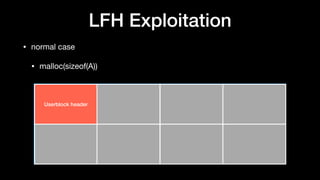
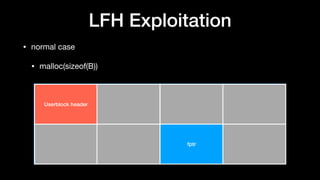
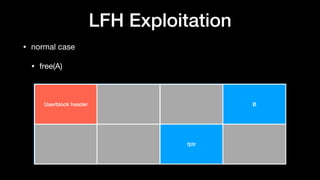
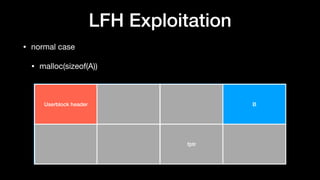
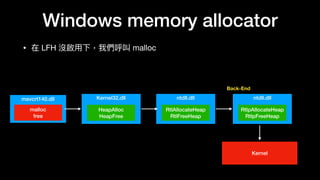
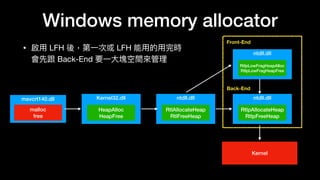
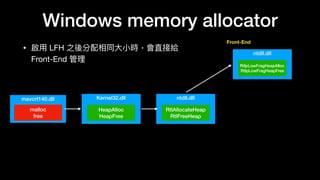
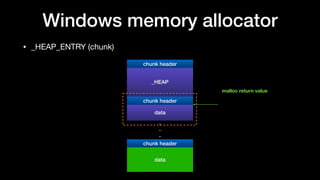
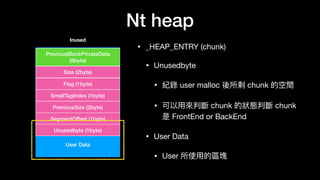
The document discusses Windows memory allocation and the NT heap. It describes the core data structures used, including the _HEAP, _HEAP_ENTRY chunks, and _HEAP_LIST_LOOKUP BlocksIndex. It explains how allocated, freed, and VirtualAlloc chunks are structured and managed in the Back-End, including using freelist chains and BlocksIndex to efficiently service allocation requests.












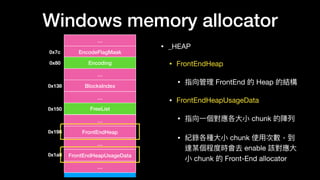
















![…
EncodeFlagMask
Encoding
…
BlocksIndex
…
FreeList
…
FrontEndHeap
…
FrontEndHeapUsageDat
…
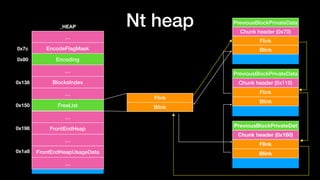
_HEAP
BlocksIndex
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Flink
Blink
Chunk header (0x110)
PreviousBlockPrivate
Flink
Blink
Chunk header(0x160)
PreviousBlockPrivat
ListHint
Flink
Flink
Flink
ListHint[7]
ListHint[0x11]
ListHint[0x16]
000001…1…1000000000
ListsInUseUlong](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-36-320.jpg)











![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
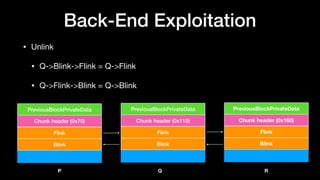
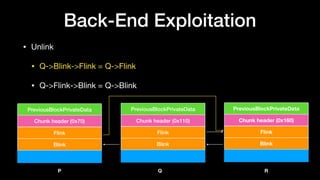
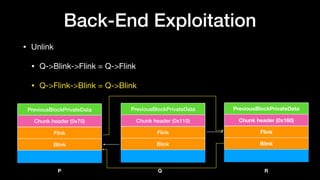
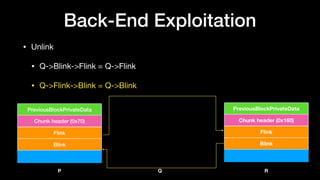
P
Q
R
S
Free(Q)
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-48-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Find Prevchunk
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Prevchunk =
Chunk address
-
(prevsize << 4)](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-49-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Find Prevchunk
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Prevchunk =
chunk addr - 0x70](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-50-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Decode prevchunk
header
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-51-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check checksum
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
SmallTagInex ==
(size & 0xff)
xor
(size >> 8)
xor
Flag](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-52-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check checksum
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
7 ==
0x7^0x0^0x0](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-53-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
linked list
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
P->Flink->Blink ==
P->Blink->Flink ==
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-54-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Find
BlocksIndex
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-55-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Find suitable
BlocksIndex
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
Check
P->size < ArraySize](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-56-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
ListHint
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
Check
ListHint[7] ==
Prevchunk](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-57-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
ListHint
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
Check
prevchunk->Flink ==
ListHead
成立的話會準備 update
ListHint](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-58-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
ListHint[7]->Flink
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
decode
prevchunk->Flink
And check
the checksum
由於前⼀一張 slide 不成立
要去驗 Flink 的 size](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-59-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
ListHint[7]->Flink
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
Size ==
prevchunk->Flink->size
如果相等,直接將 ListHint
換成下⼀一塊](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-60-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Update
ListHint[7]
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
ListHint[7] =
prevchunk->Flink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-61-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Flink
Blink
Chunk header (0x70)
PreviousBlockPrivate
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Unlink
prevchunk
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x7)
Flag (0x0)
SmallTagIndex (0x7)
Prevchunk->Blink->Flink
= Prevchunk->Flink
Prevchunk->Flink->Blink
= Prevchunk->Blink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-62-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Update
prevchunk
and next chunk
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
Prevchunk->size =
0x11 + Prevchunk->size(7)
R->Prevsize = 0x18
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-63-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Check
next chunk
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
檢查下⼀一塊 chunk
使否 freed
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-64-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Find suitable
BlocksIndex
For P
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
Check
P->Size < ArraySize
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-65-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Search
insert
point
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
Check
P->size <
ListHead->Blink->Size
P->size <
ListHead->Flink->Size
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-66-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Insert
linked list
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
Check
S->Blink->Flink
== S
If not pass it will not
abort
But it will not unlink
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-67-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Update
ListHint
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x7)
If LintHint[0x18] == NULL
LintHint[0x18] = P
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate
FlinkListHint[0x18]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-68-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Update
header
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0x18)
Flag (0x0)
SmallTagIndex (0x18)
SmallTagIndex =
(size >> 8) ^
(size & 0xff) ^
Flag
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate
FlinkListHint[0x18]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-69-320.jpg)
![ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
Flink
Blink
Chunk header(0x110)
PreviousBlockPrivat
FlinkListHint[7]
Flink
Blink
Chunk header(0x70)
PreviousBlockPrivat
merge chunk
P
Q
R
S
Encode
header
Size (0x11)
Flag (0x1)
SmallTagIndex (0x10)
Prevsize (0x7)
Size (0xda)
Flag (0xab)
SmallTagIndex (0x41)
P->header ^
_HEAP->Encoding
P
Flink
Blink
Chunk header (0x180)
PreviousBlockPrivate
FlinkListHint[0x18]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-70-320.jpg)


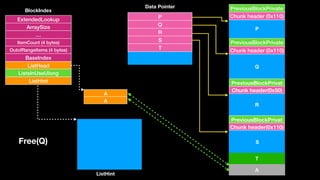
![Q
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
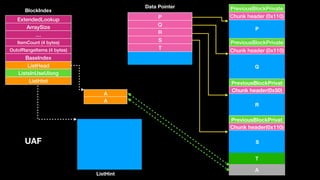
BlockIndex
Data Pointer
ListHint
T
A
A
ListHead
QListHint[0x11]
free(S)
Update ListHint](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-79-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
A
S
SListHint[0x11]
Q
ListHead](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-80-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
A
S
SListHint[0x11]
Q
ListHead
Let’s corrupt the heap !](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-81-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
free(P)](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-82-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Check next chunk
is free](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-83-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Decode
chunk Q](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-84-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead(&Q-8)->Blink
==
(&Q)->Flink
== Q](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-85-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead(&Q-8)->Blink
==
(&Q)->Flink
== Q
Flink
Blink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-86-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead(&Q-8)->Blink
==
(&Q)->Flink
== Q
Flink
Blink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-87-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead*(&Q)
==
*(&Q)
== Q](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-88-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead*(&Q)
==
*(&Q)
== Q
Pass the check !!](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-89-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Find
BlockIndex](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-90-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Check
ListHint[0x11]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-91-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead由於 S != Q
所以不會對 ListHint
做任何處理理](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-92-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
Data Pointer
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Unlink !!
Q->Blink->Flink
= Q->Flink
Flink
Blink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-93-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
&Q - 8
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHeadUnlink !!
Q = &Q-8](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-94-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
&Q - 8
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHead
Unlink !!
Q->Flink->Blink
= Q->Blink
Flink
Blink](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-95-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHeadUnlink !!
Q = &Q](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-96-320.jpg)
![S
A
Chunk header (0x110)
PreviousBlockPrivate
Q
Chunk header (0x110)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
P
Q
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
&Q - 8
&Q
SListHint[0x11]
Q
ListHeadUpdate
chunk size](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-97-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHeadUpdate
chunk size
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-98-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
Search insert point
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-99-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHeadFind the last one
And decode it
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-100-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
P
Find the first one
And decode it](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-101-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
我們要插在 A 前
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-102-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
Check
A->Blink->Flink
== A
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-103-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
Check
Q->Flink
== A
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-104-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHeadFailed
不過不會 abort
只是不會 insert
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-105-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
Update
ListHint
P](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-106-320.jpg)
![S
A
Chunk header (0x220)
PreviousBlockPrivate
Chunk header(0x50)
PreviousBlockPrivat
S
Chunk header(0x110)
PreviousBlockPrivat
R
S
P
&Q
R
S
T
ExtendedLookup
ArraySize
…
ItemCount (4 bytes)
OutofRangeItems (4 bytes)
BaseIndex
ListHead
ListsInUseUlong
ListHint
BlockIndex
ListHint
T
A
SListHint[0x11]
Q
ListHead
P
PListHint[0x22]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-107-320.jpg)















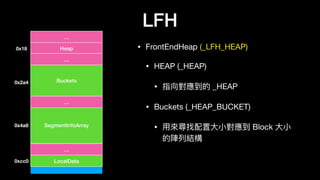
![LFH
• Buckets (_HEAP_BUCKET)
• BlockUnits
• 要分配出去的⼀一個 block ⼤大⼩小 >> 4
• SizeIndex
• 使⽤用者需要的⼤大⼩小 >> 4
BlockUnits
Buckets
SizeIndex
…
BlockUnits
SizeIndex
…
…
…
Buckets[0]
Buckets[1]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-125-320.jpg)
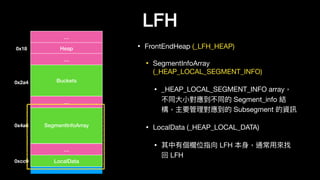
![LFH
• SegmentInfoArray
(_HEAP_LOCAL_SEGMENT_INFO)
• LocalData (_HEAP_LOCAL_DATA)
• 對應到 _LFH_HEAP->LocalData ⽅方便便
從 SegmentInfo 找回 _LFH_HEAP
• BucketIndex
• 對應到的 BucketIndex
LocalData
SegmentInfoArray[x]
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-126-320.jpg)
![LFH
• SegmentInfoArray
(_HEAP_LOCAL_SEGMENT_INFO)
• ActiveSubsegment (_HEAP_SUBSEGMENT)
• 極為重要結構
• 對應到分配出去的 Subsegment
• 其⽬目的在於管理理 Userblock
• 記錄了了剩餘多少 chunk
• 該 Userblock 最⼤大分配數等等
SegmentInfoArray[x]
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-127-320.jpg)
![LFH
• SegmentInfoArray
(_HEAP_LOCAL_SEGMENT_INFO)
• CachedItems (_HEAP_SUBSEGMENT)
• _HEAP_SUBSEGMENT array
• 存放對映到該 SegmentInfo 且還有可
以分配 chunk 給 user 的Subsegment
• 當 ActiveSubsegment ⽤用完時,會從
這邊填充,置換掉 ActiveSubsegment
SegmentInfoArray[x]
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-128-320.jpg)
![LFH
…
Heap
…
…
…
LocalData
0x18
0x2a4
0x4a8
0xcc0
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
…
EncodeFlagMask
Encoding
…
BlocksIndex
…
FreeList
…
FrontEndHeap
…
FrontEndHeapUsageData
…
_HEAP
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-129-320.jpg)






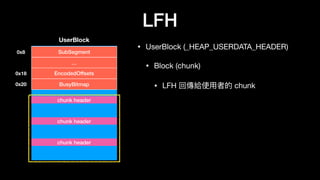





![LFH
…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-142-320.jpg)

![Windows memory allocator
• Nt Heap
• 前端管理理器 (Front-End)
• 初始化
• 在 FrontEndHeapUsageData[x] & 0x1f > 0x10 時,下⼀一次的 allocate 會對 LFH 做出初始化
• 會先 ExtendFrontEndUsageData 及增加更更⼤大的 BlocksIndex (0x80-0x400)
• 建立 FrontEndHeap
• 初始化 SegmentInfoArrays[idx]
• 接下來來在 allocate 相同⼤大⼩小的 chunk 就會開始使⽤用 LFH](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-144-320.jpg)



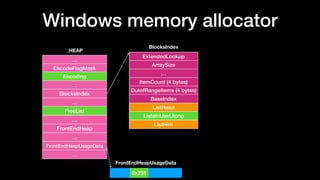
![Windows memory allocator
• LFH(初始化)
• malloc(0x40) (第 18 次)
• ExtendFrontEndUsageData 及增加更更⼤大的 BlocksIndex
(0x80-0x400) ,並設置對應的 bitmap
• 並在該對應的 FrontEndHeapUsageData 寫上對應的
index,此時可 enable LFH 範圍變為 (idx: 0-0x400)
• 建立並初始化 FrontEndHeap (mmap)
• 初始化 SegmentInfoArrays[idx]
• 在 SegmentInfoArrays[BucketIndex] 填上 segmentInfo
FrontEndHeapUsageData
…
0x4](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-149-320.jpg)
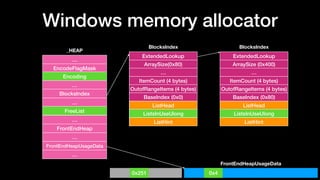
![Windows memory allocator
…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
…
EncodeFlagMask
Encoding
…
BlocksIndex
…
FreeList
…
FrontEndHeap
…
FrontEndHeapUsageData
…
_HEAP
FrontEndHeapUsageData
0x251 0x4](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-151-320.jpg)

![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-153-320.jpg)

![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Find SegementIfoArray by bucket->SizeIndex](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-155-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Find SegementIfoArray by bucket->SizeIndex](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-156-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Check ActiveSubsegment](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-157-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Check ActiveSubsegment](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-158-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Check ArgregateExchg.Depth not 0](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-159-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Check ArgregateExchg.Depth not 0](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-160-320.jpg)
![…
Heap
…
…
…
LocalData
Buckets[x]
SegmentInfoArray[x]
BlockUnits
SizeIndex
…
_LFH_HEAP
_HEAP_BUCKET
_HEAP_LOCAL_SEGMENT_INFO
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
Depth
Hint (15bit)
Lock (1bit)
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_INTERLOCK_SEQ
_HEAP_USERDATA_HEADER
LocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
Check Userblock](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-161-320.jpg)
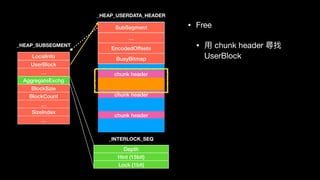
![Windows memory allocator
• LFH
• Allocate (RtlpLowFragHeapAllocFromContext)
• 取得 RtlpLowFragHeapRandomData[x] 上的直
• 下⼀一次會從 RtlpLowFragHeapRandomData[x+1] 取
• x 為 1 byte ,當下次輪輪回 x 則會 x = rand() %256 繼續取
• RtlpLowFragHeapRandomData 為⼀一個 random 256 byte 的陣列列
• 範圍為 0x0 - 0x7f](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-162-320.jpg)
![Windows memory allocator
• LFH
• Allocate (RtlpLowFragHeapAllocFromContext)
• 最獲得的 index 為
• RtlpLowFragHeapRandomData[x]*maxidx >> 7
• 如果 collision 則往後取最近的
• 檢查 (unused byte & 0x3f) !=0 (表⽰示 chunk 是 freed)
• 最後設置 index 及 unused byte 就返回給使⽤用者](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-163-320.jpg)
![….
….
….
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_HEAP_USERDATA_HEADER
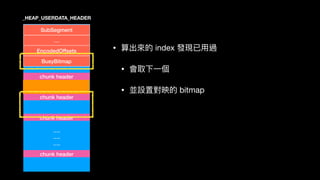
• Get an index
• RtlpLowFragHeapRandomData[x]*maxidx >> 7
• 檢查該 index 對映到的 bitmap 是否為 0
• 是 0 則返回對映的 bitmap
• 非 0 擇取最近的下⼀一個
chunk header](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-164-320.jpg)


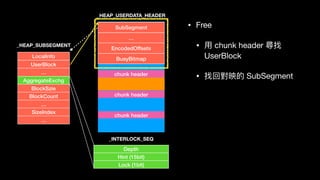
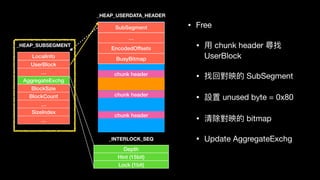
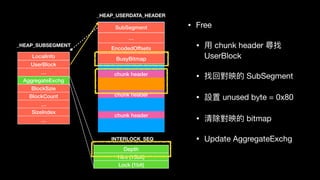
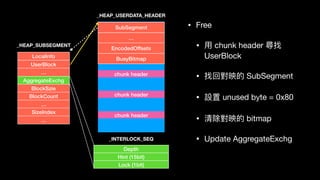
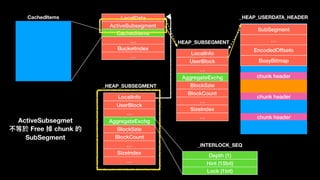
![LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
_HEAP_SUBSEGMENT
SubSegment
…
EncodedOffsets
BusyBitmap
chunk header
chunk header
chunk header
_HEAP_USERDATA_HEADERLocalData
ActiveSubsegment
CachedItems
…
BucketIndex
…
LocalInfo
UserBlock
…
AggregateExchg
BlockSzie
BlockCount
…
SizeIndex
…
_HEAP_SUBSEGMENT
Depth (1)
Hint (15bit)
Lock (1bit)
_INTERLOCK_SEQ
CachedItems
CachedItems[0]](https://image.slidesharecdn.com/winheap-190707030037/85/Windows-10-Nt-Heap-Exploitation-Chinese-version-174-320.jpg)