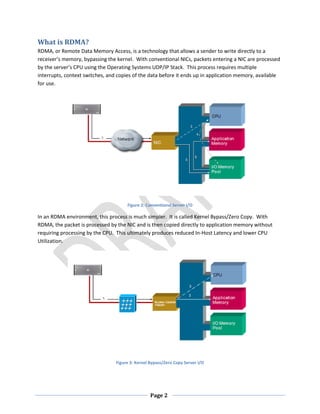
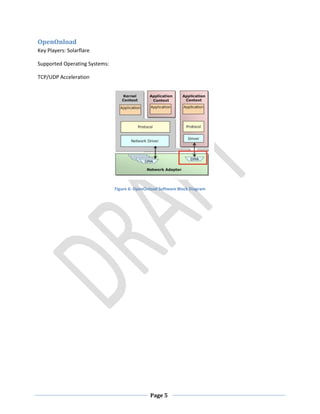
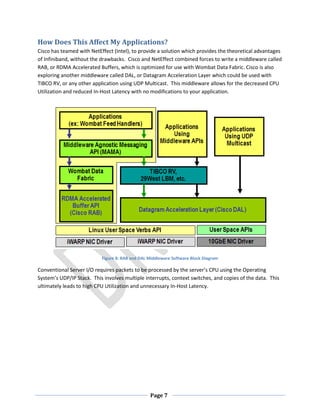
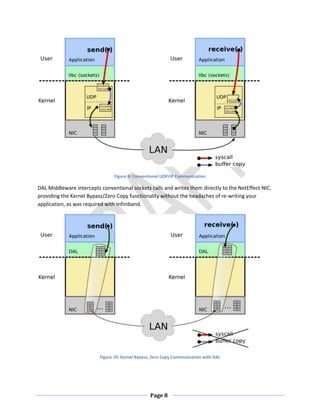
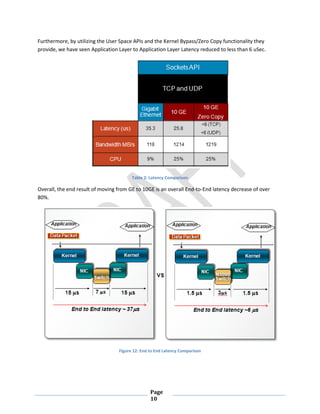
This document discusses the benefits of 10 Gigabit Ethernet (10GE) for reducing latency. It states that 10GE allows for lower CPU utilization and reduced latency within servers compared to Gigabit Ethernet. It also discusses that while Infiniband promised low latency, it required application rewrites and added complexity due to needing translation to Ethernet outside local networks. The document explores 10GE cabling options like SFP+ which provide the lowest latency, and network interface cards that support technologies like RDMA for further reducing latency within servers. With the right hardware and software, organizations can see over an 80% reduction in overall end-to-end latency by moving from Gigabit Ethernet to 10GE.











































![Beyond 100G and Low Power [Compatibility Mode]](https://cdn.slidesharecdn.com/ss_thumbnails/f02a80ef-2cfc-4b79-b226-1d2aa40e8896-150522201427-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)








