Download as PDF, PPTX



































































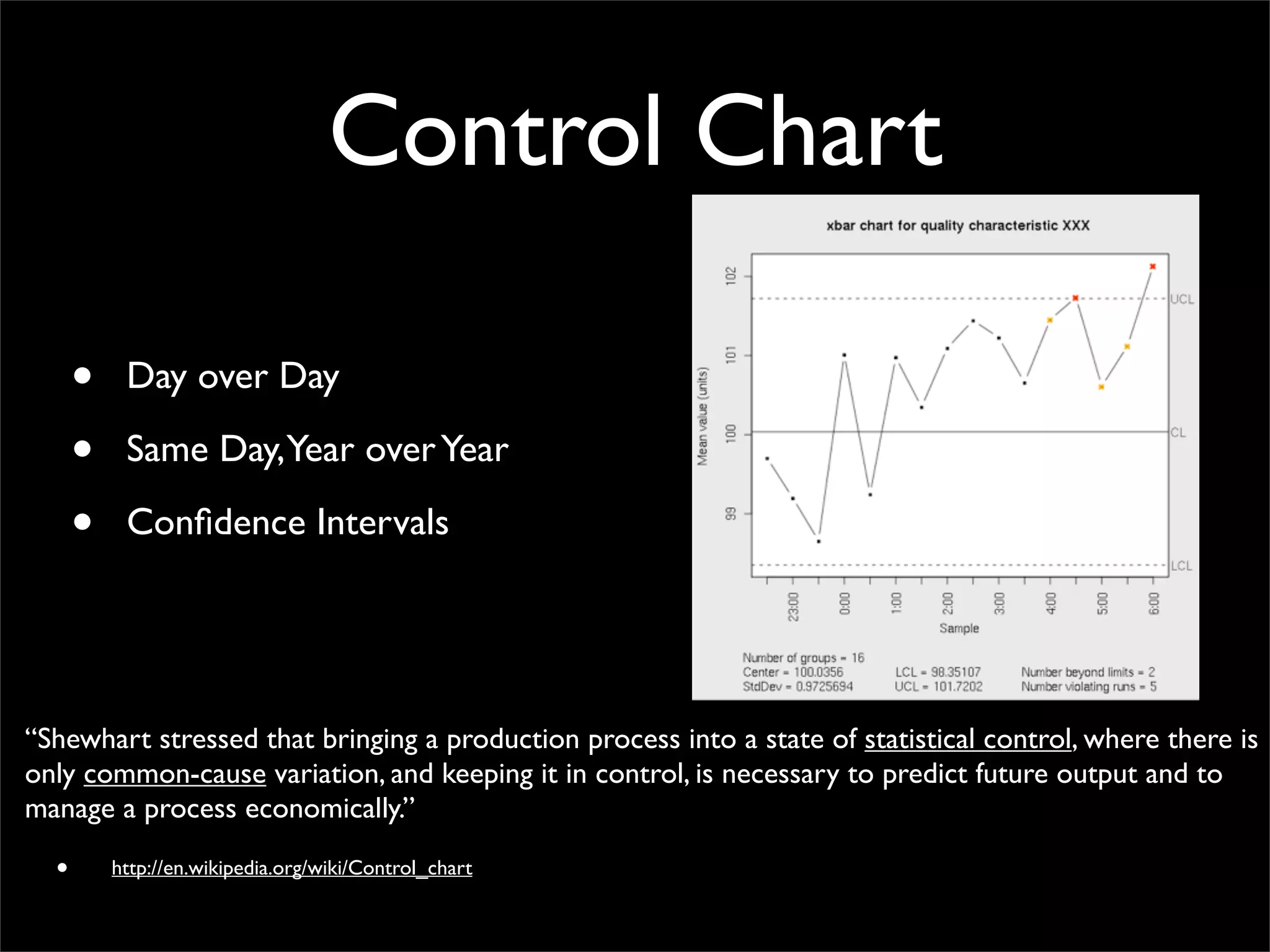
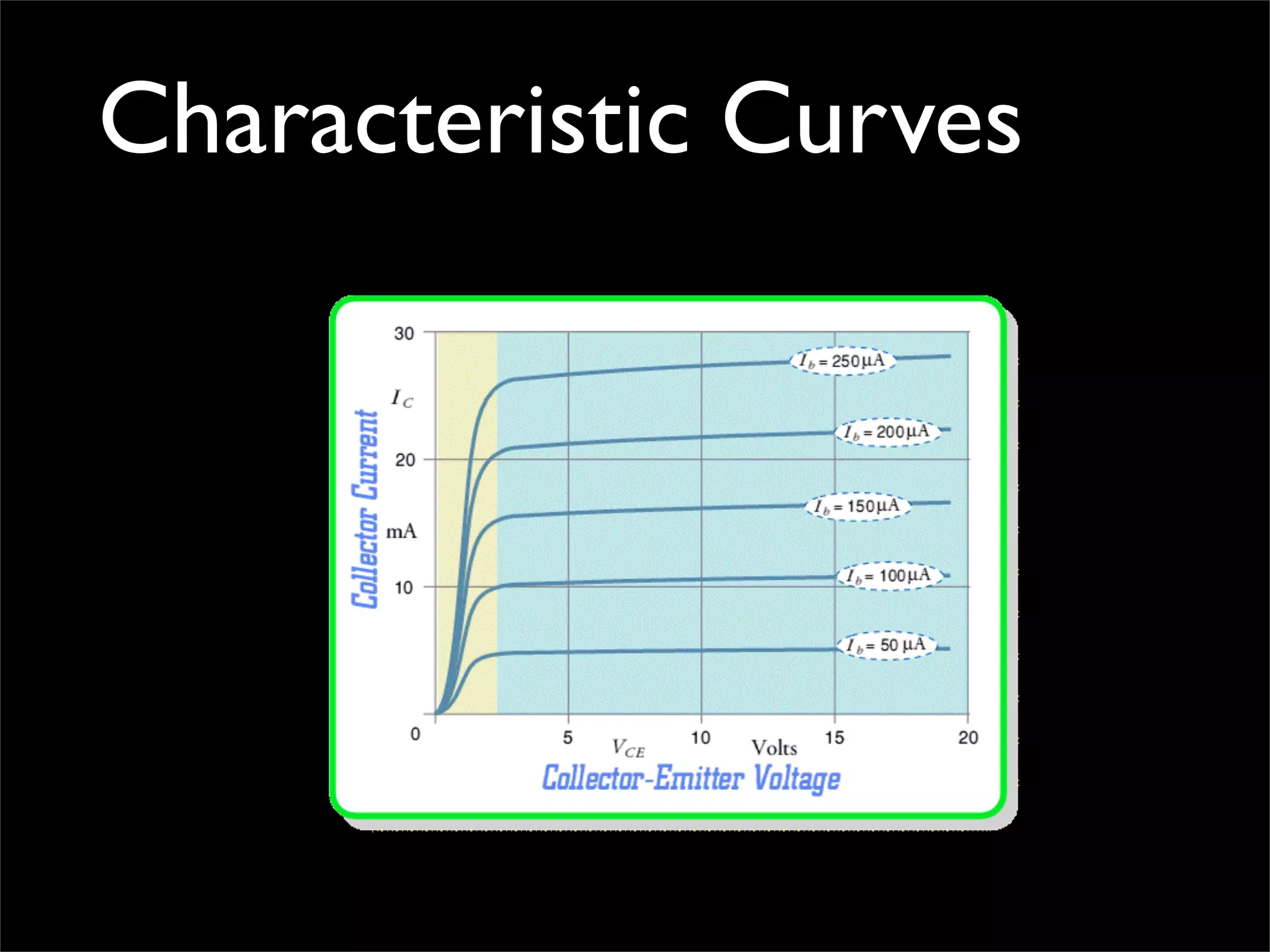
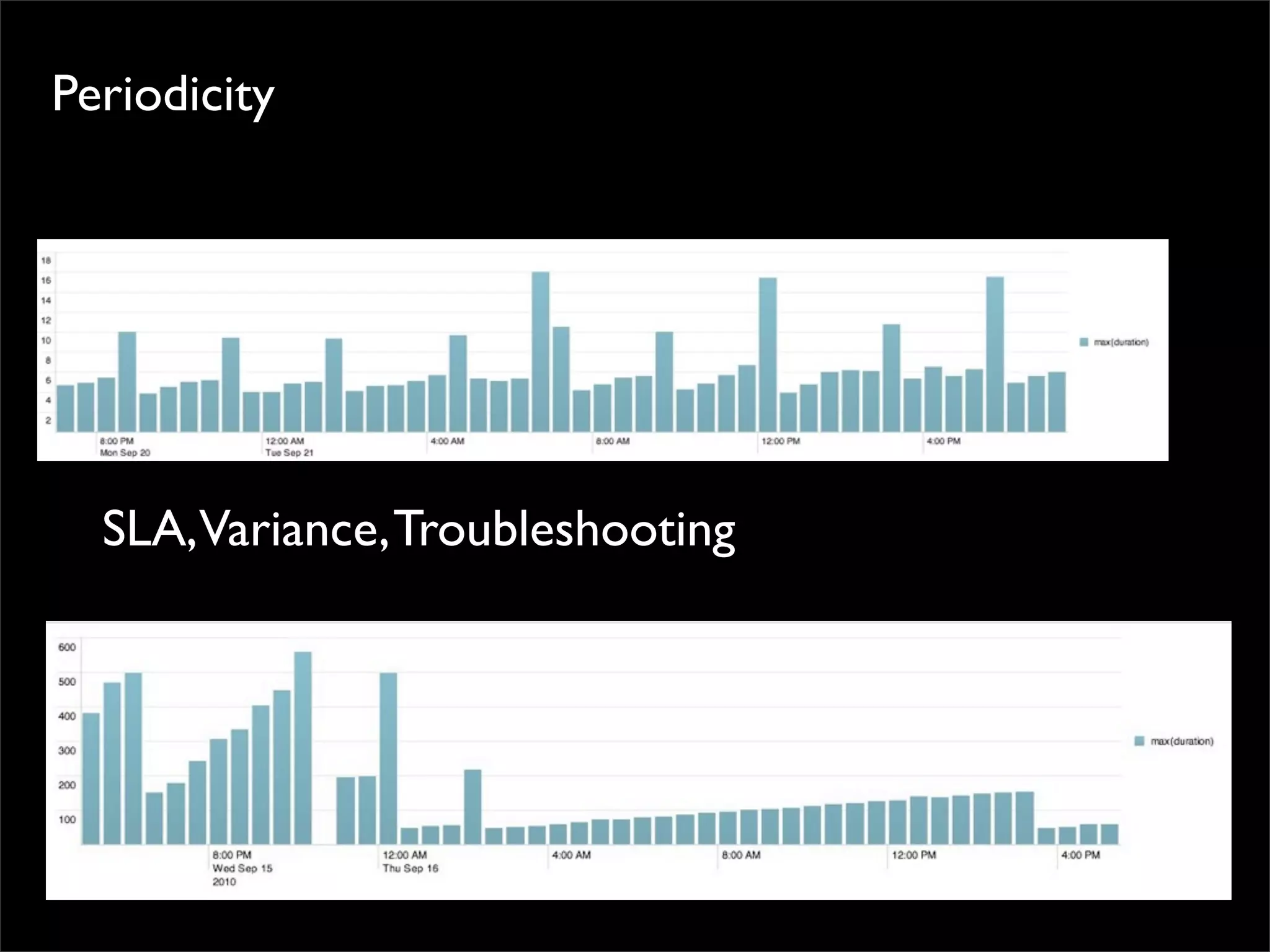









The document outlines design principles and challenges associated with cloud computing, particularly focusing on Amazon EC2 and scalability issues. It emphasizes the importance of minimizing management footprint, understanding costs, and designing for failure while noting the evolution of technology infrastructures. The presentation reflects on past successes and failures in cloud APIs and services, urging consideration of practical implementation over theoretical ideals.


















![[In Control 2010] HTML5](https://cdn.slidesharecdn.com/ss_thumbnails/incontrolorlandohtml5-100302003930-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

