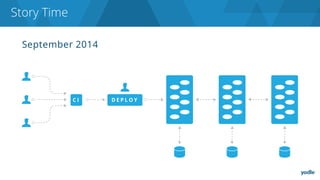
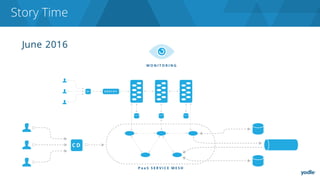
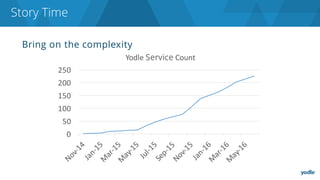
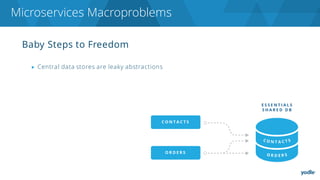
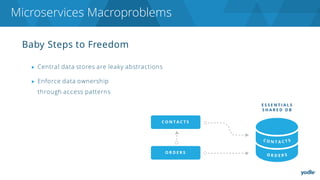
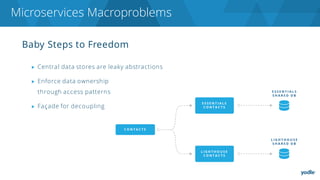
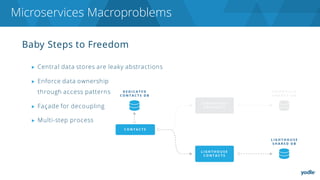
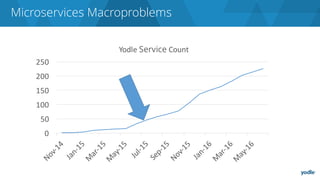
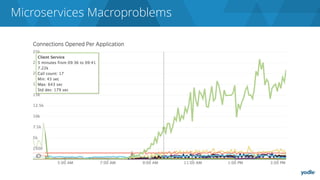
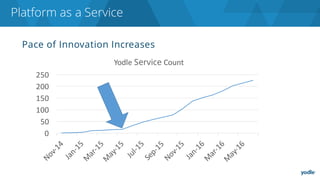
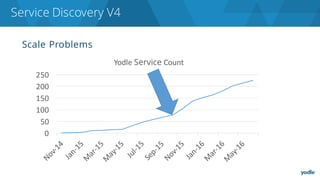
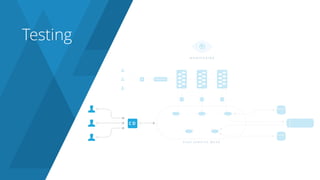
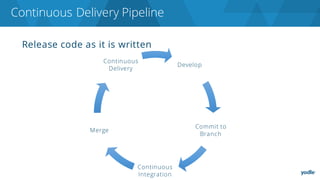
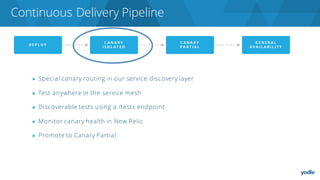
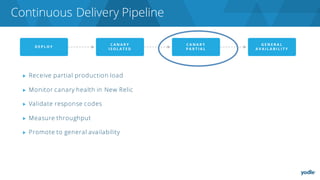
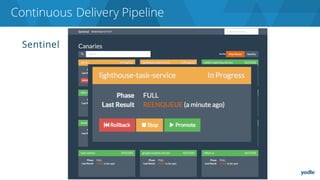
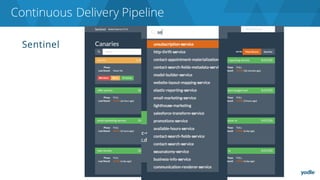
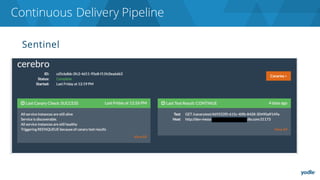
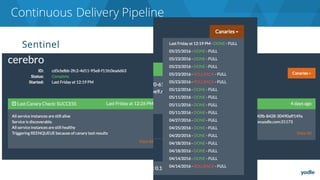
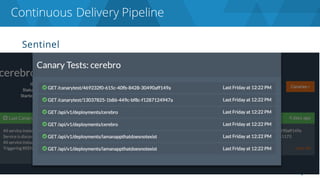
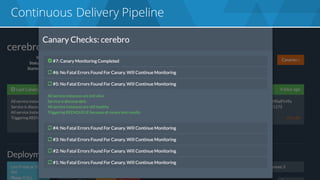
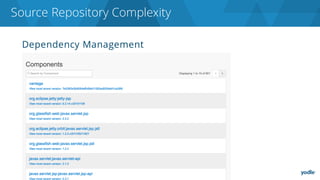
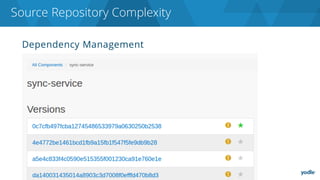
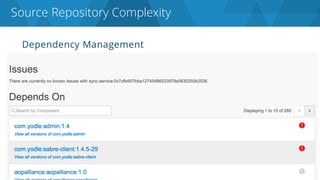
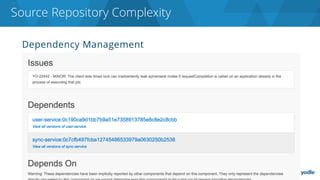
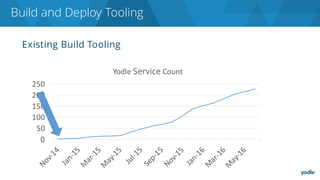
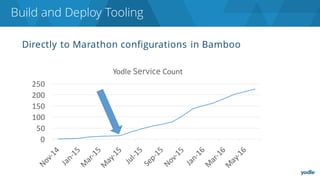
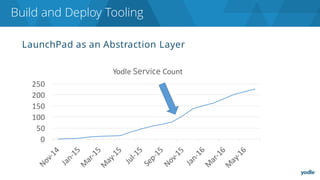
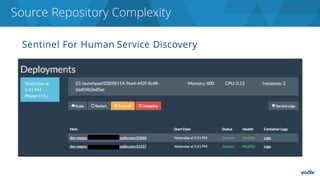
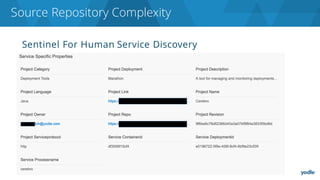
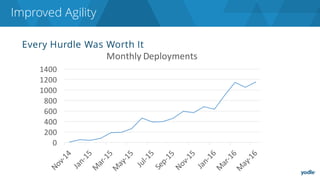
The document discusses the complexities and challenges associated with adopting microservices in business environments, highlighting the need for adaptation and process re-evaluation. It covers various aspects like data access patterns, service discovery, monitoring, and continuous delivery, emphasizing the gradual approach necessary for successful implementation. The narrative illustrates both the potential problems and benefits of microservices, ultimately advocating for careful planning and measurement of progress in a shifting technological landscape.