This document discusses various techniques for optimizing search, including:
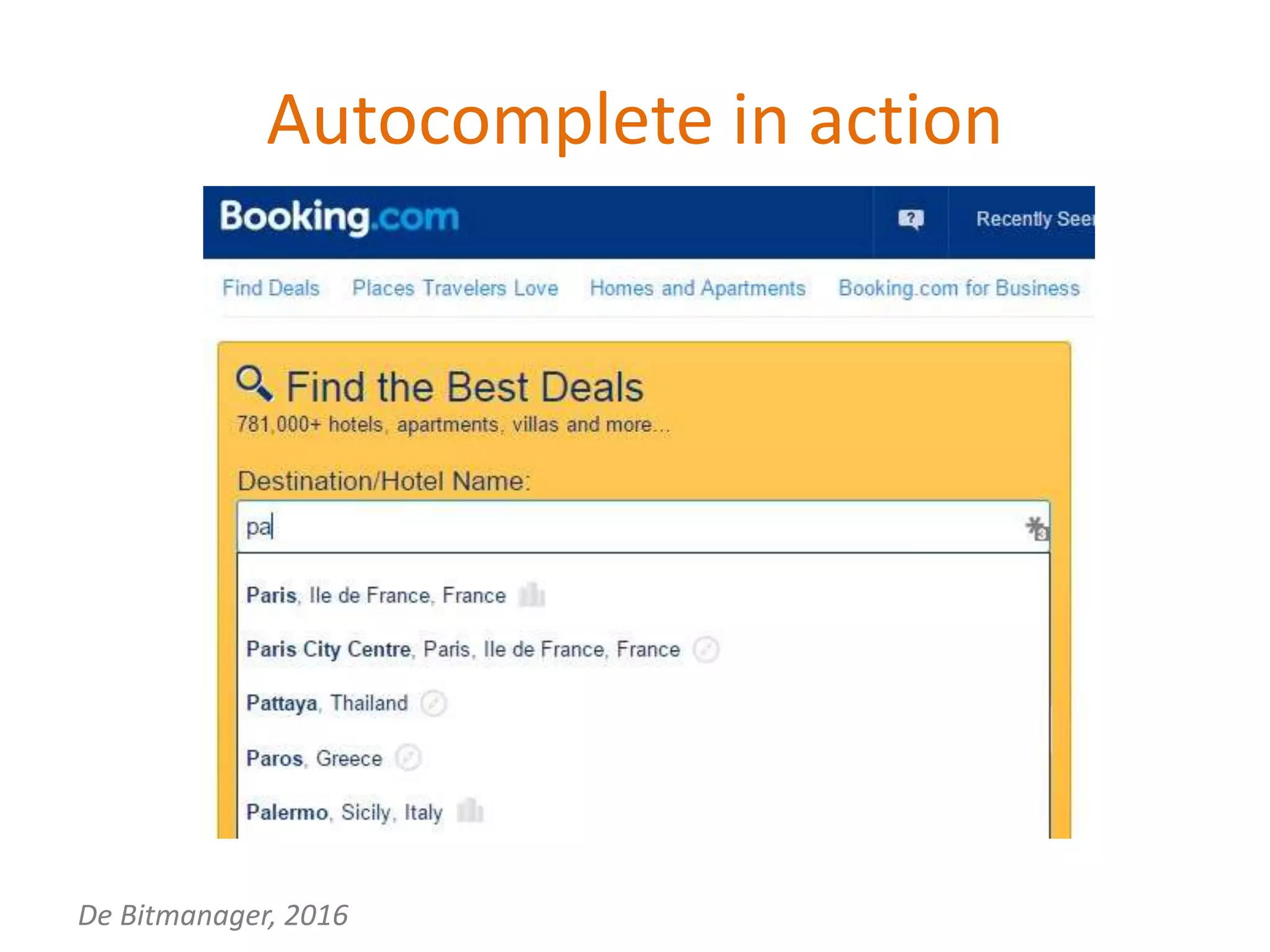
- Using autocomplete and disambiguation to improve destination search results at Booking.com
- Scoring documents based on term frequency, inverse document frequency, record popularity, language matches, and other factors
- Normalizing scores to range from 1-1.4 to better combine different scoring components
- Storing additional field information in payloads to simulate dismax queries over a single field
- Different approaches for combining query terms matched in multiple fields to find documents where terms are near each other


























![De Bitmanager, 2016
Dismax example
• Q= the house
Suppose S[the] = 0.8, S[house]=1.2
• Scores for different tiebreakers:
Bool score (tiebreaker=1): 2.0
Max score (tiebreaker=0): 1.2
Score with tiebreaker=0.1: 1.28
this makes documents containing ‘the house’ a
little bit more important than ‘house’ only.](https://image.slidesharecdn.com/youknowforsearch-160713205239/75/You-know-for-search-28-2048.jpg)



![De Bitmanager, 2016
Payload
• Small piece of information that is added to
every occurrence
• Basically a byte[]](https://image.slidesharecdn.com/youknowforsearch-160713205239/75/You-know-for-search-32-2048.jpg)















































































