Download to read offline





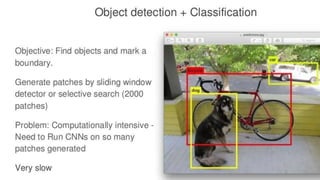


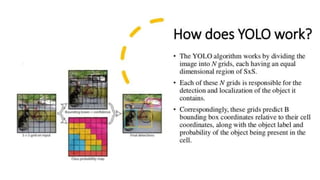





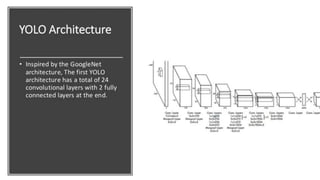
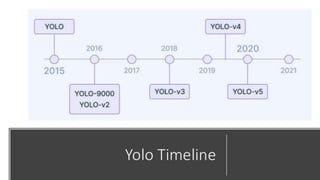
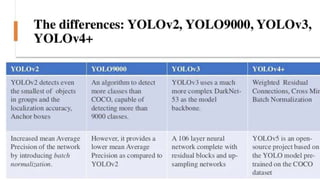


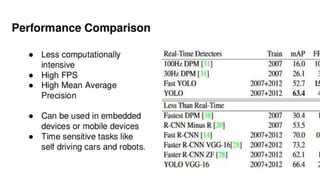


The document discusses the YOLO algorithm for object detection, including definitions of object detection and various detection stages. It details the workings of YOLO, its architecture, and different versions such as YOLOv2, YOLO9000, YOLOv3, and YOLOv4+. Additionally, it highlights the importance of the YOLO algorithm and provides a performance comparison.
![OpenGL Mini Projects With Source Code [ Computer Graphics ]](https://cdn.slidesharecdn.com/ss_thumbnails/newmicrosoftpowerpointpresentation-180330204024-thumbnail.jpg?width=640&height=640&fit=bounds)











































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







