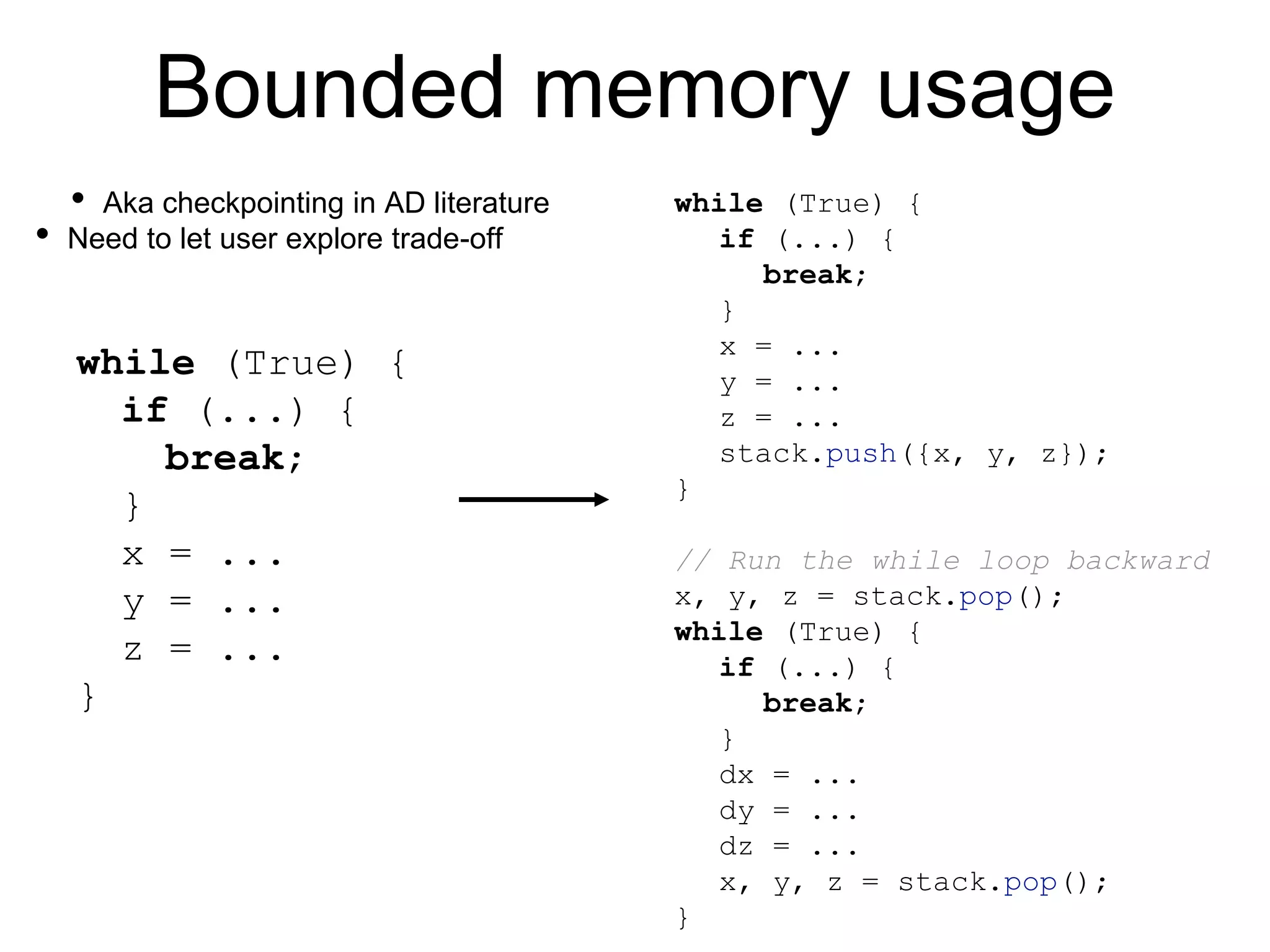
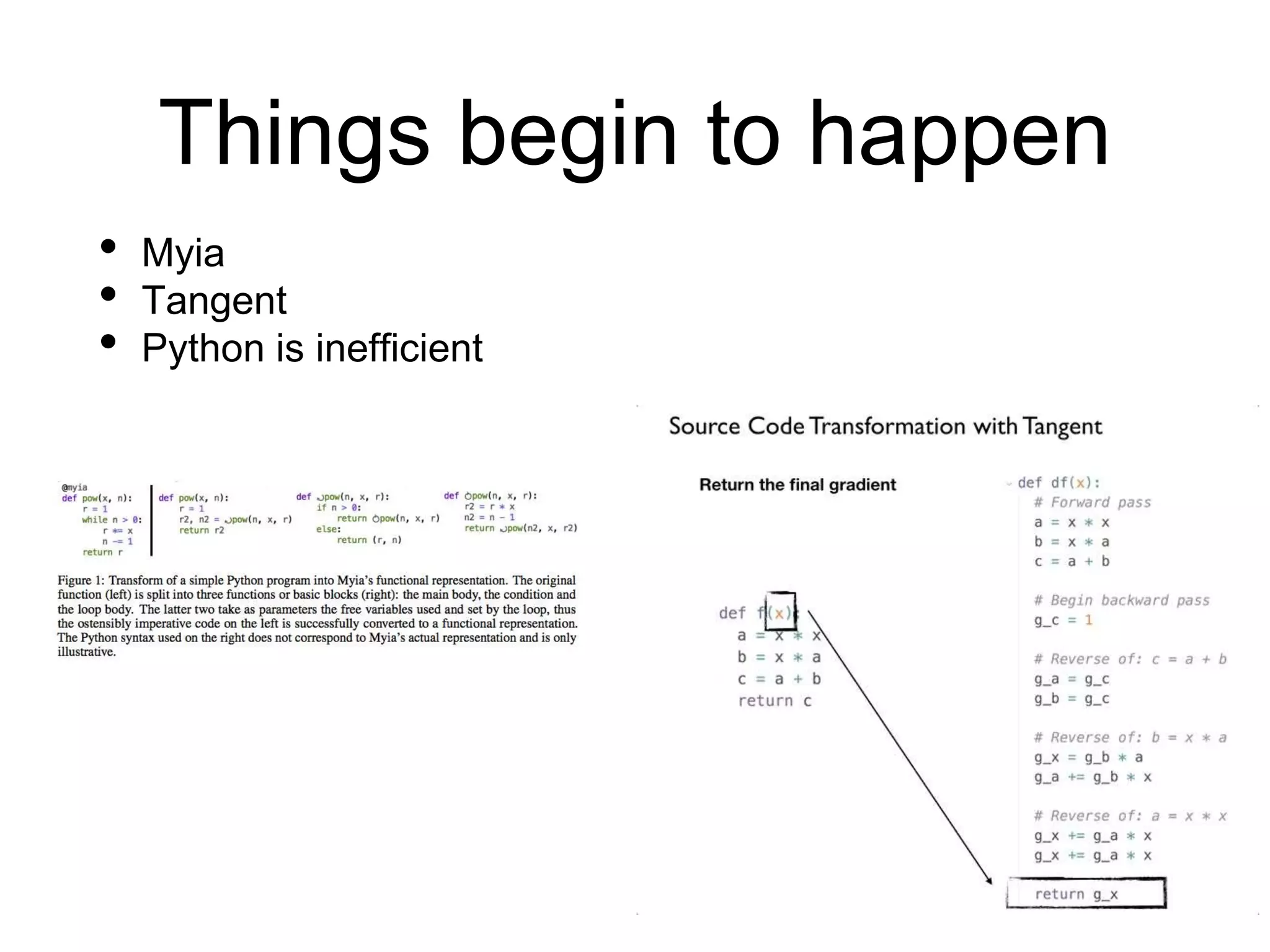
The document discusses the challenges of building an efficient automatic differentiation (autodiff) compiler. It outlines goals such as efficiency through detecting common expressions, constant folding at compile time, parallelism, bounded memory usage, and convenience without changing forward code. It also discusses handling non-differentiability, parallelism challenges, bounded memory usage through checkpointing, efficiently computing higher-order derivatives, and existing theories and implementations.