Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Minero Aoki
PDF, PPTX
8,536 views
AWS Casual 02: ふつうのRedshiftパフォーマンスチューニング
ふつうのRedshiftパフォーマンスチューニング @ AWS Casual 02, 2014-04-18
Technology
◦
Read more
36
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
PPTX
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
PPTX
Amazon Redshift ことはじめ
by
Shiro Miyazaki
PDF
Amazon Redshiftへの移行方法と設計のポイント(db tech showcase 2016)
by
Amazon Web Services Japan
PDF
はじめてのAmazon Redshift
by
Jun Okubo
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PDF
Windows Azure HDInsight サービスの紹介
by
Kuninobu SaSaki
PDF
FukuokaCloud_Azure
by
Shinichiro Isago
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
Amazon Redshift ことはじめ
by
Shiro Miyazaki
Amazon Redshiftへの移行方法と設計のポイント(db tech showcase 2016)
by
Amazon Web Services Japan
はじめてのAmazon Redshift
by
Jun Okubo
事例で学ぶApache Cassandra
by
Yuki Morishita
Windows Azure HDInsight サービスの紹介
by
Kuninobu SaSaki
FukuokaCloud_Azure
by
Shinichiro Isago
What's hot
PDF
Amazon Aurora Deep Dive (db tech showcase 2016)
by
Amazon Web Services Japan
PPT
Webアプリケーションから見たCassandra
by
2t3
PDF
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PPTX
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
PDF
AWS Black Belt Techシリーズ Amazon Redshift
by
Amazon Web Services Japan
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PDF
(LT)Spark and Cassandra
by
datastaxjp
PPT
Devsumi2013【15-e-5】NoSQLの野心的な使い方 ~Apache Cassandra編~
by
kishimotosc
PDF
Couchbase introduction-20150611
by
Couchbase Japan KK
PDF
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS
by
Yahoo!デベロッパーネットワーク
PDF
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
PDF
Cassandraのトランザクションサポート化 & web2pyによるcms用プラグイン開発
by
kishimotosc
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
PDF
Db tech showcase 2016
by
datastaxjp
PDF
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
NoSQLに関するまとめ
by
Gosuke Miyashita
PDF
[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...
by
Insight Technology, Inc.
PDF
スマートフォン×Cassandraによるハイパフォーマンス基盤の構築事例
by
terurou
PDF
リペア時間短縮にむけた取り組み@Yahoo! JAPAN #casstudy
by
Yahoo!デベロッパーネットワーク
Amazon Aurora Deep Dive (db tech showcase 2016)
by
Amazon Web Services Japan
Webアプリケーションから見たCassandra
by
2t3
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
AWS Black Belt Techシリーズ Amazon Redshift
by
Amazon Web Services Japan
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
(LT)Spark and Cassandra
by
datastaxjp
Devsumi2013【15-e-5】NoSQLの野心的な使い方 ~Apache Cassandra編~
by
kishimotosc
Couchbase introduction-20150611
by
Couchbase Japan KK
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS
by
Yahoo!デベロッパーネットワーク
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
Cassandraのトランザクションサポート化 & web2pyによるcms用プラグイン開発
by
kishimotosc
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
Db tech showcase 2016
by
datastaxjp
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
NoSQLに関するまとめ
by
Gosuke Miyashita
[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...
by
Insight Technology, Inc.
スマートフォン×Cassandraによるハイパフォーマンス基盤の構築事例
by
terurou
リペア時間短縮にむけた取り組み@Yahoo! JAPAN #casstudy
by
Yahoo!デベロッパーネットワーク
Similar to AWS Casual 02: ふつうのRedshiftパフォーマンスチューニング
PDF
[AWSマイスターシリーズ] Amazon Redshift
by
Amazon Web Services Japan
PPTX
Amazon Redshift - Create an Amazon Redshift Cluster
by
FlyData Inc.
PDF
[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...
by
Insight Technology, Inc.
PDF
新宿鮫もくもく勉強会第10回目
by
晋也 古渡
PDF
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar Amazon Redshift
by
Amazon Web Services Japan
PDF
データマート対応した話
by
株式会社オプト 仙台ラボラトリ
[AWSマイスターシリーズ] Amazon Redshift
by
Amazon Web Services Japan
Amazon Redshift - Create an Amazon Redshift Cluster
by
FlyData Inc.
[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...
by
Insight Technology, Inc.
新宿鮫もくもく勉強会第10回目
by
晋也 古渡
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
AWS Black Belt Online Seminar Amazon Redshift
by
Amazon Web Services Japan
データマート対応した話
by
株式会社オプト 仙台ラボラトリ
AWS Casual 02: ふつうのRedshiftパフォーマンスチューニング
1.
ふつうのRedshift パフォーマンスチューニング 青木峰郎
2.
Redshiftについて
3.
並列RDBMS
4.
Redshiftのアーキテクチャ compute node 0 compute
node 1 leader node compute node 2 compute node 3
5.
並列単位はNode Slice Node 0
Node 1 Node 2 Slice 0 Slice 1 Slice 2 Slice 3 Slice 4 Slice 5
6.
行は分散キーのハッシュ値で決定する node slice 0
node slice 1 node slice 2 node slice 3 time user_id item_id 1398579843 289750 19375
7.
本題
8.
なんかシステムもいろいろ あるじゃないですか
9.
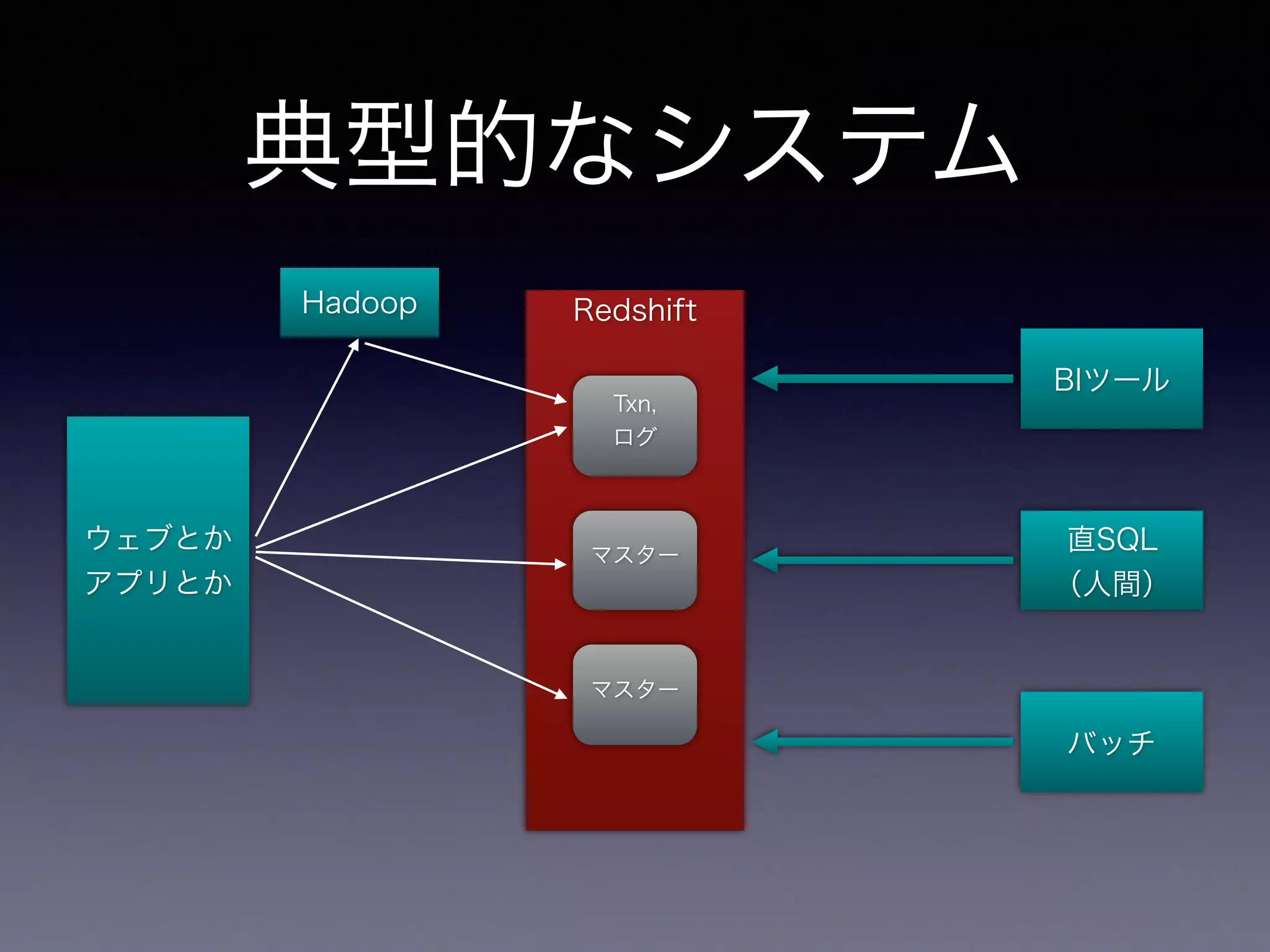
典型的なシステム ウェブとか アプリとか Redshift BIツール Txn, ログ マスター マスター Hadoop 直SQL (人間) バッチ
10.
処理の種類 • オンライン(OLTP)マイクロ秒、更新あり • オンライン(OLAP
/ tactical)0.1∼数秒 • オンライン(OLAP / strategic)数秒∼数分 • バッチ 数分∼数時間
11.
OLTP 無理
12.
具体的に言うと… • リクエストの並列度が高いのは無理 • 秒間2桁以上はやめとけ •
高頻度・細粒度で更新するのは無理 • 5分間隔の追加くらいがギリ
13.
Tactical Query • sortkeyに当てろ •
テーブルサイズを実測して一番小さくしろ • 事前ジョインはあんま効かない(集計はOK)
14.
Strategic, Batch ここからが本番
15.
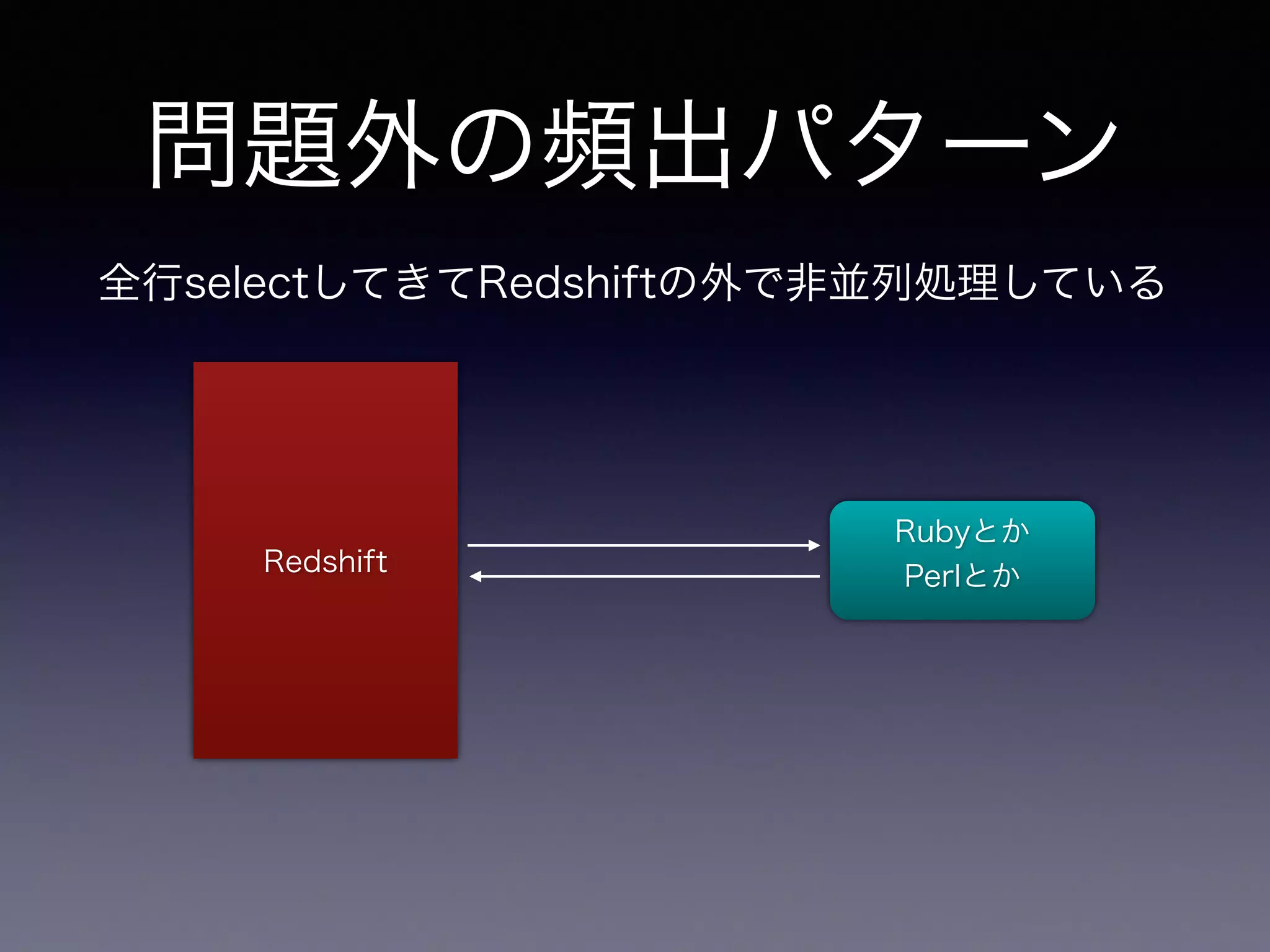
問題外の頻出パターン Redshift 全行selectしてきてRedshiftの外で非並列処理している Rubyとか Perlとか
16.
やめて!
17.
データを移動したら負け
18.
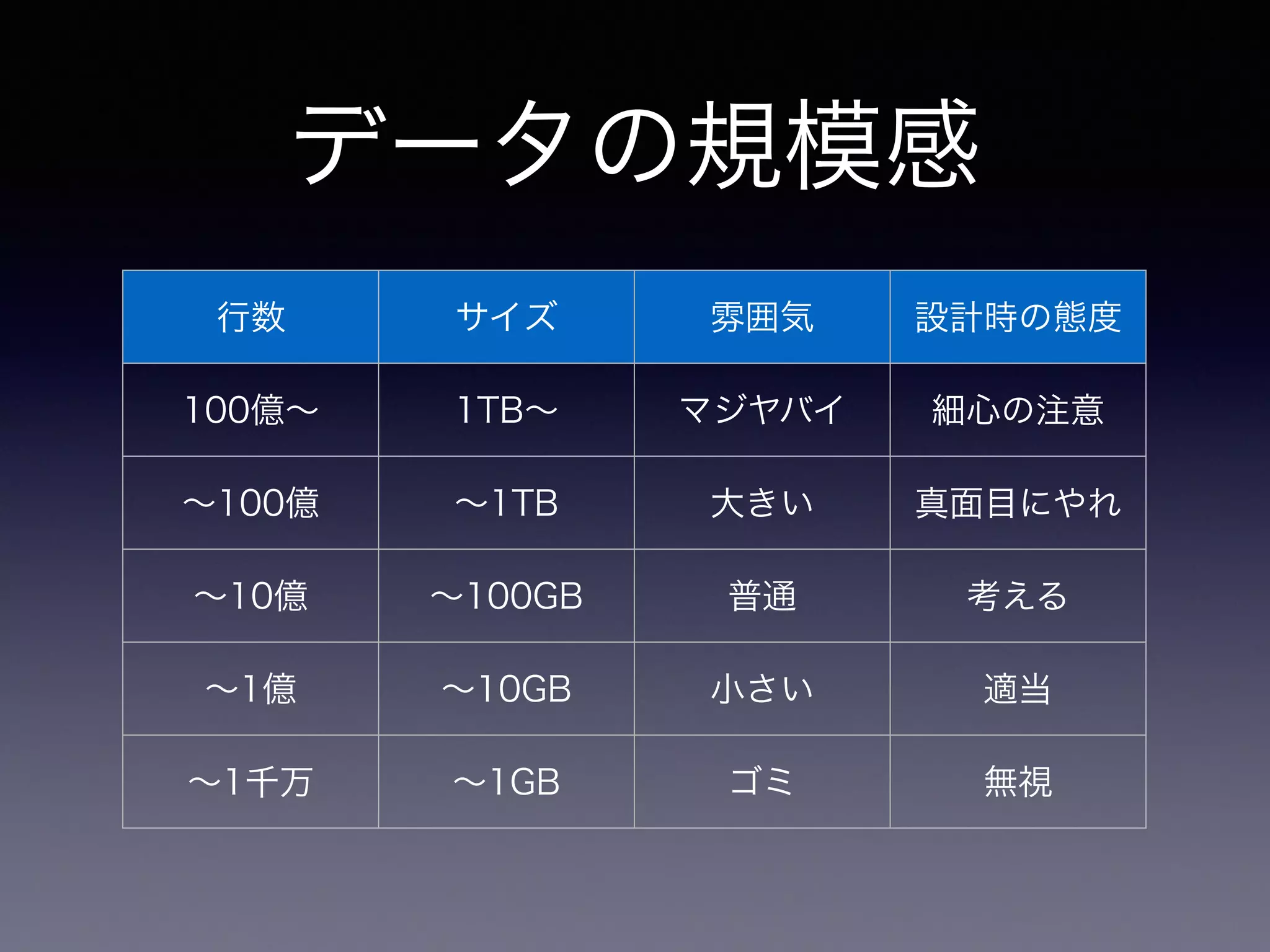
データの規模感 行数 サイズ 雰囲気
設計時の態度 100億∼ 1TB∼ マジヤバイ 細心の注意 ∼100億 ∼1TB 大きい 真面目にやれ ∼10億 ∼100GB 普通 考える ∼1億 ∼10GB 小さい 適当 ∼1千万 ∼1GB ゴミ 無視
19.
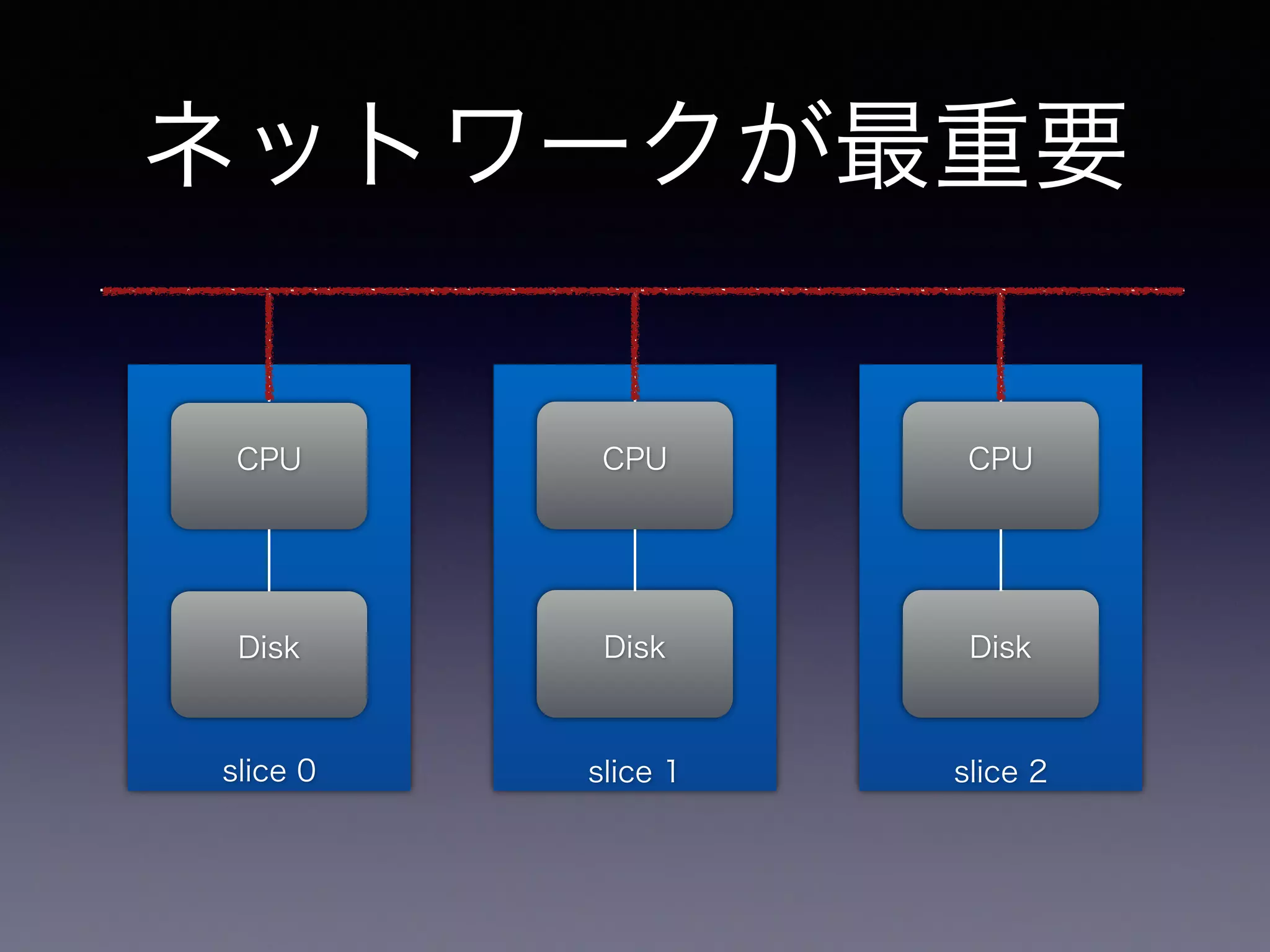
ネットワークが最重要 slice 0 CPU Disk slice 1 CPU Disk slice
2 CPU Disk
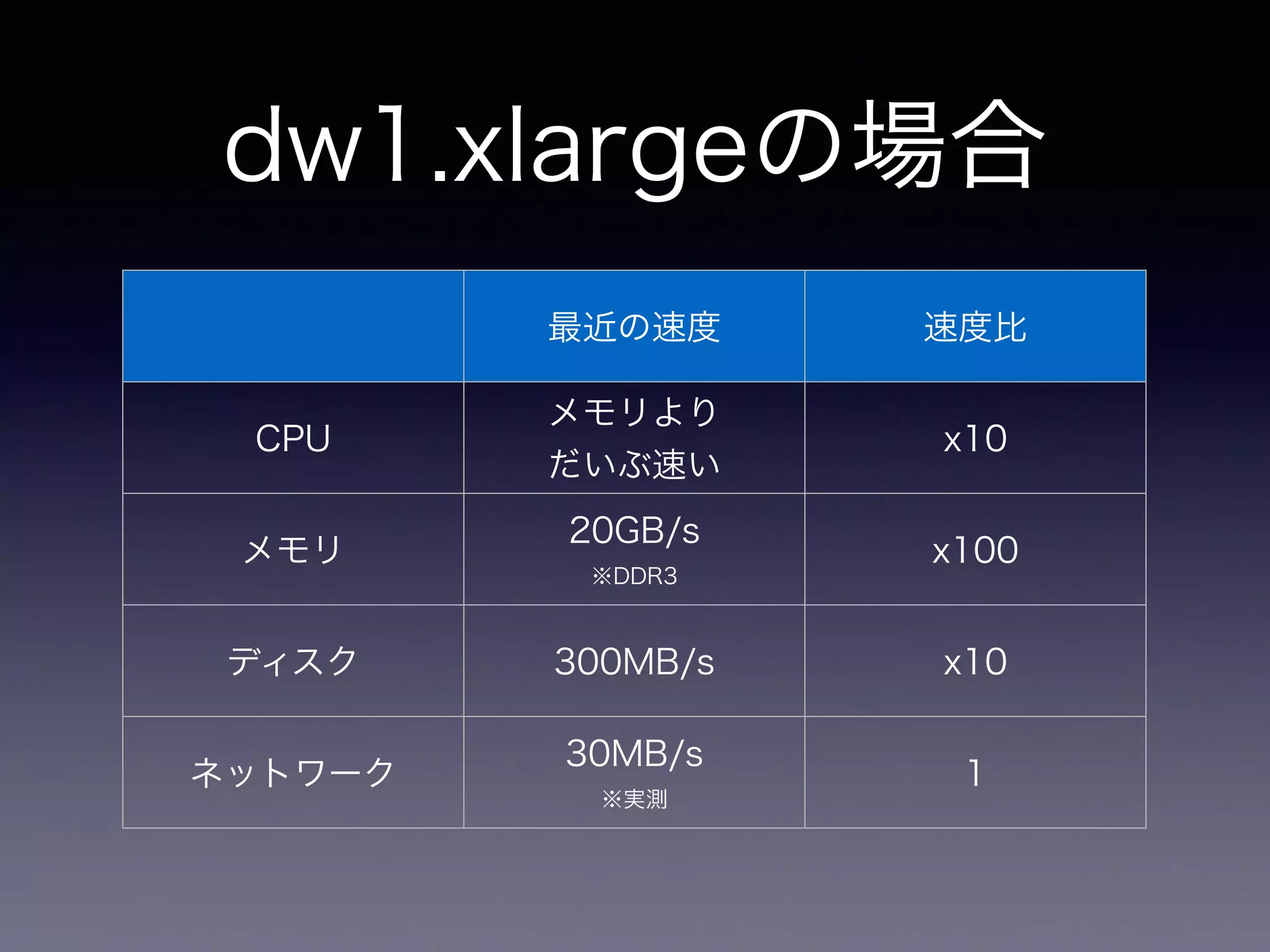
20.
dw1.xlargeの場合 最近の速度 速度比 CPU メモリより だいぶ速い x10 メモリ 20GB/s ※DDR3 x100 ディスク 300MB/s
x10 ネットワーク 30MB/s ※実測 1
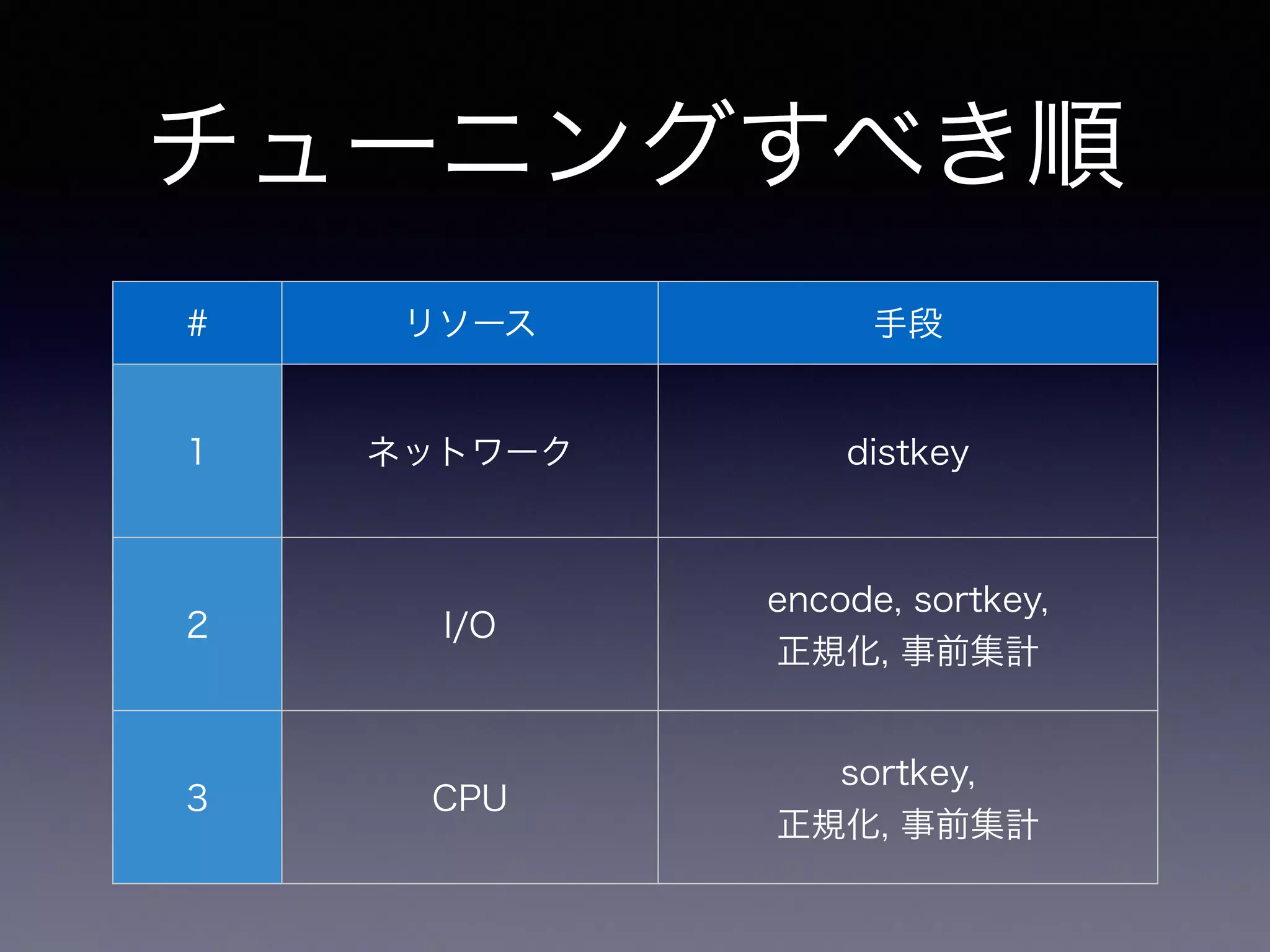
21.
チューニングすべき順 # リソース 手段 1
ネットワーク distkey 2 I/O encode, sortkey, 正規化, 事前集計 3 CPU sortkey, 正規化, 事前集計
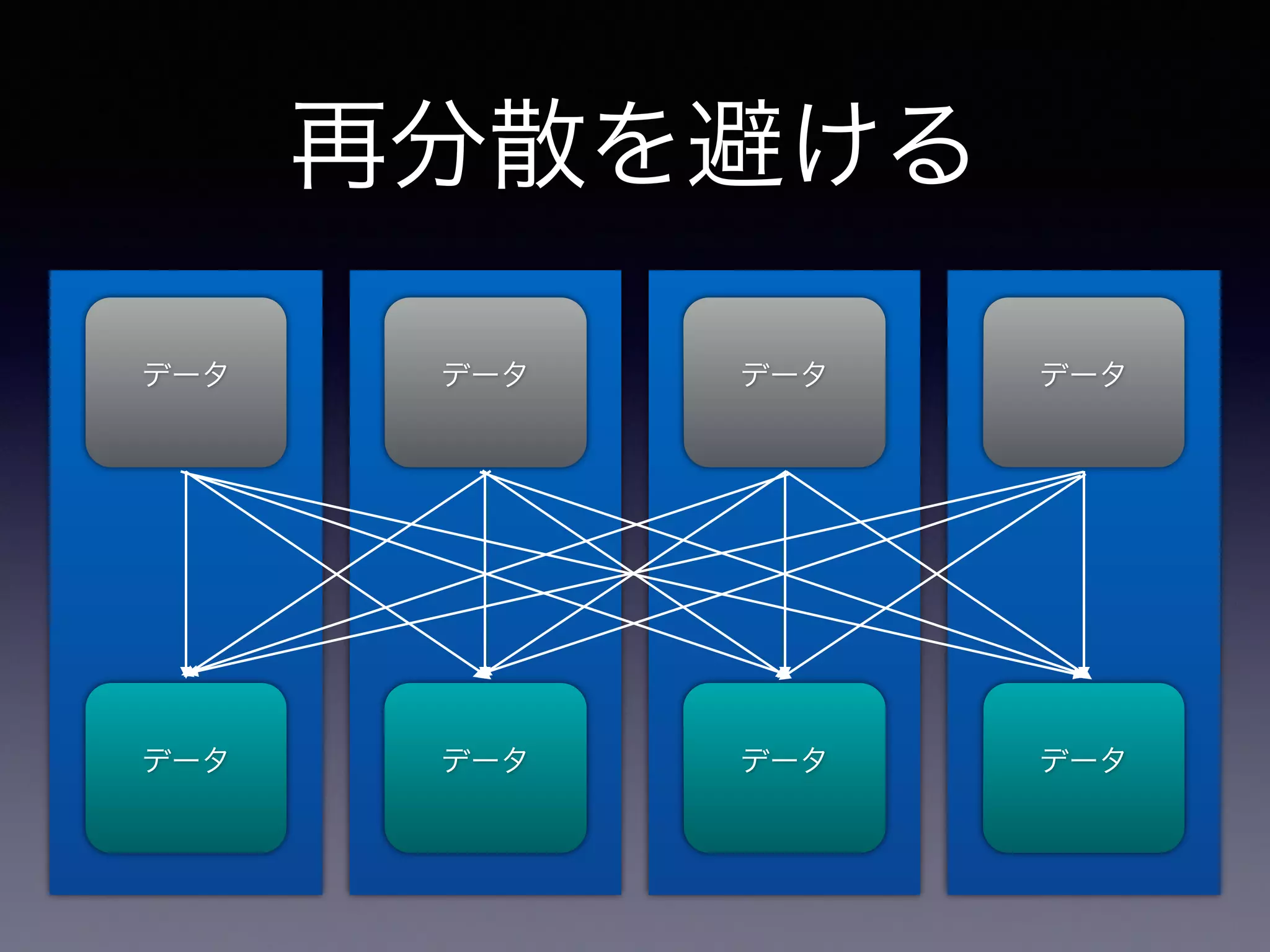
22.
再分散を避ける データ データ データ
データ データ データ データ データ
23.
ジョインキーがdistkeyなら 再分散は起こらない user_id time action 1 1 3 5 user_id
name org 1 3 5 7 user_id time action 2 4 4 4 user_id name org 2 4 6 8 ログテーブル ユーザー マスター
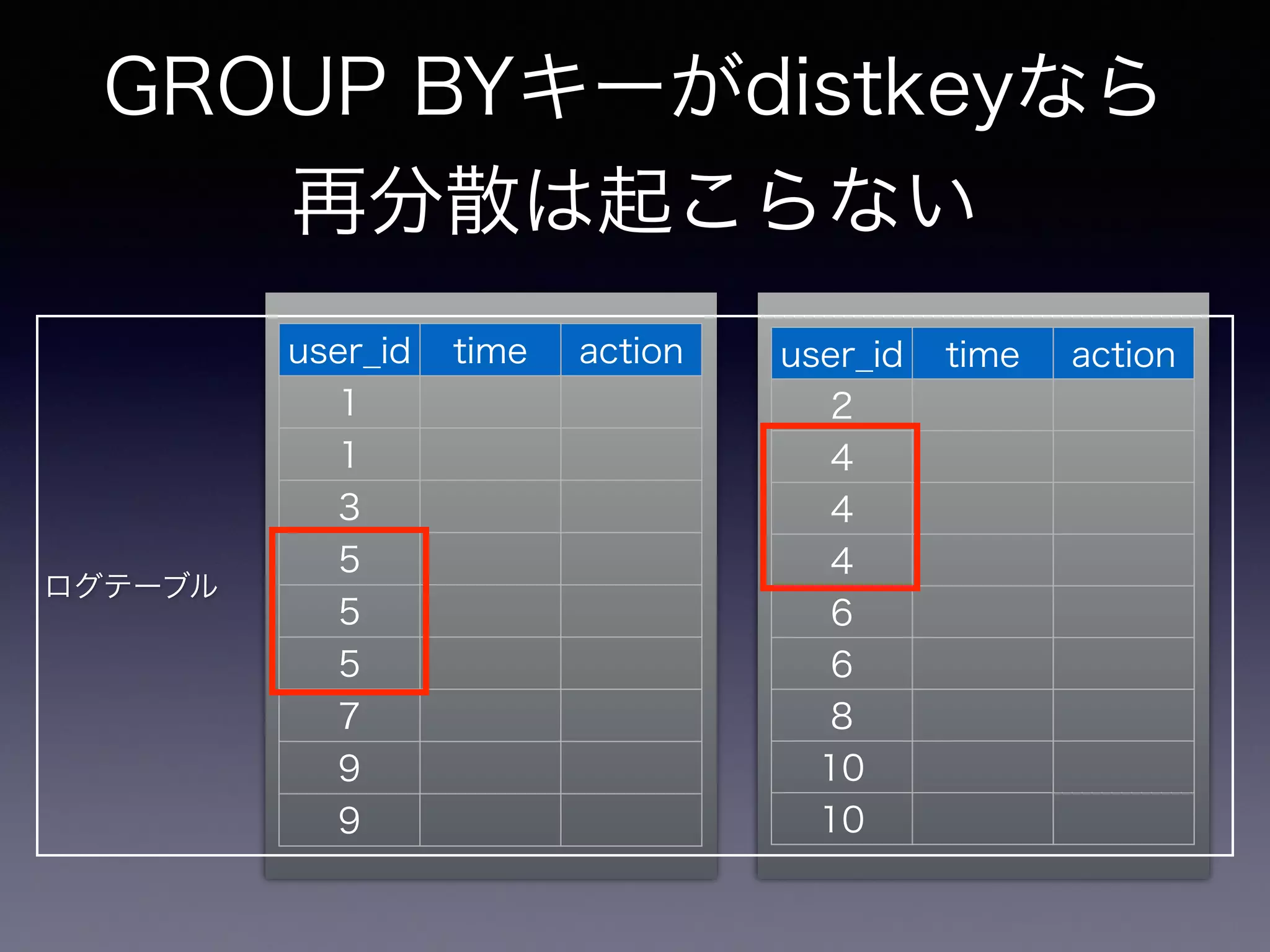
24.
ログテーブル GROUP BYキーがdistkeyなら 再分散は起こらない user_id time
action 1 1 3 5 5 5 7 9 9 user_id time action 2 4 4 4 6 6 8 10 10
25.
目印は DS_DIST_NONE
26.
データを移動したら負け (再)
27.
詳しくは WEB+DB pressの 記事をごら んください
28.
カジュアルなまとめ • 並列RDBではネットワークが最も貴重 • ネットワークの負荷を減らすには再分散を回避 •
再分散を回避するには分散キーを熟慮する
Download










































![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/6g0l8lpr6eqa08bnwkta-signature-9b274dcdb85a5eaa42259455c2cec526dc34c97173e0294f27c0fdabde43af57-poli-160719060716-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWSマイスターシリーズ] Amazon Redshift](https://cdn.slidesharecdn.com/ss_thumbnails/20130716aws-meister-regenerate-redshiftpublic-130719022907-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] A32:Amazon Redshift Deep Dive by アマゾン データ サービス ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a32amazon-redshiftamazondataservicejapan-150623010123-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



