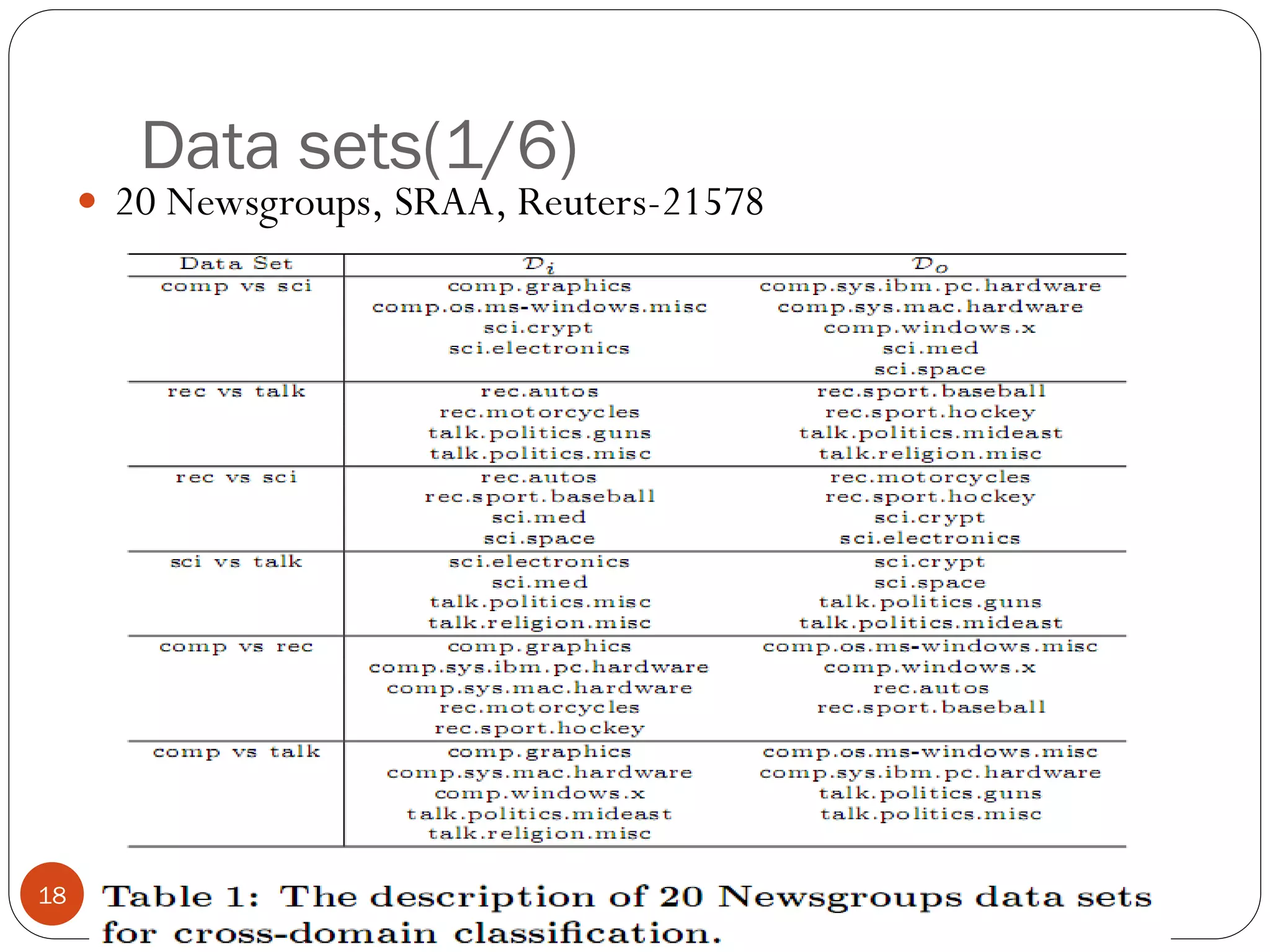
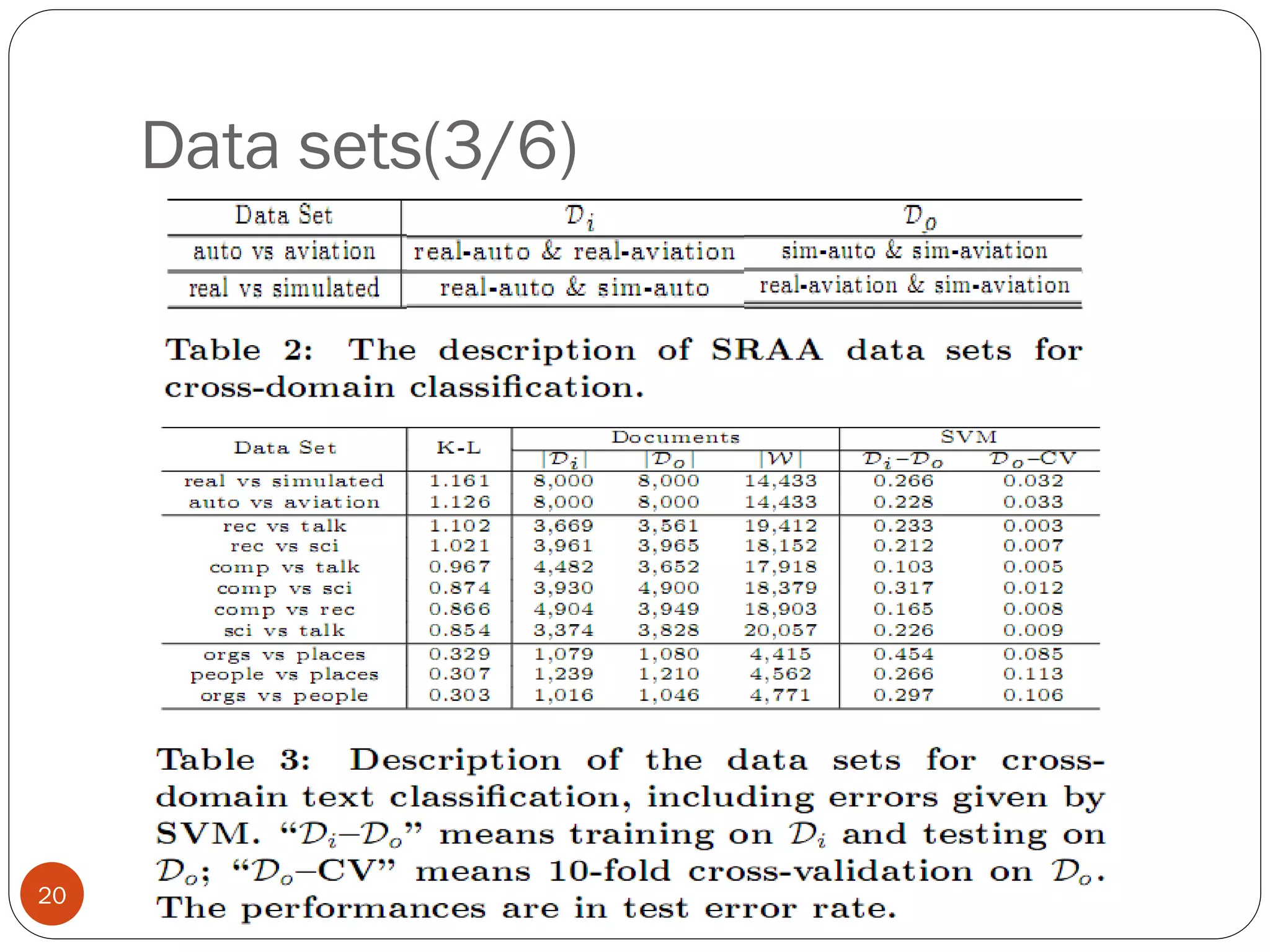
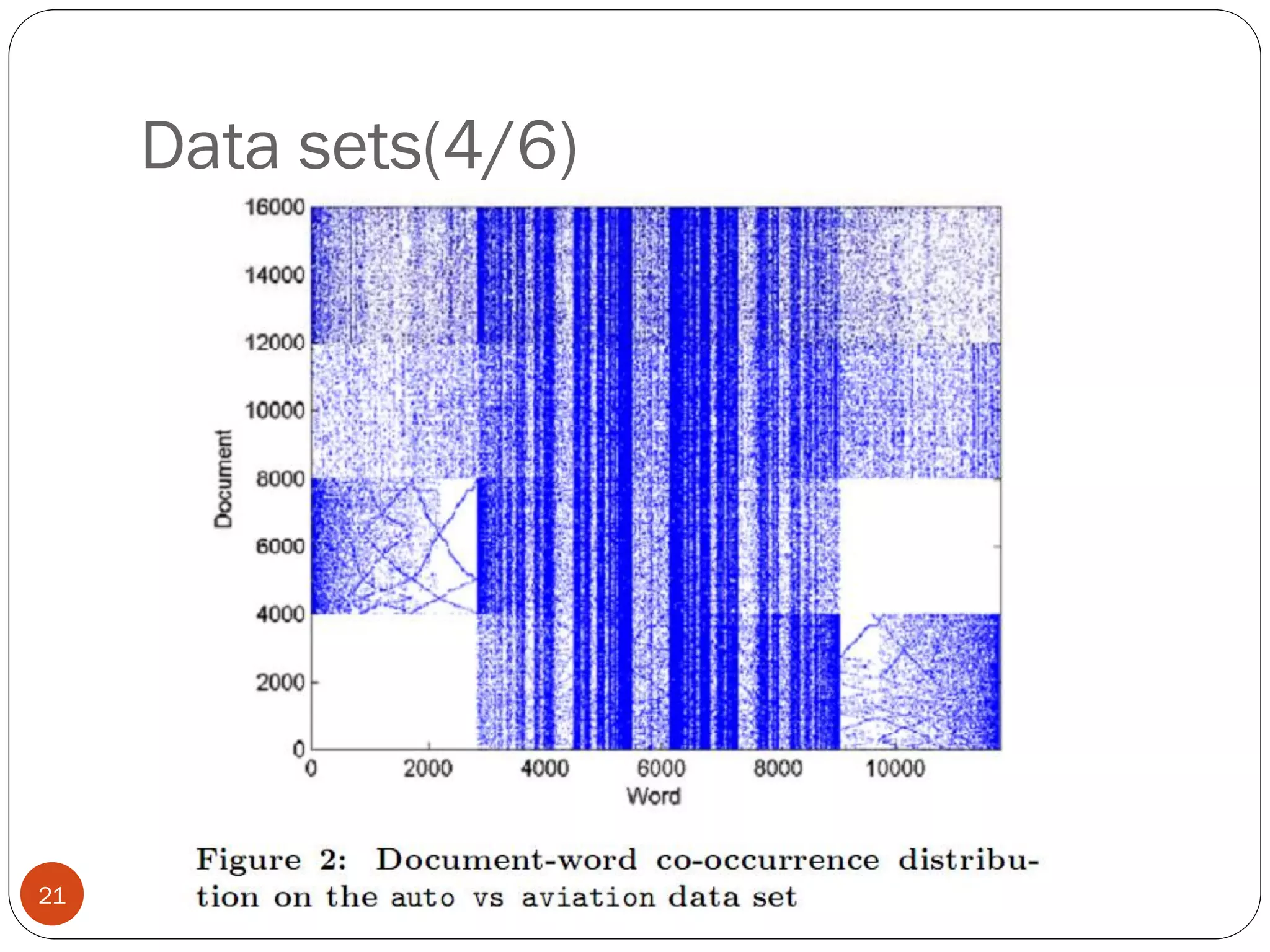
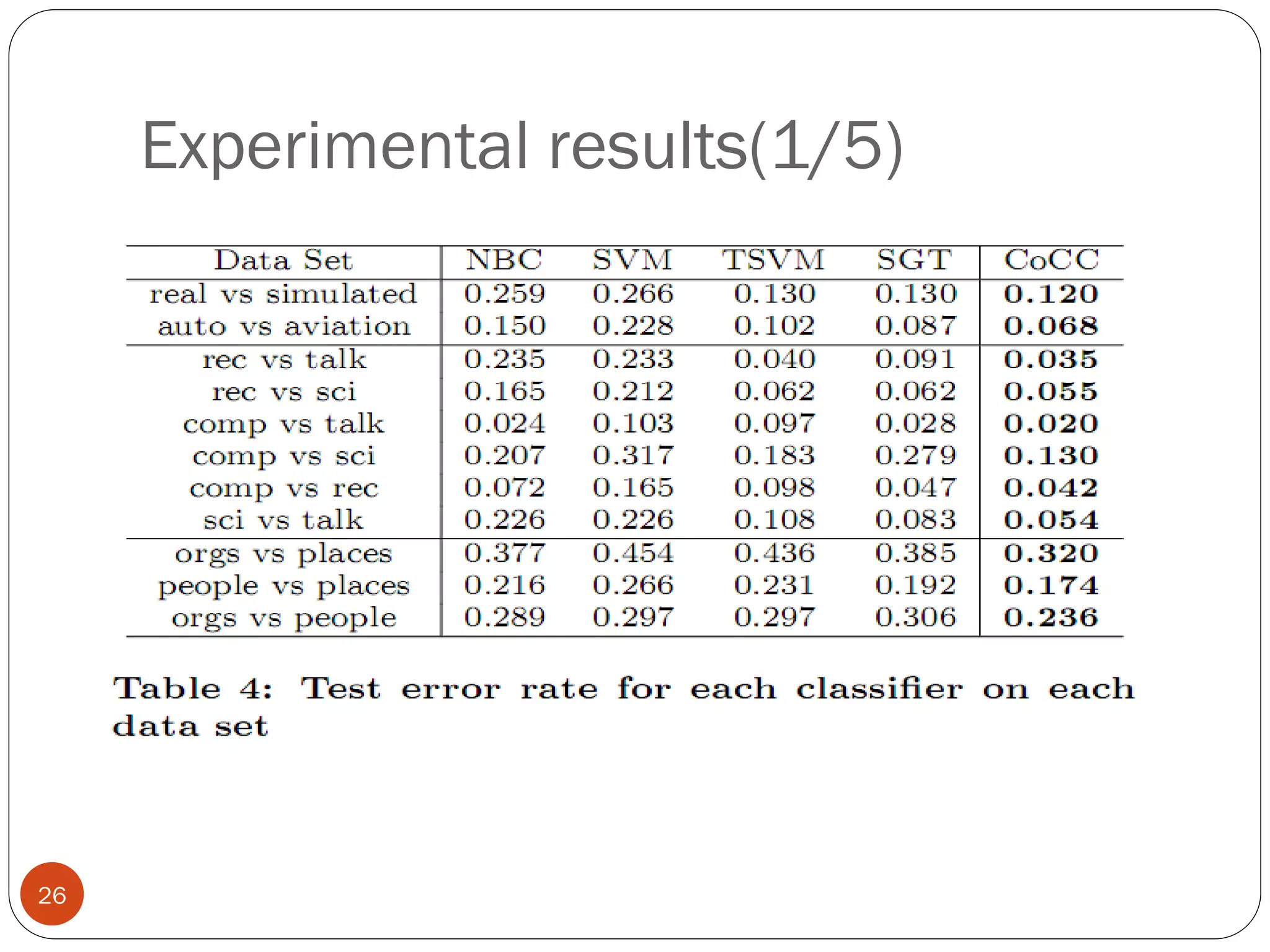
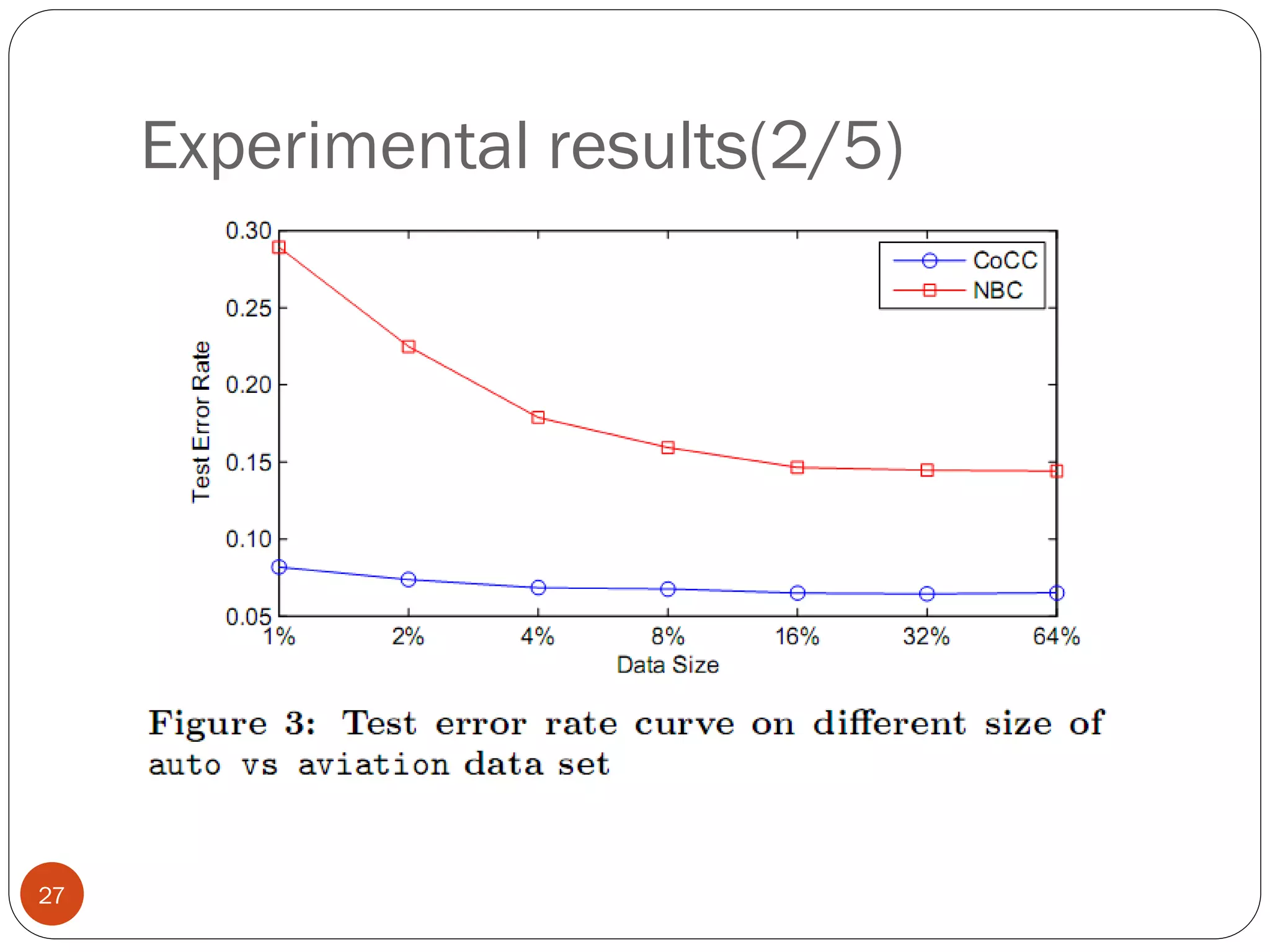
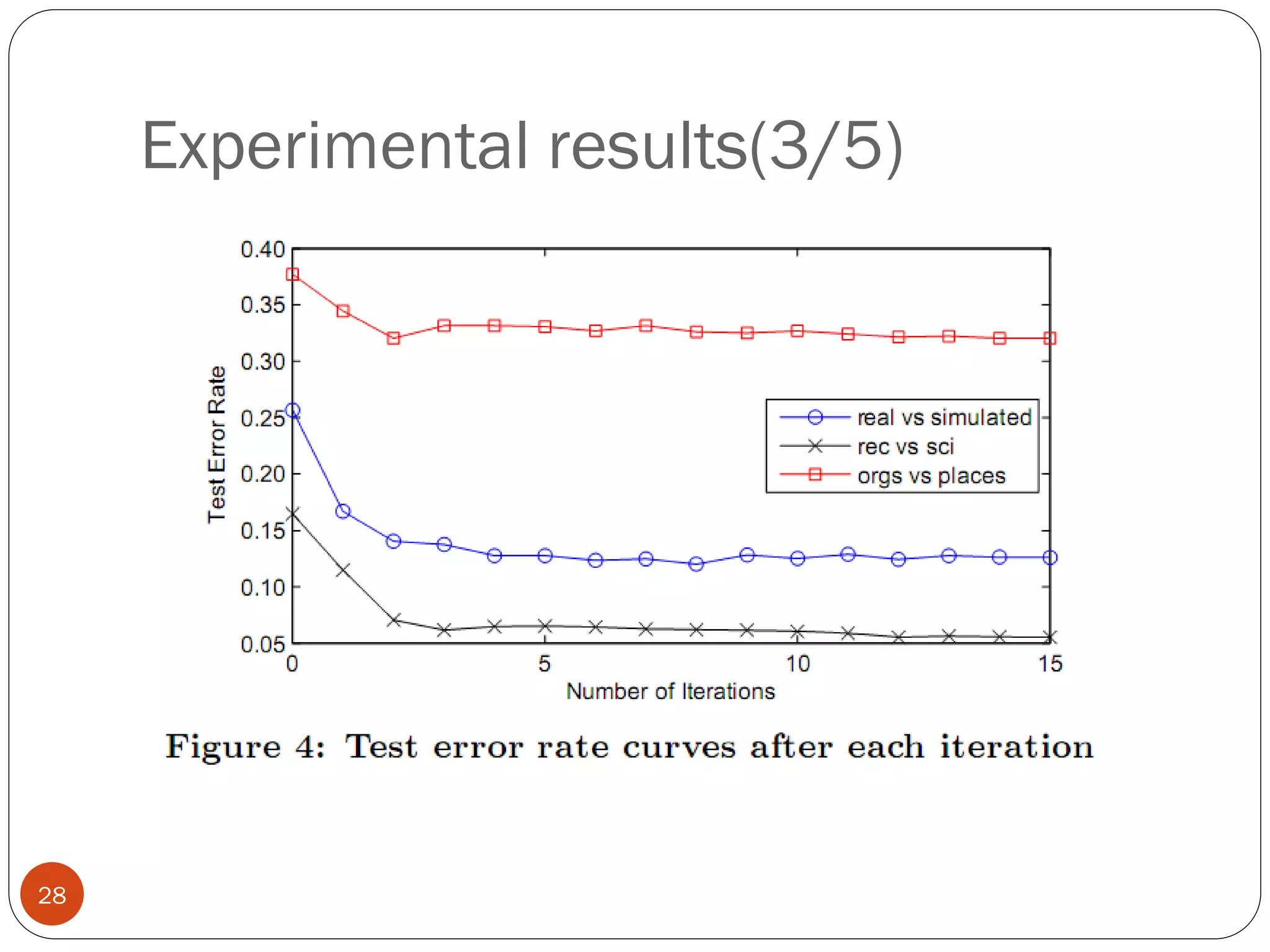
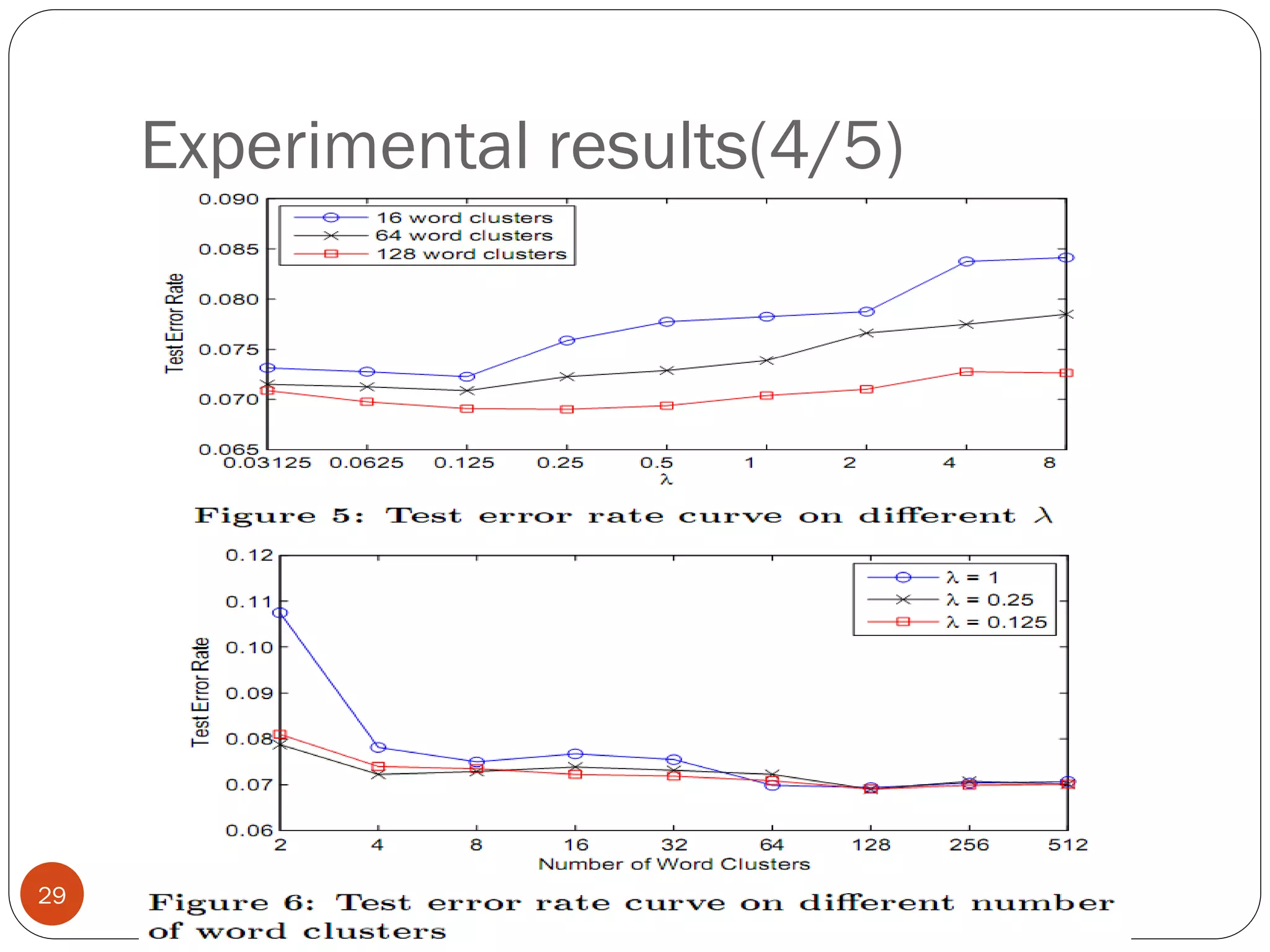
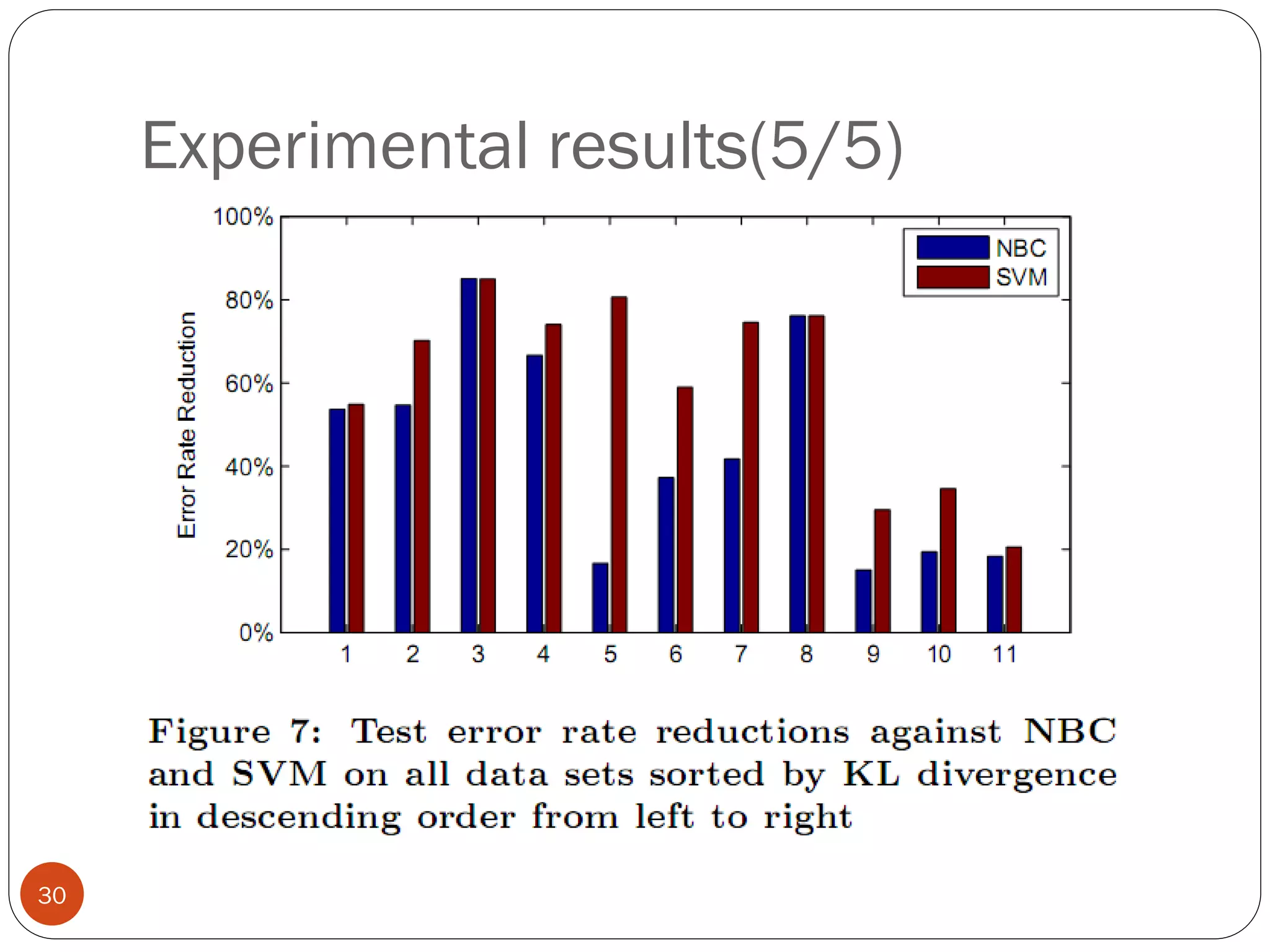
This document presents a co-clustering based classification algorithm (CoCC) for classifying documents from a related but different domain (out-of-domain documents) by utilizing labeled documents from another domain (in-domain documents). CoCC aims to simultaneously cluster out-of-domain documents and words to minimize the loss of mutual information, outperforming traditional supervised and semi-supervised algorithms. While CoCC achieved good performance, its time complexity can be inefficient due to the large number of word clusters. Future work will focus on speeding up the algorithm.