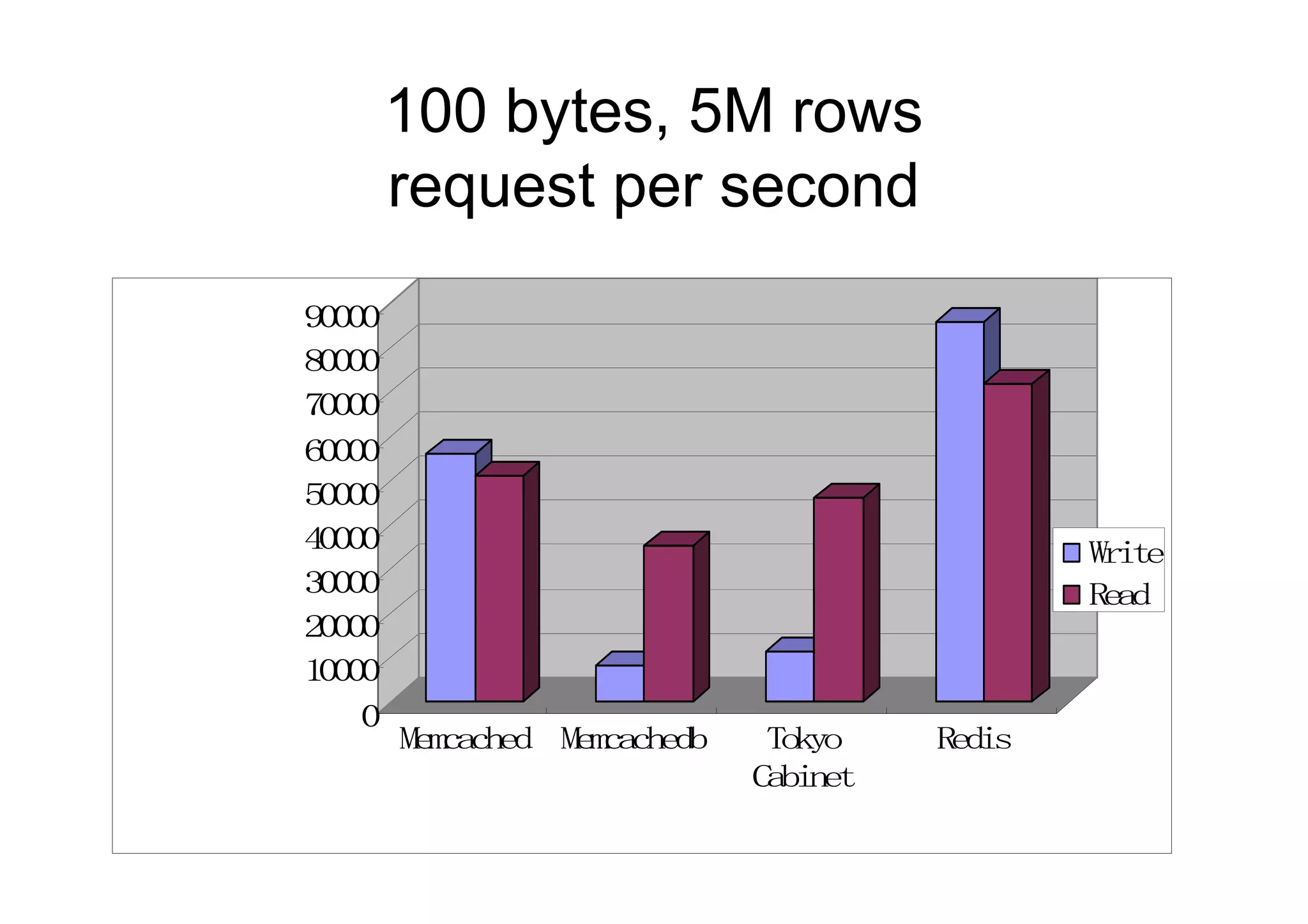
100 bytes, 5Mrows
request per second
900
00
800
00
700
00
600
00
500
00
400
00 Wie
rt
300
00 Ra
ed
200
00
100
00
0
Mmahd Mmahd
ecce ecceb Tko
oy Rds
ei
Cbnt
aie
28.
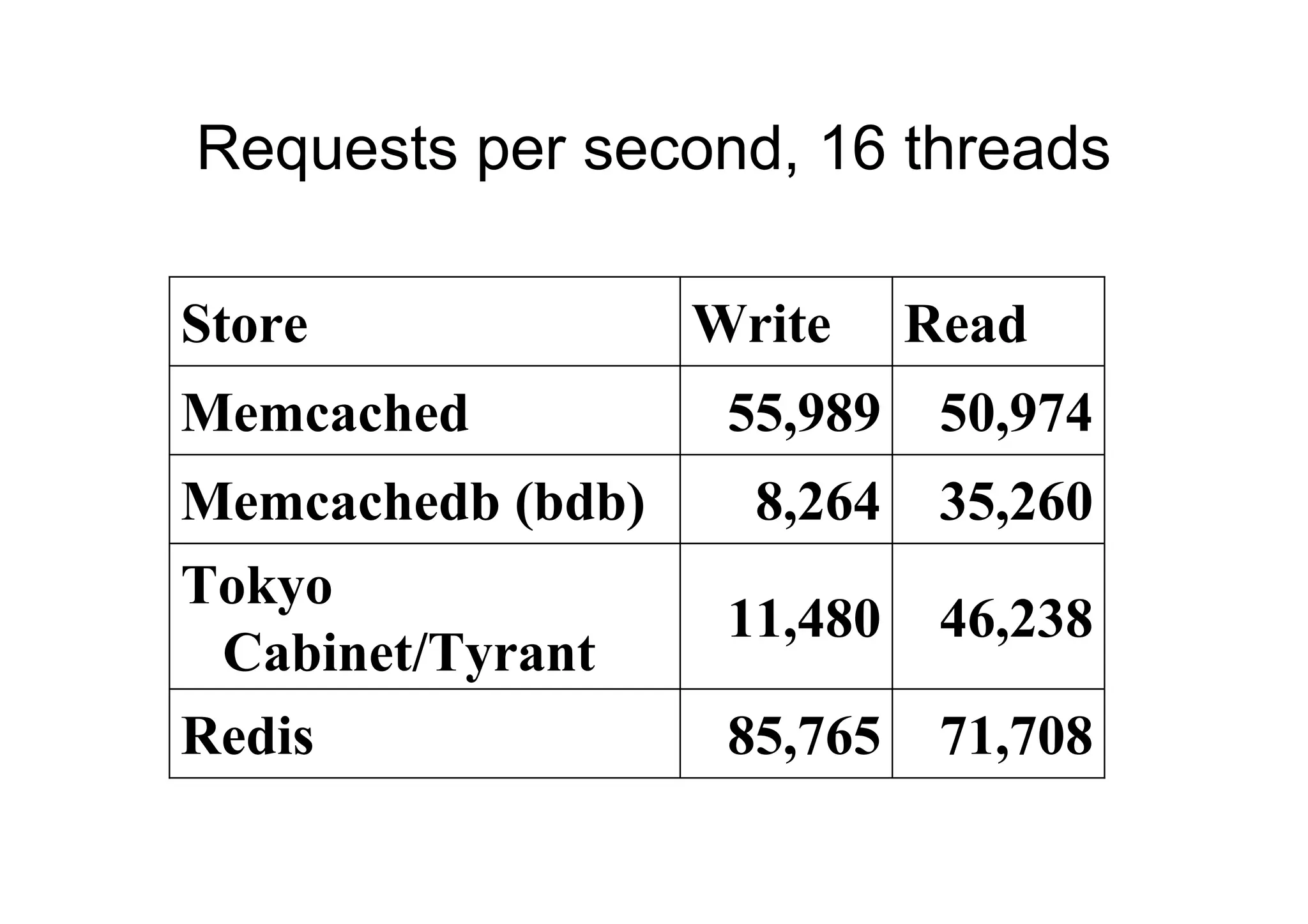
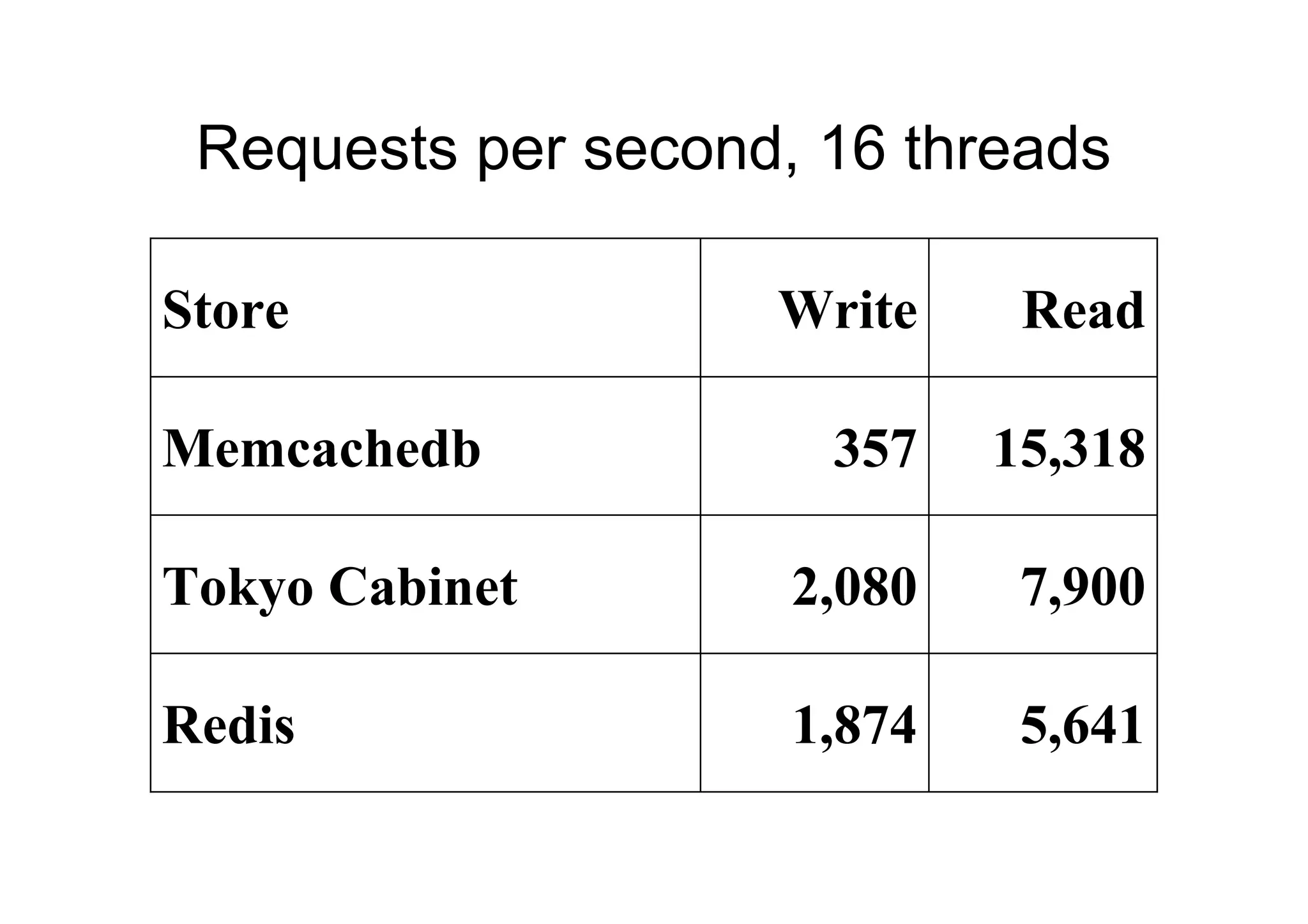
Requests per second,16 threads
Store Write Read
Memcached 55,989 50,974
Memcachedb (bdb) 8,264 35,260
Tokyo
11,480 46,238
Cabinet/Tyrant
Redis 85,765 71,708
29.
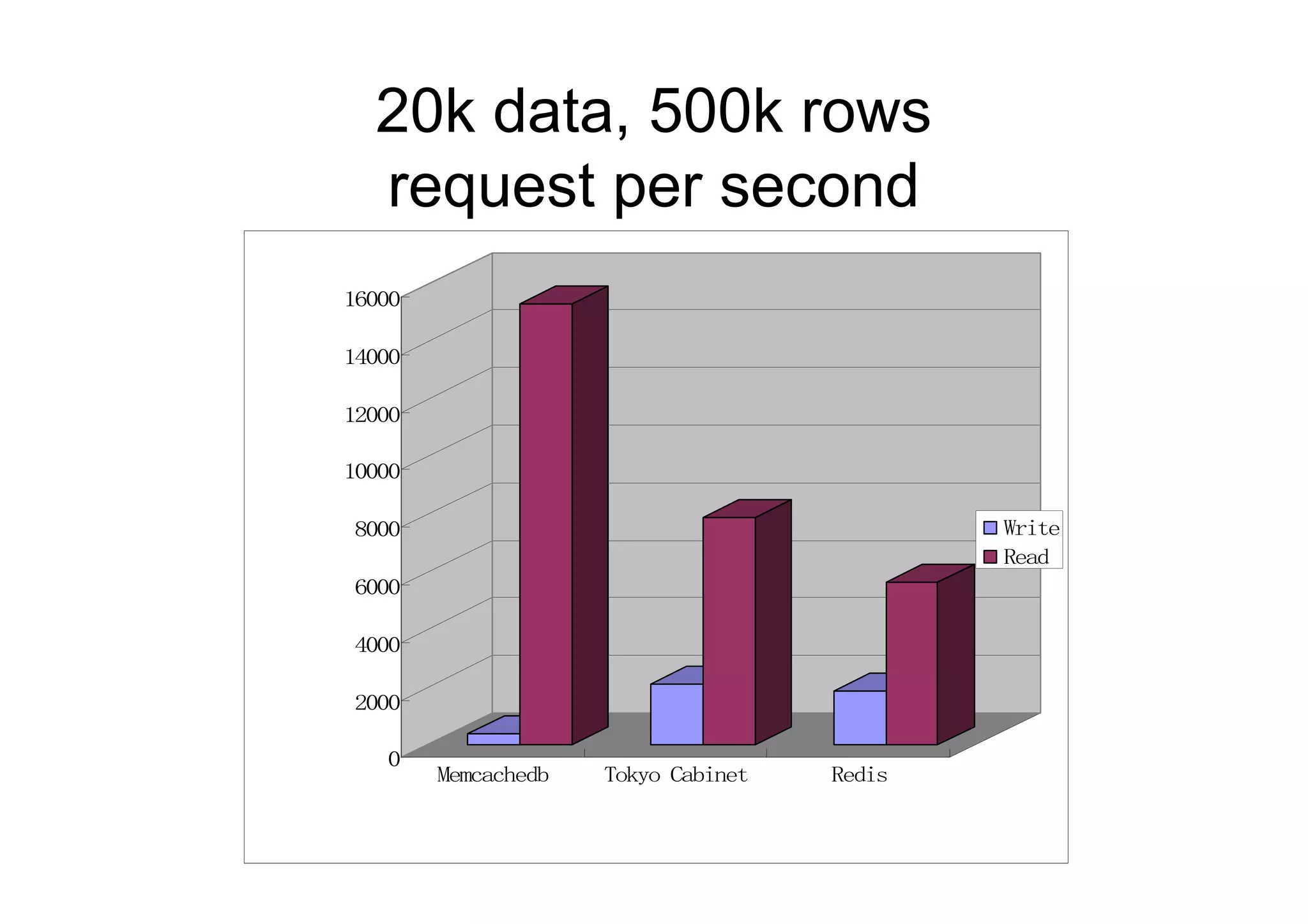
20k data, 500krows
request per second
16000
14000
12000
10000
8000 Write
Read
6000
4000
2000
0
Memcachedb Tokyo Cabinet Redis
30.
Requests per second,16 threads
Store Write Read
Memcachedb 357 15,318
Tokyo Cabinet 2,080 7,900
Redis 1,874 5,641
31.
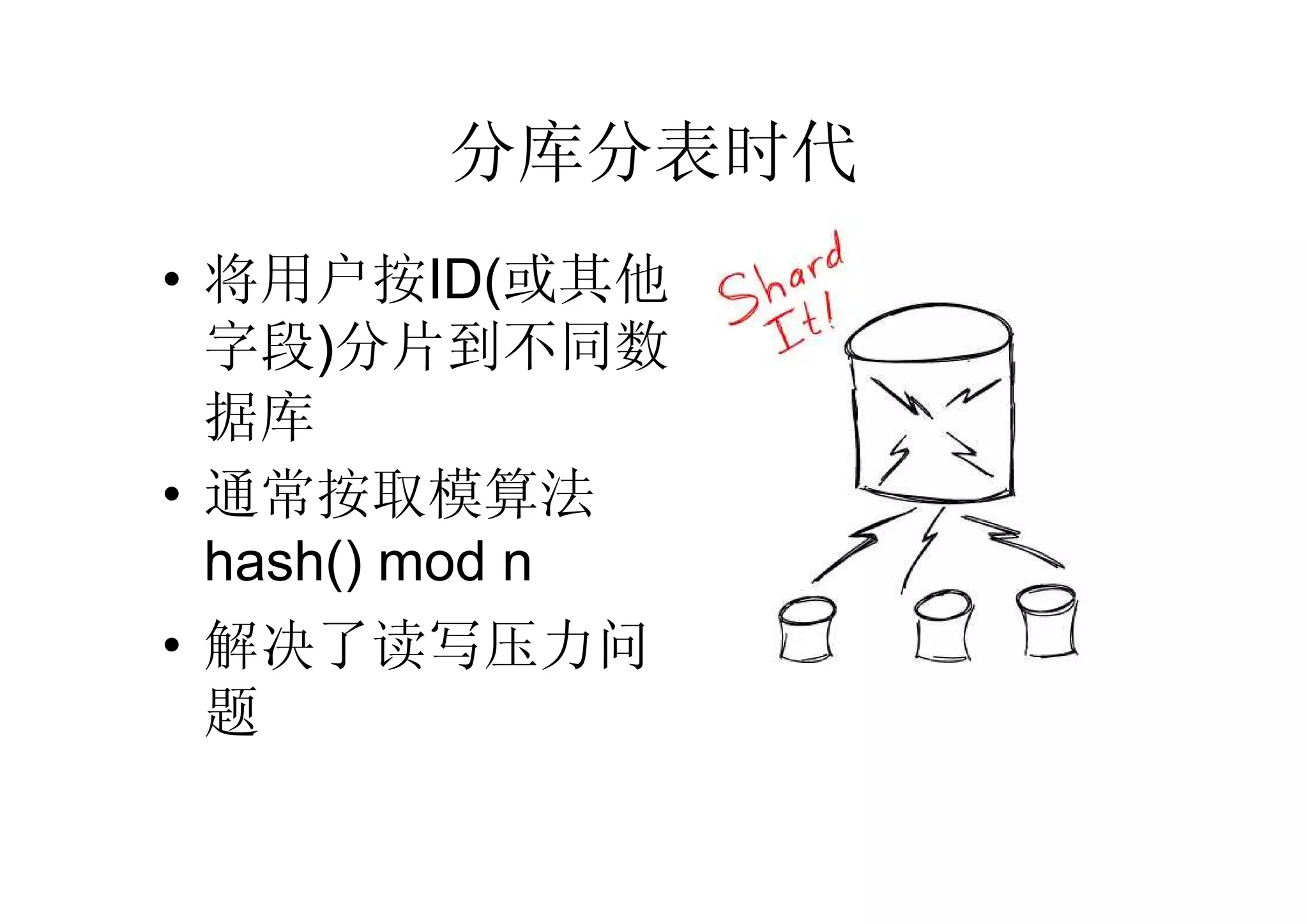
• 到此,我们已经了解了
–繁琐的切分
–Key value store的优势
–Key value store的性能区别
• 可以成为一个合格的架构师了吗
• 还缺什么
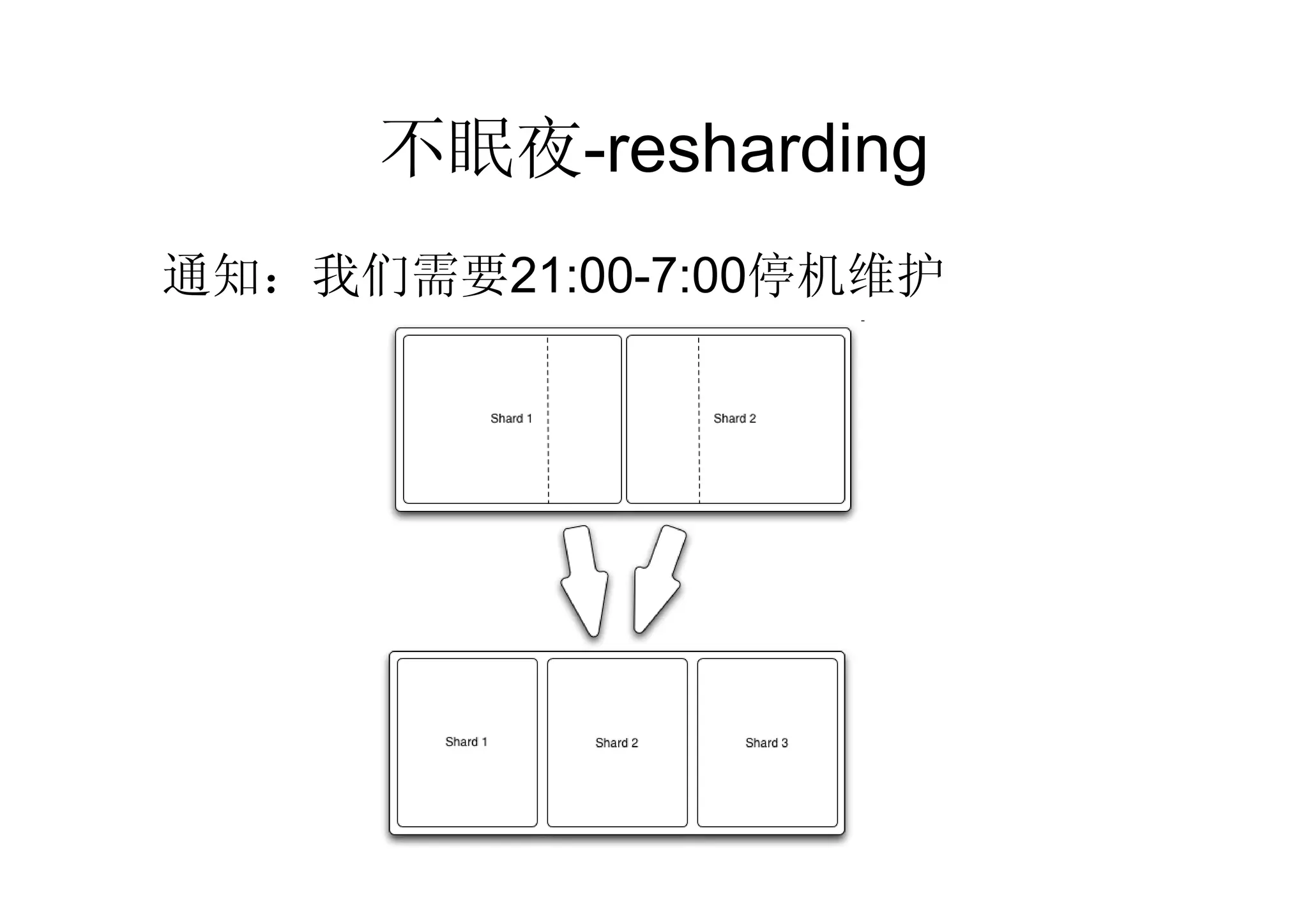
32.
新需求
• 如何设计一个分布式的有状
态的服务系统?
–如IM Server, game server
–用户分布在不同的服务器上,
但彼此交互
• 前面学的“架构”毫无帮助
33.
分布式设计思想红宝书
– Dynamo: Amazon'sHighly Available
Key-value Store
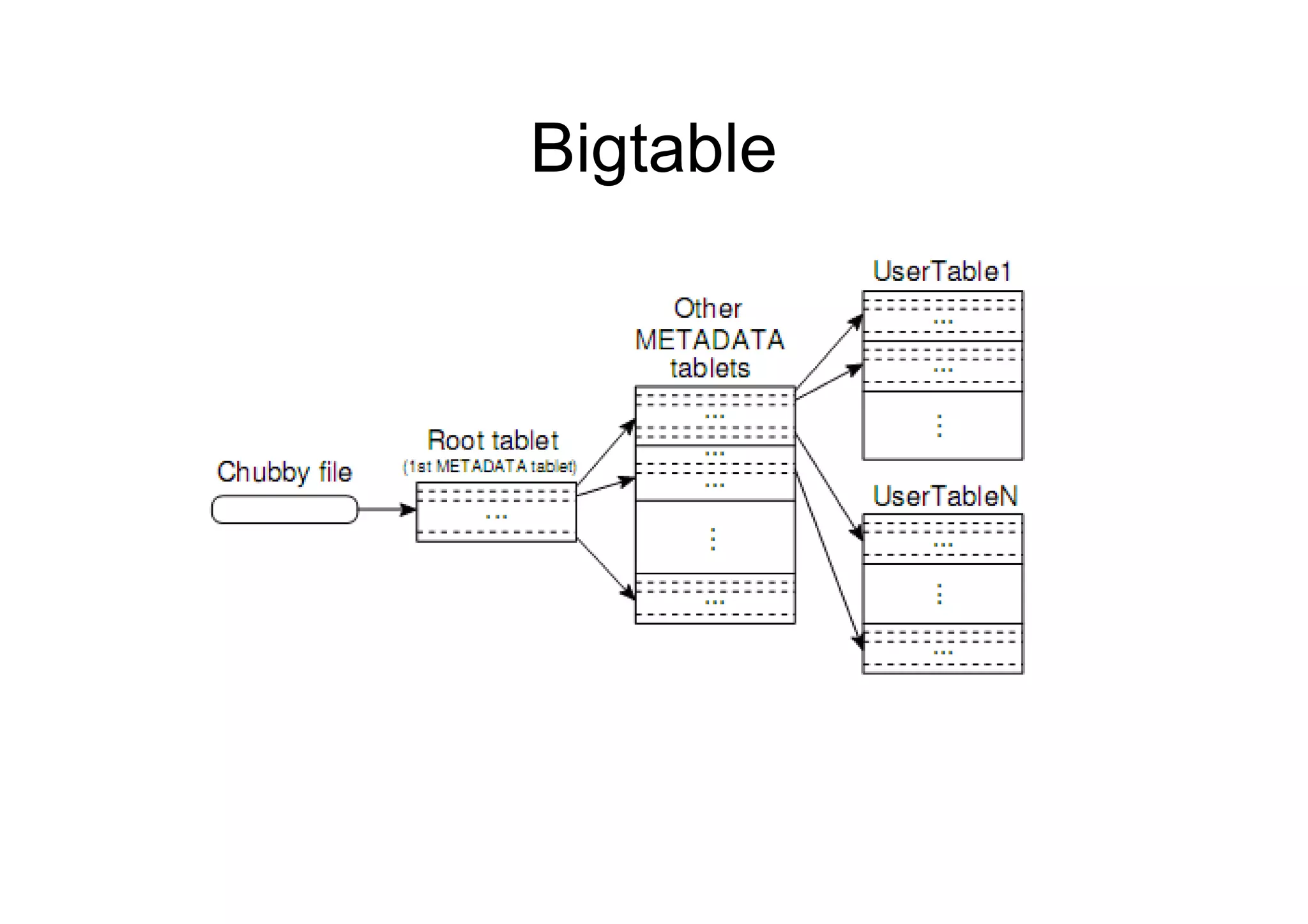
– Bigtable: A Distributed Storage System
for Structured Data
Reconciliation, Merge version
•如何处理(A:3,B:2,C1)?
– Business logic specific reconciliation
– Timestamp
– High performance read engine
• R = 1, W = N
• 越变越长?Threshold=10
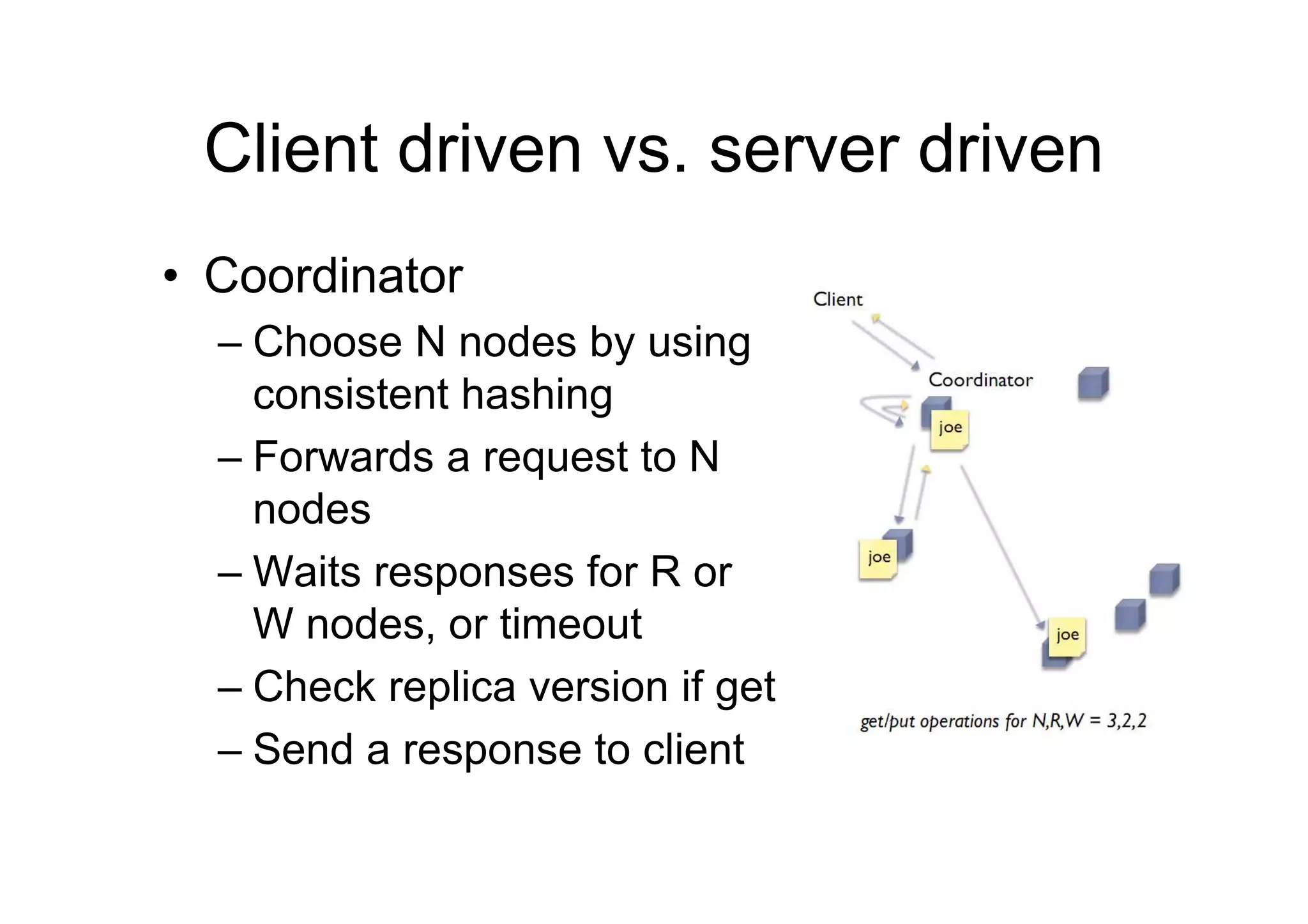
Client driven vs.server driven
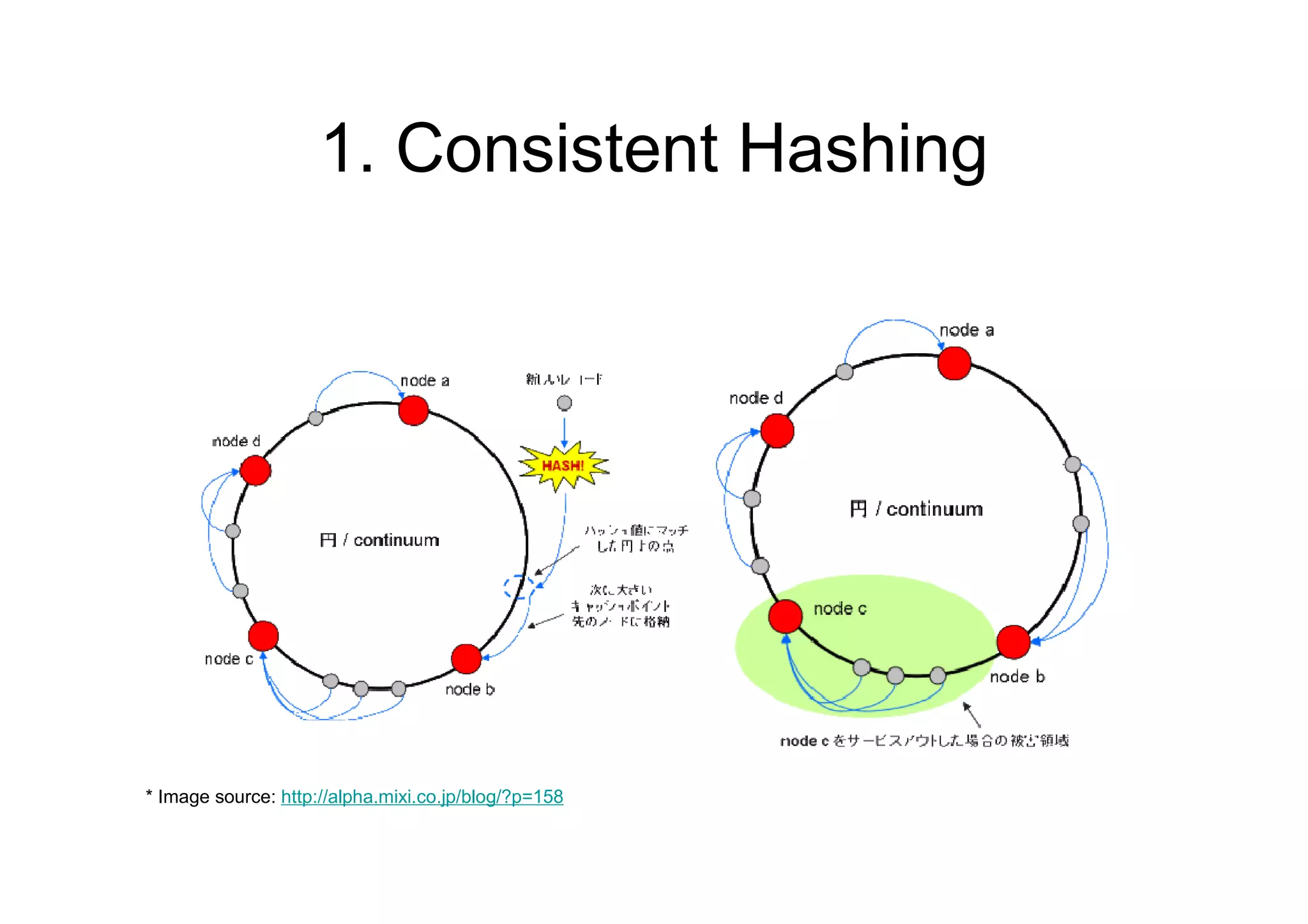
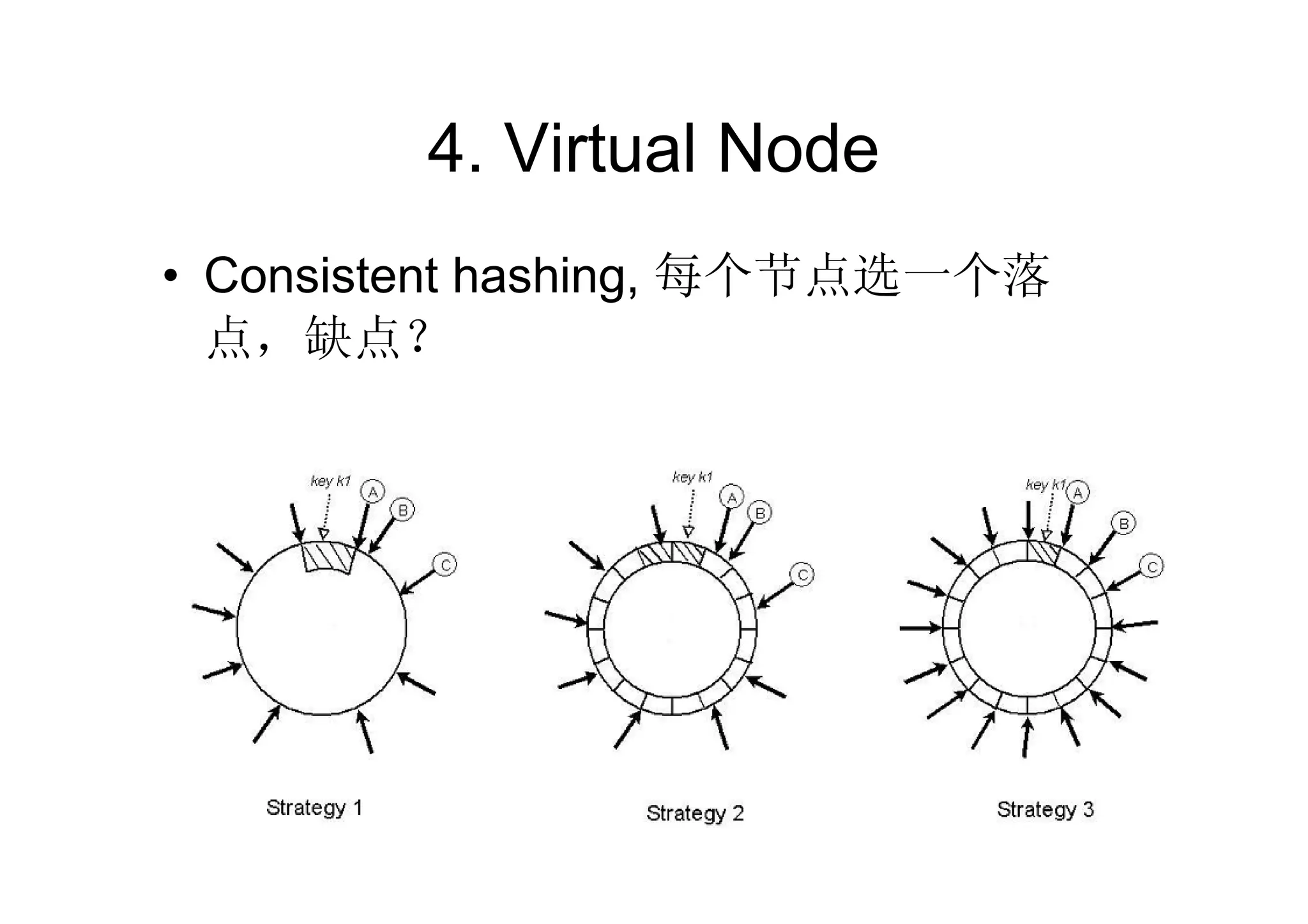
• Coordinator
– Choose N nodes by using
consistent hashing
– Forwards a request to N
nodes
– Waits responses for R or
W nodes, or timeout
– Check replica version if get
– Send a response to client
54.
Dynamo impl.
• Kai,in Erlang
• E2-dynamo, in Erlang
• Sina DynamoD, in C
–N=3
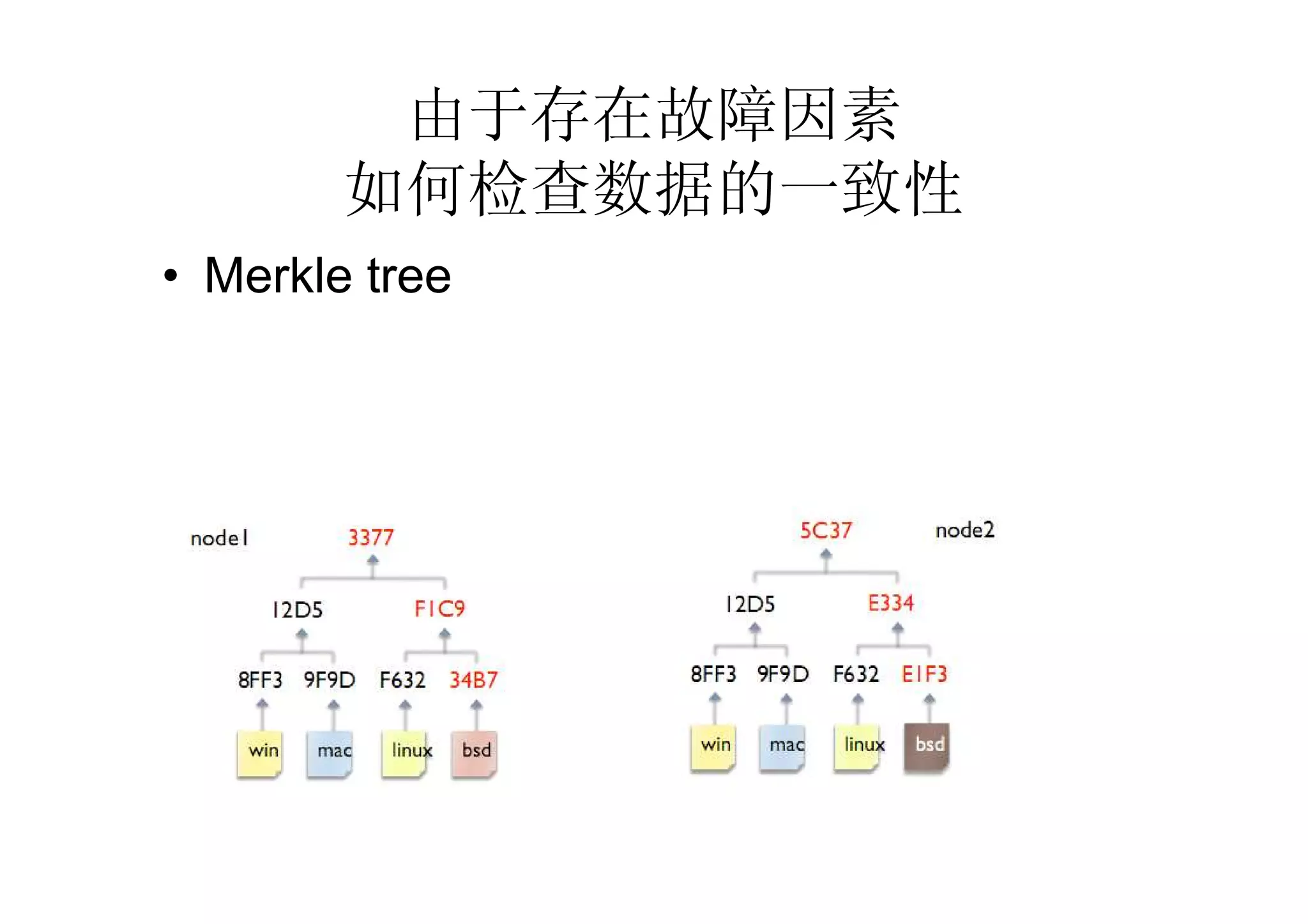
– Merkle tree based on commit log
– Virtual node mapping saved in db
– Storage based on memcachedb



![场景
• 假定场景为一IM系统,数据存储包括
– 1. 用户表(user)
• {id, nickname, avatar, mood}
– 2. 用户消息资料(vcard)
• {id, nickname, gender, age, location…}
– 好友表(roster)
• {[id, subtype, nickname, avatar,
remark],[id2,…],…}](https://image.slidesharecdn.com/keyvaluestore-090809211516-phpapp02/75/Key-Value-Store-4-2048.jpg)




























































































![[2B5]nBase-ARC Redis Cluster](https://cdn.slidesharecdn.com/ss_thumbnails/2b5nbase-arcrediscluster-140930003743-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















