목차
• 시작하며…
• Lock-free
•Lock-free Queue
• Push( T elem )
• Pop( )
• ABA 문제
• 성능 측정
• 마치며…
• 더 자세한 코드를 보고 싶으시다면...
2
3.
시작하며…
이 ppt는 개인프로젝트에서 Task Queue로 사용하기 위해서 구현해 본 Lock-
free Queue에 대해서 다룹니다.
Lock-free Queue의 코드가 왜 이렇게 짜여졌는지 알아보고 최종적으로 성능 체
크도 해보도록 하겠습니다.
들어가기 전에 다음 사항을 참고 바랍니다.
3
4.
시작하며…
• Ndc2014 시즌2 : 멀티쓰레드 프로그래밍이 왜 이리 힘드나요? (Lock-free
에서 Transactional Memory까지) 에서 발췌
4
Lock-free
• Lock-free는 Mutex와같은 동기화 요소를 사용하지 않고 공유 데이터에
안전하게 접근하는 것을 뜻합니다.
• Lock-free는 Compare And Swap 이라고 하는 CAS 연산자를 통해 이뤄
집니다.
6
7.
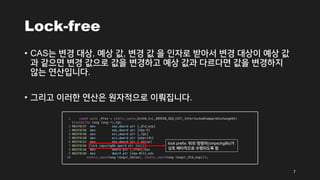
Lock-free
• CAS는 변경대상, 예상 값, 변경 값 을 인자로 받아서 변경 대상이 예상 값
과 같으면 변경 값으로 값을 변경하고 예상 값과 다르다면 값을 변경하지
않는 연산입니다.
• 그리고 이러한 연산은 원자적으로 이뤄집니다.
7
lock prefix: 뒤의 명령어(cmpxchg8b)가
상호 배타적으로 수행되도록 함
Lock-free Queue
• 그럼Lock-free Queue는 어떻게 구현할 수 있을까요.
여기서 구현한 Queue는 2가지 메서드를 제공합니다.
1. Push( T elem ) : Queue의 끝에 원소를 삽입합니다.
2. T Pop( ) : Queue의 처음에서 원소를 빼냅니다.
• 이제 각 메서드가 어떻게 구현 됐는지 하나씩 보도록 하겠습니다.
9
10.
Push( T elem)
• 실제 코드를 보기 전에 그림을 통해 Push 메서드의 동작을 알아보겠습니다.
• 이 Queue는 생성되면 다음과 같이 데이터가 없는 더미 노드를 Head와 Tail
이 가리키고 있는 초기 상태를 가집니다.
10
Head Tail
Dummy Next
11.
Push( T elem)
• 여기에 새로운 데이터를 Tail에 추가한다면…
1. Tail이 가리키는 더미 노드의 Next가 새로운 데이터 노드를 가리키게 합니
다.
11
Head Tail
Dummy Next
New
Data
Next
12.
Push( T elem)
2. 이제 Tail이 새로운 노드를 가리키도록 이동합니다.
메서드가 해야 할 일은 매우 간단합니다. 그럼 코드를 볼까요.
12
Head Tail
Dummy Next
New
Data
Next
13.
Push( T elem)
• Push 메서드의 전체 코드입니다.
• lock-free 알고리즘에서 발생할
수 있는 문제를 해결하기 위한
추가 코드로 인해 앞에서 알아본
Push 메서드의 동작에 비해 코드
가 복잡해 졌습니다.
• 우선은 Push 메서드의 동작에
집중하여 코드를 살펴보겠습니다.
13
14.
Push( T elem)
1. 새로운 데이터를 위한 노드를
할당합니다.
2. 이제 삽입 시도가 시작됩니다.
우선 Tail이 가리키고 있는
노드(last)와 해당 노드의 다음
노드(next)를 지역 변수에 저장
해 놓습니다.
14
1
2
15.
Push( T elem)
3. Tail이 변하지 않았는지 검사합
니다.
Tail이 변했다면 이전에 읽어 놓은
next도 정상적인 값이 아니기 때문
에 재시도 해야 합니다.
4. next의 nullptr여부에 따라 따른
동작을 하게 됩니다.
우선 nullptr 이 아닐 때를 보겠습
니다.
15
3
4
16.
Push( T elem)
5. next가 nullptr이 아니라는 의미
는 다른 스레드가 Tail이 가리키는
노드의 next는 변경했지만 Tail을
아직 변경하지 못한 경우입니다.
이 경우에는 능동적으로 tail을
next로 변경해 줍니다.
왜 이렇게 해야 하는지 그림으로
살펴보겠습니다.
16
5
변경 대상 예상 값 변경 값
= m_tail의 값이 last와 같으면
m_tail을 newTail로 갱신
17.
Push( T elem)
m_tail.CompareExchange( last, newTail )이 실행되기 전 상태는 아래
그림과 같습니다.
Next에 새로운 노드를 연결했지만 Tail은 갱신되지 않은 상태입니다. 이 상태
에서 스케줄러에 의해 실행이 다른 스레드로 넘어 갔다고 생각해봅시다.
17
Head Tail
Dummy Next
New
Data
Next
18.
Push( T elem)
• 다른 스레드에서도 새로운 데이터를 삽입하고자 합니다. Queue는 삽입
순서가 보장되야 합니다. 먼저 삽입된 데이터 보다 앞에 삽입할 수 없습니다.
• 현재 Queue의 Tail이 가리키는 노드의 Next가 nullptr이 아니기 때문에 tail
의 위치에 값을 삽입할 수 없습니다.
18
Head Tail
Dummy Next
New
Data
Next
19.
Push( T elem)
• 여기서 2가지 선택을 할 수 있습니다.
1. 원래 스레드가 Tail을 이동시킬 때 까지 기다린다.
2. 자신이 직접 Tail을 옮긴다.
19
Head Tail
Dummy Next
New
Data
Next
20.
Push( T elem)
• 원래 스레드가 Tail을 옮기기를 기다린다면 이제 다른 모든 스레드는 원래
스레드의 작업을 기다리는 블로킹 상태가 됩니다.
• 이후 발생하는 모든 Push연산은 원래 스레드가 다시 실행 되기 전까지 모두
실패하게 됩니다. 이런 상황을 Convoying이라고 합니다.
20
Head Tail
Dummy Next
New
Data
Next
21.
Push( T elem)
• 이런 블로킹 알고리즘은 이제 더 이상 Lock-free라고 할 수 없습니다.
• Lock-free는 다른 스레드의 상태에 상관 없이 실행되야 합니다. 그래서
능동적으로 Tail을 옮깁니다. 본래의 스레드는 로컬에 저장중인 last가 Tail
과 달라졌기 때문에 CAS가 실패하게 되므로 문제 없이 동작합니다.
21
Head Tail
Dummy Next
New
Data
Next
22.
Push( T elem)
다시 돌아와서 next 가 nullptr일
때를 살펴보겠습니다.
6. next가 nullptr 이라면 Tail이
Queue의 마지막을 가리키고
있으므로 Tail이 가리키는 노드의
next가 새로운 노드를 가리키도록
변경합니다.
22
6
23.
Push( T elem)
7. next가 변경되었다면 삽입이
성공한 것입니다. 마지막으로 tail
을 옮겨주고 루프에서 나옵니다.
23
7
24.
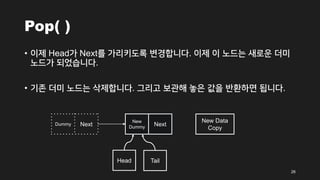
Pop( )
• 이제는Pop 메서드 입니다. Pop 메서드도 마찬가지로 그림을 통해 동작을
먼저 알아보겠습니다.
• Queue의 상태는 다음과 같습니다.
24
Head Tail
Dummy Next
New
Data
Next
25.
Pop( )
• Pop은Push에 비해서 간단합니다. 지금 Queue는 Head와 Tail이 동일한
노드를 가리키고 있지 않기 때문에 비어 있지 않습니다. 따라서 Head의
Next가 가리키는 노드의 값을 별도의 변수에 저장해 놓습니다.
25
Head Tail
Dummy Next
New
Data
Next
New Data
Copy
26.
Pop( )
• 이제Head가 Next를 가리키도록 변경합니다. 이제 이 노드는 새로운 더미
노드가 되었습니다.
• 기존 더미 노드는 삭제합니다. 그리고 보관해 놓은 값을 반환하면 됩니다.
26
Head Tail
Dummy Next
New
Dummy Next
New Data
Copy
27.
Pop( )
• Pop메서드의 전체 코드입니다.
1. Head 가 가리키고 있는 노드
(first) Tail이 가리키고 있는 노드
(last) Head의 다음 노드(next)를
지역 변수에 저장해 놓습니다.
27
1
28.
Pop( )
2. 다른스레드에 의해서 Head가
변경 되었는지 검사하고 변경됐다
면 재시도 합니다.
3. Head와 Tail이 동일한 노드를
가리키고 있는지 확인합니다.
만약 동일한 노드를 가리키고 있다
면 Queue는 비어 있는 상태입니
다. 우선 Queue가 비었을 때 처리
를 살펴보겠습니다.
28
2
3
29.
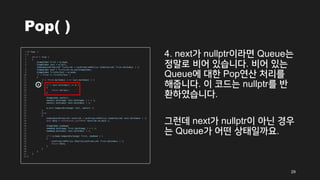
Pop( )
4. next가nullptr이라면 Queue는
정말로 비어 있습니다. 비어 있는
Queue에 대한 Pop연산 처리를
해줍니다. 이 코드는 nullptr를 반
환하였습니다.
그런데 next가 nullptr이 아닌 경우
는 Queue가 어떤 상태일까요.
29
4
30.
Pop( )
• Push메서드에서 보았던 상태입니다. 새로운 노드가 삽입 됐지만 Tail이
새로운 노드를 가리키기 전에 다른 스레드에 CPU 자원을 뺏겼습니다.
• 이 때 해야 할 작업은 정해져 있습니다. 스스로 Tail을 뒤로 이동시킵니다.
30
Head Tail
Dummy Next
New
Data
Next
31.
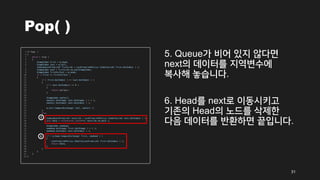
Pop( )
5. Queue가비어 있지 않다면
next의 데이터를 지역변수에
복사해 놓습니다.
6. Head를 next로 이동시키고
기존의 Head의 노드를 삭제한
다음 데이터를 반환하면 끝입니다.
31
5
6
32.
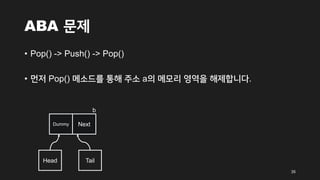
ABA 문제
• Push메서드를 살펴보면서 Lock-free 알고리즘에서 발생할 수 있는 어떤
문제에 대해 언급하였는데 여기서 한번 살펴보도록 하겠습니다.
• 다음과 같은 Queue를 생각해 보겠습니다. 각 노드의 주소를 a, b라 하겠습
니다.
32
Head
Dummy Next
New
Data
Next
Tail
a b
33.
ABA 문제
• 스레드1에서 Pop메소드를 실행하려고 하는데 Head를 전진시키기 전에
다른 스레드로 CPU 선점권을 뺏겼다고 가정하겠습니다
• 이 경우 스레드1의 로컬 변수에 Head의 주소 a와 Next의 주소 b를 저장해
놓은 상태입니다.
33
Head
Dummy Next
New
Data
Next
Tail
a b
34.
ABA 문제
• 이제다른 스레드들이 Push와 Pop을 실행합니다.
• 여러 차례의 메모리 반납과 할당이 이뤄지는데 문제는 이 메모리가 재활용
된다는 것입니다. 다음과 같은 순서로 메소드가 실행되는 경우를 봅시다.
34
Head
Dummy Next
New
Data
Next
Tail
a b
35.
ABA 문제
• Pop()-> Push() -> Pop()
• 먼저 Pop() 메소드를 통해 주소 a의 메모리 영역을 해제합니다.
35
Head
Dummy Next
Tail
b
36.
ABA 문제
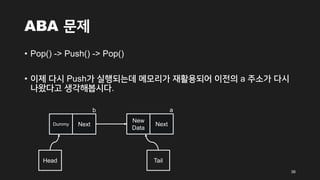
• Pop()-> Push() -> Pop()
• 이제 다시 Push가 실행되는데 메모리가 재활용되어 이전의 a 주소가 다시
나왔다고 생각해봅시다.
36
Head
Dummy Next
Tail
b
New
Data
Next
a
37.
ABA 문제
• Pop()-> Push() -> Pop()
• 그리고 또 다시 Pop이 실행되면 최종적인 Queue는 아래와 같이 됩니다.
37
Tail
Dummy Next
a
Head
38.
ABA 문제
• 이제길고 긴 시간이 지나 스레드1이 다시 실행 되었다고 생각해봅시다.
• 스레드1이 생각하고 있는 Queue의 모양은 다음과 같습니다. a 주소 노드의
다음으로 b 주소의 노드가 연결되어 있죠. 하지만 실제 Queue의 상태는…
38
Head
Dummy Next
New
Data
Next
Tail
a b
39.
ABA 문제
• a주소의 노드 뒤에 아무것도 없습니다.
• 문제는 이 때 스레드1의 CAS(Head, a, b)가 성공합니다. 그리고 Head는
스레드1의 로컬 Next 변수에 저장한 b를 가리키게 됩니다. 게다가 b는 해제
된 메모리 영역입니다.
39
Tail
Dummy Next
a
Head
40.
ABA 문제
• 메모리의재활용으로 인해서 CAS연산의 안전장치( 현재 값과 예상 값이
같을 때만 값을 변경 )가 무효화 됐습니다.
• 이런 문제를 ABA 문제라고 합니다.
• ABA 문제는 모든 CAS와 new, delete를 사용할 경우 모든 Lock-free
알고리즘에서 발생할 수 있습니다.
• 그럼 이걸 어떻게 회피해야 할까? 여기서는 2가지 방법을 소개하겠습니다.
40
41.
ABA 문제
• 첫번째방법은 메모리가 곧바로 재활용이 되지 않도록 하는 것 입니다.
• 이전 예제에서 스레드1은 Head를 로컬 변수에 저장하고 있었습니다. 만약
이 Head 주소의 메모리가 레퍼런스 카운트에 의해서 관리되고 있다면 다른
스레드에서 Pop을 하더라도 실제로 메모리가 반납되지 않아서 재활용되지
않습니다.
• 그래서 GC가 사용되는 환경(C#, Python, etc… )에서는 ABA 문제는
발생하지 않습니다.
41
42.
ABA 문제
• 두번째방법은 주소를 확장하는 것입니다.
Tag 혹은 Stamp라 불리는 추가적인 비트를 더해서 매 CAS시도 시 이 값을
다르게 설정합니다.
• 메모리가 재활용 된다고 해도 추가된 비트가 매번 다르기 때문에 ABA문제
를 회피 할 수 있습니다.
42
43.
ABA 문제
• StampIndex클래스는 ABA 문제를 해결하기 위해 4byte의 Stamp와
4byte의 메모리 풀에 대한 Index를 하나로 묶어 사용하고 있습니다.
43
44.
성능 측정
• 구현도했으니 Lock 버전의 Queue와 성능을 비교해 보겠습니다.
Lock 버전 Queue는 다음과 같이 구현하였습니다.
44
45.
성능 측정
• 테스트코드는 다음과 같습니다.
• 10000번 이하까지는 Push만 하다가 이후에는 임의로 Push 혹은 Pop을
호출합니다.
• LoopCount = 64000000, ThreadCount = 8
45
46.
성능 측정
• 성능측정에 사용한 PC 사양입니다.
CPU : Intel(R) Core(TM) i5-4200U CPU @ 1.60GHz 2.30 GHz
( 2코어 4스레드 )
RAM : 8 GB
Visual Studio 2017 64 bit 빌드
46
성능 측정
• Lock-FreeQueue가 Lock 버전의 Queue 보다 빠른 것을 확인할 수 있습
니다. 그런데 잠시 이것을 보시도록 하겠습니다.
• 동일한 코드의 32 bit 빌드 버전입니다.
CPU : Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz 3.60 GHz
( 4코어 8스레드 )
RAM : 16 GB
Visual Studio 2017 32 bit 빌드
50
성능 측정
• 그런데32bit 프로그램에서 8byte 자료형을 읽고 쓸 때는 다음과 같이 2번에
걸쳐서 메모리에 접근합니다.
• 만약 14번 째 줄 실행 후 다른 스레드가 해당 변수에 값을 쓰게 된다면 8byte의
절반은 업데이트된 값이 저장됩니다.
55
56.
성능 측정
• 그러므로std::atomic_load 를 제거할 수 는 없습니다. 따라서 32bit 에서
성능을 끌어 올리기 위해서는 다른 방법을 생각해봐야 할 것 같습니다.
• StampIndex를 16bit Stamp, 16bit 메모리 풀 인덱스로 구성하는 방법도
있겠습니다. 이렇게 구성하면 ABA 문제가 발생하려면 점유권을 빼앗긴
동안 65,536번 Push와 Pop이 발생해야 합니다.
• 아니면 Stamp를 사용하지 않고 레퍼런스 카운터를 통해 참조하고 있다면
메모리를 재활용하지 못하게 만드는 방법도 있겠습니다.
56
57.
마치며…
• 일단 제가준비한 내용은 여기까지 입니다.
• 그래프를 자세히 보셨던 분이라면 64bit에서 lock 버전 Queue의 성능이
떨어진 것에 눈치 채셨을 텐데 주제에서 벗어난 내용이라 다루지는 않았지
만 std::mutex의 구현 차이로 인해 성능의 차이가 있더군요. 정말 성능이
중요한 상황에서는 고려할 만한 상황인 것 같습니다.
57
58.
더 자세한 코드를보고 싶으시다면...
• https://github.com/xtozero/LockFreeDataStructure/tree/master/LockFre
eDataStructure/Source
58


































































![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)




![[IGC 2017] 펄어비스 민경인 - Mmorpg를 위한 voxel 기반 네비게이션 라이브러리 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NDC 2014] 던전앤파이터 클라이언트 로딩 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/ndc201420140605-140604221309-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[C++ Korea] C++ 메모리 모델과 atomic 타입 연산들](https://cdn.slidesharecdn.com/ss_thumbnails/cppmemorymodelandoperationsonatomictypes-180427162555-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2B7]시즌2 멀티쓰레드프로그래밍이 왜 이리 힘드나요](https://cdn.slidesharecdn.com/ss_thumbnails/2b72-140930004949-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























