Downloaded 11 times











![[1, 2, 3, 4].each do |e|
puts e
end](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-12-2048.jpg)








![Fancy
class Person {
read_write_slots: ['name, 'age, 'city]
def initialize: @name age: @age city: @city {
}
def go_to: city {
if: (city is_a?: City) then: {
@city = city
}
}
def to_s {
"Person: #{@name}, #{@age} years old, living in #{@city}"
}
}](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-22-2048.jpg)






































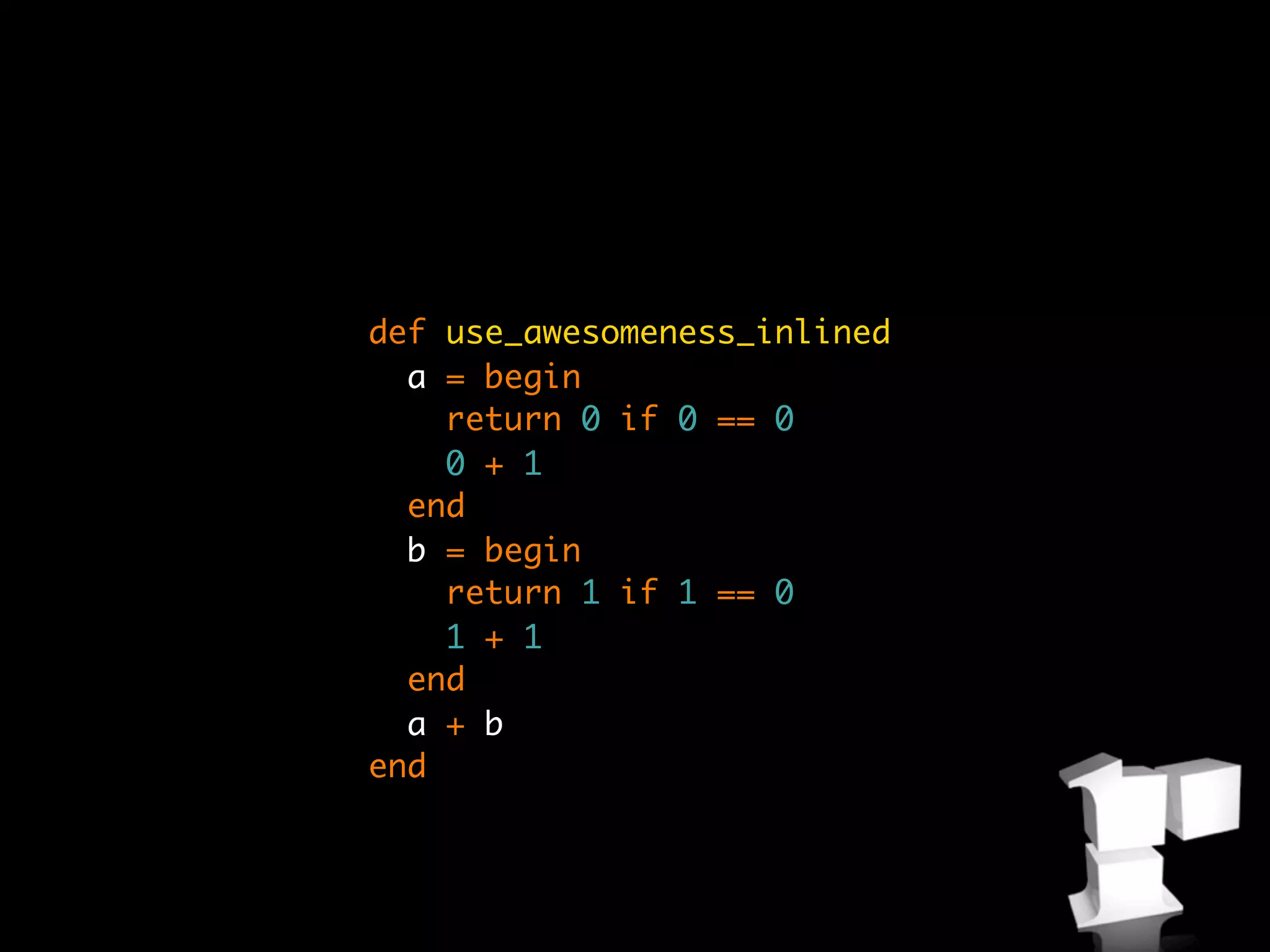
![array = [1] * 1000000
array.each do |element|
puts "element: #{element}"
end](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-65-2048.jpg)









![array = [1] * 1000000
array.each do |element|
puts "element: #{element}"
end](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-76-2048.jpg)
![array = [1] * 1000000
array = [1] * 1000000
i = 0
size = array.size
array.each do |element|
while i < size
puts "element: #{element}"
puts "element: #{array[i]}"
end
i += 1
end](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-77-2048.jpg)
![array = [1] * 1000000
array = [1] * 1000000
i = 0
array.each do |element|
puts "element: #{element}"
== size = array.size
while i < size
puts "element: #{array[i]}"
end
i += 1
end](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-78-2048.jpg)

![array = [1] * 100
array.each do |element|
puts "element: #{element}"
b = 2
end
puts b](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-80-2048.jpg)
![array = [1] * 100
array = [1] * 100
i = 0
size = array.size
array.each do |element|
while i < size
puts "element: #{element}"
puts "element: #{array[i]}"
b = 2
b = 2
end
i += 1
end
puts b
puts b](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-81-2048.jpg)
![array = [1] * 100
array = [1] * 100
i = 0
size = array.size
array.each do |element|
while i < size
puts "element: #{element}"
b = 2 != puts "element: #{array[i]}"
b = 2
end
i += 1
end
puts b
puts b](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-82-2048.jpg)
































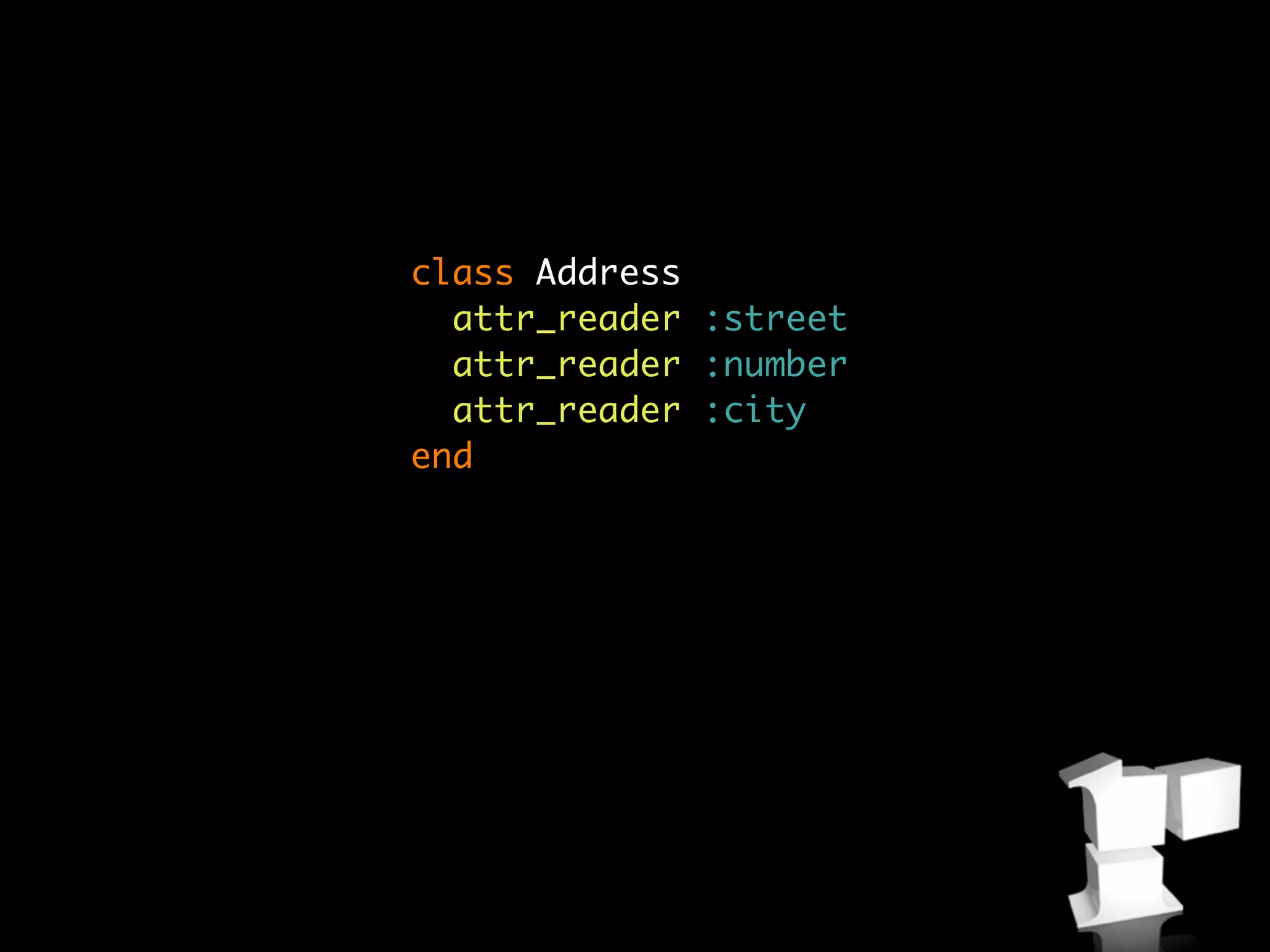
![class Address
attr_reader :street
attr_reader :number
attr_reader :city
end
Address.instance_variable_get("@seen_ivars")
=> [:@street, :@number, :@city]](https://image.slidesharecdn.com/presentation-110606130519-phpapp02/75/Lecture-on-Rubinius-for-Compiler-Construction-at-University-of-Twente-116-2048.jpg)






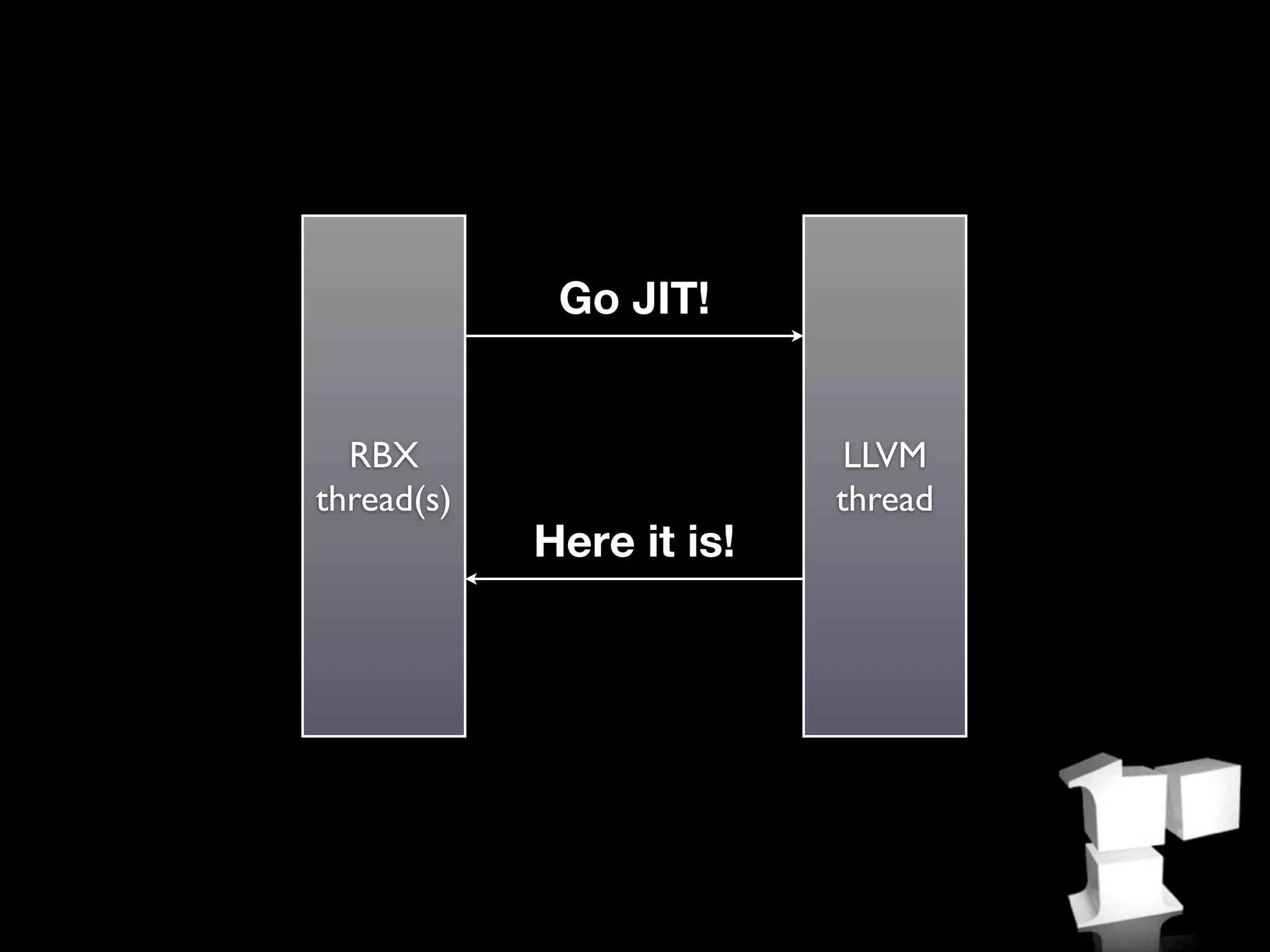
This document summarizes Rubinius, an implementation of the Ruby programming language that includes a bytecode virtual machine written in C++ and Ruby. Some key points: - Rubinius compiles Ruby code to bytecode that runs on its built-in virtual machine. This provides performance improvements over interpreting Ruby code. - The virtual machine is implemented in both C++ and Ruby to provide flexibility. It can inline methods, perform just-in-time compilation, and garbage collect memory. - Rubinius aims to be a complete Ruby implementation while also improving performance through techniques like inline caching, profiling, and garbage collection optimizations.

































































