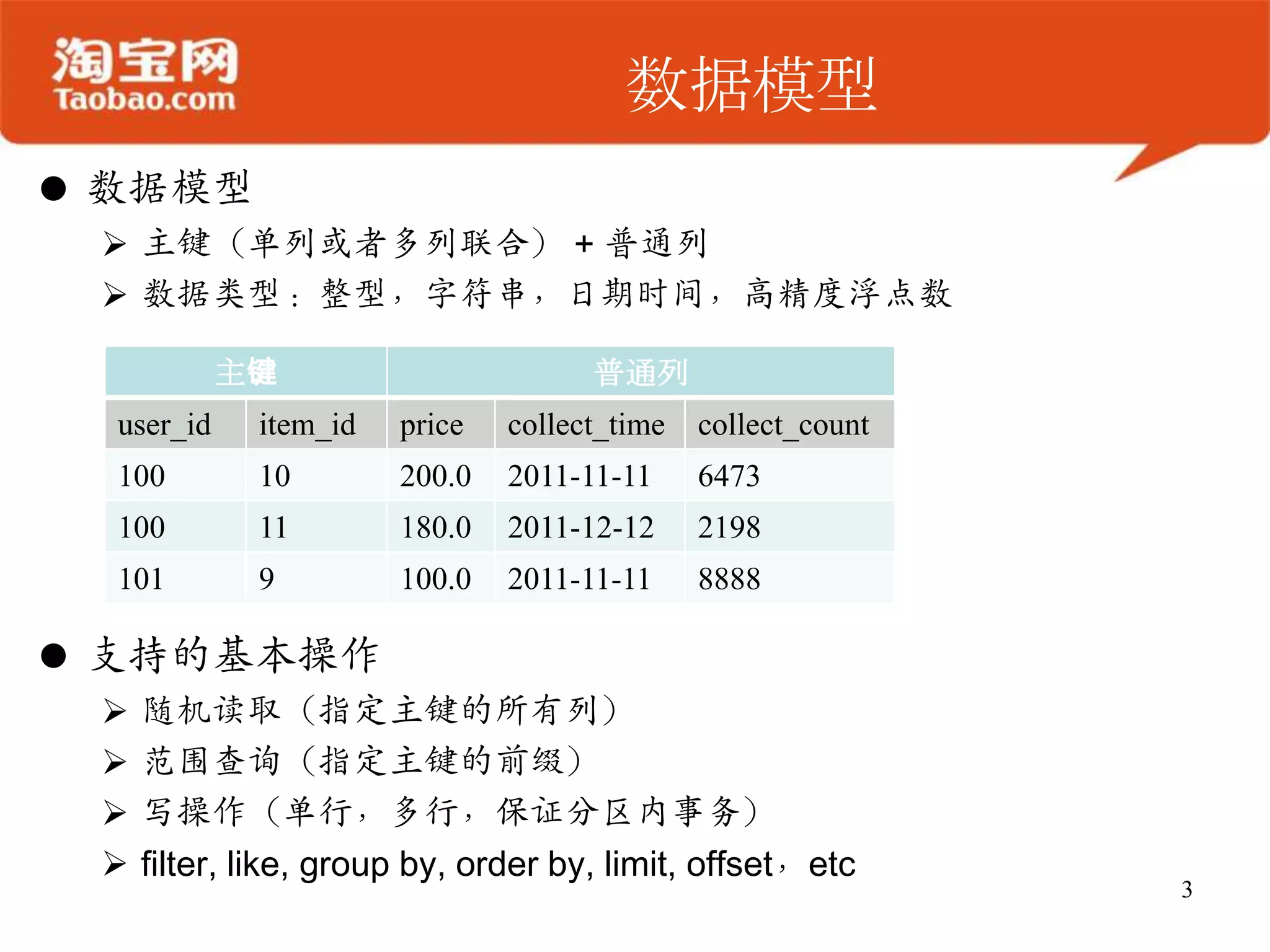
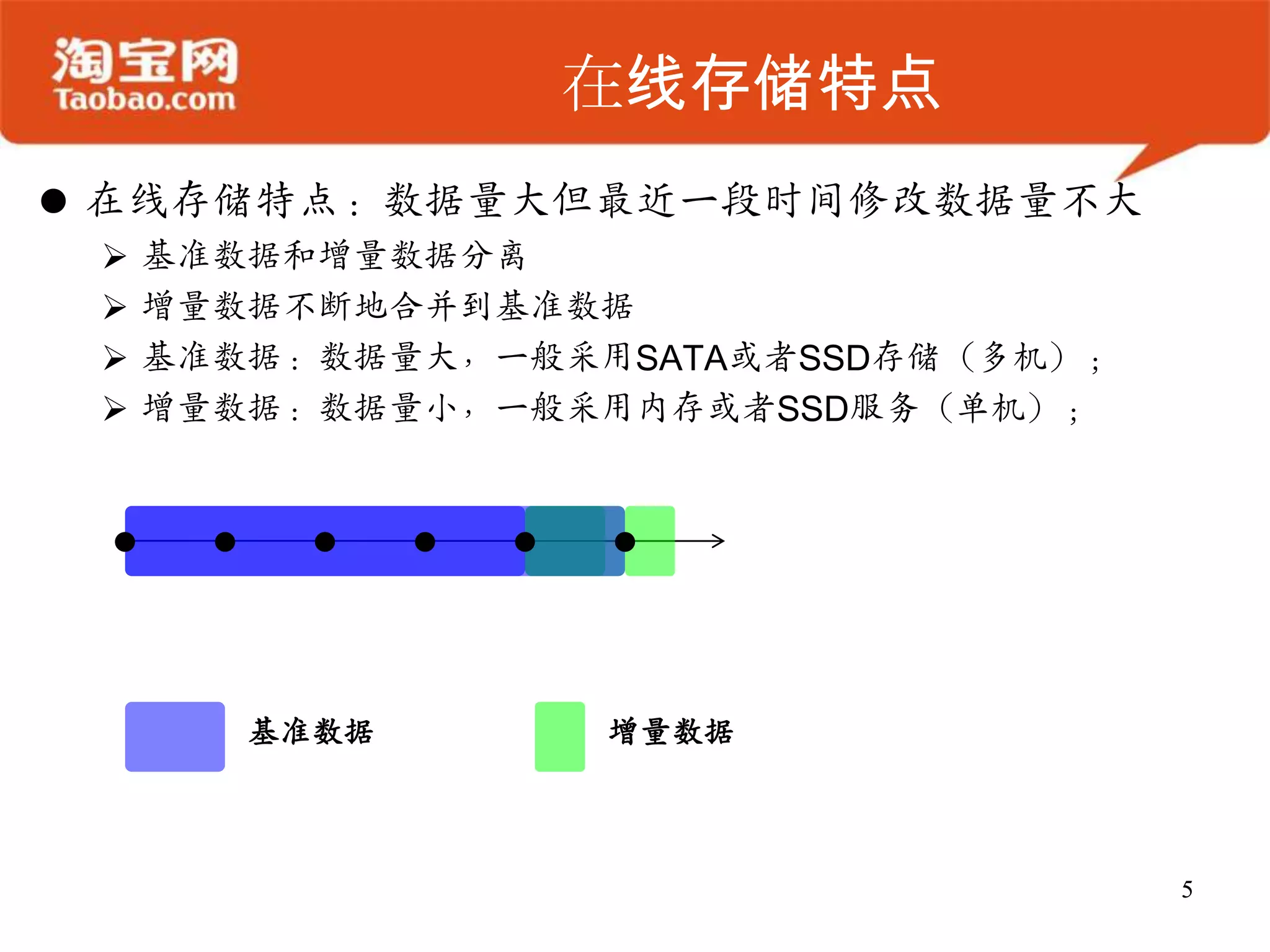
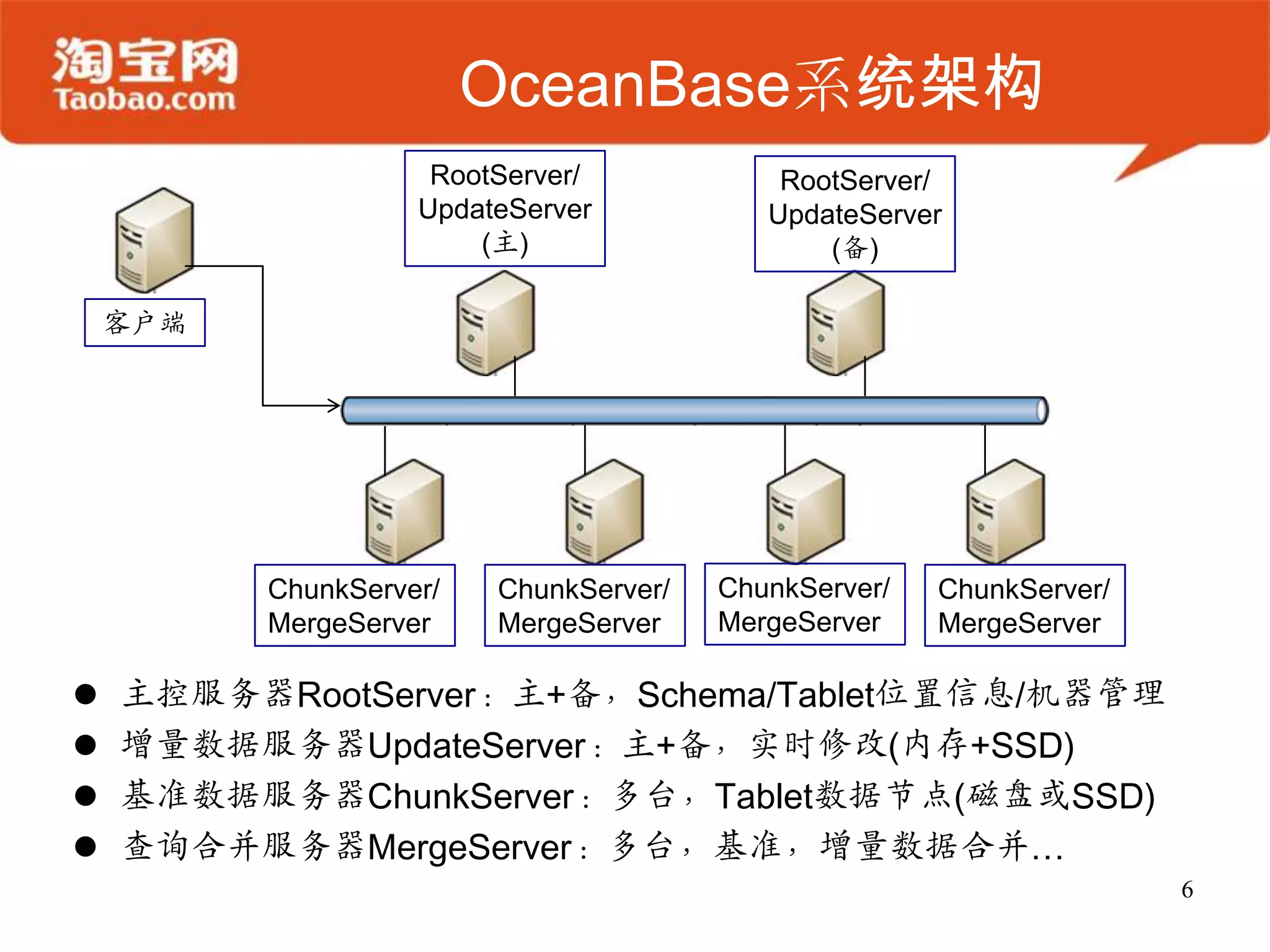
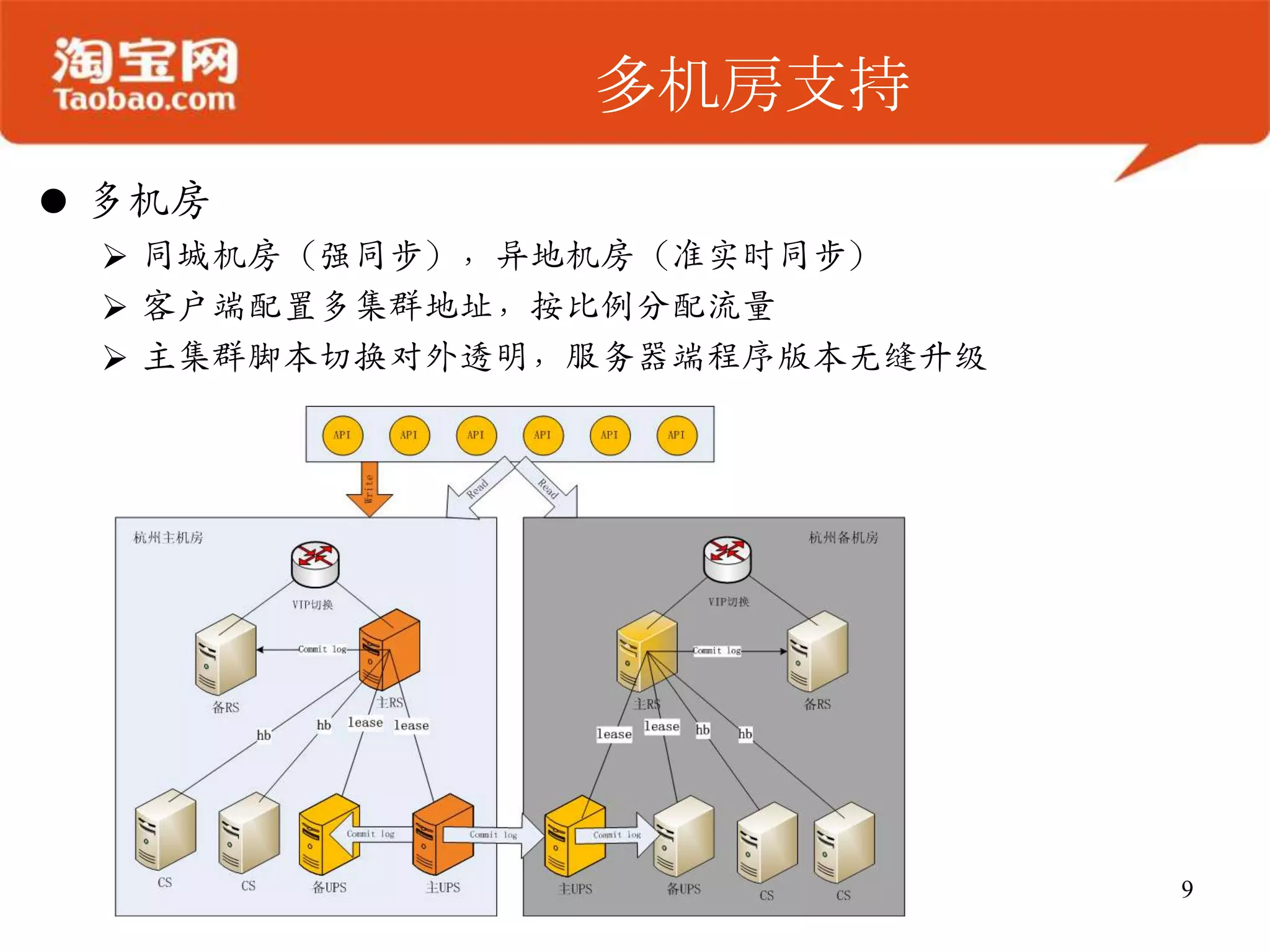
OceanBase 是一个高效的结构化数据存储系统,支持大规模数据处理,具备强大的在线存储和实时分析能力。其架构简单,确保数据安全、同步,并能够无缝扩展,适合需要处理大表 join 或高并发访问的业务场景。未来发展将集中在增强可用性、可扩展性及性能优化。