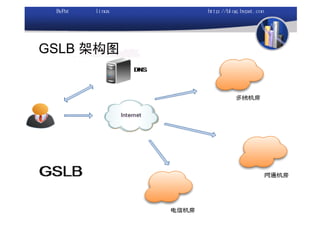
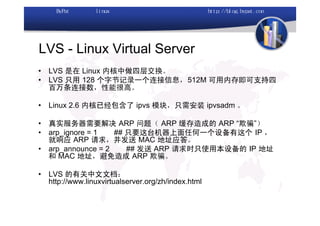
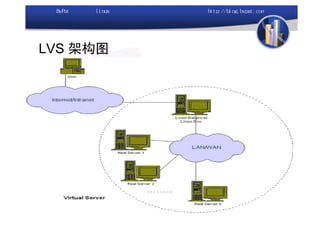
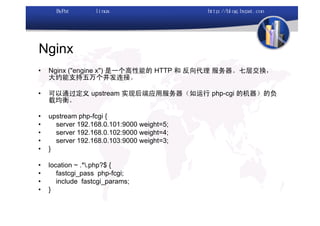
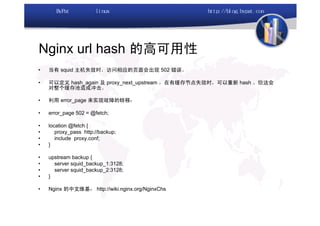
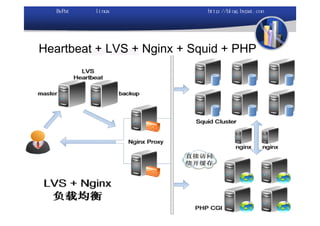
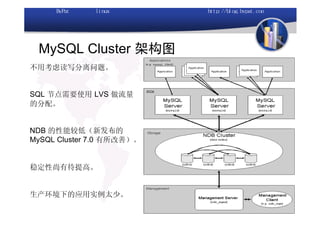
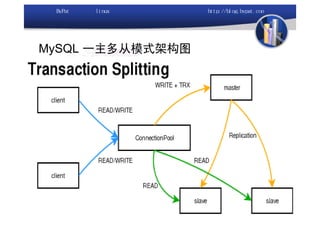
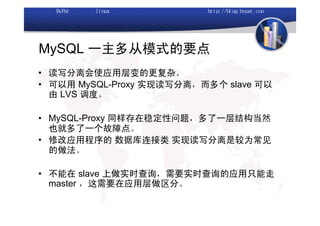
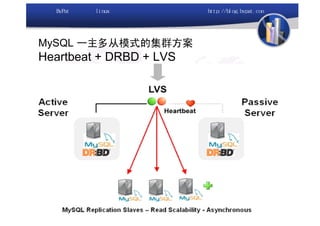
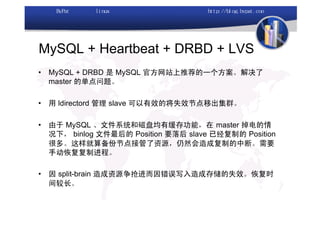
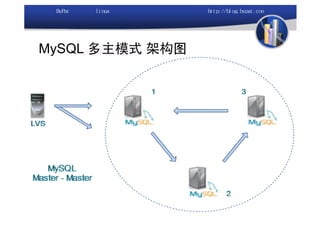
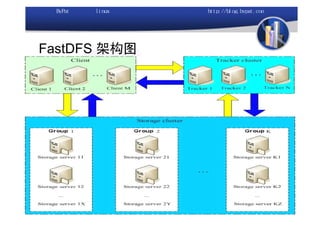
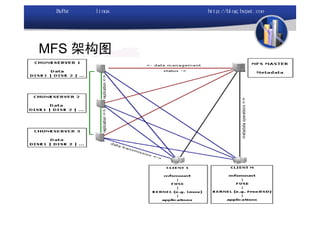
本文讨论了利用开源软件构建高可用、高性能的集群架构,涵盖全局负载均衡(GSLB)、服务器负载均衡(SLB)、心跳监测等技术。文中详细介绍了MySQL数据库集群、存储备份、集群监控以及动态扩展等内容,并提供了相关实现方案与架构图。通过多种负载均衡和数据同步策略,文档提供了建立高效集群系统的实用指南。