This document summarizes the steps to execute a WordCount program using Hadoop MapReduce:
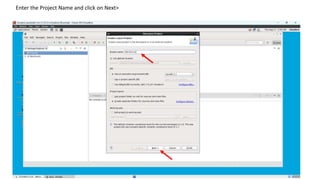
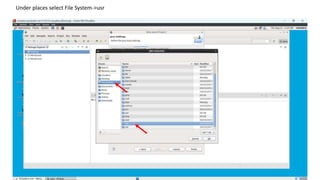
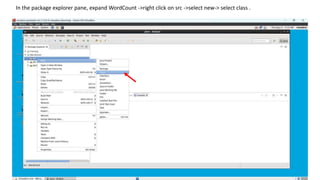
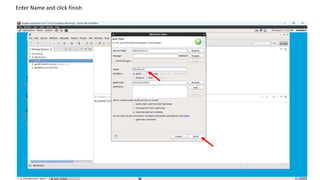
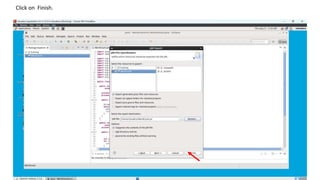
1. Create a Java project in Eclipse, add the necessary Hadoop JAR files, and create a WordCount class with the MapReduce code.
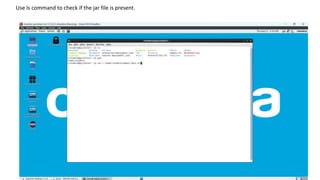
2. Export the program to a JAR file and check that it exists locally.
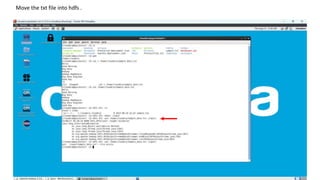
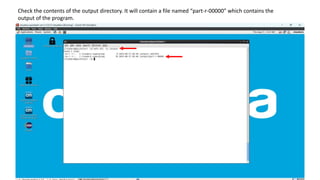
3. Put sample input data in HDFS, run the MapReduce job with the input and output directories specified, and check the output file for word counts.