2-2
발표자 소개
• KAIST전산과 박사
– 전공 : 멀티프로세서 CPU용 일관성 유지 HW
• NCSoft 근무
– Alterlife 프로그램 팀장
– Project M 프로그램 팀장
– CTO 직속 게임기술연구팀
• 현 : 한국산업기술대학교 게임공학과 부교수
– 학부 강의 : 게임서버프로그래밍
– 대학원 강의 : 멀티코어프로그래밍, 심화 게임서버
프로그래밍
3.
2-3
참고
• NDC2012, KGC2012,CJE&M에서 강연한
내용
– 업데이트
• 삼성첨단기술연수소에서 강의한 내용
– 40시간 강의 (실습 포함) 의 앞부분
• 대학원 “멀티코어 프로그래밍” 처음 4주
강의 분량의 압축
2-5
도입
• 멀티쓰레드 프로그래밍이란?
– 멀티코어 혹은 멀티프로세서 컴퓨터의 성능을
이끌어 내기 위한 프로그래밍 기법
– 흑마술의 일종
• 잘못 사용하면 패가 망신
6.
2-6
도입
• 흑마술 멀티쓰레드프로그래밍의 위험성
– “자꾸 죽는데 이유를 모르겠어요”
• 자매품 : “이상한 값이 나오는데 이유를 모르겠어요”
– “더 느려져요”
[미] MuliThreadProgramming [mʌ́ ltiθred-|proʊgrӕmɪŋ] : 1. 흑마술, 마공
2. 위력이 강대하나 다루기 어려워 잘 쓰이지 않는 기술
2-10
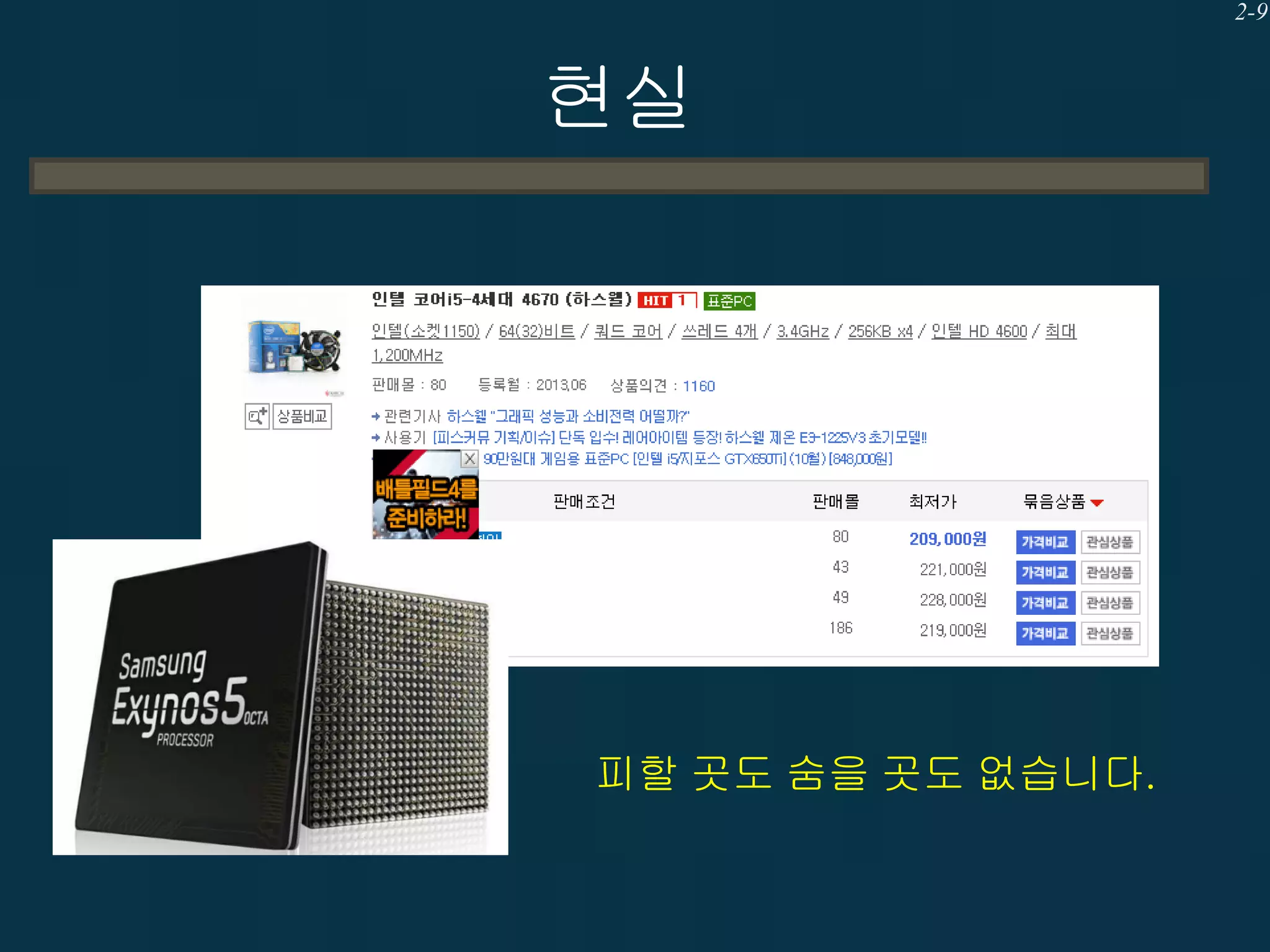
현실
• 멀티쓰레드 프로그래밍을하지 않으면?
– (멀티코어) CPU가 놀아요.
– 경쟁회사 제품보다 느려요.
• FPS(Frames Per Second)
• 동접
– 점점 줄어드는 사용자당 수입
– 만일 중국에 출동하면??
11.
2-11
현실
• 멀티 코어CPU가 왜 나왔는가?
– 예전에는 만들기 힘들어서? No
– 다른 방법들의 약발이 다 떨어져서!
• 클럭 속도, 캐시, 슈퍼스칼라, Out-of-order, 동적 분기
예측…
– 늦게 나온 이유
• 프로그래머에게 욕을 먹을 것이 뻔하기 때문.
– 기존 프로그램의 성능향상이 전혀 없고, 멀티 쓰레드
프로그래밍이 너무 어려워서.
12.
2-12
현실
• 컴퓨터 공학을전공했지만 학부에서
가르치지 않았다.
• 큰맘 먹고 스터디를 시작했지만 한 달도 못
가서 흐지부지 되었다. (원인은 다음 페이지)
• 그냥 멀티쓰레드 안 쓰기로 했다.
2-14
현실
• 왜 멀티쓰레드프로그래밍이 어려운가?
– 다른 쓰레드의 영향을 고려해서 프로그램 해야 하기
때문에
– 에러 재현과 디버깅이 힘들어서
– Visual Studio가 사기를 치고 있기 때문
• 왜 멀티쓰레드 프로그래밍이 진짜로 어려운가?
– CPU가 사기를 치고 있기 때문
2-21
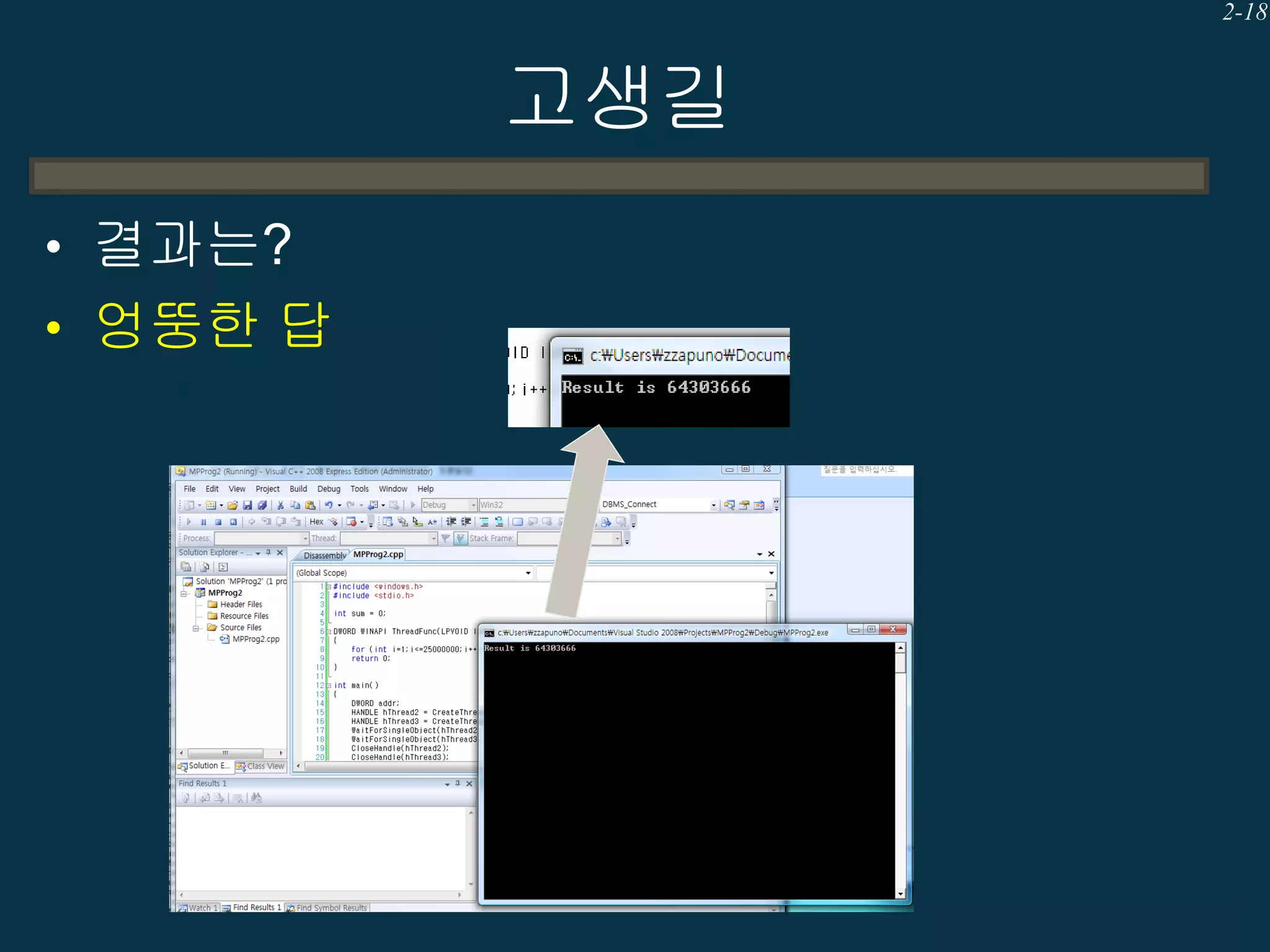
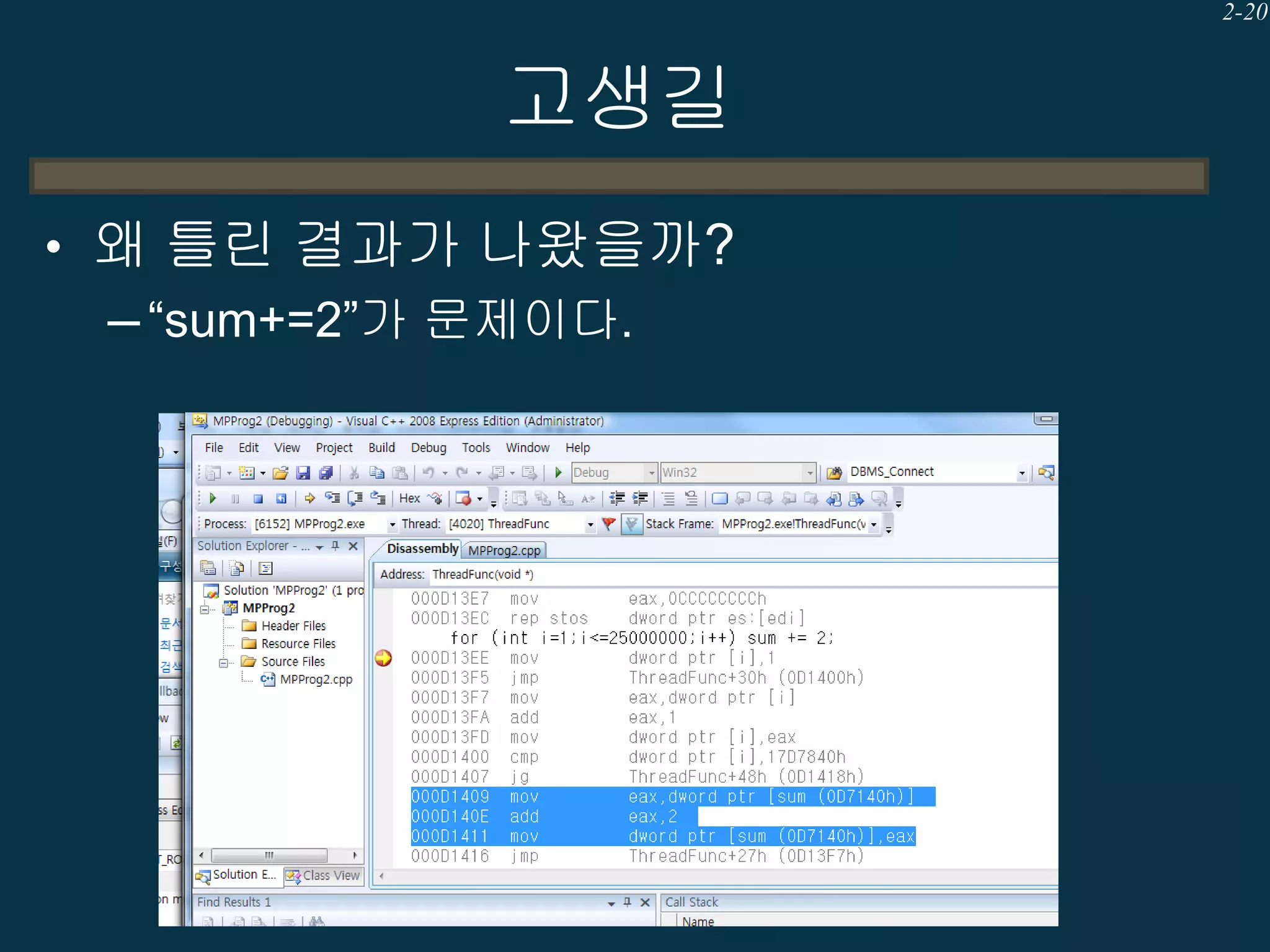
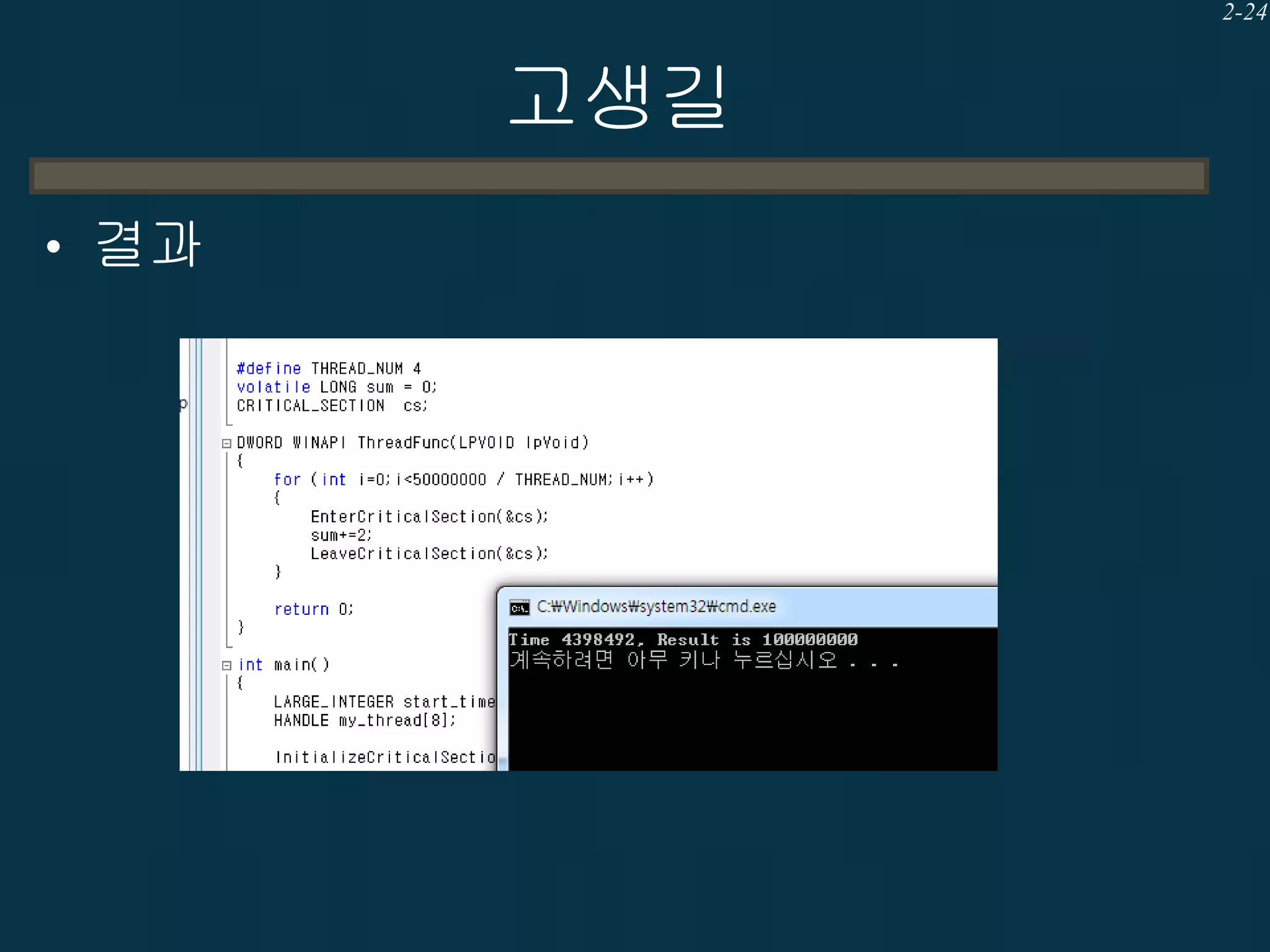
고생길
• 왜 틀린결과가 나왔을까?
– DATA RACE (복수의 쓰레드에서 같은 공유
메모리에 WRITE하는 행위) 때문.
– “sum+=2”가 문제이다.
쓰레드 1
쓰레드 2
MOV EAX, SUM
sum = 200
ADD EAX, 2
MOV EAX, SUM
sum = 200
MOV SUM, EAX
ADD EAX, 2
sum = 202
MOV SUM, EAX
sum = 202
2-35
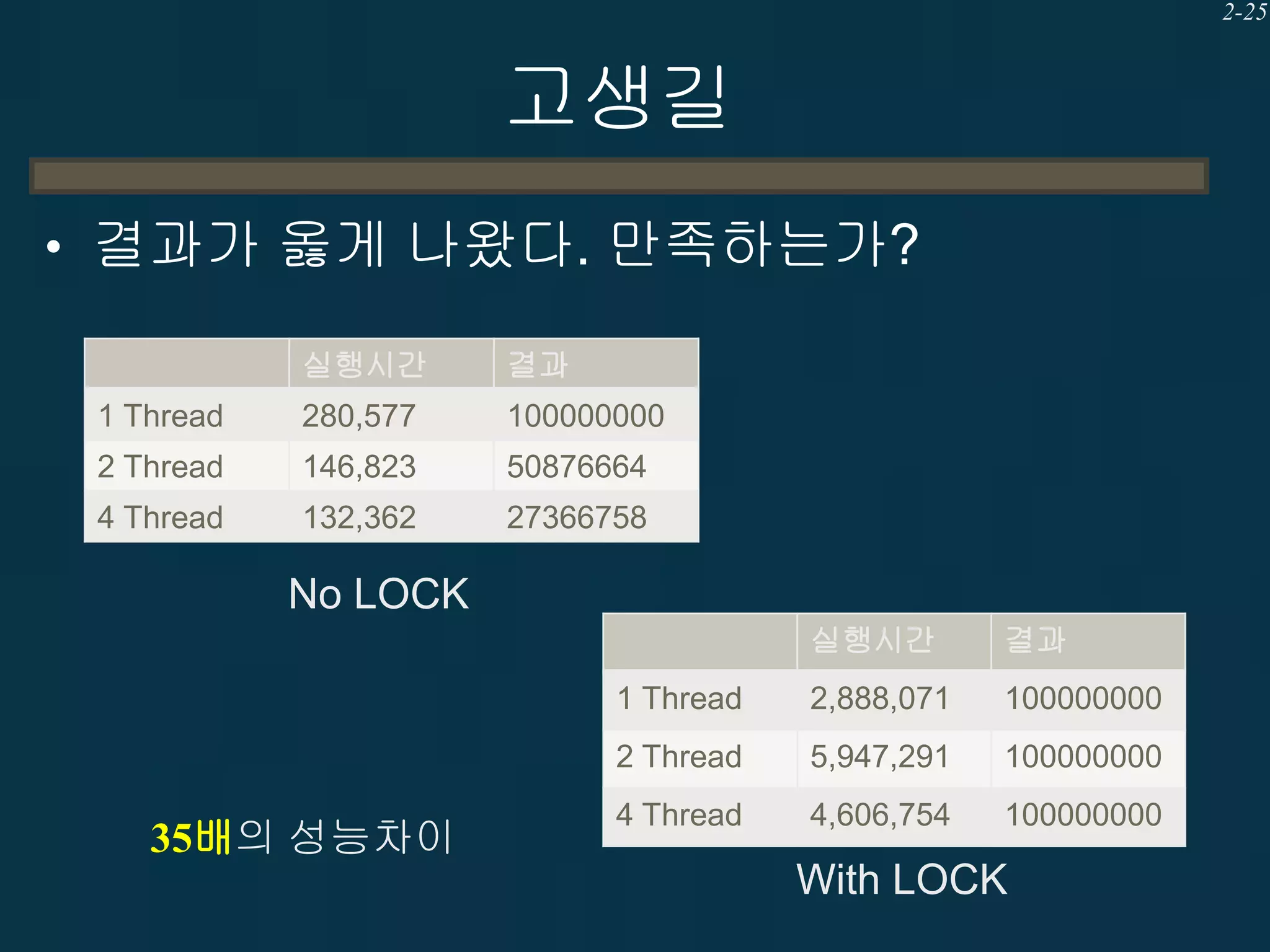
고생길
• Visual Studio의사기를 피하는 방법
– volatile을 사용하면 된다.
• 최적화를 하지 않는다.
• 반드시 메모리를 읽고 쓴다.
• 읽고 쓰는 순서를 지킨다.
– 참 쉽죠?
– “어셈블리를 모르면 Visual Studio의 사기를 알
수 없다” 흠좀무…
고생길
• volatile의 사용법
–volatile int * a;
• *a = 1; // 순서를 지킴
• a = b; // 순서를 지키지 않는다.
– int * volatile a;
• *a = 1; // 순서를 지키지 않음,
• a = b; // 이것은 순서를 지킴
2-39
고생길
• 지금까지
– VisualStudio의 마수에서 벗어나기
• Volatile을 잘 쓰자
– 경쟁상태 해결하기.
• Lock을 최소화 하자
• Lock대신 atomic operation을 사용하자
40.
2-40
고생길
• 그러나
– 절대로모든 문제가 정답처럼 풀리지 않는다.
– Interlocked로 구현 가능하면 다행 (atomic)
• Interlock이 가능한 것은 일부 Instruction
– 일반적인 자료구조를 Lock없이 Atomic하게
구현하는 것은 큰 문제다.
– Lock말고도 다른 문제가 있다.
2-45
HELL
• 이유는?
– CPU는사기를 친다.
• Line Based Cache Sharing
• Out of order execution
• write buffering
– CPU는 프로그램을 순차적으로 실행하는
척만한다.
• 자기 자신이 실행하는 프로그램에게는 제대로
실행하는 것처럼 거짓말한다.
• 옆의 Core에서 보면 거짓말이 보인다.
2-47
HELL
• 문제는 메모리
–프로그램 순서대로 읽고 쓰지 않는다.
• 읽기와 쓰기는 시간이 많이 걸리므로.
• 옆의 프로세서(core)에서 보면 속도차와 실행순서
뒤바뀜이 보인다.
• 어떠한 일이 벌어지는가?
48.
2-48
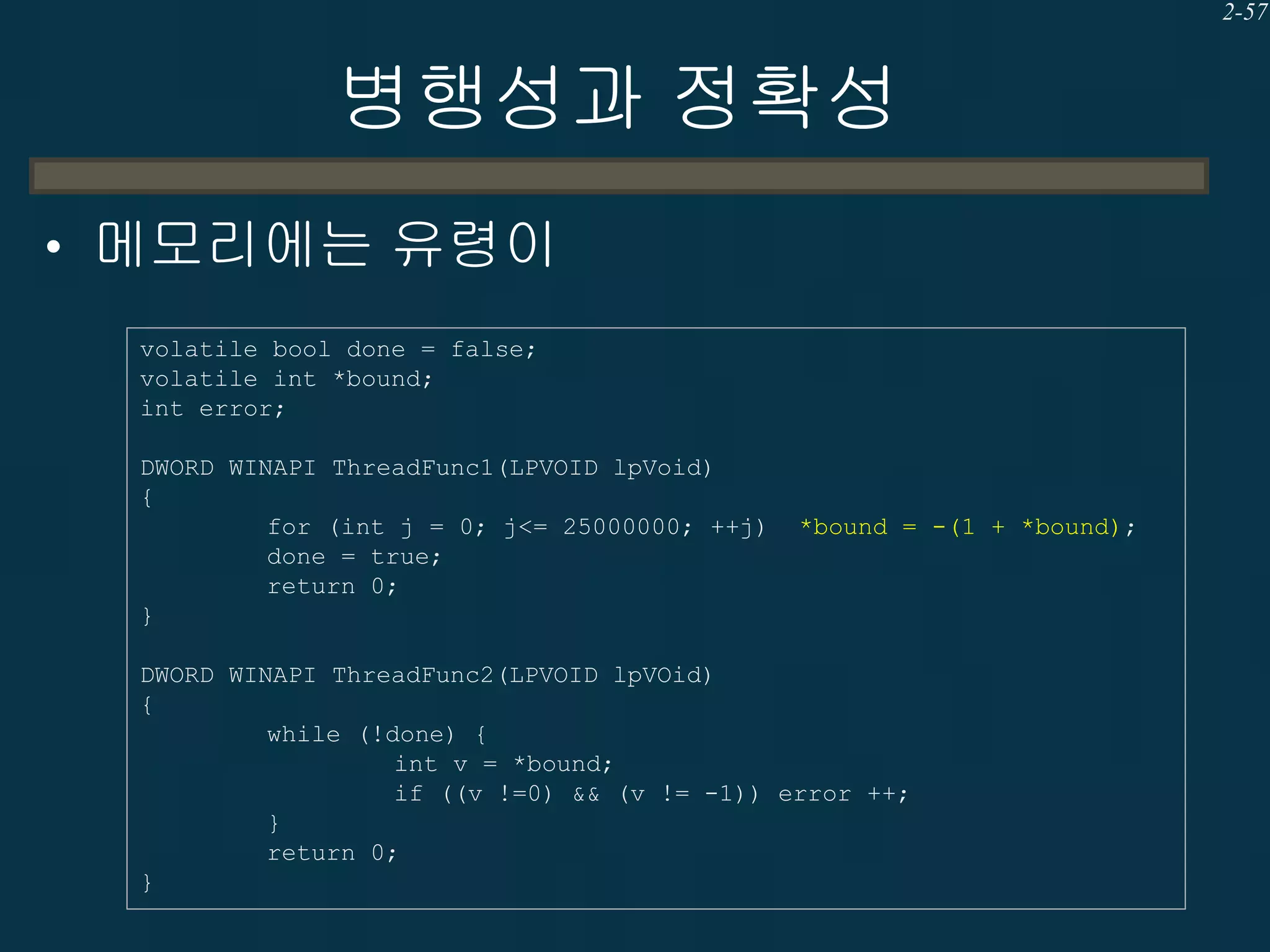
병행성과 정확성
• 아래의두 개의 실행결과는 서로 다르다
어떠한 것이 정확한 결과인가?
thread a
thread b
write (x, 1)
write(x, 2)
read(x, 2)
Type-A
read(x, 2)
Type-B !!
thread a
thread b
write (x, 1)
read(y, 1)
write (y, 1)
read(x, 0)
49.
2-49
병행성과 정확성
• 그러면이것은?
thread a
thread b
write (x, 1)
write(x, 2)
read(x, 2)
Type-C!!
read(x, 1)
thread a
thread b
write (x, 1)
write(y, 1)
read (y, 0)
Read(x, 0)
Type-D!!
50.
2-50
HELL
• 현실
– 앞의여러 형태의 결과는 전부 가능하다.
• 부정확해 보이는 결과가 나오는 이유?
– 현재의 CPU는 Out-of-order실행을 한다.
– 메모리의 접근은 순간적이 아니다.
– 멀티 코어에서는 옆의 코어의 Out-of-order
실행이 관측된다.
51.
2-51
HELL
• 진짜?
• 확인해보자.
• 메모리 접근 순서를 강제로 맞추어 주는
명령어
_asm mfence;
• 앞에 피터슨 알고리즘에 적용해보자.
– 근데… 오류의 확률이 낮아서…
52.
2-52
HELL
• 메모리 접근오류 검출 프로그램을
사용해보자
• 아이디어.
– 메모리 내용을 계속 업데이트 하면서 다른
쓰레드의 업데이트를 같이 기록하여 나중에
기록된 로그를 비교해 보자.
53.
2-53
HELL
• 정말 간단한프로그램
#define THREAD_MAX 2
#define SIZE 10000000
volatile int x,y;
int trace_x[SIZE], trace_y[SIZE];
DWORD WINAPI ThreadFunc0(LPVOID a)
{
for(int i = 0; i <SIZE;i++) {
x = i;
trace_y[i] = y;
}
return 0;
}
int main()
{
DWORD addr;
HANDLE hThread[THREAD_MAX];
DWORD WINAPI ThreadFunc1(LPVOID a)
{
for(int i = 0; i <SIZE;i++) {
y = i;
trace_x[i] = x;
}
return 0;
}
.. // Thread 2개 실행
int count = 0;
for (int i=0; i< SIZE;++i)
if (trace_x[i] == trace_x[i+1])
if (trace_y[trace_x[i]] == trace_y[trace_x[i] + 1]) {
if (trace_y[trace_x[i]] != i) continue;
count++;
}
printf("Total Memory Inconsistency:%dn", count);
return 0;
}
54.
2-54
HELL
• 프로그램 설명
8보다3이 먼저 write!!
2
3
4
5
6
7
7
x
traceY
7
8
8
8
9
6
7
8
9
10
11
y
1
2
2
3
5
6
traceX
3보다 8이 먼저 write!!!
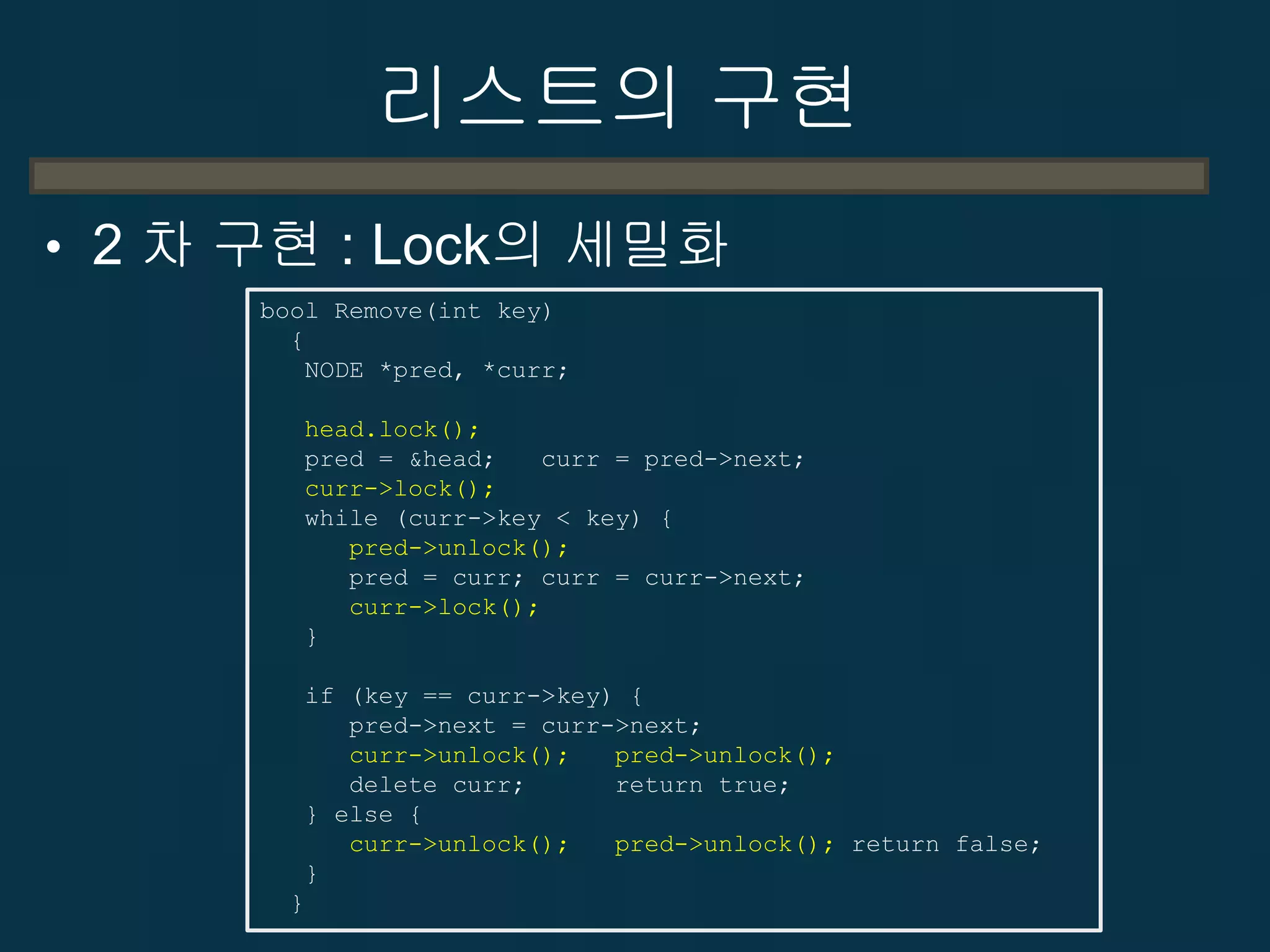
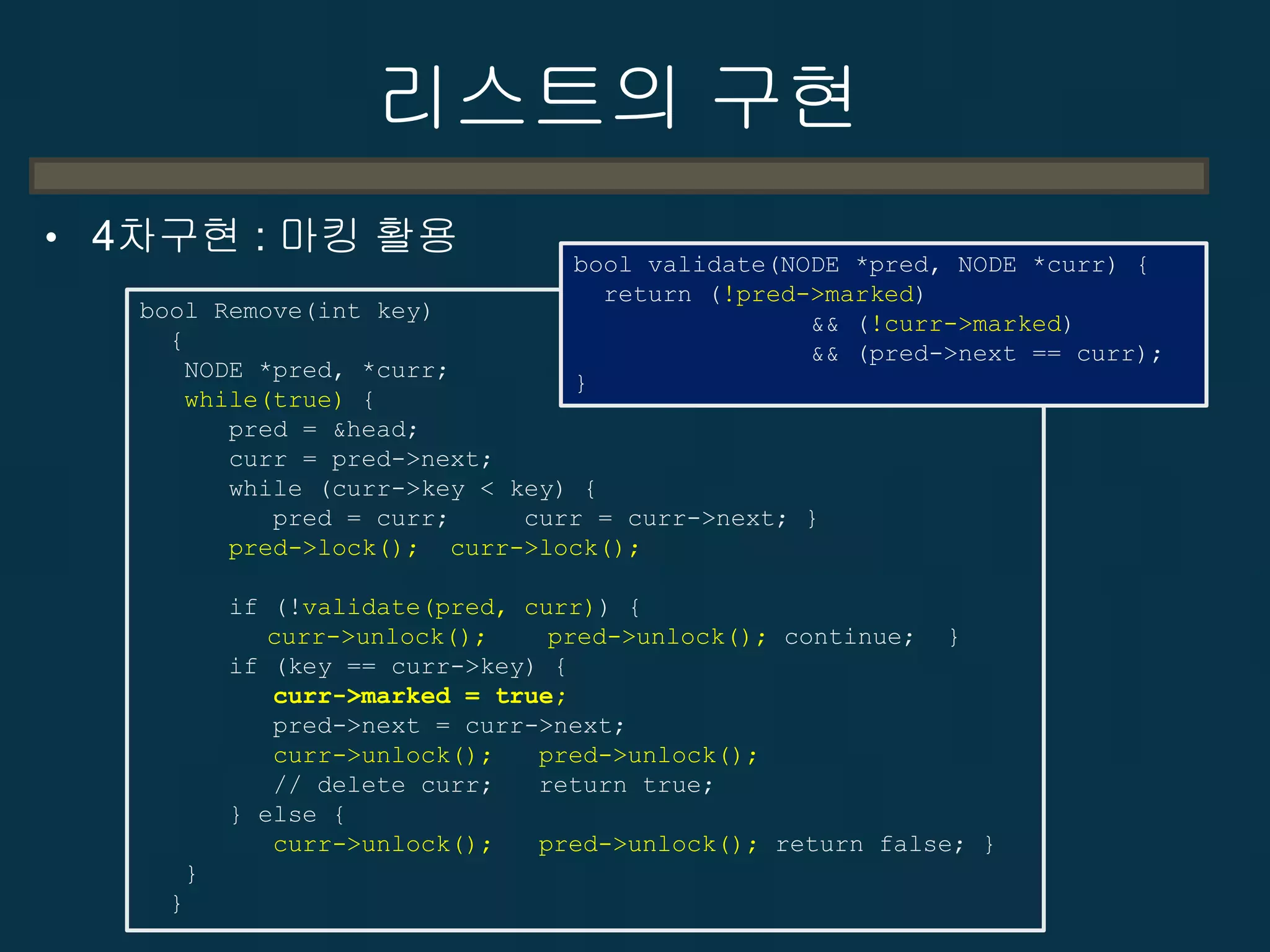
2-60
HELL
• 결과가….
– 중간값
•write시 최종값과 초기값이 아닌 다른 값이 도중에 메모리에
써지는 현상
– 이유는?
• Cache Line Size Boundary
– 대책은?
• Pointer를 절대 믿지 마라.
• Byte 밖에 믿을 수 없다.
• Pointer가 아닌 변수는
– Visual C++ 또는 G++가 잘 해준다.
unsigned char buf[256]
buf[0] = length;
buf[1] = OP_MOVE;
*((float *)(&buf[2])) = x;
*((float *)(&buf[6])) = y;
*((float *)(&buf[10])) = z;
*((float *)(&buf[14])) = dx;
*((float *)(&buf[18])) = dy;
*((float *)(&buf[22])) = dz;
*((float *)(&buf[26])) = ax;
*((float *)(&buf[30])) = ay;
*((float *)(&buf[34])) = az;
*((int *)(&buf[38])) = h;
…
send( fd, buf, (size_t)buf[0], 0 );
어디서 많이 본 소스코드..
61.
2-61
HELL
• 이러한 현상을메모리 일관성(Memory
Consistency) 문제라고 부른다.
– x86은 얌전한 편, ARM CPU는 더하다.
http://en.wikipedia.org/wiki/Memory_ordering
62.
2-62
HELL
• 정리
– 멀티쓰레드에서의공유 메모리
• 다른 코어에서 보았을 때 업데이트 순서가 틀릴 수 있다.
• 메모리의 내용이 한 순간에 업데이트 되지 않을 때 도 있다.
– 일반적인 프로그래밍 방식으로는 멀티쓰레드에서
안정적으로 돌아가는 프로그램을 만들 수 없다.
63.
2-63
HELL
• 어떻게 할것인가?
– 위의 상황을 감안하고 프로그램 작성
• 프로그래밍이 너무 어렵다.
– 피터슨이나 빵집 알고리즘도 동작하지 않는다.
– 모든 공유메모리 접근을 Atomic하도록 수정한다.
• 모든 메모리 접근을 Lock/Unlock으로 막으면 가능
– 성능저하!!!, Lock은 어떻게 구현?
• Interlocked Operation 사용
– 간단한 연산만 가능, 성능저하
• mfence의 적절한 추가
– 적절하다는 보장은???
어쩌라고???
2-65
희망
• 언젠가는 메모리에대한 쓰기가 실행 된다.
• 자기 자신의 프로그램 실행순서는 지켜진다.
• 캐시의 일관성은 지켜진다.
– 한번 지워졌던 값이 다시 살아나지는 않는다.
– 언젠가는 모든 코어가 동일한 값을 본다
• 캐시라인 내부의 쓰기는 중간 값을 만들지
않는다.
66.
2-66
희망
• 우리가 할수 있는 것
– CPU의 여러 삽질에도 불구 하고 주의 깊게
프로그래밍 하면 모든 메모리 접근을
Atomic하게 할 수 있다.
• HW의 도움 없이도 가능.
• 하지만 mfence가 효율적
67.
2-67
희망
• Atomic Memory만 있으면 되는가?
– NO
• 진짜 큰 규모의 상용 멀티쓰레드
프로그래밍은?
– 쓰레드간의 동기화나 자료 전송은 고유의
자료구조 사용
• Queue, Stack, List, Map, Tree……
• 예) Tera의 시야처리용 Lock-free job queue
• 예) Unreal3의 rendering command queue
68.
2-68
희망
• 하지만.
– 지금까지배운 모든 자료구조가
멀티쓰레드에서는 동작하지 않는다.
– STL도 동작하지 않는다.
– 다시 작성해야 한다.
• LOCK을 쓰면?
“Lock 없애야 해요 Lock 없앨 때 마다
동접이 300명씩 늘어났어요.” - N모사에서
L모 게임을 만들었던 S모님
69.
2-69
Lock없는 프로그램
• 효율적인구현
– Lock없는 구현
• 성능 저하의 주범이므로 당연
– Overhead & Critical Section
– Priority inversion
– Convoying
– Lock이 없다고 성능저하가 없는가??
• 상대방 쓰레드에서 어떤 일을 해주기를 기다리는 한
동시실행으로 인한 성능 개선을 얻기 힘들다.
– while (other_thread.flag == true);
– lock과 동일한 성능저하
• 상대방 쓰레드의 행동에 의존적이지 않는 구현방식이 필요하다.
70.
2-70
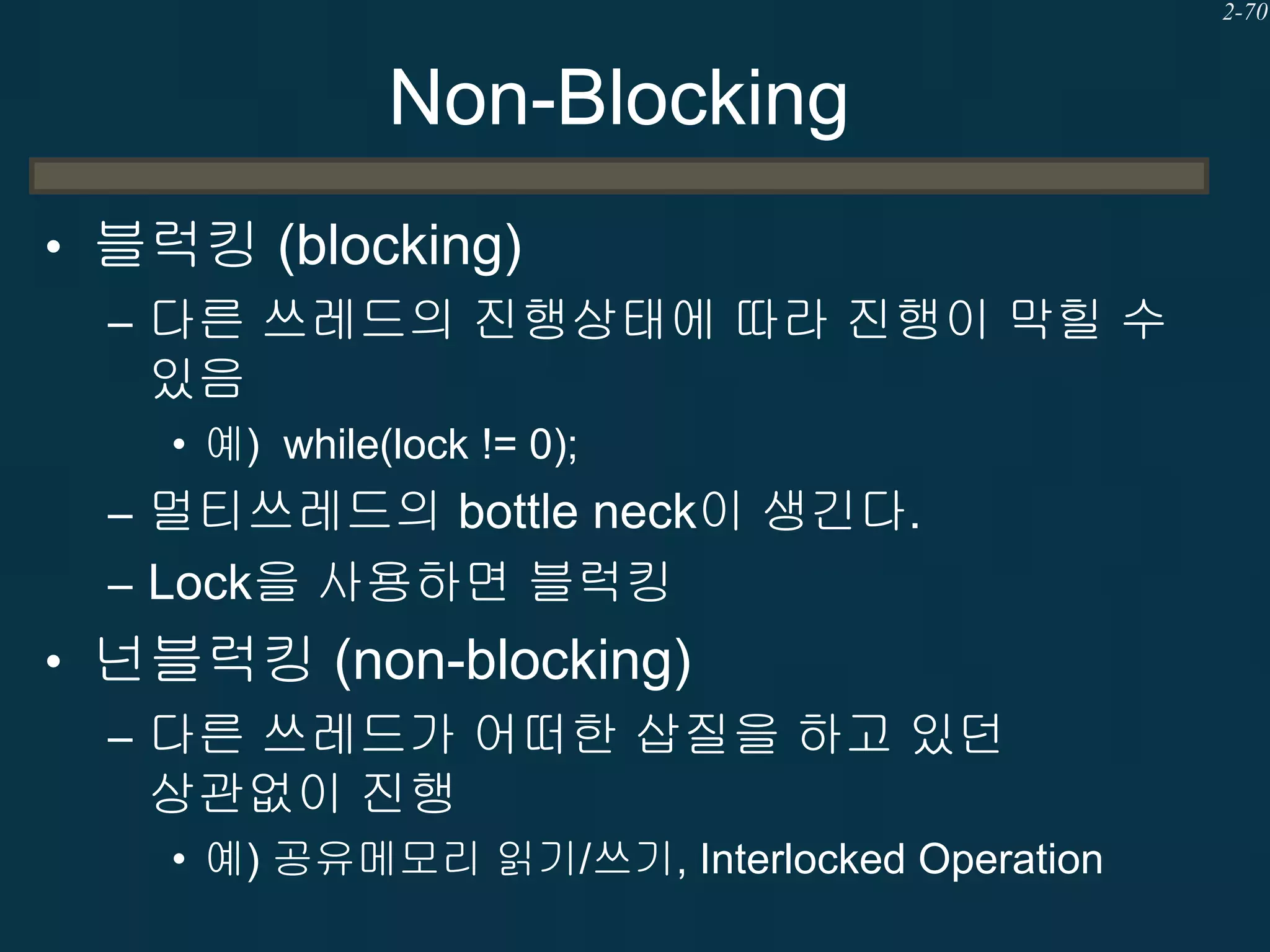
Non-Blocking
• 블럭킹 (blocking)
–다른 쓰레드의 진행상태에 따라 진행이 막힐 수
있음
• 예) while(lock != 0);
– 멀티쓰레드의 bottle neck이 생긴다.
– Lock을 사용하면 블럭킹
• 넌블럭킹 (non-blocking)
– 다른 쓰레드가 어떠한 삽질을 하고 있던
상관없이 진행
• 예) 공유메모리 읽기/쓰기, Interlocked Operation
71.
2-71
Non-Blocking
• 블럭킹 알고리즘의문제
– 성능저하
– Priority Inversion
• Lock을 공유하는 덜 중요한 작업들이 중요한 작업의 실행을
막는 현상
• Reader/Write Problem에서 많이 발생
– Convoying
• Lock을 얻은 쓰레드가 스케쥴링에서 제외된 경우, lock을
기다리는 모든 쓰레드가 공회전
• Core보다 많은 수의 thread를 생성했을 경우 자주 발생.
• 성능이 낮아도 Non-Blocking이 필요할 수 있다.
72.
2-72
Non-Blocking
• 넌블럭킹의 등급
–무대기 (wait-free)
• 모든 메소드가 정해진 유한한 단계에 실행을 끝마침
• 멈춤 없는 프로그램 실행
– 무잠금 (lock-free)
•
•
•
•
항상, 적어도 한 개의 메소드가 유한한 단계에 실행을 끝마침
무대기이면 무잠금이다
기아(starvation)을 유발하기도 한다.
성능을 위해 무대기 대신 무잠금을 선택하기도 한다.
73.
2-73
Non-Blocking
• 정리
– Wait-free,Lock-free
• Lock을 사용하지 않고
• 다른 쓰레드가 어떠한 행동을 하기를 기다리는 것
없이
• 자료구조의 접근을 Atomic하게 해주는 알고리즘의
등급
– 멀티 쓰레드 프로그램에서 쓰레드 사이의
효율적인 자료 교환과 협업을 위해서는 NonBlocking 자료 구조가 필요하다.
74.
2-74
병행성과 정확성
• 그러면,Atomic Memory로 그런 자료구조를
만들면 되지 않는가?
• Atomic Memory만으로는 다중 쓰레드
무대기 큐를 만들 수 없다!!!!!!
– (증명) : 아까 그 책
75.
2-75
병행성과 정확성
• 다중쓰레드 무대기 큐를 만들려면?
– CAS 명령어가 필요하다.
• 반드시 HW에서 지원해야 한다.
− CAS가 없이는 대부분의 non-blocking
알고리즘들을 구현할 수 없다.
• Queue, Stack, List…
− CAS를 사용하면 모든 싱글쓰레드 알고리즘
들을 Lock-free 알고리즘으로 변환할 수 있다!!!
− Lock-free 알고리즘의 핵심
76.
2-76
CAS
• CAS
− CAS(&A,old, new);
− 의미 : 아래의 연산을 Atomic하게 수행
if (A == old) { A = new; return true; }
else return false;
− 다른 버전의 의미 : A메모리를 다른 쓰레드가 먼저
업데이트 해서 false가 나왔다. 모든 것을 포기하라.
77.
2-77
CAS
• 구현 :Windows
– API
#include <windows.h>
LONG __cdecl InterlockedCompareExchange(
__inout LONG volatile *Destination,
__in LONG Exchange,
__in LONG Comparand );
– CAS의 구현
Bool CAS(LONG volatile *Addr, LONG New, LONG Old)
{
LONG temp = InterlockedCompareExchange(Addr, New, Old);
return temp == Old;
}
78.
2-78
CAS
• 구현 :LINUX
#include <stdbool.h>
bool CAS(int *ptr, int oldval, int newval)
{
return __sync_bool_compare_and_swap(ptr, oldval, newval);
}
79.
2-79
CAS
• 구현 :C++11
#include <atomic>
bool atomic_compare_exchange_strong( std::atomic<T>* obj,
T* expected, T desired );
80.
2-80
CAS
• 실제 HW(x86 계열 CPU) 구현
– LOCK prefix와 CMPXCHG 명령어로 구현
– lock cmpxchg [A], b 기계어 명령으로
구현
• eax에 비교값, A에 주소, b에 넣을 값
if (eax == [a]) {
ZF = true;
[a] = b;
} else {
ZF = false;
eax = [a];
}
이론 시간
• XEON,E5-4620, 2.2GHz, 4CPU (32 core)
• STL의 queue를 무잠금, 무대기로 구현한 것과,
CriticalSection으로 atomic하게 만든 것의 성능 비교.
– Test조건 : 16384번 Enqueue, Dequeue (결과는 mili second)
– EnterCriticaSection()을 사용한 것은 테스트 데이터의 크기가 100배
– 따라서 100배 성능 차이 (4개 thread의 경우)
쓰레드 갯수
1
2
4
8
16
32
64
무잠금 만능
3749
1966
1697
1120
742
525
413
무대기 만능
3640
1964
1219
1136
577
599
448
EnterCritical
232
822
1160
1765
1914
4803
7665
• 그렇다면, EnterCriticalSection을 사용해야 하는가?
– No : 멀티쓰레드에서의 성능향상이 없다.
86.
2-86
희망
• 결론
– CPU가제공하는 CAS 명령어를 사용하면
기존의 모든 싱글쓰레드 알고리즘을 Lockfree한 멀티쓰레드 알고리즘으로 변환할 수
있다.
• 현실
– Universal Algorithm은 비효율 적이다.
87.
2-87
희망
• 대안
– 자료구조에맞추어 최적화된 lockfree알고리즘을 일일이 개발해야 한다.
• 멀티쓰레드 프로그램은 힘들다. => 연봉이 높다.
• 다른 데서 구해 쓸 수도 있다.
– Intel TBB, VS2012 PPL
– 인터넷
– 하지만 범용적일 수록 성능이 떨어진다.
자신에게 딱 맞는 것을 만드는 것이 좋다.
2-89
Non-Blocking
• 우리의 목적
–정확한 결과
– 고성능
• 번역하면
– Lock을 사용하지 않고
– 비멈춤 (wait-free, lock-free)
– 자료구조 (Queue, Stack, List~~~)
90.
2-90
Non-Blocking
• 지향하는 프로그래밍스타일
– Lock을 사용한 프로그래밍
• Blocking
• 느림 (몇 십배)
– 원자적 레지스터를 사용한 프로그래밍
• 표현력이 떨어짐
• Lock-free Queue도 만들지 못함
– Non-blocking 자료구조를 사용한 프로그래밍
• OK
2-98
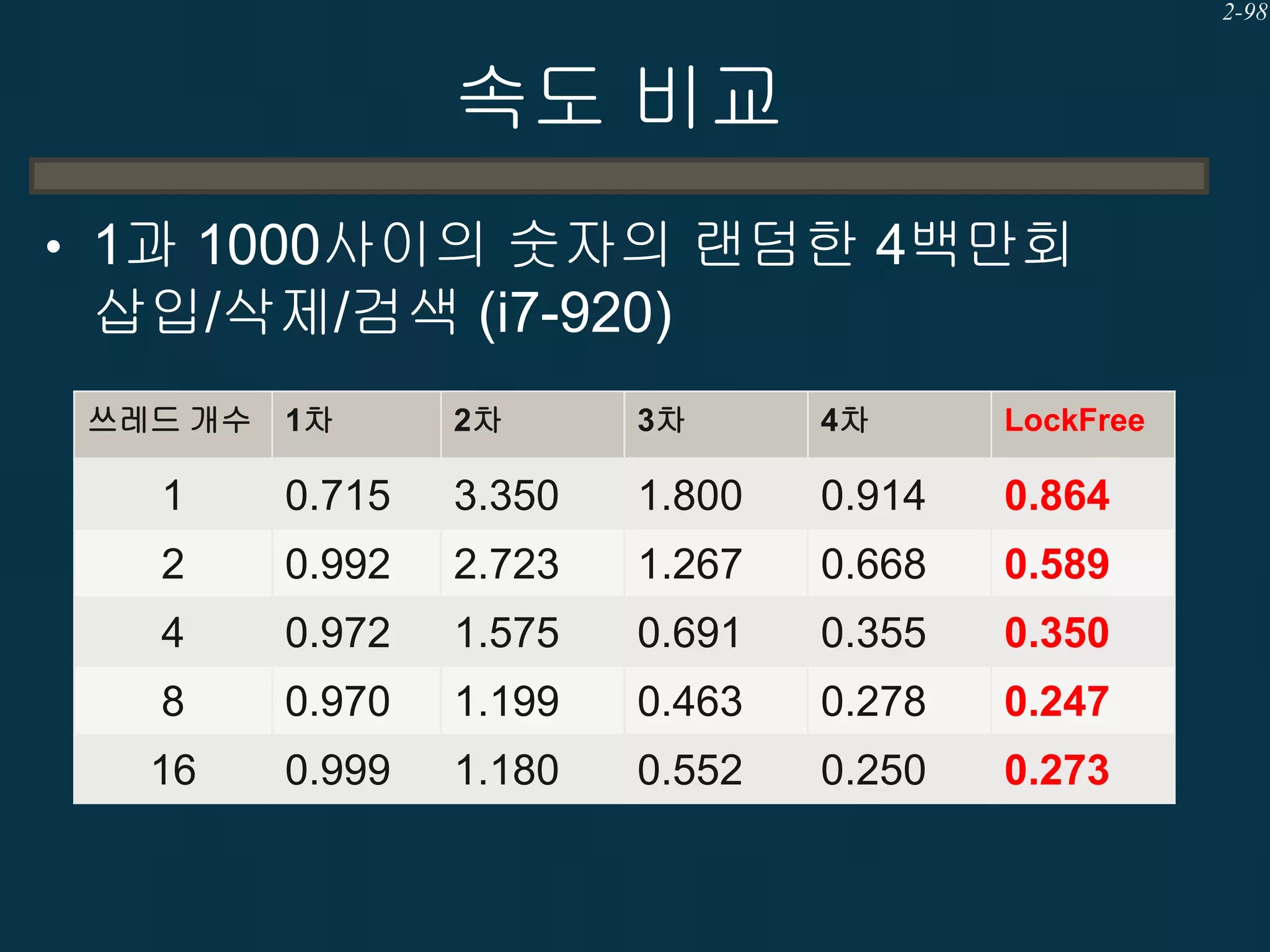
속도 비교
• 1과1000사이의 숫자의 랜덤한 4백만회
삽입/삭제/검색 (i7-920)
쓰레드 개수
1차
2차
3차
4차
LockFree
1
0.715
3.350
1.800
0.914
0.864
2
0.992
2.723
1.267
0.668
0.589
4
0.972
1.575
0.691
0.355
0.350
8
0.970
1.199
0.463
0.278
0.247
16
0.999
1.180
0.552
0.250
0.273
99.
2-99
정리
• 공유메모리를 사용한동기화는 사용하기 힘들다.
– 일관성, 중간 값
– Atomic memory의 한계
• 공유 자료 구조를 사용해야 한다.
– Non-blocking
• 좋은 공유 자료 구조는 만들기 힘들다.
– Non-blocking 알고리즘의 작성은 까다롭다.
– 상용 라이브러리도 좋다. Intel TBB, VS2010
PPL(Parallel Patterns Library)등
– ??NOBEL library, Concurrency Kit
100.
2-100
미래
• 그래도 멀티쓰레딩은힘들다.
– 서버 프로그래머 연봉이 높은 이유
• Core가 늘어나면 지금 까지의 방법도 한계
– lock-free. wait-free overhead증가
– interlocked operation overhead증가
• 예측
– Transactional Memory
– 새로운 언어의 필요
• 예) Erlang, Haskell
101.
2-101
TIP
• 절대로 경험을믿지 마라!!!
– 에러 날 확률이 로또 이하인 경우가 비일비재
– 디버깅 할 때, 사내 테스트 할 때는 멀쩡하다가
오픈베타 때 대형사고가 난다!!
– Correct가 증명된 알고리즘이나, 믿을 수 있는
회사에서 작성한 non-Blocking 프로그램을
사용하라.
• 자신이 만든 알고리즘이면 증명하세요. (증명 방법은
교재 참조)
102.
2-102
TIP
• 클라우드환경은 다르다.
–많은 가상머신에서 CompareAndSwap
오퍼레이션의 딜레이가 급증하는 현상이 있다.
– Parallels on MaxOS-X (OK)
– VMWare, Parallels, VirtualBox on Windows-7
(성능저하)
103.
2-103
NEXT
• 다음 발표(내년???)
–Lock-free 프로그래밍 근본적 이해
– 실제 MMO서버에서의 Lock-ree 성능 향상
– Transactional Memory with intel RTM
• 그 다음 발표???
− Lock-free search : SKIP-LIST
− ABA Problem, aka 효율적인 reference counting
− 고성능 MMO서버를 위한 non-blocking
자료구조의 활용
104.
2-104
Q&A
• 연락처
– nhjung@kpu.ac.kr
–발표자료 : ftp://210.93.61.41 id:ndc21 passwd: 바람의나라
• 또는 www.slideshare.net 에서 발표제목 검색
• 참고자료
– Herlihy, Shavit, “The Art of Multiprocesor Programming, revised”,
Morgan Kaufman, 2012
– SEWELL, P., SARKAR, S., OWENS, S., NARDELLI, F. Z., AND
MYREEN, M. O. x86-tso: A rigorous and usable programmer’s
model for x86 multiprocessors. Communications of the ACM 53, 7
(July 2010), 89–97.
– INTEL, “Intel 64 and IA-32 Architectures Software Developer’s
Manual”, Vol 3A: System Programming Guide, Part 1





![2-6
도입
• 흑마술 멀티쓰레드 프로그래밍의 위험성
– “자꾸 죽는데 이유를 모르겠어요”
• 자매품 : “이상한 값이 나오는데 이유를 모르겠어요”
– “더 느려져요”
[미] MuliThreadProgramming [mʌ́ ltiθred-|proʊgrӕmɪŋ] : 1. 흑마술, 마공
2. 위력이 강대하나 다루기 어려워 잘 쓰이지 않는 기술](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-6-2048.jpg)




















![2-34
고생길
• Visual Studio의 사기
– 참조 <simple_sync>
DWORD WINAPI ThreadFunc2(LPVOID lpVoid)
{
DWORD WINAPI ThreadFunc2(LPVOID lpVOid)
while(!flag);
{
my_data = data;
00951020 mov
al,byte ptr [flag
}
00951025
00951027
싱글 쓰레드 프로그램이면?
VS는 무죄!
(953374h)]
while (!flag);
test
al,al
je
ThreadFunc2+5 (951025h)
int my_data = data;
printf("Data is %Xn", my_data);
mov
eax,dword ptr [data (953370h)]
push
eax
push
offset string "Data is %Xn"
00951029
0095102E
0095102F
(952104h)
00951034 call
(9520ACh)]
0095103A add
return 0;
0095103D xor
}
0095103F ret
dword ptr [__imp__printf
esp,8
eax,eax
4](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-34-2048.jpg)



![고생길
• Volatile 위치 오류의 예
volatile Qnode*
next;
Qnode * volatile next;
void UnLock() {
Qnode *qnode;
qnode = myNode;
if (qnode->next == NULL) {
LONG long_qnode = reinterpret_cast<LONG>(qnode);
volatile LONG *long_tail = reinterpret_cast<volatile LONG*>(&tail);
if ( CAS(long_tail, NULL, long_qnode) ) return;
while ( qnode->next == NULL ) { }
}
qnode->next->locked = false;
qnode->next = NULL;
}
011F1089
011F108C
011F1090
011F1092
01191090
01191093
01191095
mov
test
je
eax,dword ptr [esi+4]
eax,eax
ThreadFunc+90h (1191090h)
mov
lea
cmp
je
eax,dword ptr [esi+4]
esp,[esp]
eax,ebx
ThreadFunc+90h (11F1090h)](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-38-2048.jpg)




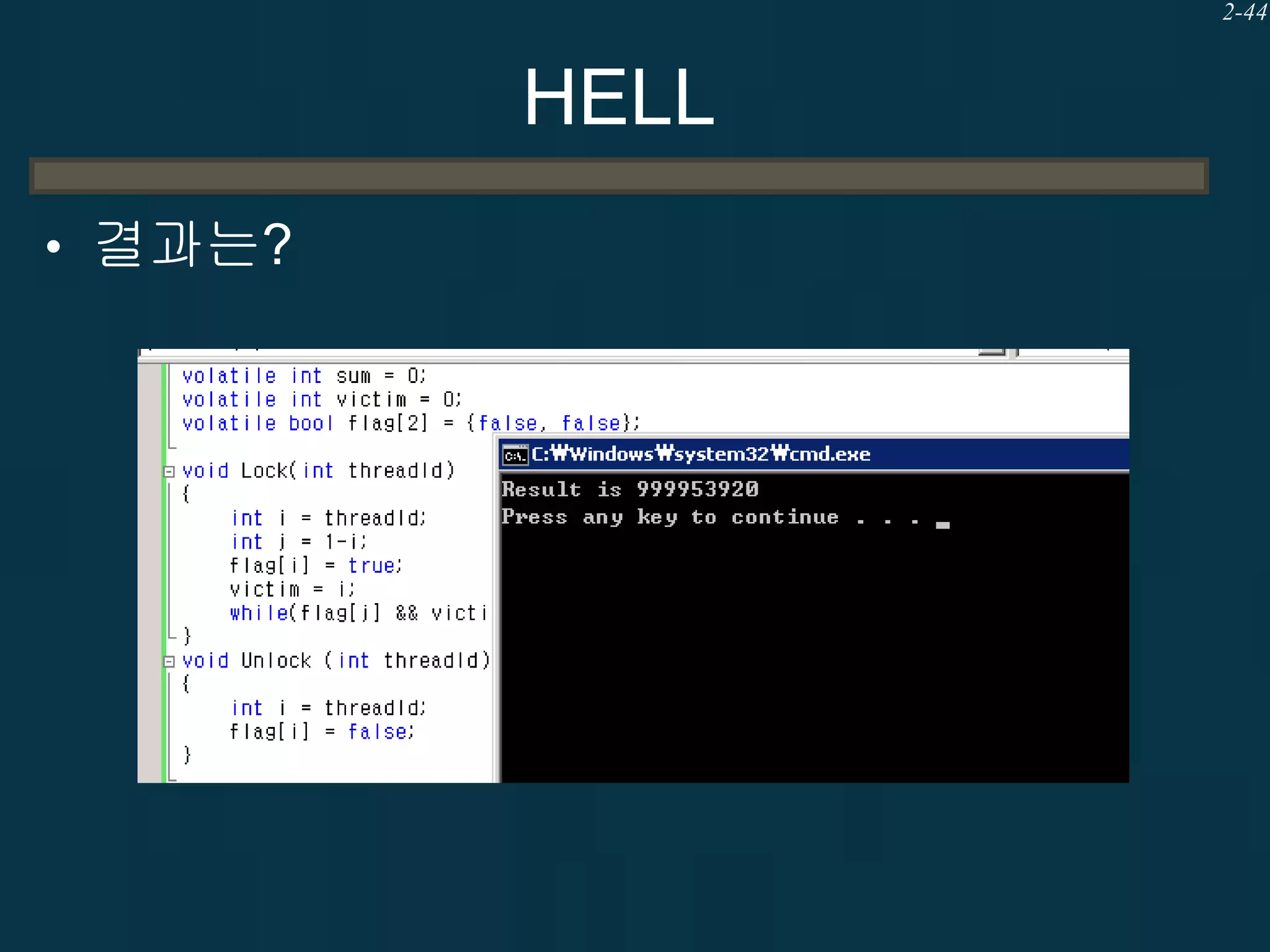
![2-43
HELL
• 다음의 프로그램으로 Lock과 Unlock이 동작할까?
– 피터슨 알고리즘
– 두 개의 쓰레드에서 Lock구현
– 운영체제 교과서에 실려 있음
– threadId는 0과 1이라고 가정 (myID에 저장)
• 실행해 보자
• 결과는?
volatile int victim = 0;
volatile bool flag[2] = {false, false};
Lock(int myID)
{
int other = 1 – myID;
flag[myID] = true;
victim = myID;
while(flag[other] && victim == myID) {}
}
Unlock (int myID)
{
flag[myID] = false;
}](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-43-2048.jpg)








![2-53
HELL
• 정말 간단한 프로그램
#define THREAD_MAX 2
#define SIZE 10000000
volatile int x,y;
int trace_x[SIZE], trace_y[SIZE];
DWORD WINAPI ThreadFunc0(LPVOID a)
{
for(int i = 0; i <SIZE;i++) {
x = i;
trace_y[i] = y;
}
return 0;
}
int main()
{
DWORD addr;
HANDLE hThread[THREAD_MAX];
DWORD WINAPI ThreadFunc1(LPVOID a)
{
for(int i = 0; i <SIZE;i++) {
y = i;
trace_x[i] = x;
}
return 0;
}
.. // Thread 2개 실행
int count = 0;
for (int i=0; i< SIZE;++i)
if (trace_x[i] == trace_x[i+1])
if (trace_y[trace_x[i]] == trace_y[trace_x[i] + 1]) {
if (trace_y[trace_x[i]] != i) continue;
count++;
}
printf("Total Memory Inconsistency:%dn", count);
return 0;
}](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-53-2048.jpg)



![2-58
병행성과 정확성
• 어떻게 실행했길래?
int ARR[32];
int temp = (int) &ARR[16];
temp = temp & 0xFFFFFFC0;
temp -= 2;
bound = (int *) temp;
*bound = 0;
HANDLE hThread2 = CreateThread(NULL, 0, ThreadFunc1, (LPVOID) 0, 0, &addr);
HANDLE hThread3 = CreateThread(NULL, 0, ThreadFunc2, (LPVOID) 1, 0, &addr);](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-58-2048.jpg)

![2-60
HELL
• 결과가….
– 중간값
• write시 최종값과 초기값이 아닌 다른 값이 도중에 메모리에
써지는 현상
– 이유는?
• Cache Line Size Boundary
– 대책은?
• Pointer를 절대 믿지 마라.
• Byte 밖에 믿을 수 없다.
• Pointer가 아닌 변수는
– Visual C++ 또는 G++가 잘 해준다.
unsigned char buf[256]
buf[0] = length;
buf[1] = OP_MOVE;
*((float *)(&buf[2])) = x;
*((float *)(&buf[6])) = y;
*((float *)(&buf[10])) = z;
*((float *)(&buf[14])) = dx;
*((float *)(&buf[18])) = dy;
*((float *)(&buf[22])) = dz;
*((float *)(&buf[26])) = ax;
*((float *)(&buf[30])) = ay;
*((float *)(&buf[34])) = az;
*((int *)(&buf[38])) = h;
…
send( fd, buf, (size_t)buf[0], 0 );
어디서 많이 본 소스코드..](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-60-2048.jpg)


















![2-80
CAS
• 실제 HW (x86 계열 CPU) 구현
– LOCK prefix와 CMPXCHG 명령어로 구현
– lock cmpxchg [A], b 기계어 명령으로
구현
• eax에 비교값, A에 주소, b에 넣을 값
if (eax == [a]) {
ZF = true;
[a] = b;
} else {
ZF = false;
eax = [a];
}](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-80-2048.jpg)
![2-81
CAS
• 실제 HW (ARM) 구현
static inline AtomicWord CompareAndSwap(volatile AtomicWord* ptr,
AtomicWord old_value,
AtomicWord new_value)
{
uint32_t old, tmp;
__asm__ __volatile__("1: @ atomic cmpxchgn"
"mov %0, #0n"
"ldrex %1, [%2]n"
"teq %1, %3n"
"strexeq %0, %4, [%2]n"
"teq %0, #0n"
"bne 1b"
: "=&r" (tmp), "=&r" (old)
: "r" (ptr), "Ir" (old_value),
"r" (new_value)
: "cc");
return old;
}](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-81-2048.jpg)

![2-83
CAS
•
모든 자료구조를 멀티쓰레드 Lock-Free로 바꿔주는 프로그램
class LFUniversal {
private:
Node *head[N], Node tail;
public:
LFUniversal() {
tail.seq = 1;
for (int i=0;i<N;++i) head[i] = &tail;
}
Response apply(Invocation invoc) {
int i = Thread_id();
Node prefer = Node(invoc);
while (prefer.seq == 0) {
Node *before = tail.max(head);
Node *after = before->decideNext->decide(&prefer);
before->next = after; after->seq = before->seq + 1;
head[i] = after;
}
SeqObject myObject;
Node *current = tail.next;
while (current != &prefer) {
myObject.apply(current->invoc);
current = current->next;
}
return myObject.apply(current->invoc);
} };](https://image.slidesharecdn.com/naver-3-131017034221-phpapp02/75/2013-DEVIEW-83-2048.jpg)





















![[2B7]시즌2 멀티쓰레드프로그래밍이 왜 이리 힘드나요](https://cdn.slidesharecdn.com/ss_thumbnails/2b72-140930004949-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[아꿈사/110528] 멀티코어cpu이야기 5,6장](https://cdn.slidesharecdn.com/ss_thumbnails/110528cpu56-110527204545-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

