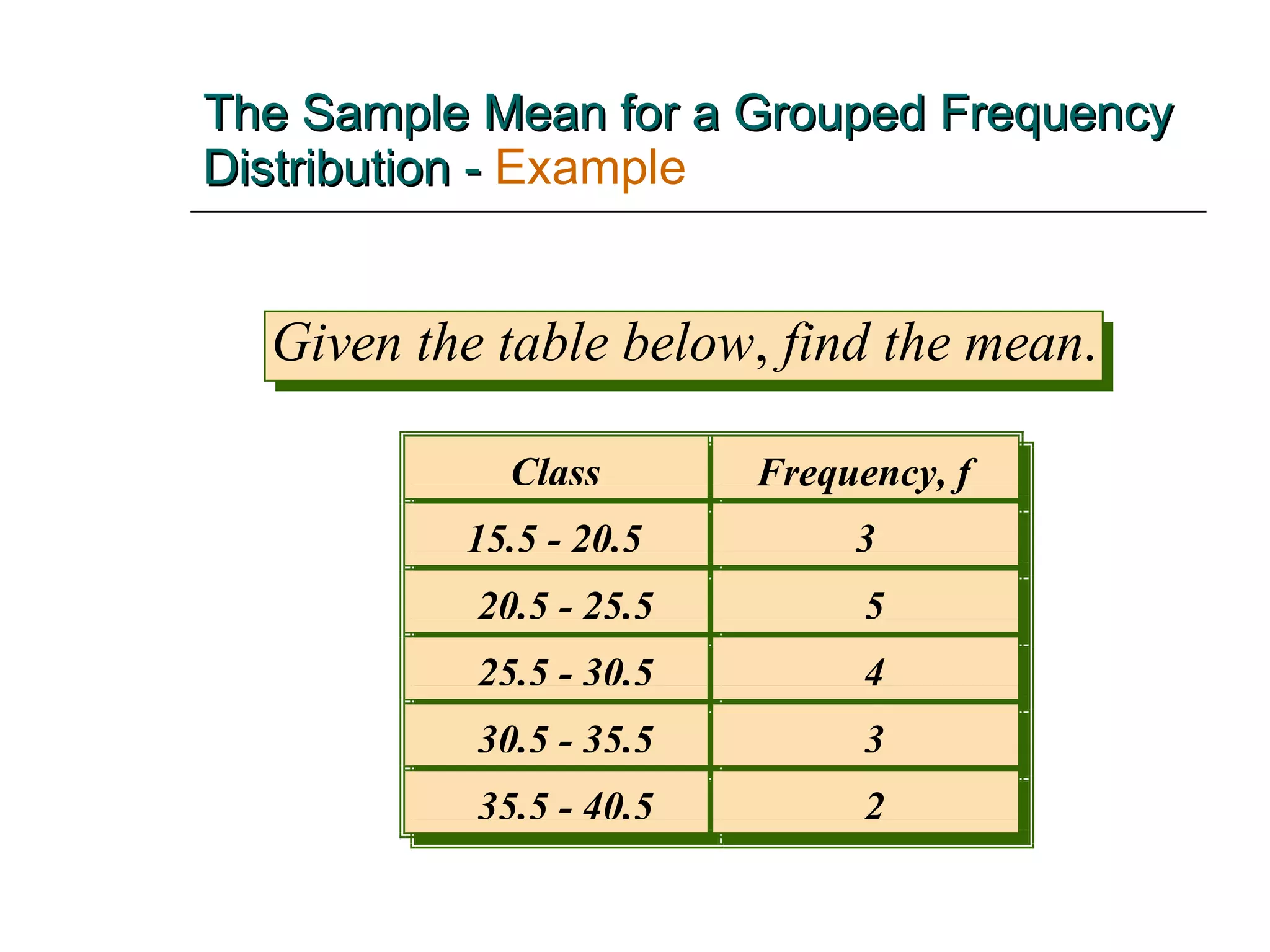
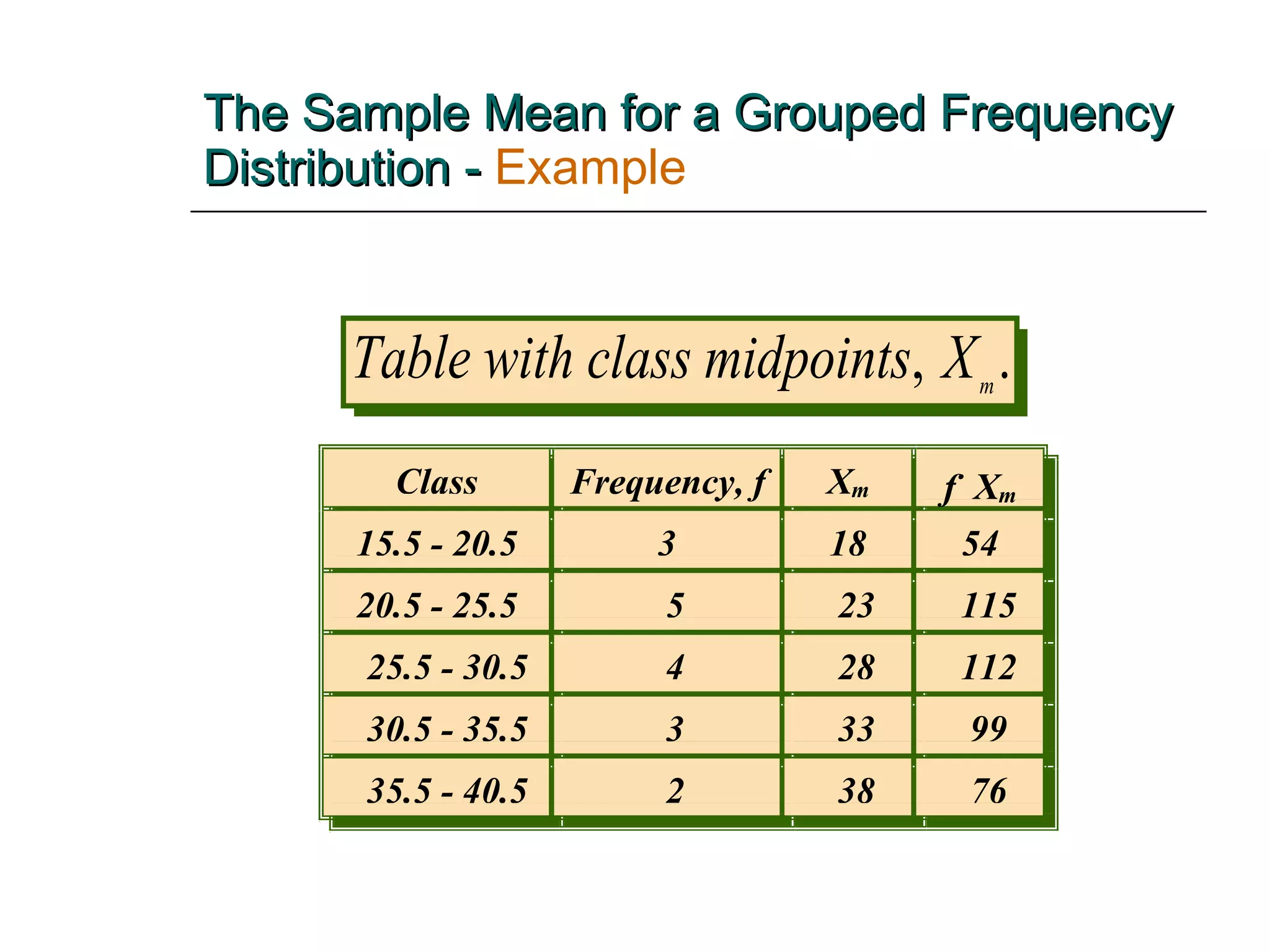
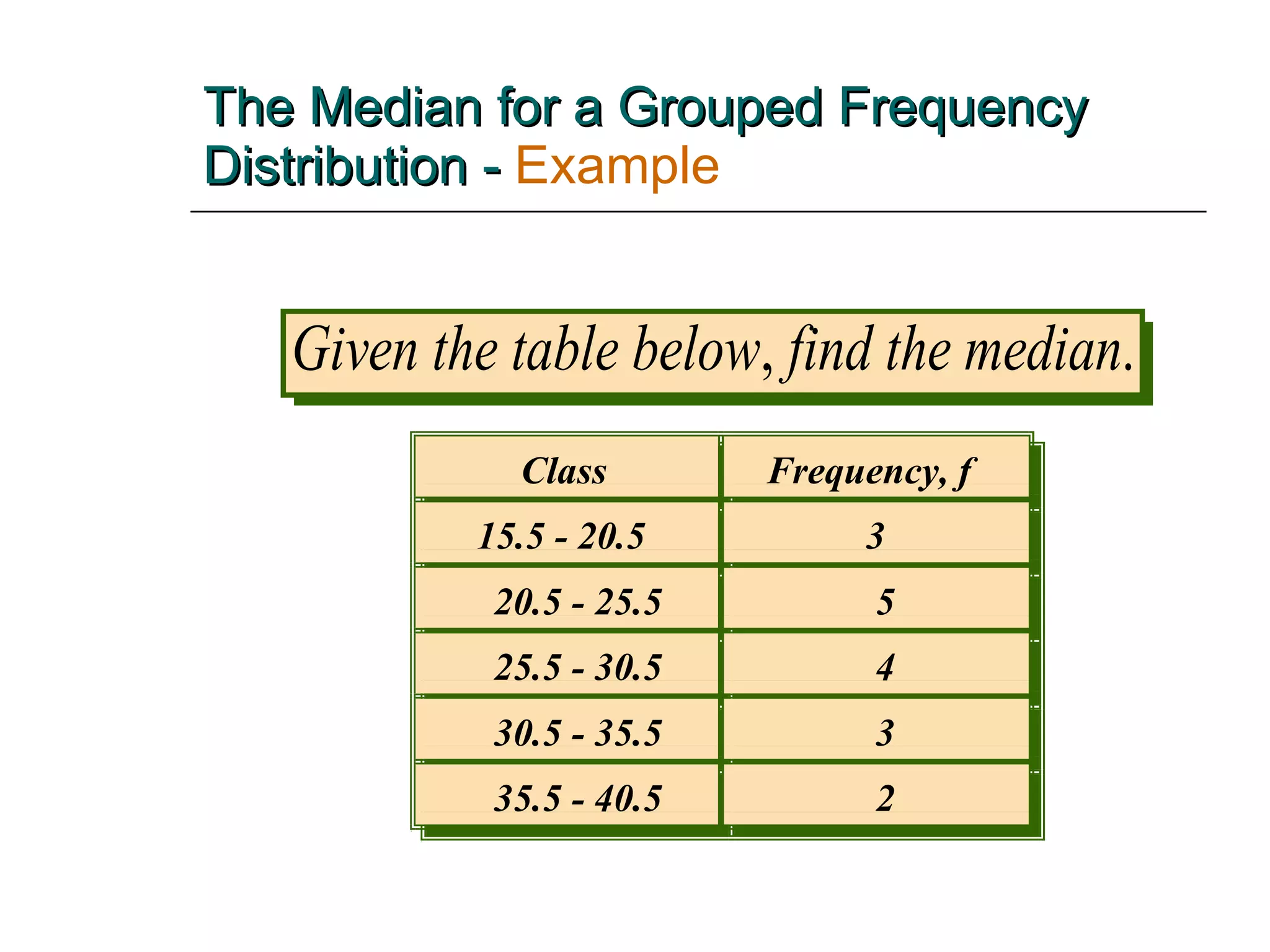
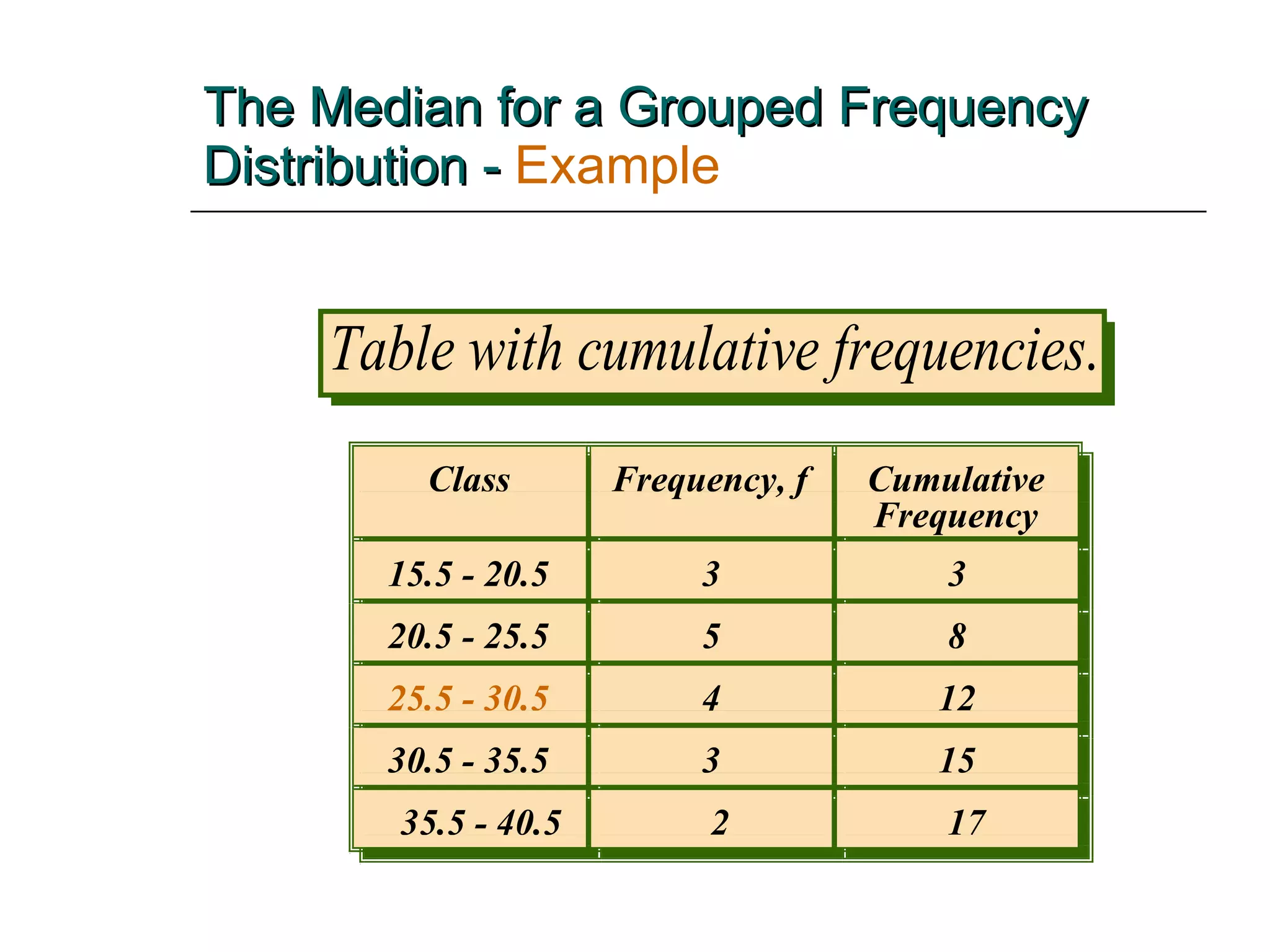
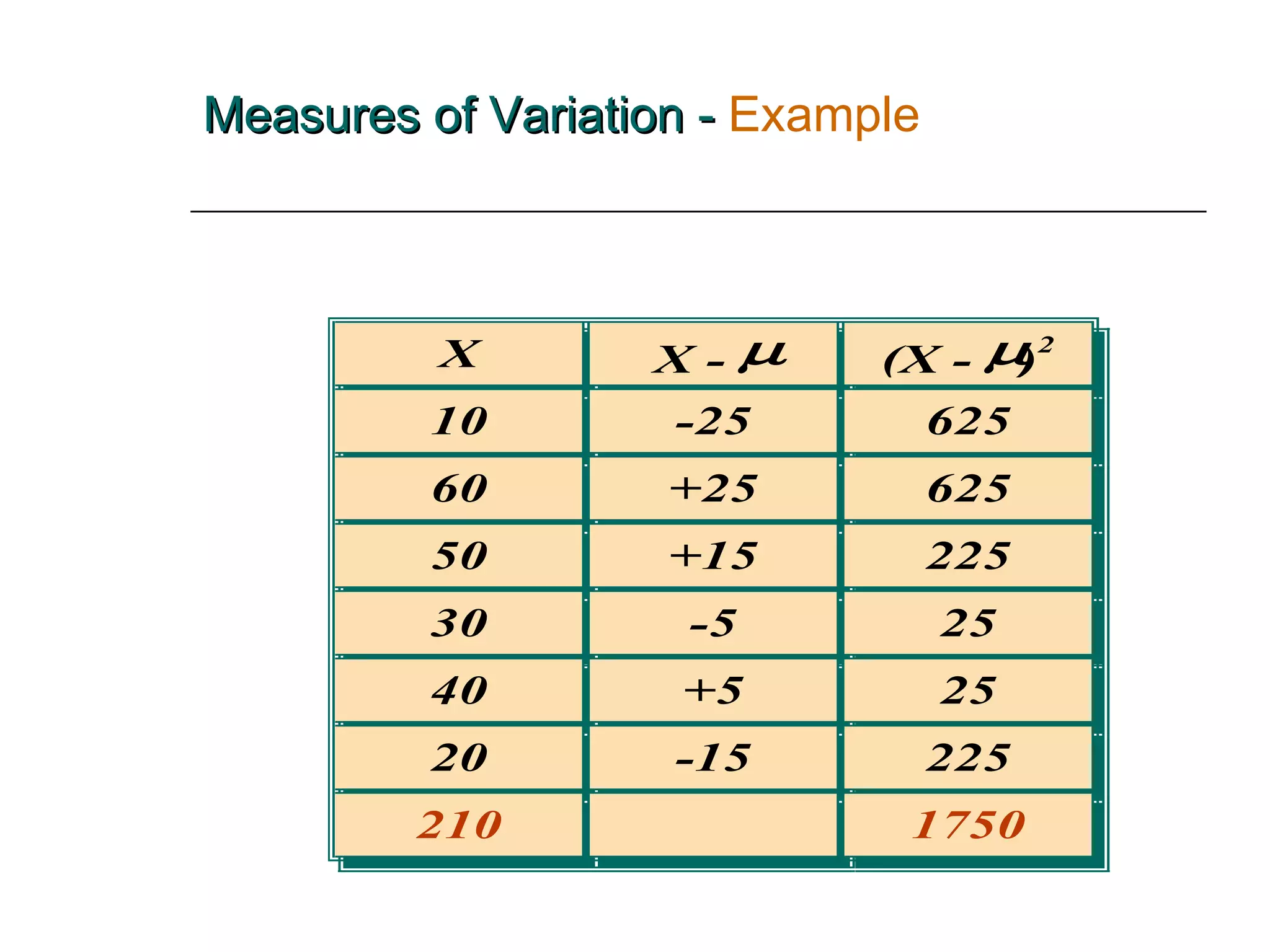
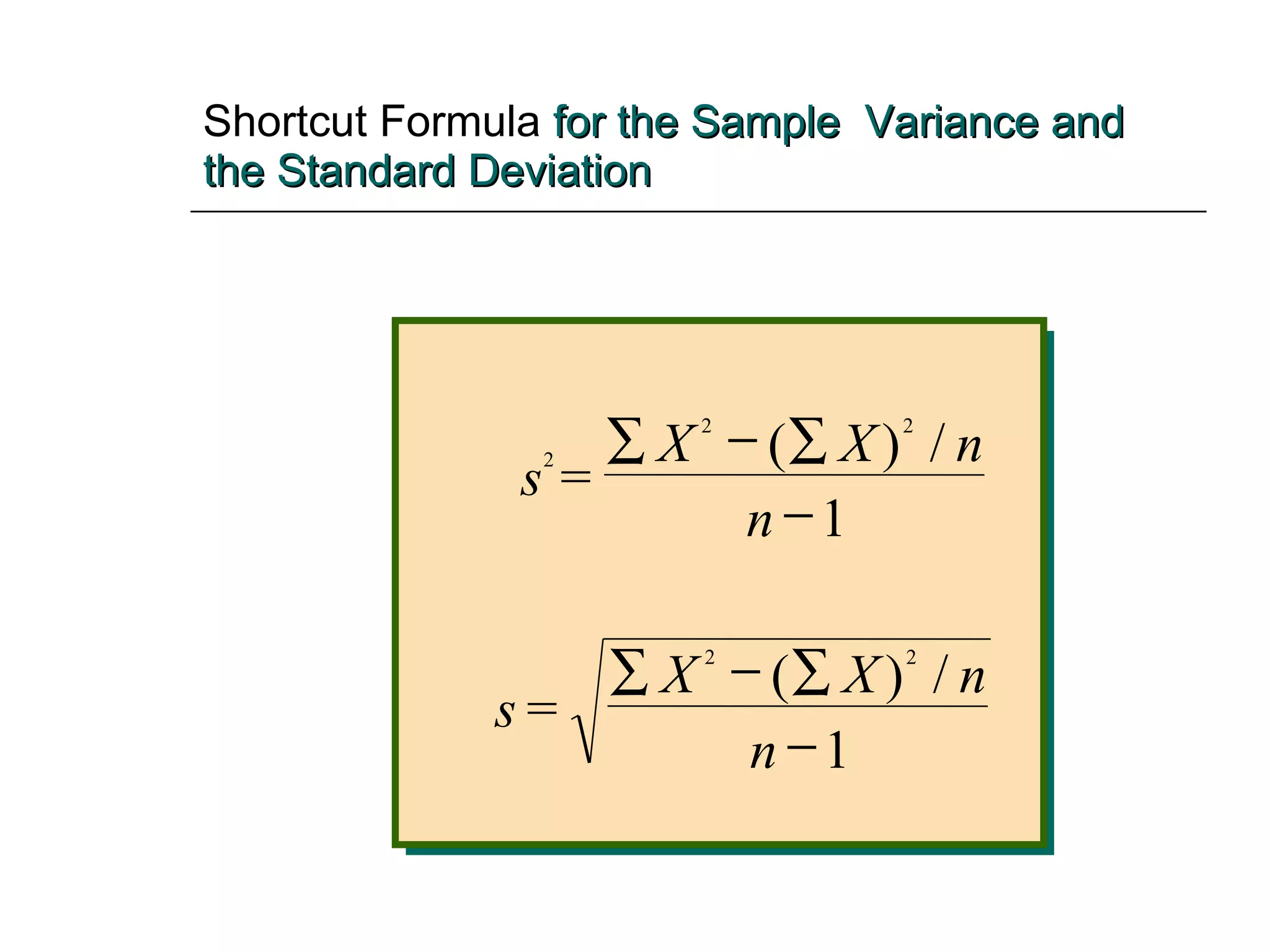
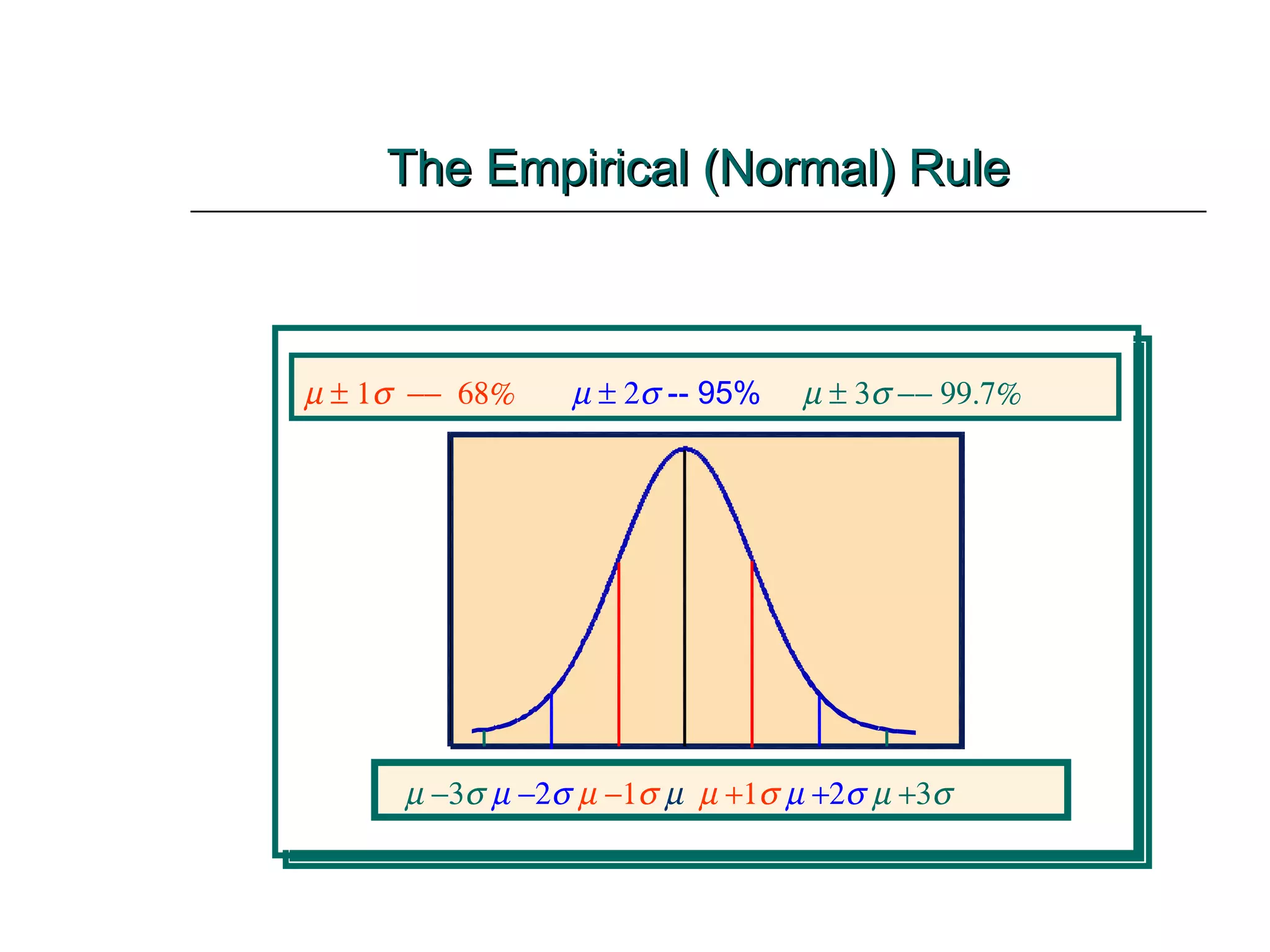
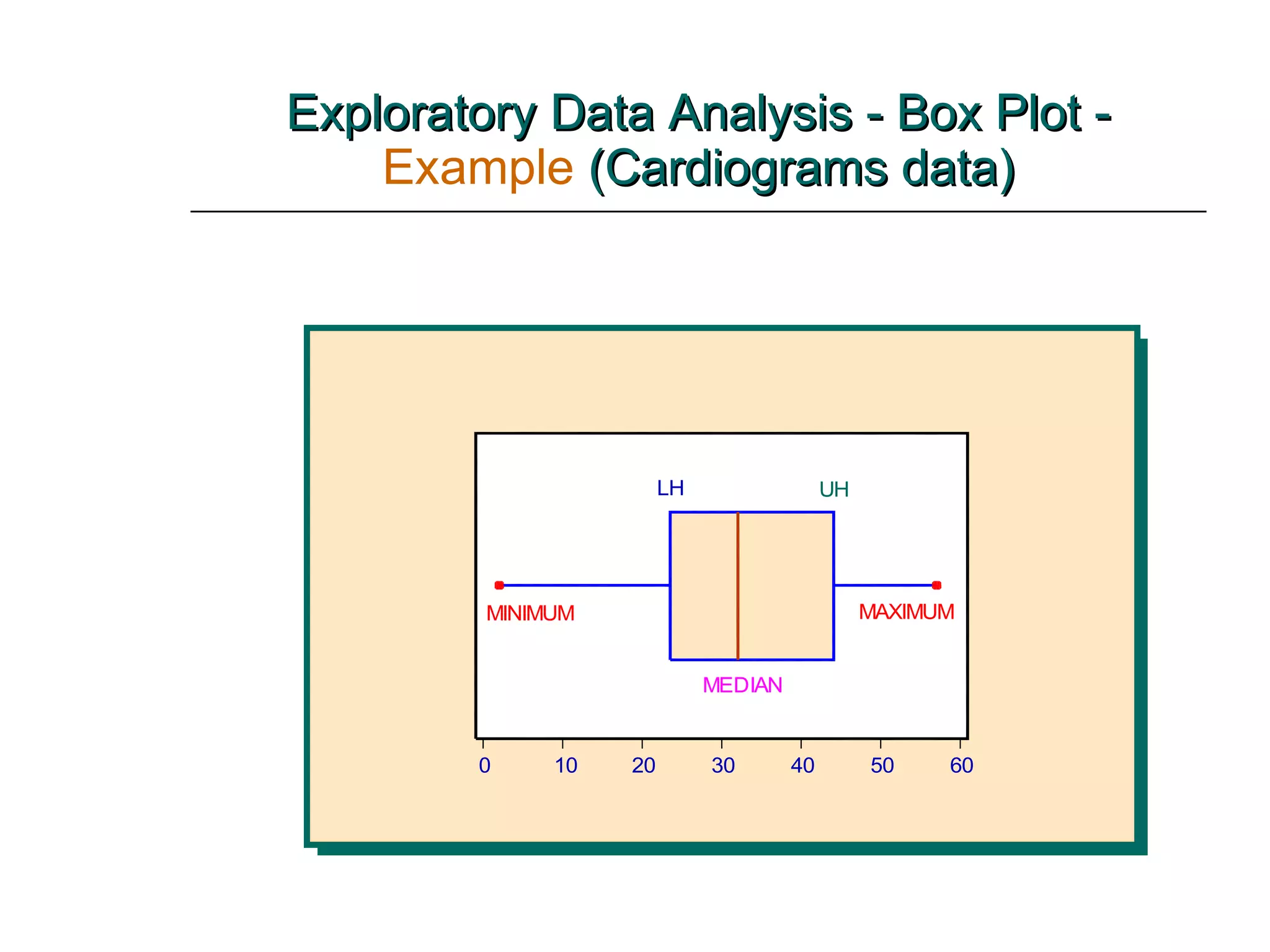
This document provides an overview of key concepts for describing and summarizing data, including measures of central tendency (mean, median, mode), measures of variation (range, variance, standard deviation), and concepts like skewness. It discusses how to calculate and interpret these measures for both grouped and ungrouped data sets. Examples are provided to demonstrate calculating these statistics for different types of data distributions.

















































![Sample Variance for Grouped and Ungrouped Data The sample variance for groupe d data: = s f X f X n n m m 2 2 2 1 [( ) / ] . For ungrouped data, replace X m with the observe X value.](https://image.slidesharecdn.com/chapter3-260110044503-100213035240-phpapp02/75/Chapter-3-260110-044503-60-2048.jpg)

![Sample Variance for Ungrouped Data - Example The sample variance and standa rd deviati on: = = 1500 [(186) 2 s f X f X n n s 2 2 2 1 24 23 2 54 2 54 1 6 [( ) / ] / ] . . . . .](https://image.slidesharecdn.com/chapter3-260110044503-100213035240-phpapp02/75/Chapter-3-260110-044503-62-2048.jpg)










 = 65th percentile. Student did better than 65% of the class.](https://image.slidesharecdn.com/chapter3-260110044503-100213035240-phpapp02/75/Chapter-3-260110-044503-74-2048.jpg)






































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


