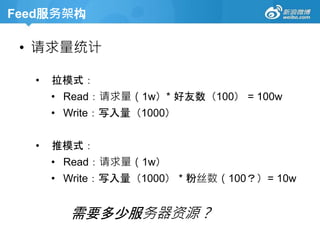
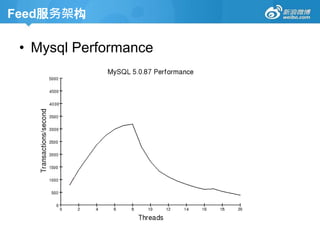
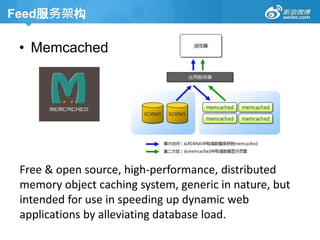
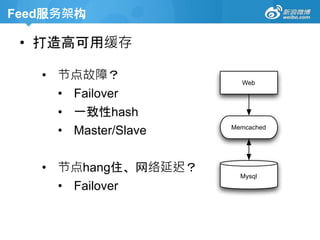
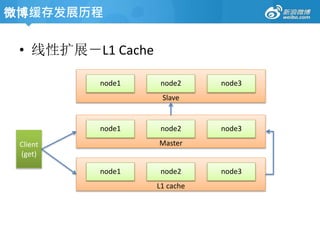
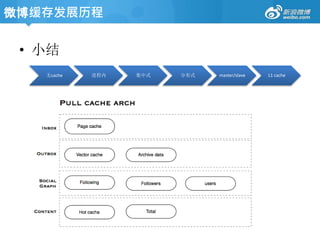
Feed服务架构
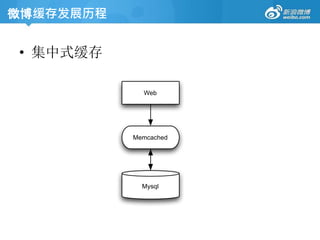
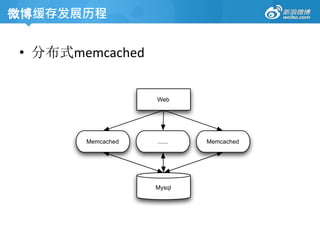
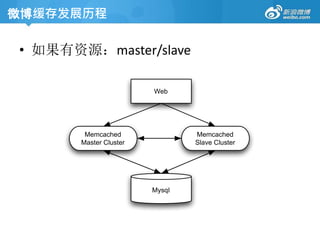
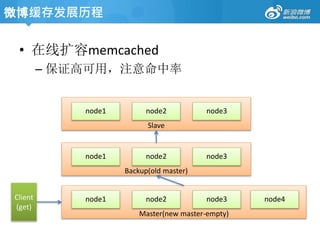
• Memcached
Free &open source, high-performance, distributed
memory object caching system, generic in nature, but
intended for use in speeding up dynamic web
applications by alleviating database load.
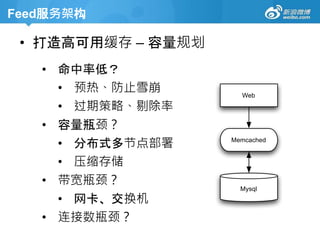
• 扩展前准备工作
– selectt.id, c.content from timeline t
left join content c where t.uid=?
– 这样的sql语句假定content和timeline在同一
数据库中,并且是单表结构。
• 如果content和timeline拆分到不同数据库?
• 如果content和timeline要分库和分表?
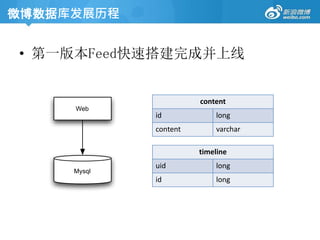
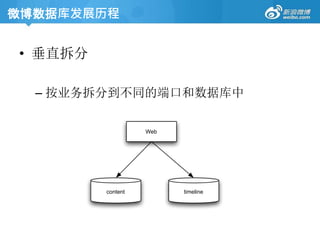
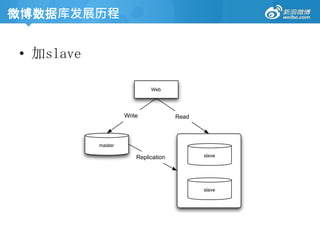
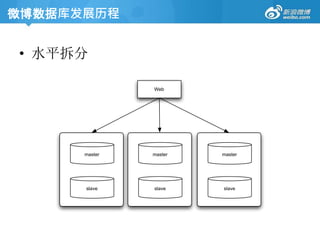
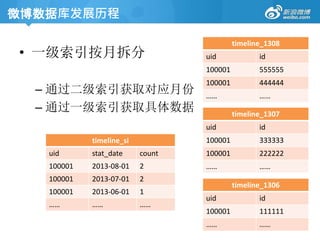
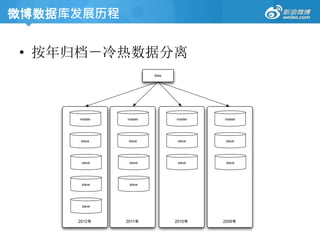
微博数据库发展历程
33.
• 数据库只是存储
– 在数据库层面没有业务逻辑
–业务逻辑在应用端处理
– sql语句应该是
• select id from timeline where uid =?
• select id,content from content where id in (?)
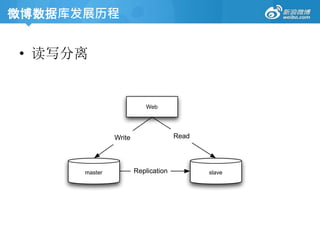
微博数据库发展历程