Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Sotetsu KOYAMADA(小山田創哲)
PDF, PPTX
1,828 views
【論文紹介】Reward Augmented Maximum Likelihood for Neural Structured Prediction
Reward Augmented Maximum Likelihood for Neural Structured Prediction Norouzi et al. 2016 (NIPS)
Engineering
◦
Related topics:
Reinforcement Learning
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 14
2
/ 14
3
/ 14
4
/ 14
5
/ 14
6
/ 14
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
Recent rl
by
Reiji Hatsugai
PDF
Continuous control
by
Reiji Hatsugai
PDF
論文輪読資料「Multi-view Face Detection Using Deep Convolutional Neural Networks」
by
Kaoru Nasuno
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
PDF
introduction to Dueling network
by
WEBFARMER. ltd.
PDF
強化学習その3
by
nishio
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
Q prop
by
Reiji Hatsugai
Recent rl
by
Reiji Hatsugai
Continuous control
by
Reiji Hatsugai
論文輪読資料「Multi-view Face Detection Using Deep Convolutional Neural Networks」
by
Kaoru Nasuno
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
introduction to Dueling network
by
WEBFARMER. ltd.
強化学習その3
by
nishio
Stan超初心者入門
by
Hiroshi Shimizu
Q prop
by
Reiji Hatsugai
Similar to 【論文紹介】Reward Augmented Maximum Likelihood for Neural Structured Prediction
PDF
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
PPTX
論文紹介: Value Prediction Network
by
Katsuki Ohto
PDF
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
by
Eiji Uchibe
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PPTX
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement ...
by
Keisuke Nakata
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PPTX
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
by
Deep Learning JP
PDF
ICASSP2017読み会 (Deep Learning III) [電通大 中鹿先生]
by
Shinnosuke Takamichi
PDF
ICML2017 参加報告会 山本康生
by
Yahoo!デベロッパーネットワーク
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
PDF
ACL2020
by
Arithmer Inc.
PDF
NeurIPS'21参加報告 tanimoto_public
by
Akira Tanimoto
PPTX
[DL輪読会]Explainable Reinforcement Learning: A Survey
by
Deep Learning JP
PPTX
[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking
by
Deep Learning JP
PPTX
【DL輪読会】Data-Efficient Reinforcement Learning with Self-Predictive Representat...
by
Deep Learning JP
PDF
[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction
by
Deep Learning JP
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PPTX
20160716 ICML paper reading, Learning to Generate with Memory
by
Shinagawa Seitaro
PDF
[DL輪読会]Z-Forcing: Training Stochastic Recurrent Networks (NIPS2017)
by
Deep Learning JP
PDF
Fast abstractive summarization with reinforce selected sentence rewriting
by
Yasuhide Miura
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
論文紹介: Value Prediction Network
by
Katsuki Ohto
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
by
Eiji Uchibe
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement ...
by
Keisuke Nakata
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
by
Deep Learning JP
ICASSP2017読み会 (Deep Learning III) [電通大 中鹿先生]
by
Shinnosuke Takamichi
ICML2017 参加報告会 山本康生
by
Yahoo!デベロッパーネットワーク
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
ACL2020
by
Arithmer Inc.
NeurIPS'21参加報告 tanimoto_public
by
Akira Tanimoto
[DL輪読会]Explainable Reinforcement Learning: A Survey
by
Deep Learning JP
[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking
by
Deep Learning JP
【DL輪読会】Data-Efficient Reinforcement Learning with Self-Predictive Representat...
by
Deep Learning JP
[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction
by
Deep Learning JP
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
20160716 ICML paper reading, Learning to Generate with Memory
by
Shinagawa Seitaro
[DL輪読会]Z-Forcing: Training Stochastic Recurrent Networks (NIPS2017)
by
Deep Learning JP
Fast abstractive summarization with reinforce selected sentence rewriting
by
Yasuhide Miura
More from Sotetsu KOYAMADA(小山田創哲)
PDF
【論文紹介】PGQ: Combining Policy Gradient And Q-learning
by
Sotetsu KOYAMADA(小山田創哲)
PDF
【強化学習】Montezuma's Revenge @ NIPS2016
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2016論文読み会資料(DeepIntent)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
強化学習勉強会・論文紹介(第22回)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
Principal Sensitivity Analysis
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2015論文読み会
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2014勉強会 発表資料
by
Sotetsu KOYAMADA(小山田創哲)
PDF
知能型システム論(後半)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
【論文紹介】PGQ: Combining Policy Gradient And Q-learning
by
Sotetsu KOYAMADA(小山田創哲)
【強化学習】Montezuma's Revenge @ NIPS2016
by
Sotetsu KOYAMADA(小山田創哲)
KDD2016論文読み会資料(DeepIntent)
by
Sotetsu KOYAMADA(小山田創哲)
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
強化学習勉強会・論文紹介(第22回)
by
Sotetsu KOYAMADA(小山田創哲)
Principal Sensitivity Analysis
by
Sotetsu KOYAMADA(小山田創哲)
KDD2015論文読み会
by
Sotetsu KOYAMADA(小山田創哲)
KDD2014勉強会 発表資料
by
Sotetsu KOYAMADA(小山田創哲)
知能型システム論(後半)
by
Sotetsu KOYAMADA(小山田創哲)
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
【論文紹介】Reward Augmented Maximum Likelihood for Neural Structured Prediction
1.
論文紹介 “Reward Augmented Maximum
Likelihood for Neural Structured Prediction” Norouzi et al. 2016 (NIPS) @sotetsuk
2.
一枚で説明すると https://docs.goog le.com/presentati on/d/1P_ks8cqXc Qmc8rBk7QlxcBH wfSdlNYnPmnWF 0yj_nYs/edit#slide =id.g20593483e2_ 0_17
3.
何故この論文を紹介するか ● 最近強化学習界隈ではエントロピー正則化付きの方策勾配法に関する研究が おもしろい(e.g., PGQ,
PCL) ○ この文脈で引用される文献として挙げられる ● アルゴリズムのヒューリスティックさと理論的裏付けのギャップがおもしろい
4.
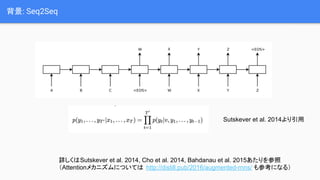
背景: Seq2Seq 詳しくはSutskever et
al. 2014, Cho et al. 2014, Bahdanau et al. 2015あたりを参照 (Attentionメカニズムについては http://distill.pub/2016/augmented-rnns/ も参考になる) Sutskever et al. 2014より引用
5.
背景: Seq2Seqの最適化における問題点(トレーニング、テスト時の指標の乖離) Seq2Seqの最適化には以下のような問題点がある : 1.
テスト時に最適化したい指標を直接最適化していない( e.g., テストはBLUE、トレーニングは対数尤度) 2. トレーニング時には予測する次のトークンを真の次のトークンと置き換えて条件付けるが、テスト時には モデルによる予測で条件付けている(トレーニング時にはそれまでの自分の予測が全てあっているとい う条件のもとで次のトークンの予測をして尤度を計算している) これらの問題点を解決するため、強化学習的なアプローチで最適化する研究がいくつかある (e.g., Ranzato et al. 2016, Bahdanau et al. 2017)
6.
背景: Seq2Seqの強化学習による最適化(とその問題点) デコーダーのを方策と見立てて現在時点までの自分の予測の系列(とコンテキスト)を現在の状態、として次の トークンを行動として予測・学習する Ranzato et
al. 2016: RNNによるDecoderの予測を確率的な方策だとして、文の最後まで予測をしたら BLUE等 のスコアによって報酬を与えることで強化学習の問題に落とし、 REINFORCEで解いている。 強化学習の問題と しては行動空間が大きすぎるので、クロスエントロピー誤差も組み合わせることにより解決する MIXERを提案。 具体的には、最初の方の epochはクロスエントロピー誤差だけでトレーニングし、その後で段々と REINFORCE で学習するトークン数を後ろから前に広げていく。 Bahdanau et al. 2017: REINFORCEベースの手法は勾配の分散が大きくなってしまうので、 actor-criticにして 行動価値関数も推定することで分散を減らして性能の向上をさせたい。 先行研究と同じように Decoderを確率的 な方策と見なし、各トークンを予測したときに BLUE等から報酬を定めて強化学習の枠組みに落とし込み、 actor-criticで解いている。 また、大きい行動空間を制限するためのヒューリスティックな工夫や、 報酬がスパース になるのを避けるため部分系列にも報酬を定義するなどの工夫もした上で対数尤度でプレトレーニングもしてい る。 結局のところ、(1) 行動空間が大きすぎるのに加え、 (2) 報酬がスパース(系列の終わりだけ)という2つの問題が あり、結局MLベースでプレトレーニングのようなことをしないと両手法うまく学習できない。
7.
提案手法 (RAML) RLの推定方策でのサンプリングを回避 特徴 ● RLの目的関数をKLダイバージェ ンスで書いたときと同じ二つの分 布のKLダイバージェンスを(前後 逆にして)最小化している ●
正則化パラメータτ↓0 でMLの目 的関数と同じになる ● 最適化時にサンプリングする分布 が推定方策でなく、定常分布qに なる(推定方策の初期化がクリ ティカルでなくなり、報酬ベースの 最適化がこれ単体で出来るように なった) Appendixに計算の補足を用意しました
8.
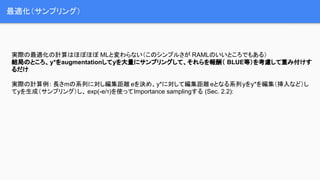
最適化(サンプリング) 実際の最適化の計算はほぼほぼ MLと変わらない(このシンプルさが RAMLのいいところでもある) 結局のところ、y*をaugmentationしてyを大量にサンプリングして、それらを報酬(
BLUE等)を考慮して重み付けす るだけ 実際の計算例: 長さmの系列に対し編集距離 eを決め、y*に対して編集距離eとなる系列yをy*を編集(挿入など)し てyを生成(サンプリング)し、 exp(-e/τ)を使ってImportance samplingする (Sec. 2.2):
9.
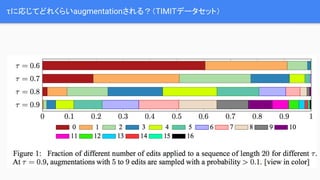
τに応じてどれくらいaugmentationされる?(TIMITデータセット)
10.
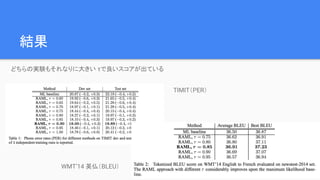
結果 WMT’14 英仏(BLEU) TIMIT(PER) どちらの実験もそれなりに大きい τで良いスコアが出ている
11.
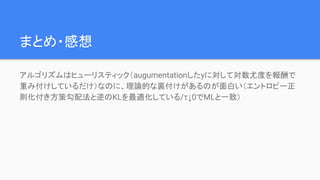
まとめ・感想 アルゴリズムはヒューリスティック(augumentationしたyに対して対数尤度を報酬で 重み付けしているだけ)なのに、理論的な裏付けがあるのが面白い(エントロピー正 則化付き方策勾配法と逆のKLを最適化している/τ↓0でMLと一致)
12.
Appendix A
13.
Appendix B
14.
Appendix C
Download






















![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)

![ICASSP2017読み会 (Deep Learning III) [電通大 中鹿先生]](https://cdn.slidesharecdn.com/ss_thumbnails/icayominakashika-170628021331-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Explainable Reinforcement Learning: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/dl20201218okada-201218023817-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking](https://cdn.slidesharecdn.com/ss_thumbnails/20220311arlfinal-220314025127-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Z-Forcing: Training Stochastic Recurrent Networks (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/180810nonakadlhacks-180810002712-thumbnail.jpg?width=640&height=640&fit=bounds)










