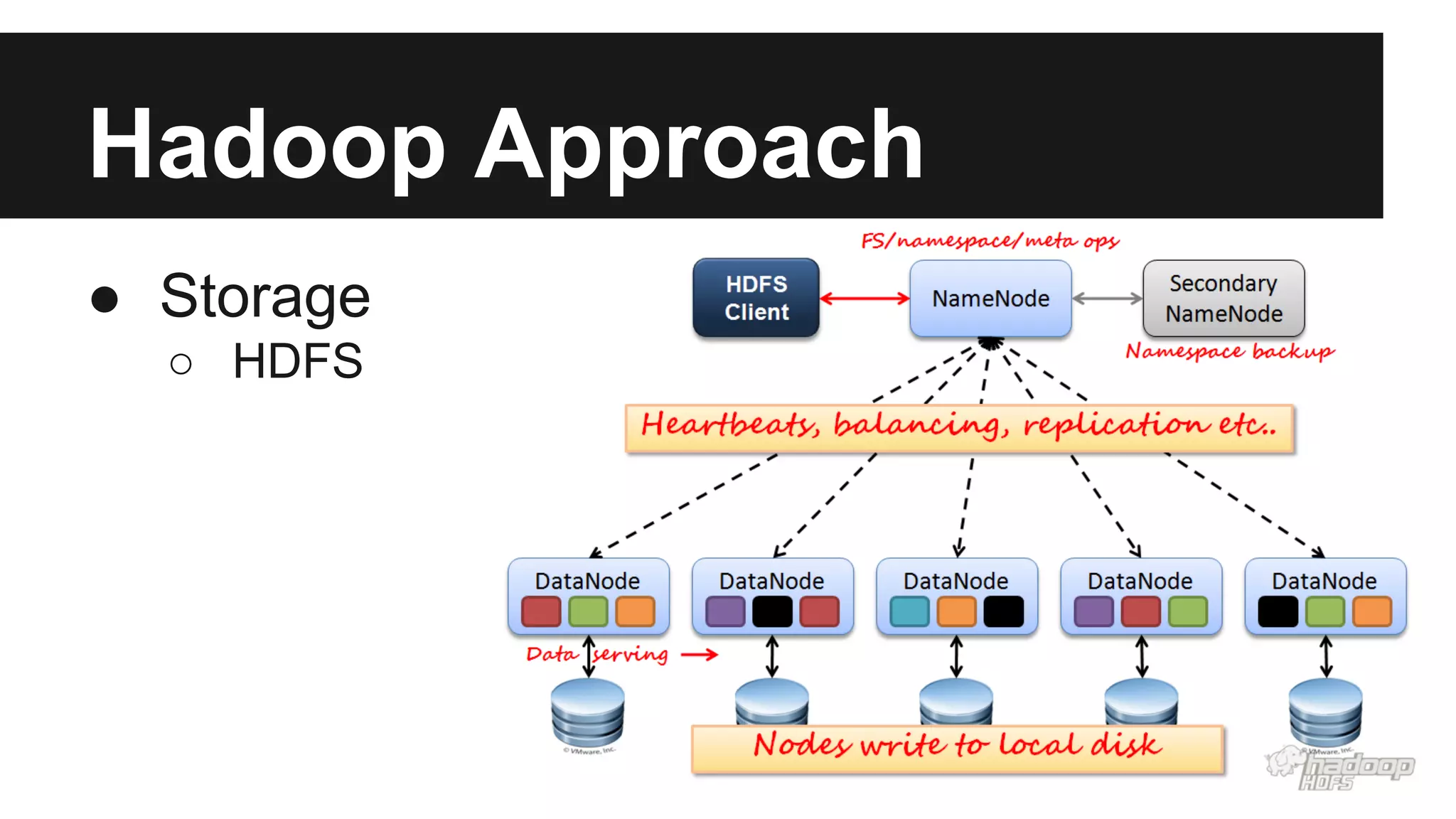
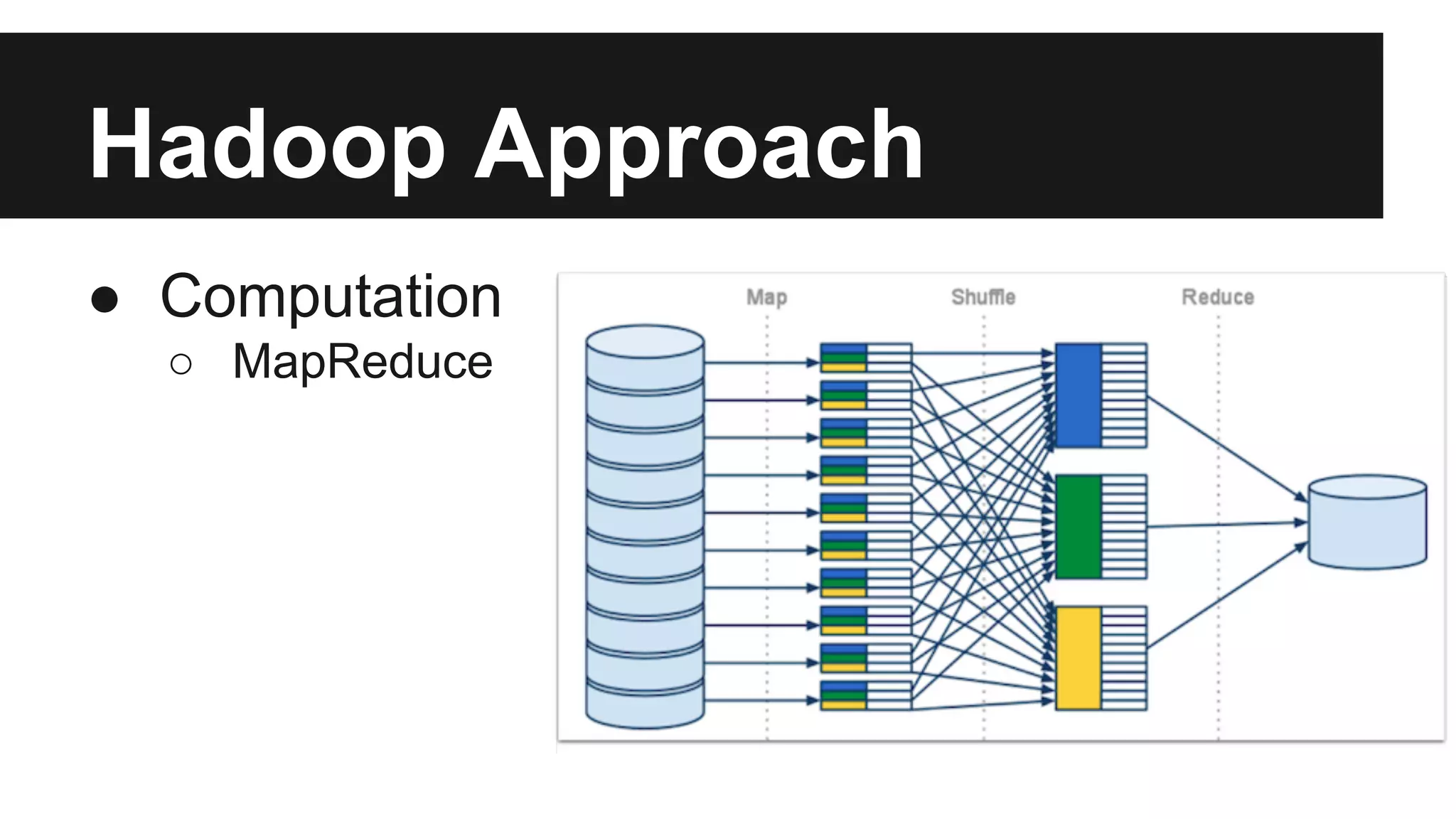
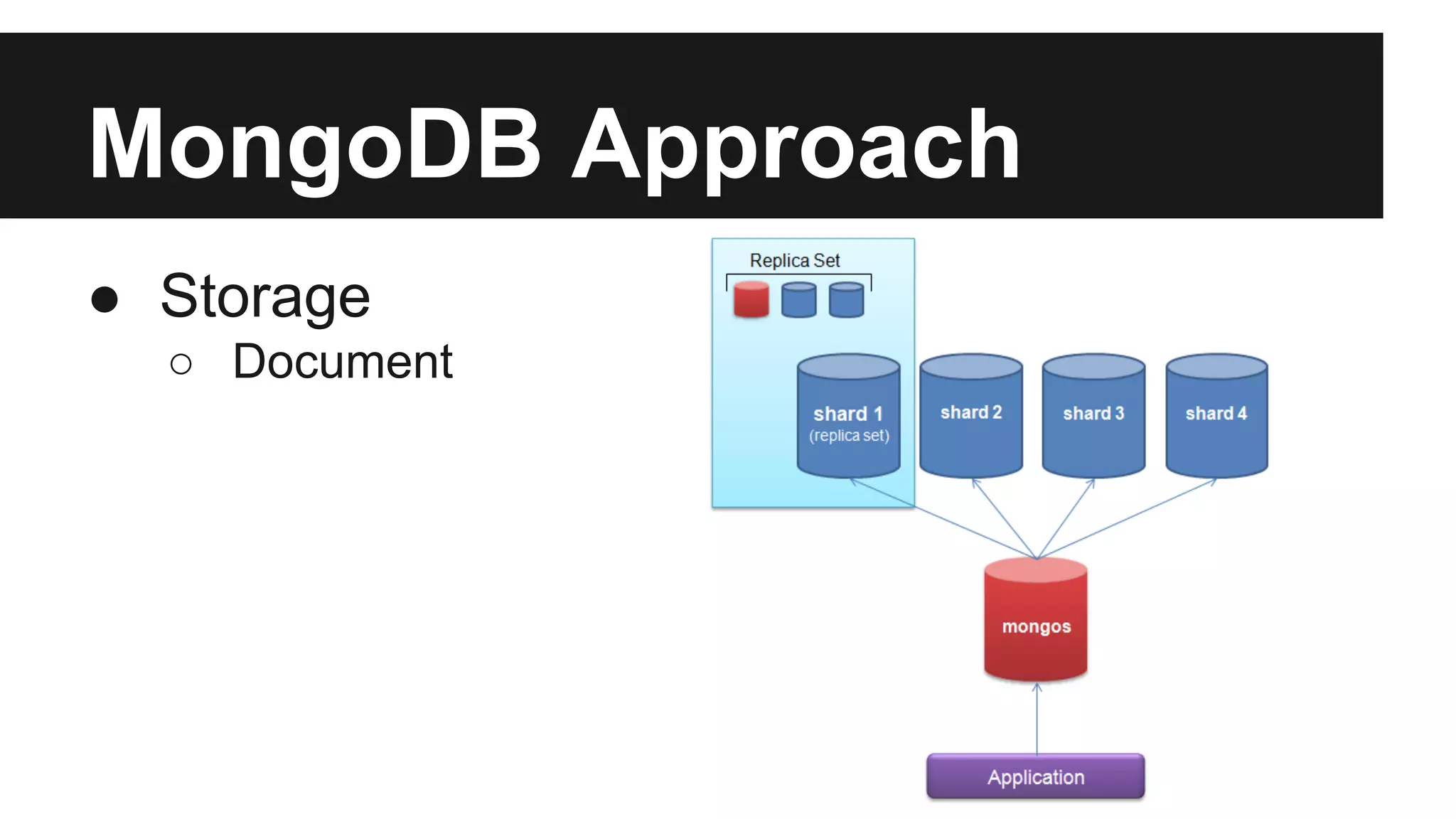
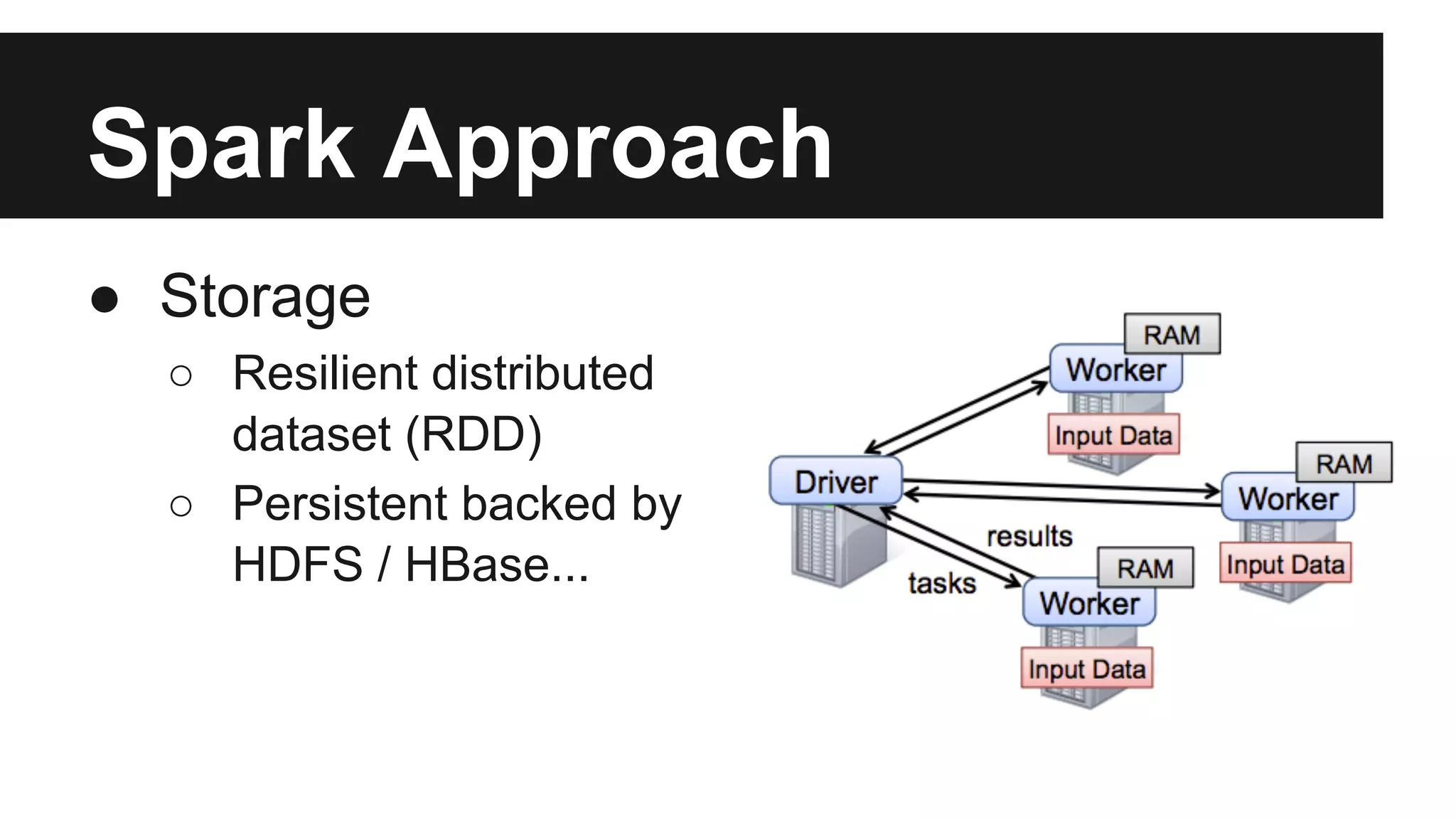
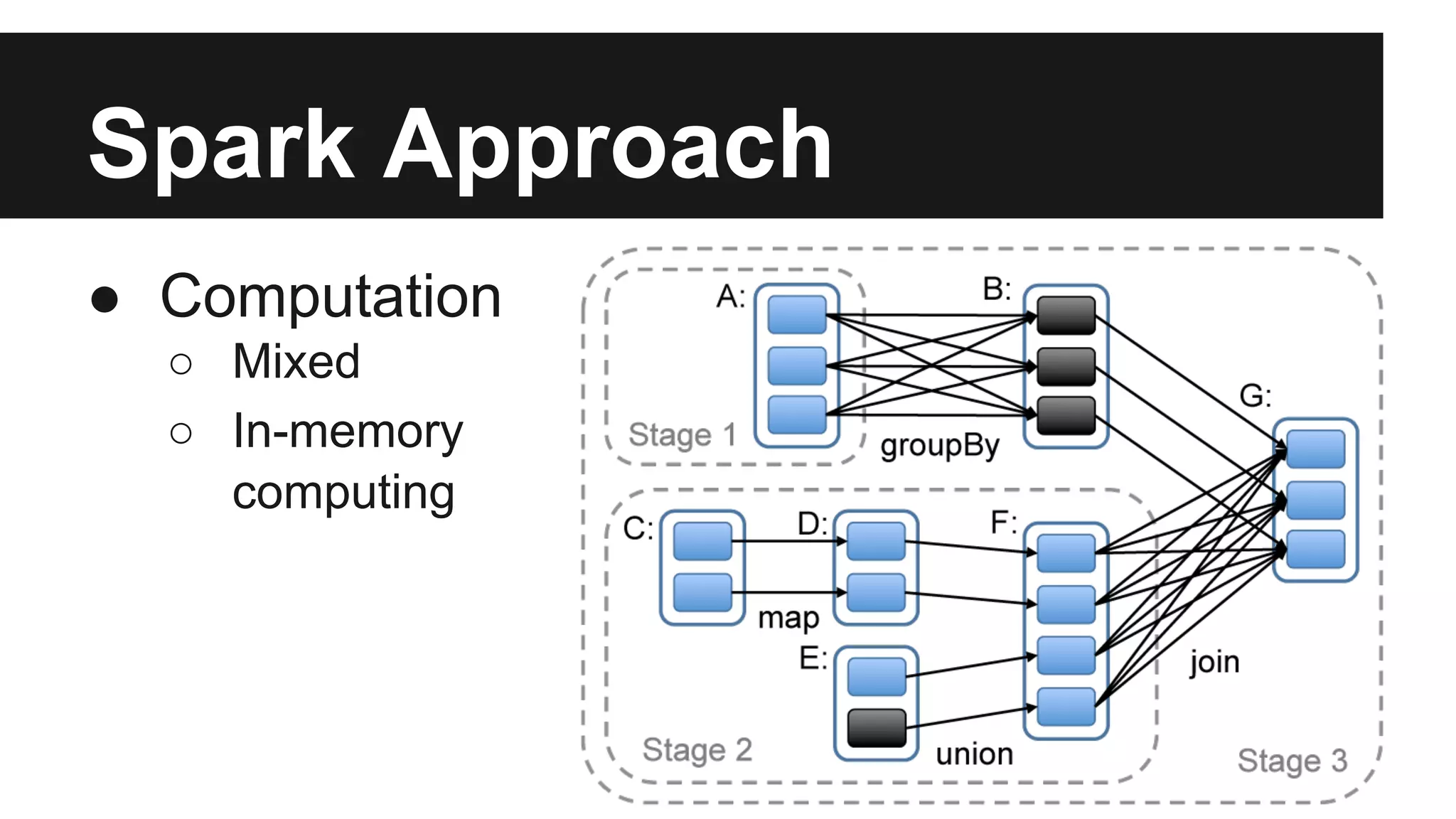
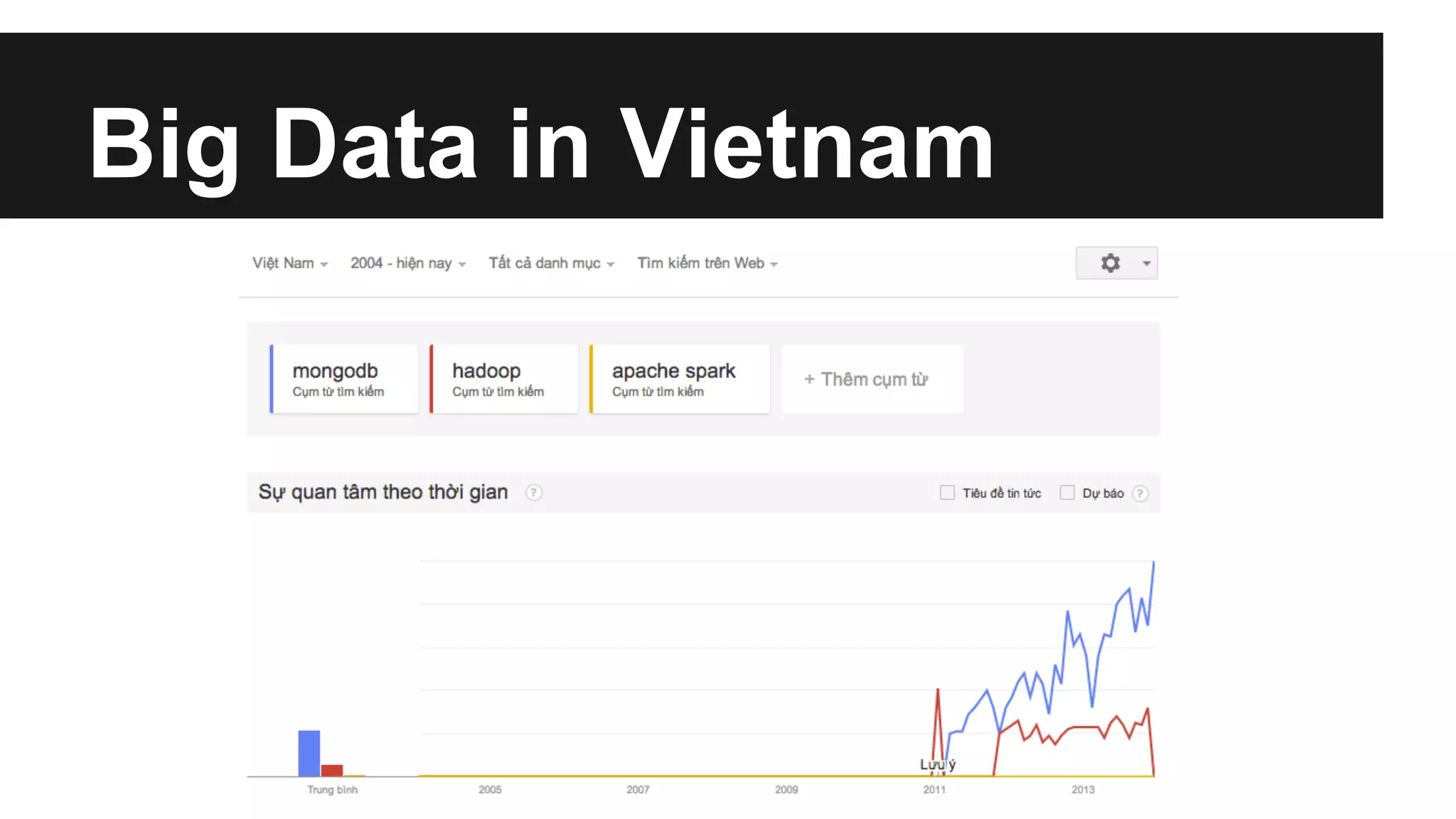
This document discusses big data and different approaches to processing large datasets. It introduces how internet-enabled devices generate huge amounts of data daily. Storing and processing 10 terabytes of data on Amazon EC2 is then used as an example, showing how using multiple machines in parallel can process the data much faster than a single machine. Common approaches using Hadoop, MongoDB, and Spark are overviewed, along with examples of how each can be used for storage and computation. A demo of setting up an Amazon cluster and processing Wikipedia data with Hadoop and Spark is proposed. Issues around big data in Vietnam are also briefly covered.