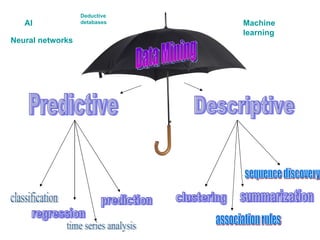
1. Data Mining Predictive Descriptive classification regression time series analysis prediction clustering association rules summarization sequence discovery AI Machine learning Neural networks Deductive detabases
12. The weather data N TRUE high mild rain 14 P FALSE normal hot overcast 13 P TRUE high mild overcast 12 P TRUE normal mild sunny 11 P FALSE normal mild rain 10 P FALSE normal cool sunny 9 N FALSE high mild sunny 8 P TRUE normal cool overcast 7 N TRUE normal cool rain 6 P FALSE normal cool rain 5 P FALSE high mild rain 4 P FALSE high hot overcast 3 N TRUE high hot sunny 2 N FALSE high hot sunny 1 Class Windy Humidity Temperature Outlook Object
![[object Object],[object Object],[object Object],Discovering useful information in large data sets](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)