발표자 소개
KAIST전산과 박사
− 전공 : 멀티프로세서 CPU용 일관성 유지 HW
NCSoft 근무
− Alterlife 프로그램 팀장
− Project M(현 Blade & Soul) 프로그램 팀장
− CTO 직속 게임기술연구팀
현 : 한국산업기술대학교 게임공학과 부교수
− 학부 강의 : 게임서버프로그래밍
− 대학원 강의 : 멀티코어프로그래밍, 심화 게임서버
프로그래밍
2-2
3.
참고
삼성 첨단기술연수소에서강의한 내용 반영
− 40시간 강의 (실습 포함) => 뒷부분 만 발췌
대학원 4주 강의 분량의 압축
2-3
4.
2-4
목차
도입 :그래도 멀티쓰레드 프로그램을
하시려구요?
대책
성능
미래 또는 현실
5.
도입
제가 하는발표 들어본 적이 있으신 분?
멀티쓰레드 프로그래밍 경험 있으신 분?
Lock-free 자료 구조가 무엇인지 아시는 분?
2-5
CJ E&M, NDC, KGC2012, 삼성, JCE
6.
도입
멀티쓰레드 프로그래밍의위험성
− “자꾸 죽는데 이유를 모르겠어요”
자매품 : “이상한 값이 나오는데 이유를 모르겠어요”
− “더 느려져요”
2-6
[미] MuliThreadProgramming [mʌ́ltiθred-|proʊgrӕmɪŋ] : 1. 흑마술, 마공
2. 위력이 강대하나 다루기 어려워 잘 쓰이지 않는 기술
7.
도입
멀티쓰레드 프로그래밍의어려움 (한페이지 요약)
− Data Race : 2를 5천만번 더했는데 1억이 안 나오는
경우.
Lock을 사용해 해결
− 컴파일러 : 변수를 참조했는데, 컴파일러가 무시
volatile 키워드로 해결
− CPU : 프로그램을 자기 마음대로 변조
asm mfence; 명령으로 해결
− Cache : -1을 썼는데 65535가 써짐
포인터 주소 확인하기.
− 성능 : 싱글 쓰레드 버전보다 더 느림
Lock 쓰지 말자.
2-7
ABA
문제는?
8.
목차
도입
대책: Lock-free 프로그래밍이 도대체
뭐야?
성능
미래 또는 현실
2-8
9.
대책
현실의 멀티쓰레드프로그램은?
− 여러 쓰레드가 동시에 멀티 코어에서 실행된다.
− 쓰레드간의 데이터 공유 및 동기화는 안전한
Lock-free 자료구조를 통해서 이루어진다.
− 언리얼 3 : 디스플레이 리스트 Queue
− 각종 게임 서버 : Job Queue외 다수
2-9
10.
대책
Lock-free 알고리즘을사용하여야 한다.
사용하지 않으면
− 병렬성 감소
− Priority Inversion
− Convoying
− /* 성능이 떨어지고 랙이 발생한다 */
− /* 작년에 보여드렸어요~~ */
10
대책
Lock-free 알고리즘이란?
−자료구조 및 그것에 대한 접근 방법
예) QUEUE : enqueue, dequeue
예) STACK : push, pop
예) 이진 트리 : insert, delete, search
12
13.
대책
Lock-free 알고리즘이란?
−멀티쓰레드에서 동시에 호출해도 정확한
결과를 만들어 주는 알고리즘
STL 탈락.
− Non-Blocking 알고리즘
다른 쓰레드가 어떤 상태에 있건 상관없이 호출이
완료된다.
− 호출이 다른 쓰레드와 충돌하였을 경우 적어도
하나의 승자가 있어서, 승자는 delay없이 완료
된다.
13
14.
대책
(보너스)
− Wait-free알고리즘은?
호출이 다른 쓰레드와 충돌해도 모두 delay없이
완료 된다.
추가 상식
− LOCK을 사용하지 않는다고 lock-free
알고리즘이 아니다!!!
− LOCK을 사용하면 무조건 lock-free알고리즘이
아니다.
14
대책
예) Blocking알고리즘
16
EnterCriticalSection(&mylock);
sum = sum + 2;
LeaveCriticalSection(&mylock);
EnterCriticalSection(&mylock);
q.push(35);
LeaveCriticalSection(&mylock);
while (dataReady == false);
asm mfence;
temp = g_data;
17.
대책
왜 Blocking인가?
−dataReady에 true가 들어가지 않으면 이
알고리즘은 무한 대기, 즉 다른 쓰레드에서
무언가 해주기를 기다린다.
− 여러 가지 이유로 dataReady에 true가
들어오는 것이 지연될 수 있다.
Schedule out, 다른 쓰레드 때문에 대기
17
while (dataReady == false);
temp = g_data;
대책
CAS?
− CAS가없이는 대부분의 non-blocking
알고리즘들을 구현할 수 없다.
Queue, Stack, List…
− CAS를 사용하면 모든 싱글쓰레드 알고리즘
들을 Lock-free 알고리즘으로 변환할 수 있다!!!
− Lock-free 알고리즘의 핵심
20
21.
대책
정리
− Lock-free알고리즘을 써야한다.
성능때문이다.
CAS가 꼴 필요하다.
CAS
− CAS(&A, old, new);
− 의미 : A의 값이 old면 new로 바꾸고 true를 리턴
− 다른 버전의 의미 : A메모리를 다른 쓰레드가 먼저
업데이트 해서 false가 나왔다. 모든 것을 포기하라.
21
22.
대책
Lock-free 알고리즘은어떻게 구현되는가?
알고리즘의 동작이란?
− 기존의 자료구조의 구성을 다른 구성으로 변경하거나
자료구조에서 정보를 얻어내는 행위
22
3
Head Tail
1 9X
3
Head
Tail
1 9X
push(35);
35
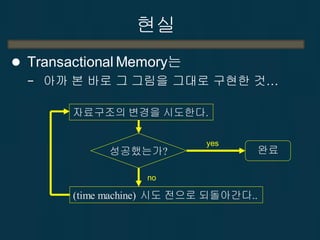
23.
대책
Lock-free 알고리즘은어떻게 구현되는가?
23
자료구조의 변경을 시도한다.
성공했는가? 완료
yes
no
(time machine) 시도 전으로 되돌아간다..
???
???
24.
대책
Lock-free 알고리즘은어떻게 구현되는가?
앞의 알고리즘이 불가능 하므로
24
자료구조의 변경을 시도한다.
but, 다른 쓰레드가 먼저 변경했으면 시도 취소.
성공했는가? 완료
yes
no
현재의 자료구조를 파악한다.
25.
대책
25
자료구조의 변경을 시도한다.
but,다른 쓰레드가 먼저 변경했으면 시도 취소.
CAS
while (true) {
int old_sum = sum;
if (true == CAS(&sum, old_sum, old_sum+2)) break;
}
결과물
EnterCriticalSection(&mylock);
sum = sum + 2;
LeaveCriticalSection(&mylock);
26.
대책
26
자료구조의 변경을 시도한다.
but,다른 쓰레드가 먼저 변경했으면 시도 취소.
CAS
LF_QUEUE::push(int x) {
Node *e = New_Node(x);
while (true) {
Node *last = tail;
Node *next = last->next;
if (last != tail) continue;
if (NULL != next) continue;
if (CAS(&(last->next), NULL, e,
&tail, last, e)) return;
}
}
QUEUE::push(int x) {
Node *e = new Node(x);
tail->next = e;
tail = e;
}
27.
대책
27
현실
LF_QUEUE::push(int x) {
Node*e = New_Node(x);
while (true) {
Node *last = tail;
Node *next = last->next;
if (last != tail) continue;
if (NULL != next) continue;
if (CAS(&(last->next), NULL, e,
&tail, last, e)) return;
}
}
LF_QUEUE::push(int x) {
Node *e = New_Node(x);
while (true) {
Node *last = tail;
Node *next = last->next;
if (last != tail) continue;
if (NULL == next) {
if (CAS(&(last->next), NULL, e)) {
CAS(&tail, last, e);
return;
}
} else CAS(&tail, last, next);
} }
하지만 2개의 변수에 동시에
CAS를 적용할 수 는 없다!
28.
대책
…
− 알고리즘이많이 복잡하다.
− 그래서 작성시 실수하기가 쉽다.
− 실수를 적발하기가 어렵다.
하루에 한두 번 서버 크래시
가끔 가다가 아이템 증발
− 제대로 동작하는 것이 증명된 알고리즘을
사용해야 한다.
28
29.
대책
결론
− 믿을수 있는 non-blocking container들을
사용하라.
Intel TBB, Visual Studio PPL
− 자신을 포함한 출처가 의심스러운 알고리즘은
정확성을 증명하고 사용하라.
정확성이 증명된 논문에 있는 알고리즘은 OK.
29
30.
목차
도입
대책
성능 : 데스크탑에서 동접 1만 서버를
만들어 보자.
미래 또는 현실
30
31.
성능
간단한 MMORPG서버를 만들어 보자
− 1000x1000 world
− 60x60 sector
− 시야 30
− 1000마리의 몬스터
플레이어 접근 시 자동 이동 및 공격
− 이동/공격/채팅 가능
− Windows에서 IOCP로 구현
32.
성능
성능 향상을위해
− 시야 처리시 검색 성능을 위해 월드를 sector로
분할하여 주위 sector만 검색
병렬 검색을 위해 tbb::concurrent_hash_map사용
− 몬스터 AI 처리를 모든 쓰레드에서 균등하게 나누어
처리하기 위해 timer와 event시스템 사용
timer queue 병렬 등록을 위해
tbb::concurrent_priority_queue를 사용
− 객체 id의 재사용을 막고 메모리 재사용을 위해 객체
id와 객체 배열의 인덱스를 쌍으로 관리
<id, index>의 병렬 검색을 위해 tbb::concurrent_hash_map
사용
33.
성능
성능 측정용DummyClient
− 서버에게 부하를 걸 수 있도록 여러 명의 Player를
에뮬레이션 해주는 프로그램
− 사람이 플레이 하는 것과 비슷하게 Player를
주기적으로 랜덤한 방향으로 이동 시킴
− 한명의 유저당 하나의 소켓 연결을 하므로 서버에서는
일반 클라이언트 접속과 DummyClient접속이 서로
차이가 없음
− 훌륭한 UNIT TESTER
− /* 이것도 IOCP로 구현, Direct3D로 유저 분포 실시간
디스플레이 */
현실
멀티쓰레드 프로그래밍도우미 (1/2)
− Intel TBB
좋은 성능, 유용한 라이브러리
Concurrent 자료 구조
− Visual Studio PPL
Intel TBB와 유사
− OpenMP
컴파일러 레벨에서 병렬 프로그램 API를 제공
성능과 골치 아픈 문제들은 그대로
38.
현실
멀티쓰레드 프로그래밍도우미 (2/2)
− CUDA, OpenCL, DirectCompute
멀티코어 활용이 아니라 GPU활용
렌더링 하느라 바쁜 GPU를 건드리지 마세요.
I/O처리가 불가능해서 서버 Core Logic에는 적용
불가능
39.
현실
암담한 현실
−Blocking Algorithm
성능 저하, priority inversion, convoying
Deadlock!
− Non-blocking Algorithm
높은 난이도로 인한 생산성 저하
어쩌라고????
Transactional Memory!
현실
어떻게 가능한가???
1.transaction 구간에서 읽고 쓴 메모리를 다른
쓰레드에서 접근했는지 검사한다.
write는 실제 메모리에 쓰지 않고 잠시 대기
2. 다른쓰레드에서의 접근이 있었으면 모든
업데이트를 무효화 한 후 다시 시도.
3. 다른쓰레드에서의 접근이 없었다면 transaction
구간에서의 update를 실제 메모리에 update
트랜잭션 메모리의 구현
Haswell의 HTM
− 복수개의 메모리에 대한 Transaction을
허용한다.
Cache Line 8개 까지
− CPU에서 transaction 실패시의 복구를
제공한다.
메모리와 레지스터의 변경을 모두 Roll-back한다.
− Visual Studio 2012, update 2에서 지원
2-49
50.
트랜잭션 메모리의 구현
하드웨어 트랜잭션 메모리 예제
2-50
DWORD WINAPI ThreadFunc(LPVOID lpVoid)
{
for (int i=0;i<500000000 / num_thread;++i) {
while (_xbegin() != _XBEGIN_STARTED) _xabort(0);
sum += 2;
_xend();
}
return 0;
}
미래
HTM이 업그레이드되어서 보급되면
끝인가?
− 쓰레드가 많아 질 수록 충돌확률이 올라가
TM의 성능이 떨어진다.
− 64Core 정도가 한계일 것이라고 예측하고
있다. (2010 GameTech, Tim Sweeny)
55.
미래
왜 쓰레드사이에충돌이 생기는가?
− C 스타일 언어를 사용하기 때문이다.
공유 메모리
side effect
해결책은? C 비슷한 언어를 버린다.
− 대신 함수형 언어 사용
공유 메모리 없고 side effect없음
56.
새로운 언어
주목받고있는 언어
− 하스켈
순수 함수형 언어로 1990년에 개발
개념은 뛰어나나 난이도로 인해 많이 사용되지 못하고 있음.
− Earlang
에릭슨에서 전자 계산기용으로 1982년에 개발
Scalable한 서버 시스템에 자주 사용되고 있음
2010GDC
정리
Lock-free 알고리즘이무엇인가?
− 어떤 조건을 만족해야 하는가?
− 어떻게 구현되는가?
− 왜 어려운가?
− 하지만 왜 써야만 하는가.
멀티쓰레드 프로그래밍의 미래.
− Transactional Memory
진격의 INTEL
− 새로운 언어의 필요
2-58
59.
NEXT
다음 주제(내년???)
−Lock-free search : SKIP-LIST
− ABA Problem, aka 효율적인 reference
counting
− 고성능 MMO서버를 위한 non-
blocking자료구조의 활용
2-59
60.
Q&A
연락처
− nhjung@kpu.ac.kr
−발표자료 : ftp://210.93.61.41 id:ndc21 passwd: <바람의나라>
− Slideshare에 올릴 예정.
참고자료
− Herlihy, Shavit, “The Art of Multiprocesor Programming,
Revised”, Morgan Kaufman, 2012
2-60





![도입
멀티쓰레드 프로그래밍의 위험성
− “자꾸 죽는데 이유를 모르겠어요”
자매품 : “이상한 값이 나오는데 이유를 모르겠어요”
− “더 느려져요”
2-6
[미] MuliThreadProgramming [mʌ́ltiθred-|proʊgrӕmɪŋ] : 1. 흑마술, 마공
2. 위력이 강대하나 다루기 어려워 잘 쓰이지 않는 기술](https://image.slidesharecdn.com/kgc2013-3-130926104127-phpapp01/85/2-6-320.jpg)























































![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)
![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)





![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NDC17] Unreal.js - 자바스크립트로 쉽고 빠른 UE4 개발하기](https://cdn.slidesharecdn.com/ss_thumbnails/wjkqukgsqgm2vger5dnt-signature-2cf736e9b897e2aaaa6315f9d31d6951ba19fae7560fe278cefb4644ac0753c6-poli-170428114140-thumbnail.jpg?width=640&height=640&fit=bounds)
![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[0903 구경원] recast 네비메쉬](https://cdn.slidesharecdn.com/ss_thumbnails/0903recast-111221053315-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 2009] 행동 트리로 구현하는 인공지능](https://cdn.slidesharecdn.com/ss_thumbnails/sozq6jekqxsztuufax7q-signature-36c67eff9cc876072bc7cbb8cc904a6ded5de90832dee56b9f72b022c381012d-poli-150121233510-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[0410 박민근] 기술 면접시 자주 나오는 문제들](https://cdn.slidesharecdn.com/ss_thumbnails/0410-111117021726-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[2B7]시즌2 멀티쓰레드프로그래밍이 왜 이리 힘드나요](https://cdn.slidesharecdn.com/ss_thumbnails/2b72-140930004949-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


















