Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TS
Uploaded by
Tetsuya Sodo
PDF, PPTX
2,217 views
Elasticsearch勉強会#44 20210624
2021/6/24に行われたElasticsearch勉強会のスライドです。 7.3でGAとなったベクトルフィールドの機能とBERTを組み合わせて高精度な日本語類似検索を行う発表をしました。
Technology
◦
Related topics:
Deep Learning
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 35
2
/ 35
3
/ 35
4
/ 35
5
/ 35
6
/ 35
7
/ 35
8
/ 35
9
/ 35
10
/ 35
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
More Related Content
PDF
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
PPTX
MLOpsはバズワード
by
Tetsutaro Watanabe
PDF
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
PDF
推薦アルゴリズムの今までとこれから
by
cyberagent
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
Pythonによる黒魔術入門
by
大樹 小倉
PDF
イミュータブルデータモデル(世代編)
by
Yoshitaka Kawashima
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
MLOpsはバズワード
by
Tetsutaro Watanabe
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
推薦アルゴリズムの今までとこれから
by
cyberagent
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
Pythonによる黒魔術入門
by
大樹 小倉
イミュータブルデータモデル(世代編)
by
Yoshitaka Kawashima
What's hot
PDF
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
by
NTT DATA Technology & Innovation
PDF
オブジェクト指向できていますか?
by
Moriharu Ohzu
PDF
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
PPTX
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
PDF
Elasticsearchの機械学習機能を使ってみた
by
YuichiArisaka
PDF
Ml system in_python
by
yusuke shibui
PDF
Rustに触れて私のPythonはどう変わったか
by
ShunsukeNakamura17
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
「いい検索」を考える
by
Shuryo Uchida
PDF
イミュータブルデータモデルの極意
by
Yoshitaka Kawashima
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
例外設計における大罪
by
Takuto Wada
PDF
協調フィルタリング入門
by
hoxo_m
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PDF
効果のあるクリエイティブ広告の見つけ方(Contextual Bandit + TS or UCB)
by
Yusuke Kaneko
PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
PPTX
カルマンフィルタ入門
by
Yasunori Nihei
PDF
データサイエンティストのつくり方
by
Shohei Hido
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
by
NTT DATA Technology & Innovation
オブジェクト指向できていますか?
by
Moriharu Ohzu
ChatGPT 人間のフィードバックから強化学習した対話AI
by
Shota Imai
データ履歴管理のためのテンポラルデータモデルとReladomoの紹介 #jjug_ccc #ccc_g3
by
Hiroshi Ito
Elasticsearchの機械学習機能を使ってみた
by
YuichiArisaka
Ml system in_python
by
yusuke shibui
Rustに触れて私のPythonはどう変わったか
by
ShunsukeNakamura17
階層ベイズによるワンToワンマーケティング入門
by
shima o
最適輸送の計算アルゴリズムの研究動向
by
ohken
「いい検索」を考える
by
Shuryo Uchida
イミュータブルデータモデルの極意
by
Yoshitaka Kawashima
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
例外設計における大罪
by
Takuto Wada
協調フィルタリング入門
by
hoxo_m
backbone としての timm 入門
by
Takuji Tahara
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
効果のあるクリエイティブ広告の見つけ方(Contextual Bandit + TS or UCB)
by
Yusuke Kaneko
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
カルマンフィルタ入門
by
Yasunori Nihei
データサイエンティストのつくり方
by
Shohei Hido
Similar to Elasticsearch勉強会#44 20210624
PDF
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
PPTX
第45回elasticsearch勉強会 BERTモデルを利用した文書分類
by
shinhiguchi
PDF
BERT+XLNet+RoBERTa
by
禎晃 山崎
PDF
ChatGPTのデータソースにPostgreSQLを使う[詳細版](オープンデベロッパーズカンファレンス2023 発表資料)
by
NTT DATA Technology & Innovation
PDF
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
PPT
[FUNAI輪講] BERT
by
Takanori Ebihara
PDF
research.pdf
by
ssuserf94232
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
第45回elasticsearch勉強会 BERTモデルを利用した文書分類
by
shinhiguchi
BERT+XLNet+RoBERTa
by
禎晃 山崎
ChatGPTのデータソースにPostgreSQLを使う[詳細版](オープンデベロッパーズカンファレンス2023 発表資料)
by
NTT DATA Technology & Innovation
Elasticsearch入門 pyfes 201207
by
Jun Ohtani
[FUNAI輪講] BERT
by
Takanori Ebihara
research.pdf
by
ssuserf94232
More from Tetsuya Sodo
PDF
Elasticsearch勉強会#39 LT 20201217
by
Tetsuya Sodo
PDF
OCP Meetup Tokyo #05 ECK on OCP
by
Tetsuya Sodo
PDF
red-hat-forum-2017-openshift-baremetal-deployment
by
Tetsuya Sodo
PDF
OpenShift.RUN Summer 10 tetsuyasd
by
Tetsuya Sodo
PDF
JAZUG #26 AKS backup with Velero
by
Tetsuya Sodo
PPTX
MUGT01 - mesos.DCOS demo
by
Tetsuya Sodo
PPTX
MUGT02 - vamp demo
by
Tetsuya Sodo
PDF
Jeug 02 lt_tetsuyasodo_v01
by
Tetsuya Sodo
PDF
Jeug 01 lt_tetsuyasodo_v01
by
Tetsuya Sodo
PDF
Microsoft Open Tech Night #01 LT-tetsuyasd
by
Tetsuya Sodo
Elasticsearch勉強会#39 LT 20201217
by
Tetsuya Sodo
OCP Meetup Tokyo #05 ECK on OCP
by
Tetsuya Sodo
red-hat-forum-2017-openshift-baremetal-deployment
by
Tetsuya Sodo
OpenShift.RUN Summer 10 tetsuyasd
by
Tetsuya Sodo
JAZUG #26 AKS backup with Velero
by
Tetsuya Sodo
MUGT01 - mesos.DCOS demo
by
Tetsuya Sodo
MUGT02 - vamp demo
by
Tetsuya Sodo
Jeug 02 lt_tetsuyasodo_v01
by
Tetsuya Sodo
Jeug 01 lt_tetsuyasodo_v01
by
Tetsuya Sodo
Microsoft Open Tech Night #01 LT-tetsuyasd
by
Tetsuya Sodo
Elasticsearch勉強会#44 20210624
1.
ElasticsearchのベクトルフィールドとBERTを 用いた日本語テキスト類似検索の機能検証 @tetsuyasd 2021/06/24 Elasticsearch勉強会 #44 #elasticsearchjp
2.
Who am I
? 2 名前: 惣道 哲也 (そうどう てつや) Twitter: @tetsuyasd 所属: 日本マイクロソフト株式会社 クラウドアーキテクト事業本部 職務: Microsoft Azure導入支援にまつわるいろいろ(調査、検証、提案) 技術: Cloud / Container / Data Analytics / etc… #elasticsearchjp
3.
本日のセッションの背景・概要・動機 ■背景: Elasticsearch 7.3で高次元ベクトル向けフィールドタイプがGAになった –
これまでのインデックスを用いたドキュメント検索とは異なる仕組み – Elasticsearchの高速な検索機能に加えて、高精度な自然言語処理タスクを組み合わせることも可能に ■概要: テキスト埋め込み技術として注目を集めたBERTを題材として、Elasticsearchのベクトル フィールドと組み合わせた日本語テキスト類似検索に関する情報整理と動作検証を行う – BERTの簡単な概要 – Elasticsearchのベクトルフィールドの概要とそれを利用した検索の仕組み – デモ(先人のデモをなぞる程度です) ■動機: BERTについて聞いたことあったがきちんと調べたことがなかったのでこの機会に・・・ –デモで動かすことでより深く理解できるかもという期待 –自然言語処理系の検索技術のキャッチアップと今後の技術展望の理解 3 #elasticsearchjp
4.
Agenda ■自然言語処理とBERTの登場 – 従来のアプローチ – BERTのアプローチ ■Elasticsearchのベクトルフィールドの機能
(7.3 GA) – できること – できないこと ■日本語コーパスを用いた類似検索検証 – 概要 – 手順紹介・デモ ■まとめ 4 #elasticsearchjp
5.
ある日ブログに興味深い機能の紹介が 5 #elasticsearchjp 便利そうな感じ・・・
6.
読み進めること3分後・・・ 6 #elasticsearchjp わ、わからん・・・
7.
コサイン類似度 → 何となくわかる ■2つのベクトルの「類似度(≒近さ)」を表現する1手法 –
ベクトルα、βが角度θを持つとき – 全く同一方向の場合 cosθ=cos0°=1 – 垂直方向の場合 cosθ=cos90°=0 – 逆方向の場合 cosθ=cos180°=-1 7 #elasticsearchjp a α(x1,y1,z1) β(x2,y2,z2) θ cosθ = |α|・|β| α・β → → → → → → コサイン類似度の計算方法 ※ベクトル長は1に正規化されるケースが多い その場合、cosθは2ベクトルの内積として求められる つまり -1~1 の間の値を持ち、 「類似度」が高いほど1に近い値になる
8.
Word2Vec → 何となくわかる 単語の意味付けをベクトル化で行うという手法が2013年にGoogleにより提案されていた。 ただし、これだと単語の文字の構成有無のみで判断してしまい、文脈を考慮することができないため、 文章全体をベクトル化する手法が2018年ごろに複数提案されることに。 8 #elasticsearchjp (引用:
https://cvml-expertguide.net/2020/07/01/word2vec/) a King Queen 各単語のベクトル空間 (実際には多次元) Men Women King – Men + Women = Queen
9.
BERTとは? 単語の数や種類だけでなく文脈も考慮して、各単語の登場位置による意味の違いも識別しようとする – W2Vだと単語が現れる順序は考慮されない(例: “turn
in” と “in turn”の違い) – W2Vだと同形異義語(例:interest → 興味 or 利子)を区別できない – BERTでは文章全体の文脈も考慮してベクトル化することが可能 – 2018年にGoogleにより提唱され、検索エンジンなどに搭載されて精度が大幅に向上した 要は自然言語の文章を入力として、全体を見てうまく特徴をあらわすいい感じの多次元ベクトル (通常100~数100次元)を出力するもの、と理解 – ここで次元数は固定となる点に注意 – 以前にもあったBag-of-Wordでは単語の種類数に応じて次元が大きくなり、かつ、疎(sparse)なベクトルだった #elasticsearchjp a
10.
BERTの高い汎用性(適用範囲の広さ) 2段階の学習により、従来手法にはない高い汎用性を獲得 (1) 膨大なコーパス(Wikipedia全文等)でベースとなるモデルを学習(pre-training) (2) 応用したい領域の文脈に合わせた(ライトな)追加学習(fine
tuning) #elasticsearchjp ベースモデル 教師なし学習 コーパス (ex. Wikipedia) 追加学習済モデル① 追加学習済モデル② 追加学習済モデル③ 追加学習① 追加学習② 追加学習③ ①SQuAD:質問応答 テキストが与えられ、その内容を含んだ 質問に適切に回答する ②SST-2:レビューのネガポジ判定 映画レビューのテキスト内容に対して ネガポジ判定を行う ③SWAG:後続文判定 与えれた文章に後続する文を4つの候補 から1つ選択する (1) Pre-trainフェーズ (2) Fine tuningフェーズ 膨大な計算量 軽微な計算量 【以下は応用例】
11.
BERTの何が革新的なのか: 高い汎用性と高い精度 BERT以後、いろいろな応用が開発され、タスクに よっては人間の性能を超えるものがでてきた。 これまでAI/DLが比較的得意と言われていた画像、 音声分野だけでなく、自然言語処理分野でも多くの ブレイクスルーが起こってきている。 – BERTのベースモデルを土台に、10数種類の応用タスク のための再学習(fine
tuning)を行うことで従来の最高性 能(SOTA)を超える性能が得られた – ComputerVisionではImageNetで事前学習したVGGや ResNetがあるが、今回BERTによって自然言語でも同じ ようなポジションのモデルが作られたことを意味する 11 #elasticsearchjp (引用: https://twitter.com/_Ryobot/status/1050925881894400000)
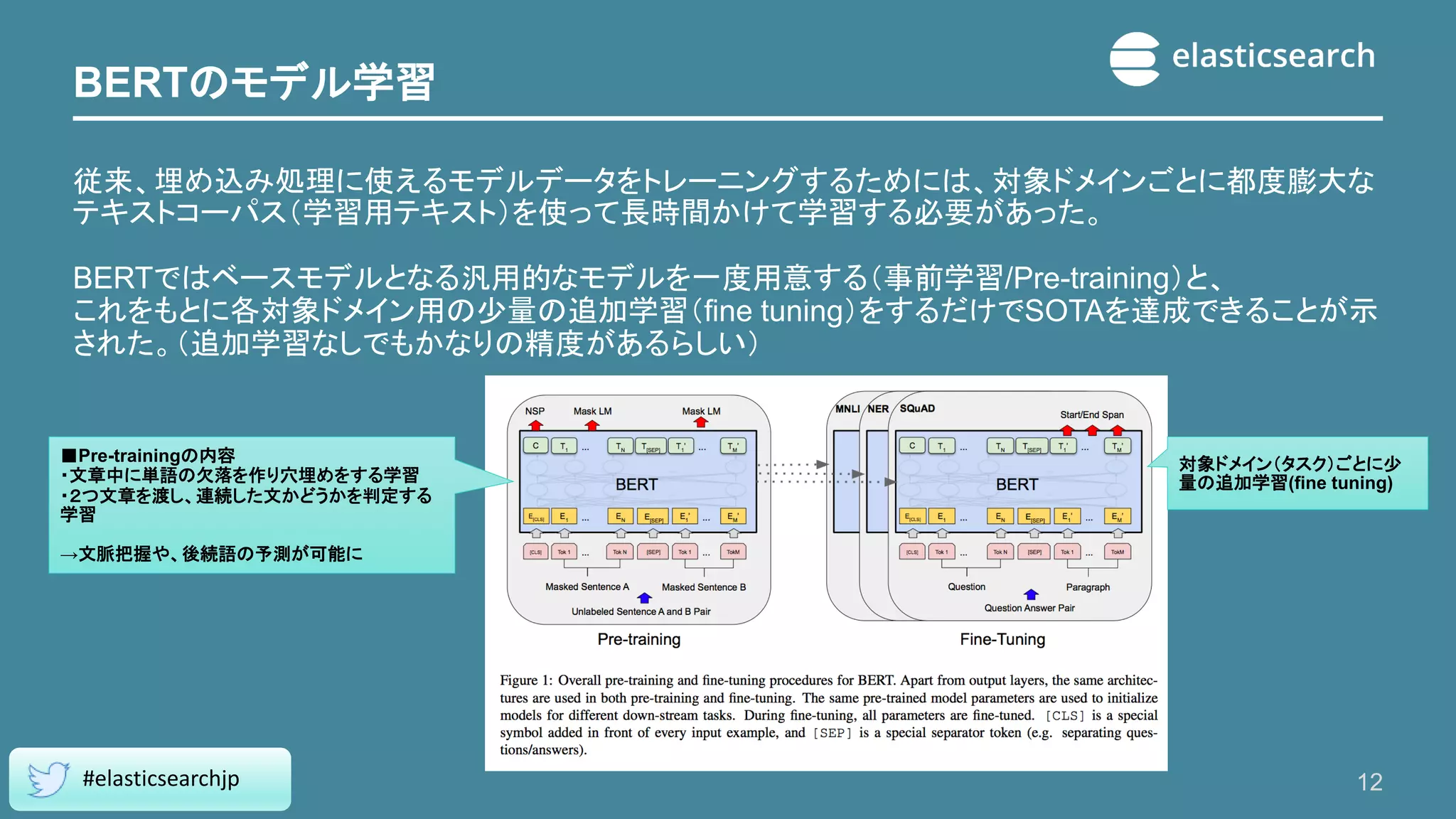
12.
BERTのモデル学習 従来、埋め込み処理に使えるモデルデータをトレーニングするためには、対象ドメインごとに都度膨大な テキストコーパス(学習用テキスト)を使って長時間かけて学習する必要があった。 BERTではベースモデルとなる汎用的なモデルを一度用意する(事前学習/Pre-training)と、 これをもとに各対象ドメイン用の少量の追加学習(fine tuning)をするだけでSOTAを達成できることが示 された。(追加学習なしでもかなりの精度があるらしい) 12 #elasticsearchjp ■Pre-trainingの内容 ・文章中に単語の欠落を作り穴埋めをする学習 ・2つ文章を渡し、連続した文かどうかを判定する 学習 →文脈把握や、後続語の予測が可能に 対象ドメイン(タスク)ごとに少 量の追加学習(fine tuning)
13.
BERTのベクトル化のイメージ – 入力例① – “東京ディズニーシーの人気アトラクション「センター・オブ・ジ・アース」の世界を映画化した第2弾 『センター・オブ・ジ・アース・・・” –
出力例① – [-0.9192637205123901, -0.07473928481340408, 0.08322068303823471, … -0.43304893374443054, 0.6378014087677002, 0.04336249455809593] – 入力例② – “”『24 -TWENTYFOUR-』が終了してから2年、ジャック・バウワー役のキーファー・サザーランドが 主演を務める最新海外ドラマ『TOUCH/タッチ』が10・・・” – 出力例② – [-0.8536872863769531, -0.048283740878105164, -0.008795815519988537,… -0.3717033565044403, -0.522616982460022, -0.10493569076061249] 13 #elasticsearchjp このベクトル同士のコサイン 類似度が大きければ 似た文章と考えられる ここでのBERTの入力は自然言語テキスト、出力は固定長多次元ベクトル(100~数100次元が一般的)となる。 このとき「モデルの精度が高い」と、入力した文章に対してより適切なベクトルを出力できて、さまざまな応用タ スクで高精度な識別が可能になる。
14.
Elasticsearchのベクトルフィールドとは BERTに限らず、ベクトル表現が抽出できるものであれば同様の「コサイン類似度」計算が利用できる Elasticsearchではバージョン7.3からこのベクトル表現を格納するためのフィールドがGAになった 14 #elasticsearchjp ■できること – 最大2048次元のベクトルフィールドを格納 – 格納したベクトルは、スクリプトフィールドにビルトイン関 数(vector
functions)を適用することで類似度の高いド キュメントを検索可能 – コサイン類似度やベクトル内積などが計算可能 ■できないこと – ドキュメントからBERTのようなベクトル表現抽出はでき ない – このため、Elasticsearchの外でBERTサーバを起動するなど の構成が必要
15.
今回やりたいこと 以下のブログで今回やりたいことに非常に近い実装をされていたため、大いに参考にさせて頂きました (ありがとうございます!!) – ElasticsearchとBERTを組み合わせて類似文書検索 https://hironsan.hatenablog.com/entry/elasticsearch-meets-bert – ベースモデルをもとにしたBERTサーバ(ベクトル生成API)をコンテナで起動(今回はfine
tuningは行わない) – 登録したいテキストとBERTサーバで生成したベクトルをセットにしてESにインデックス登録 – クエリとして自然言語を入力すると、類似したテキストをスコア順に提示する仕組みを作る – 上記ブログでは英語を扱っていたので、今回日本語コーパスを登録して日本語検索を試してみた 15 #elasticsearchjp
16.
今回やりたいこと ■BERTクライアントからBERTサーバにベクトル変換をさせるコード例(下図赤枠内②③の動作) 16 #elasticsearchjp $ python3 Python 3.8.5
(default, May 27 2021, 13:30:53) [GCC 9.3.0] on linux >>> from bert_serving.client import BertClient >>> bc = BertClient(ip='bart01', output_fmt='list’) >>> vector = bc.encode(["テストの文章です"]) >>> vector [[-0.6728561520576477, -0.20123611390590668, 0.13580602407455444, 0.5271162986755371, 0.04913650453090668, -0.14195780456066132, 0.0345018170773983, 0.1410500407218933, … , 0.3903881907463074, -0.21575897932052612]] >>> len(vector) 1 >>> len(vector[0]) 768 >>>
17.
今回やりたいこと ■取得したベクトルを元にElasticsearchに類似検索させるコード例(下図赤枠内④⑤の動作) 17 #elasticsearchjp client = Elasticsearch('elasticsearch:9200') query_vector
= bc.encode([query])[0] script_query = { "script_score": { "query": {"match_all": {}}, "script": { "source": "cosineSimilarity(params.query_vector, doc['text_vector']) + 1.0", "params": {"query_vector": query_vector} } } } response = client.search( index=INDEX_NAME, body={ "query": script_query, "_source": {"includes": ["title", "text"]} } )
18.
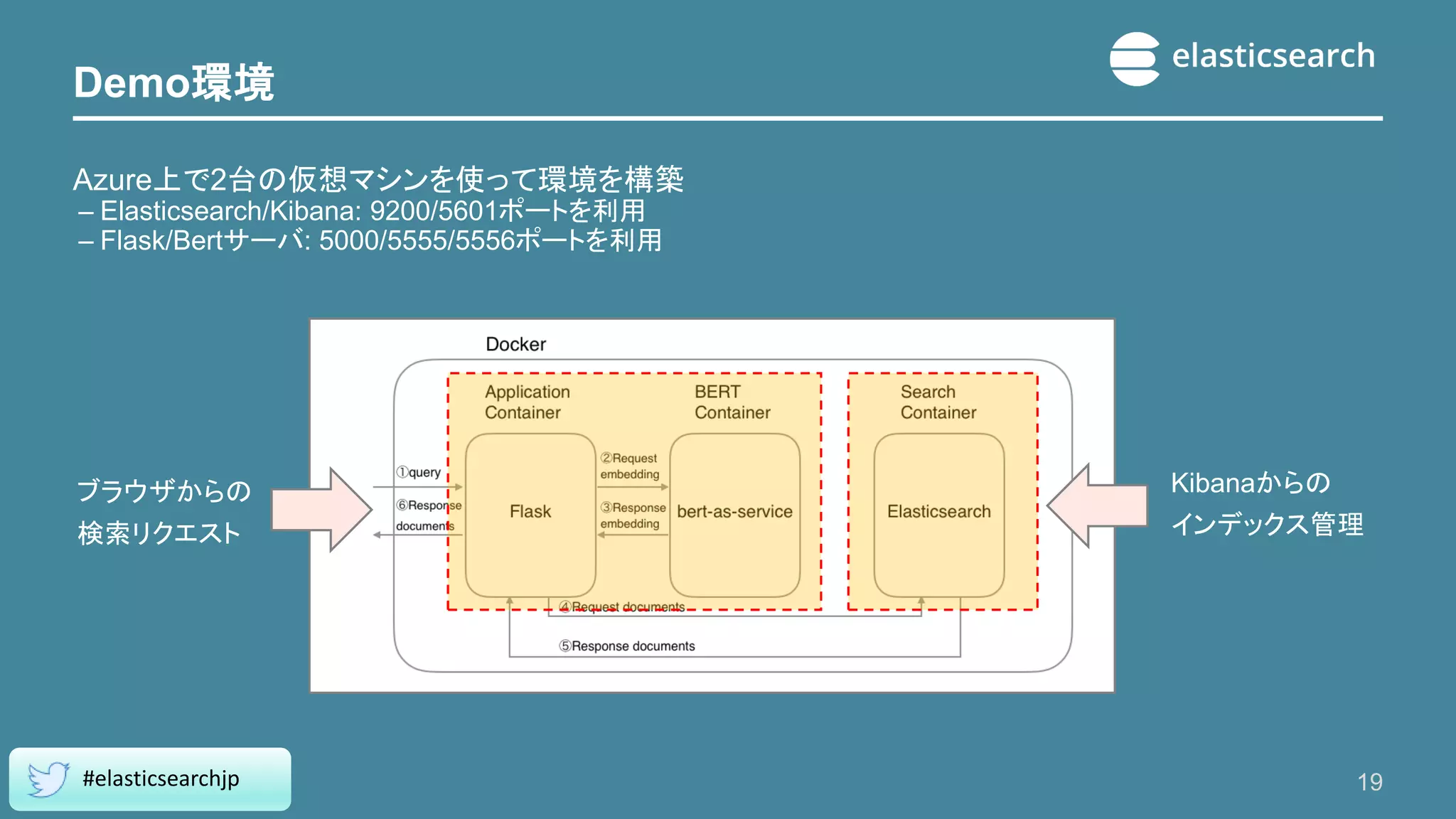
検証手順(概要) ■Elasicsearch/Kibanaの起動 – ES/Kibanaを起動しておく ■BERTサーバの起動 – BERTのモデルファイルをダウンロードしておく –
BERTサーバのコンテナイメージを起動する(引数にモデルファイルを指定) ■事前ドキュメント格納 – Livedoorニュースコーパス(Rondhuitさん公開 *1)をダウンロードする – スクリプトを使ってCSVフォーマットに変換する – Elasticsearchにindexを作っておく(vectorフィールドを持つmappingを定義する) – スクリプトを使ってBERT変換およびESへのbulkインサートをする ■Flask(Webアプリ)コンテナのbuildおよび起動 – Webアプリコンテナをbuildする – Webアプリコンテナを起動 18 #elasticsearchjp (*1) https://www.rondhuit.com/download.html 各記事ファイルにはクリエイティブ・コモンズライセンス「表示-改変禁止」が適用されます。詳細は上記URLの記載を参照ください。 livedoor はNHN Japan株式会社の登録商標です。livedoorニュースコーパスは、NHN Japan株式会社が運営する「livedoor ニュース」 のうち、クリエイティブ・コモンズライセンスが適用されるニュース記事を収集し、可能な限りHTMLタグを取り除いて作成したものです。
19.
Demo環境 Azure上で2台の仮想マシンを使って環境を構築 – Elasticsearch/Kibana: 9200/5601ポートを利用 –
Flask/Bertサーバ: 5000/5555/5556ポートを利用 19 #elasticsearchjp ブラウザからの 検索リクエスト Kibanaからの インデックス管理
20.
利用イメージ 20 #elasticsearchjp 日本語で文章を入力すると、BERT サーバにリクエストが投げられ、ベクト ル表現(リスト)が返される これを入力としてElasticsearchにコサ イン類似度検索を実行し、スコア順に 結果を表示する 登録ドキュメントはLivedoorニュース コーパス(7367ドキュメント)
21.
未検証事項 – 日本語固有のさまざまな精度改善 – (例)大規模コーパスやカスタムトークナイザーを利用した精度改善 –おそらくデフォルトでは自動で裏でトークン化しているようだが、ESのtokenizerとの連携やmecab/sudachiなどとの連 携もできそう –
タスクに応じたfine tuning(再学習)の検証 –扱う文章のドメインに合わせたfine tuningによりモデルがより高精度になる可能性が考えられる –(例)既存特許の類似検索→過去の公開特許情報を使ってfine tuningを行うなど。。 – スケーラビリティの改善 –BERTサーバの性能がボトルネックになった場合のスケールアウトアーキテクチャの検討 –今回はコンテナで起動しているが、同一コンテナをスケールアウトするなどの工夫ができそう 21 #elasticsearchjp
22.
この機能を用いた応用 – 類似文章検索(いわゆるgoogle検索をキーワードでなく自然言語で行うイメージ) – チャットボットの精度向上 –
社内、自治体などにおけるQ&A/FAQの自動応答 – 高度な質問応答(文章を与えて内容に関する質問に回答する) – 自然言語で要求・要件を記述してプログラムを自動生成する(次ページ) 画像もVisual Transformerという新しい技術を使うことでベクトル化でき、従来のCNNなどの手法より精 度が高いと言われている ESにテキストと画像を入れて、どちらでも類似検索できると活用範囲が広がる 22 #elasticsearchjp
23.
BERTの先にあるもの(現在進行形) – BERTのパラメータ(ニューラルネットワークを構成する要素)数:3億4000万 – GPT-3のパラメータ数:1750億 23 #elasticsearchjp
https://www.publickey1.jp/blog/21/aipower_appsaigpt-3microsoft_build_2021.html Microsoft Build 2021で紹介されたPower Fxのデモ OpenAIが開発したNLPモデル「GPT-3」を採用し、自然言語で 与えられた文章をもとにPower Fxで動作するコードに自動変換する
24.
まとめ 24 2018年以降のBERTをはじめとした自然言語処理分野の技術進歩により、「文章」の特徴を 高精度でベクトル表現できるようになりました。 Elasticsearchでもベクトルを扱えるようになり、Elasticsearchの特徴を生かしたさまざまユースケースが 今後あらわれることが期待できます。 今回BERTをあらためて勉強し直して理解も深まりました。 ブログに書いてある内容が わかるようになった! ぜひみなさんもご一読ください 新しい応用のヒントが見つかる かもしれません
25.
参考URL 25 – ベクトルフィールドを使ったテキスト類似性検索 https://www.elastic.co/jp/blog/text-similarity-search-with-vectors-in-elasticsearch – Dense
Vector field type(7.13) https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html – ElasticsearchとBERTを組み合わせて類似文書検索 https://hironsan.hatenablog.com/entry/elasticsearch-meets-bert – Elasticsearchで分散表現を使った類似文書検索 https://yag-ays.github.io/project/elasticsearch-similarity-search/ – livedoorニュースコーパスをcsvファイル形式で取得する https://nxdataka.netlify.app/ldncsv/ – 汎用言語表現モデルBERTを日本語で動かす(PyTorch) https://qiita.com/Kosuke-Szk/items/4b74b5cce84f423b7125 – NICT BERT日本語Pre-trainedモデル https://alaginrc.nict.go.jp/nict-bert/index.html – BERT以降の事前学習済みモデルのトレンドと主要モデルを紹介!Part1学習方法編 https://elyza-inc.hatenablog.com/entry/2021/03/25/160727 – [速報]マイクロソフト、自然言語をプログラミング言語にAIで変換、新ノーコード機能をPower Appsに搭載。 AI言語モデル「GPT-3」を採用。Microsoft Build 2021 https://www.publickey1.jp/blog/21/aipower_appsaigpt-3microsoft_build_2021.html
26.
ご清聴ありがとうございました
27.
27 本資料に関するお問い合わせ 27 @tetsuyasd Mailto: tetsuya.sodo@gmail.com 本資料で記載されているロゴ、システム名、製品名は各社及び商標権者の登録商標あるいは商標です。 本発表内容に関して、ご質問等があればお問い合わせ下さい。 また、内容に関しては個人の意見に基づくものであり、所属組織団体の公式見解とは異なる場合がございます点、ご了承 下さい。
28.
Appendix: 検証手順の詳細
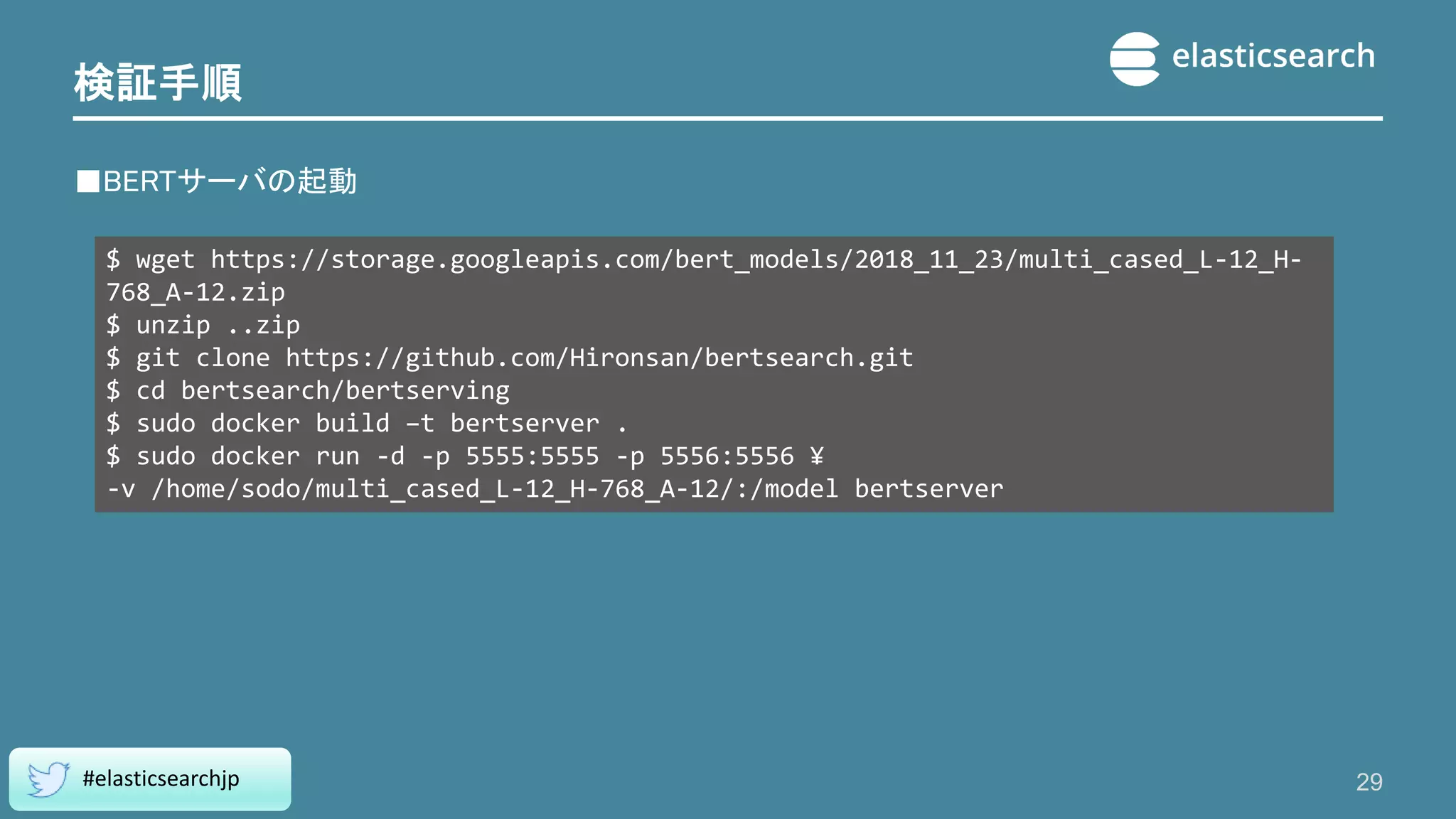
29.
検証手順 ■BERTサーバの起動 29 #elasticsearchjp $ wget https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H- 768_A-12.zip $
unzip ..zip $ git clone https://github.com/Hironsan/bertsearch.git $ cd bertsearch/bertserving $ sudo docker build –t bertserver . $ sudo docker run -d -p 5555:5555 -p 5556:5556 ¥ -v /home/sodo/multi_cased_L-12_H-768_A-12/:/model bertserver
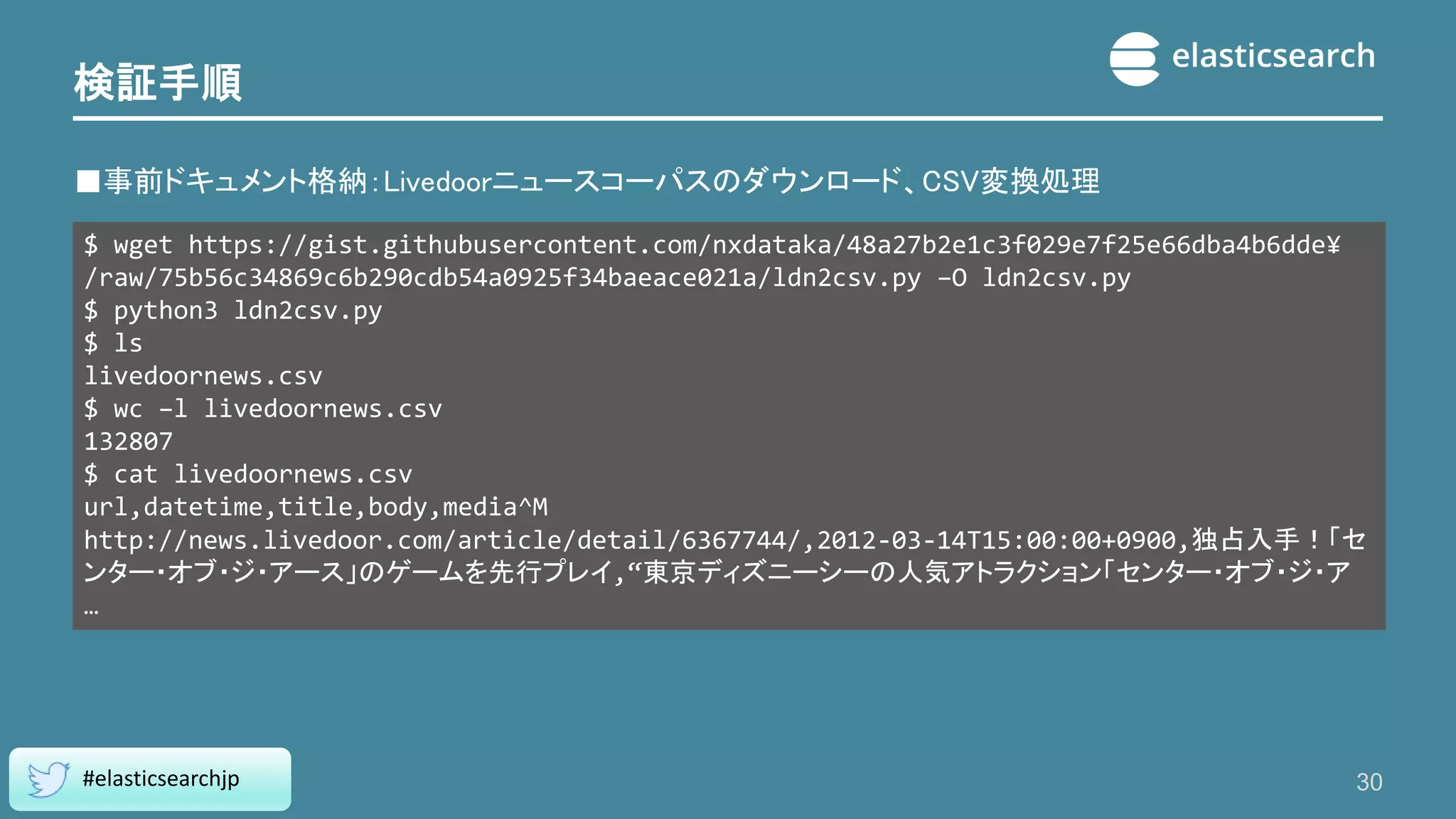
30.
検証手順 ■事前ドキュメント格納:Livedoorニュースコーパスのダウンロード、CSV変換処理 30 #elasticsearchjp $ wget https://gist.githubusercontent.com/nxdataka/48a27b2e1c3f029e7f25e66dba4b6dde¥ /raw/75b56c34869c6b290cdb54a0925f34baeace021a/ldn2csv.py
–O ldn2csv.py $ python3 ldn2csv.py $ ls livedoornews.csv $ wc –l livedoornews.csv 132807 $ cat livedoornews.csv url,datetime,title,body,media^M http://news.livedoor.com/article/detail/6367744/,2012-03-14T15:00:00+0900,独占入手!「セ ンター・オブ・ジ・アース」のゲームを先行プレイ,“東京ディズニーシーの人気アトラクション「センター・オブ・ジ・ア …
31.
検証手順 ■事前ドキュメント格納: CSVファイルを元にBERTサーバにテキストを投げて変換し、JSONに整形① 31 #elasticsearchjp $ cd
bertsearch $ vi example/create_documents.py … doc = { ‘title’: series.Title, ## Title -> title に修正する ‘text’: series.Description ## Description -> body に修正する } … # with open(args.save, ‘w’) as f: ## 赤字部分をコメントアウトし、次の2行に入れ替える import codecs with codecs.open(args.save, 'w', 'utf-8') as f: … # f.write(json.dumps(d) + ‘¥n’) ## 赤字部分をコメントアウトし、次の2行に入れ替える json.dump(d, f, ensure_ascii=False) f.write('¥n’) …
32.
検証手順 ■事前ドキュメント格納: CSVファイルを元にBERTサーバにテキストを投げて変換し、JSONに整形② 32 #elasticsearchjp $ cd
bertsearch $ python3 example/create_documents.py --data=../livedoornews.csv ¥ --index_name=testindex (この処理は時間がかかります) $ wc -l documents.jsonl 7367 $ cat documents.jsonl {"_op_type": "index", "_index": "testindex", "text": "東京ディズニーシーの人気アトラクション 「センター・オブ・ジ・アース」の世界を映画化した第2弾『センター・オブ・ジ・アー… ", "title": "独占入手! 「センター・オブ・ジ・アース」のゲームを先行プレイ", "text_vector": [-0.9192637205123901, - 0.07473928481340408, 0.08322068303823471, -0.10188467800617218, -0.43304893374443054, …, 0.6378014087677002, 0.04336249455809593]} {"_op_type": "index", "_index": "testindex", "text": "『24 -TWENTYFOUR-』が終了してから2年、 ジャック・バウワー役のキーファー・サザーランドが主演を務める最新海外ドラマ『TOUCH/タッチ』が10…
33.
検証手順 ■事前ドキュメント格納: Elasticsearchに格納用インデックスを作成 33 #elasticsearchjp PUT testindex { "mappings":
{ "properties": { "title": { "type": "text" }, "text": { "type": "text" }, "text_vector": { "type": "dense_vector", "dims": 768 } } } } ■今回のキモ 取得したBERTモデルに合わせて 768次元格納できるフィールドを 定義している
34.
検証手順 ■事前ドキュメント格納: JSONファイルをElasticsearchに投げてbulkインサート 34 #elasticsearchjp $ python3
example/index_documents.py --data=../livedoornews.csv GET _cat/indices/testindex?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open testindex ibQE3yDjQ7CR8raxvVIRjQ 1 1 7367 0 134mb 134mb Kibanaからインデックスの確認
35.
検証手順 ■Flask(Webアプリ)コンテナのbuildおよび起動 35 #elasticsearchjp $ vi web/app.py … @app.route('/search') def
analyzer(): #bc = BertClient(ip=‘bertserving’, output_fmt=‘list’) ## 赤字2行をコメントアウト、入替え #client = Elasticsearch('elasticsearch:9200’) bc = BertClient(ip=‘bart01’, output_fmt=‘list’) ## BERTサーバのホスト/IPに書換え client = Elasticsearch(‘esweb01:9200’) ## Elasticsearchのホスト/IP $ sudo docker build –t web . $ sudo docker run -d -p 5000:5000 –e INDEX_NAME=testindex web
Download











![BERTのベクトル化のイメージ
– 入力例①
– “東京ディズニーシーの人気アトラクション「センター・オブ・ジ・アース」の世界を映画化した第2弾
『センター・オブ・ジ・アース・・・”
– 出力例①
– [-0.9192637205123901, -0.07473928481340408, 0.08322068303823471, …
-0.43304893374443054, 0.6378014087677002, 0.04336249455809593]
– 入力例②
– “”『24 -TWENTYFOUR-』が終了してから2年、ジャック・バウワー役のキーファー・サザーランドが
主演を務める最新海外ドラマ『TOUCH/タッチ』が10・・・”
– 出力例②
– [-0.8536872863769531, -0.048283740878105164, -0.008795815519988537,…
-0.3717033565044403, -0.522616982460022, -0.10493569076061249]
13
#elasticsearchjp
このベクトル同士のコサイン
類似度が大きければ
似た文章と考えられる
ここでのBERTの入力は自然言語テキスト、出力は固定長多次元ベクトル(100~数100次元が一般的)となる。
このとき「モデルの精度が高い」と、入力した文章に対してより適切なベクトルを出力できて、さまざまな応用タ
スクで高精度な識別が可能になる。](https://image.slidesharecdn.com/esug-20210624tetsuyasodo-210624115320/75/Elasticsearch-44-20210624-13-2048.jpg)


![今回やりたいこと
■BERTクライアントからBERTサーバにベクトル変換をさせるコード例(下図赤枠内②③の動作)
16
#elasticsearchjp
$ python3
Python 3.8.5 (default, May 27 2021, 13:30:53) [GCC 9.3.0] on linux
>>> from bert_serving.client import BertClient
>>> bc = BertClient(ip='bart01', output_fmt='list’)
>>> vector = bc.encode(["テストの文章です"])
>>> vector
[[-0.6728561520576477, -0.20123611390590668, 0.13580602407455444, 0.5271162986755371,
0.04913650453090668, -0.14195780456066132, 0.0345018170773983, 0.1410500407218933,
…
, 0.3903881907463074, -0.21575897932052612]]
>>> len(vector)
1
>>> len(vector[0])
768
>>>](https://image.slidesharecdn.com/esug-20210624tetsuyasodo-210624115320/75/Elasticsearch-44-20210624-16-2048.jpg)
![今回やりたいこと
■取得したベクトルを元にElasticsearchに類似検索させるコード例(下図赤枠内④⑤の動作)
17
#elasticsearchjp
client = Elasticsearch('elasticsearch:9200')
query_vector = bc.encode([query])[0]
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, doc['text_vector']) + 1.0",
"params": {"query_vector": query_vector}
}
}
}
response = client.search(
index=INDEX_NAME,
body={
"query": script_query,
"_source": {"includes": ["title", "text"]}
}
)](https://image.slidesharecdn.com/esug-20210624tetsuyasodo-210624115320/75/Elasticsearch-44-20210624-17-2048.jpg)






![参考URL
25
– ベクトルフィールドを使ったテキスト類似性検索
https://www.elastic.co/jp/blog/text-similarity-search-with-vectors-in-elasticsearch
– Dense Vector field type(7.13)
https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html
– ElasticsearchとBERTを組み合わせて類似文書検索
https://hironsan.hatenablog.com/entry/elasticsearch-meets-bert
– Elasticsearchで分散表現を使った類似文書検索
https://yag-ays.github.io/project/elasticsearch-similarity-search/
– livedoorニュースコーパスをcsvファイル形式で取得する
https://nxdataka.netlify.app/ldncsv/
– 汎用言語表現モデルBERTを日本語で動かす(PyTorch)
https://qiita.com/Kosuke-Szk/items/4b74b5cce84f423b7125
– NICT BERT日本語Pre-trainedモデル
https://alaginrc.nict.go.jp/nict-bert/index.html
– BERT以降の事前学習済みモデルのトレンドと主要モデルを紹介!Part1学習方法編
https://elyza-inc.hatenablog.com/entry/2021/03/25/160727
– [速報]マイクロソフト、自然言語をプログラミング言語にAIで変換、新ノーコード機能をPower Appsに搭載。
AI言語モデル「GPT-3」を採用。Microsoft Build 2021
https://www.publickey1.jp/blog/21/aipower_appsaigpt-3microsoft_build_2021.html](https://image.slidesharecdn.com/esug-20210624tetsuyasodo-210624115320/75/Elasticsearch-44-20210624-25-2048.jpg)




![検証手順
■事前ドキュメント格納: CSVファイルを元にBERTサーバにテキストを投げて変換し、JSONに整形②
32
#elasticsearchjp
$ cd bertsearch
$ python3 example/create_documents.py --data=../livedoornews.csv ¥
--index_name=testindex
(この処理は時間がかかります)
$ wc -l documents.jsonl
7367
$ cat documents.jsonl
{"_op_type": "index", "_index": "testindex", "text": "東京ディズニーシーの人気アトラクション
「センター・オブ・ジ・アース」の世界を映画化した第2弾『センター・オブ・ジ・アー… ", "title": "独占入手!
「センター・オブ・ジ・アース」のゲームを先行プレイ", "text_vector": [-0.9192637205123901, -
0.07473928481340408, 0.08322068303823471, -0.10188467800617218, -0.43304893374443054,
…, 0.6378014087677002, 0.04336249455809593]}
{"_op_type": "index", "_index": "testindex", "text": "『24 -TWENTYFOUR-』が終了してから2年、
ジャック・バウワー役のキーファー・サザーランドが主演を務める最新海外ドラマ『TOUCH/タッチ』が10…](https://image.slidesharecdn.com/esug-20210624tetsuyasodo-210624115320/75/Elasticsearch-44-20210624-32-2048.jpg)


































](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqlchatgptodc2023nttdata-230830045114-329af13b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[FUNAI輪講] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/bert-190625044118-thumbnail.jpg?width=640&height=640&fit=bounds)










