3文字読む関数と1桁読む関数
def eat_repeat(chrs, c,max):
count = 0
while len(chrs) > 0:
cc = chrs.pop()
if cc != c:
chrs.append(cc)
break
count += 1
if count > max:
return -1
return count
def eat_digit(chrs, one, five, ten,
mul):
if len(chrs) == 0:
print('empty')
return -1
c = chrs.pop()
if c == one:
v = eat_repeat(chrs, one, 2)
if v > 0:
return mul * (v + 1)
elif v < 0:
return v
if len(chrs) == 0:
return mul
c2 = chrs.pop()
if c2 == ten:
return mul * 9
elif c2 == five:
return mul * 4
else:
chrs.append(c2)
return mul
elif c == five:
v = eat_repeat(chrs, one, 3)
if v >= 0:
return mul * (v + 5)
else:
return v
else:
chrs.append(c)
return 0
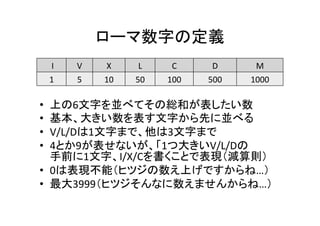
結果クラスと連続文字パース
sealed case classParseResult(chrs: Seq[Char], num: Int) {
def +(add: Int) = ParseResult(chrs, num + add)
}
private def parseRepeated(chrs: Seq[Char], chr: Char, mul: Int):
Option[ParseResult] = {
val next = chrs.indexWhere(_ != chr)
val drop = if (next >= 0) next else chrs.length
if (drop <= 3) {
Some(ParseResult(chrs.drop(drop), drop * mul))
} else {
None
}
}
15.
各桁のパース
private def parseThousand(chrs:Seq[Char]): Option[ParseResult] = parseRepeated(chrs,
'M', 1000)
private def parseDigit(chrs: Seq[Char], chr1: Char, chr5: Char, chr10: Char, mul:
Int): Option[ParseResult] =
chrs.headOption match {
case Some(c) if c == chr1 =>
chrs.tail.headOption match {
case Some(cc) if cc == chr10 =>
Some(ParseResult(chrs.drop(2), mul * 9))
case Some(cc) if cc == chr5 =>
Some(ParseResult(chrs.drop(2), mul * 4))
case Some(cc) if cc == chr1 =>
parseRepeated(chrs, chr1, mul)
case _ =>
Some(ParseResult(chrs.tail, mul))
}
case Some(c) if c == chr5 =>
parseRepeated(chrs.tail, chr1, mul).map(_ + mul * 5)
case _ =>
Some(ParseResult(chrs, 0))
16.
統合
override def parseRoman(str:String): Int = (for {
t <- parseThousand(str)
h <- parseDigit(t.chrs, 'C', 'D', 'M', 100)
e <- parseDigit(h.chrs, 'X', 'L', 'C', 10)
o <- parseDigit(e.chrs, 'I', 'V', 'X', 1)
} yield {
val value = if (o.chrs.isEmpty) t.num + h.num + e.num + o.num
else -1
if (value > 0) value else -1
}).getOrElse(-1)
数値に変換=足し算
def parse(str):
m =r.match(str)
if m is None:
return -1
else:
return parse_thousand(m.group(1)) +
parse_hundred(m.group(2)) +
parse_ten(m.group(3)) +
parse_one(m.group(4))
RegexParsersでべた書き
lazy val hundred9:Parser[Int] = "CM" ^^ (_ => 900)
lazy val hundred5: Parser[Int] = "DC{0,3}".r ^^ (_.length() * 100 -
100 + 500)
lazy val hundred4: Parser[Int] = "CD" ^^ (_ => 400)
lazy val hundred1: Parser[Int] = "C{0,3}".r ^^ (_.length * 100)
lazy val hundred: Parser[Int] = hundred9 | hundred5 | hundred4 |
hundred1
lazy val romanNumerals: Parser[Int] = thousand ~! hundred ~! ten ~!
one ^^ {
case t ~ h ~ e ~ o => t + h + e + o
}
def parseRoman(str:String): Int = parseAll(romanNumerals, str) match
{
case Success(num, next) => if (num > 0) num else -1
case NoSuccess(errorMessage, next) => -1
}
RegexParsersでパーサー生成(2)
lazy val romanNumerals:Parser[Int] =
createParser('M', None, None, 1000) ~!
createParser('C', Some('D'), Some('M'), 100) ~!
createParser('X', Some('L'), Some('C'), 10) ~!
createParser('I', Some('V'), Some('X'), 1) ^^ {
case t ~ h ~ e ~ o => t + h + e + o
}
def parseRoman(str:String): Int = parseAll(romanNumerals, str)
match {
case Success(num, next) => if (num > 0) num else -1
case NoSuccess(errorMessage, next) => -1
}













![結果クラスと連続文字パース
sealed case class ParseResult(chrs: Seq[Char], num: Int) {
def +(add: Int) = ParseResult(chrs, num + add)
}
private def parseRepeated(chrs: Seq[Char], chr: Char, mul: Int):
Option[ParseResult] = {
val next = chrs.indexWhere(_ != chr)
val drop = if (next >= 0) next else chrs.length
if (drop <= 3) {
Some(ParseResult(chrs.drop(drop), drop * mul))
} else {
None
}
}](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-14-320.jpg)
![各桁のパース
private def parseThousand(chrs: Seq[Char]): Option[ParseResult] = parseRepeated(chrs,
'M', 1000)
private def parseDigit(chrs: Seq[Char], chr1: Char, chr5: Char, chr10: Char, mul:
Int): Option[ParseResult] =
chrs.headOption match {
case Some(c) if c == chr1 =>
chrs.tail.headOption match {
case Some(cc) if cc == chr10 =>
Some(ParseResult(chrs.drop(2), mul * 9))
case Some(cc) if cc == chr5 =>
Some(ParseResult(chrs.drop(2), mul * 4))
case Some(cc) if cc == chr1 =>
parseRepeated(chrs, chr1, mul)
case _ =>
Some(ParseResult(chrs.tail, mul))
}
case Some(c) if c == chr5 =>
parseRepeated(chrs.tail, chr1, mul).map(_ + mul * 5)
case _ =>
Some(ParseResult(chrs, 0))](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-15-320.jpg)





![千の位と百の位のパース
r = re.compile("""^(M{0,3})(CM|DC{0,3}|CD|C{0,3})
(XC|LX{0,3}|XL|X{0,3})(IX|VI{0,3}|IV|I{0,3})$""")
def parse_thousand(str):
return len(str) * 1000
def parse_hundred(str):
if not str:
return 0
elif str == 'CM':
return 900
elif str == 'CD':
return 400
elif str[0] == 'D':
return 500 + (len(str) - 1) * 100
else:
return len(str) * 100](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-21-320.jpg)



![RegexParsersでべた書き
lazy val hundred9: Parser[Int] = "CM" ^^ (_ => 900)
lazy val hundred5: Parser[Int] = "DC{0,3}".r ^^ (_.length() * 100 -
100 + 500)
lazy val hundred4: Parser[Int] = "CD" ^^ (_ => 400)
lazy val hundred1: Parser[Int] = "C{0,3}".r ^^ (_.length * 100)
lazy val hundred: Parser[Int] = hundred9 | hundred5 | hundred4 |
hundred1
lazy val romanNumerals: Parser[Int] = thousand ~! hundred ~! ten ~!
one ^^ {
case t ~ h ~ e ~ o => t + h + e + o
}
def parseRoman(str:String): Int = parseAll(romanNumerals, str) match
{
case Success(num, next) => if (num > 0) num else -1
case NoSuccess(errorMessage, next) => -1
}](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-25-320.jpg)

![RegexParsersでパーサー生成(1)
private def createParser(chr1: Char, chro5: Option[Char],
chro10: Option[Char], mul: Int): Parser[Int] = {
val p1 = (chr1.toString + "{0,3}").r ^^ (_.length * mul)
(for {
chr5 <- chro5
chr10 <- chro10
} yield {
(chr1.toString + chr10) ^^ (_ => 9 * mul) |
(chr5.toString + chr1 + "{0,3}").r ^^
(s => (s.length() + 4) * mul) |
(chr1.toString + chr5) ^^ (_ => 4 * mul) |
p1
}).getOrElse(p1)
}](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-27-320.jpg)
![RegexParsersでパーサー生成(2)
lazy val romanNumerals: Parser[Int] =
createParser('M', None, None, 1000) ~!
createParser('C', Some('D'), Some('M'), 100) ~!
createParser('X', Some('L'), Some('C'), 10) ~!
createParser('I', Some('V'), Some('X'), 1) ^^ {
case t ~ h ~ e ~ o => t + h + e + o
}
def parseRoman(str:String): Int = parseAll(romanNumerals, str)
match {
case Success(num, next) => if (num > 0) num else -1
case NoSuccess(errorMessage, next) => -1
}](https://image.slidesharecdn.com/procon20-yonezawaizumi-20170902-170902054500/85/slide-28-320.jpg)







![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera](https://cdn.slidesharecdn.com/ss_thumbnails/dl2018216vnect1-180323034835-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)























![[Basic 11] 文脈自由文法 / 構文解析 / 言語解析プログラミング](https://cdn.slidesharecdn.com/ss_thumbnails/basic-11-180306134245-thumbnail.jpg?width=640&height=640&fit=bounds)